Java开发网络爬虫:教你如何自动化抓取网页数据
“纵有疾风来,人生不言弃”,这句话送给正在学习文章的朋友们,也希望在阅读本文《Java开发网络爬虫:教你如何自动化抓取网页数据》后,能够真的帮助到大家。我也会在后续的文章中,陆续更新文章相关的技术文章,有好的建议欢迎大家在评论留言,非常感谢!
Java开发网络爬虫:教你如何自动化抓取网页数据
在互联网时代,数据是非常宝贵的资源,如何高效地获取并处理这些数据成为许多开发者关注的焦点。而网络爬虫作为一种自动化抓取网页数据的工具,因其高效、灵活的特点,受到了广大开发者的青睐。本文将介绍如何使用Java语言开发网络爬虫,并提供具体的代码示例,帮助读者了解和掌握网络爬虫的基本原理和实现方式。
一、了解网络爬虫的基本原理
网络爬虫(Web Crawler)是模拟人工浏览器行为,自动访问网络服务器上的网页,并将关键信息抓取下来的程序。网络爬虫通常由以下几个主要组件组成:
- URL管理器(URL Manager):负责管理待抓取的URL队列,以及已经抓取过的URL集合。
- 网页下载器(Web Downloader):负责下载URL所指向网页的HTML源代码。
- 网页解析器(Web Parser):负责解析网页源代码,提取出感兴趣的数据。
- 数据存储器(Data Storage):负责将解析得到的数据存储到本地文件或数据库中。
二、使用Java实现网络爬虫
下面,我们将使用Java语言实现一个简单的网络爬虫程序。首先,我们需要导入一些必要的类库:
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
然后,我们定义一个名为WebCrawler的类,其中包含一个名为crawl()的方法,用于执行网络爬虫的主要逻辑。具体代码如下:
public class WebCrawler {
public void crawl(String seedUrl) {
// 初始化URL管理器
URLManager urlManager = new URLManager();
urlManager.addUrl(seedUrl);
// 循环抓取URL队列中的URL
while(!urlManager.isEmpty()) {
String url = urlManager.getNextUrl();
// 下载网页
String html = WebDownloader.downloadHtml(url);
// 解析网页
WebParser.parseHtml(html);
// 获取解析到的URL,并加入URL队列
urlManager.addUrls(WebParser.getUrls());
// 存储解析得到的数据
DataStorage.saveData(WebParser.getData());
}
}}
网页下载器和网页解析器的具体实现可参考以下代码:
public class WebDownloader {
public static String downloadHtml(String url) {
StringBuilder html = new StringBuilder();
try {
URL targetUrl = new URL(url);
BufferedReader reader = new BufferedReader(new InputStreamReader(targetUrl.openStream()));
String line;
while ((line = reader.readLine()) != null) {
html.append(line);
}
reader.close();
} catch (Exception e) {
e.printStackTrace();
}
return html.toString();
}}
public class WebParser {
private static Listurls = new ArrayList<>(); private static List data = new ArrayList<>(); public static void parseHtml(String html) { // 使用正则表达式解析网页,提取URL和数据 // ... // 将解析得到的URL和数据保存到成员变量中 // ... } public static List getUrls() { return urls; } public static List getData() { return data; }
}
最后,我们需要实现一个URL管理器和一个数据存储器。代码如下:
public class URLManager {
private QueueurlQueue = new LinkedList<>(); private Set urlSet = new HashSet<>(); public void addUrl(String url) { if (!urlSet.contains(url)) { urlQueue.offer(url); urlSet.add(url); } } public String getNextUrl() { return urlQueue.poll(); } public void addUrls(List urls) { for (String url : urls) { addUrl(url); } } public boolean isEmpty() { return urlQueue.isEmpty(); }
}
public class DataStorage {
public static void saveData(Listdata) { // 存储数据到本地文件或数据库 // ... }
}
三、总结
通过本文的介绍,我们了解了网络爬虫的基本原理和实现方式,并通过Java语言提供的类库和具体代码示例,帮助读者了解和掌握网络爬虫的使用方法。通过自动化抓取网页数据,我们可以高效地获取和处理互联网上的各种数据资源,为后续的数据分析、机器学习等工作提供基础支持。
今天关于《Java开发网络爬虫:教你如何自动化抓取网页数据》的内容介绍就到此结束,如果有什么疑问或者建议,可以在golang学习网公众号下多多回复交流;文中若有不正之处,也希望回复留言以告知!
 PHP开发技巧:如何实现网站访问日志记录功能
PHP开发技巧:如何实现网站访问日志记录功能
- 上一篇
- PHP开发技巧:如何实现网站访问日志记录功能

- 下一篇
- 如何在PHP微服务中实现分布式定时任务和调度
-
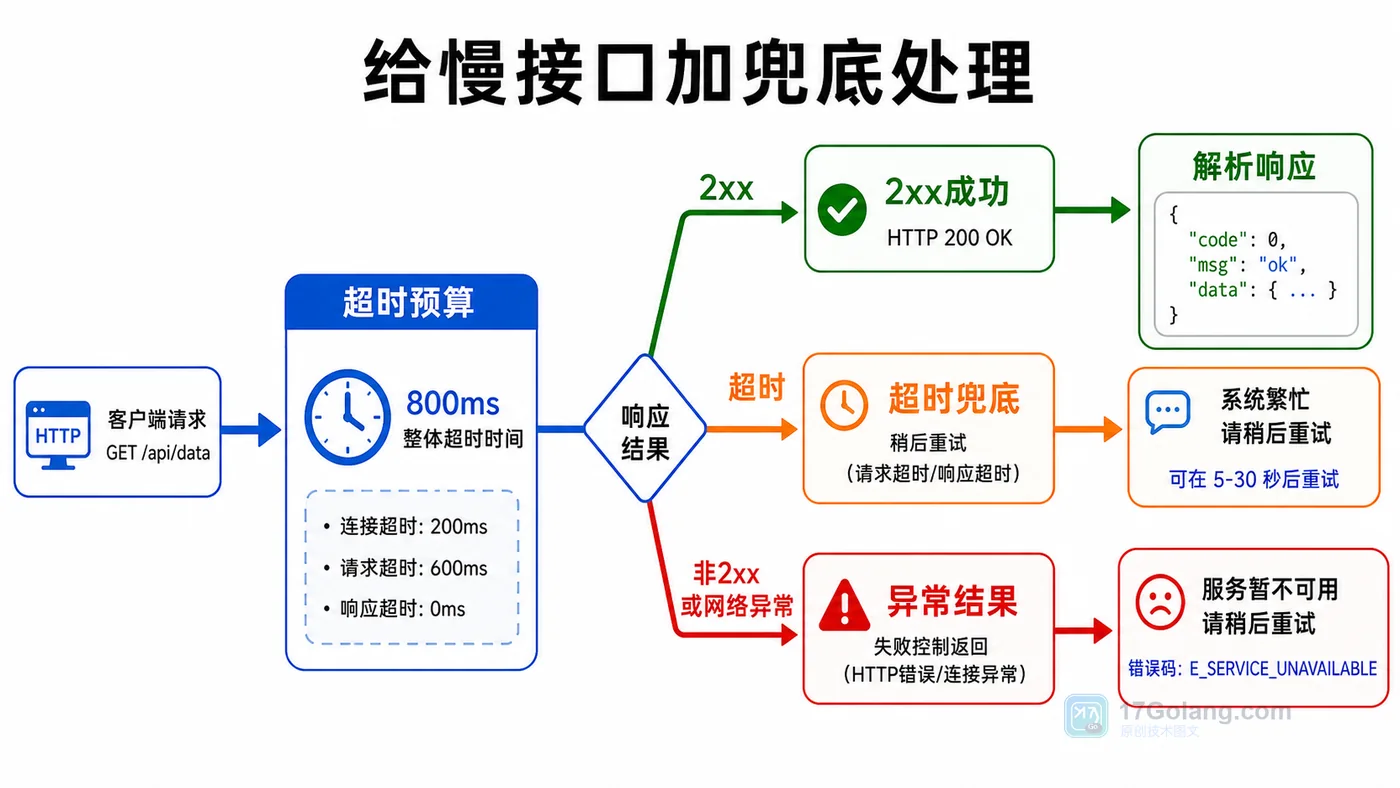
- 文章 · java教程 | 1天前 | http接口 · httpclient · Java教程 · 接口调试 · 超时处理 · java 接口调用 httpclient 超时控制 状态码 响应体
- Java HttpClient 调接口实战:超时、状态码和响应体这样处理
- 224浏览 收藏
-
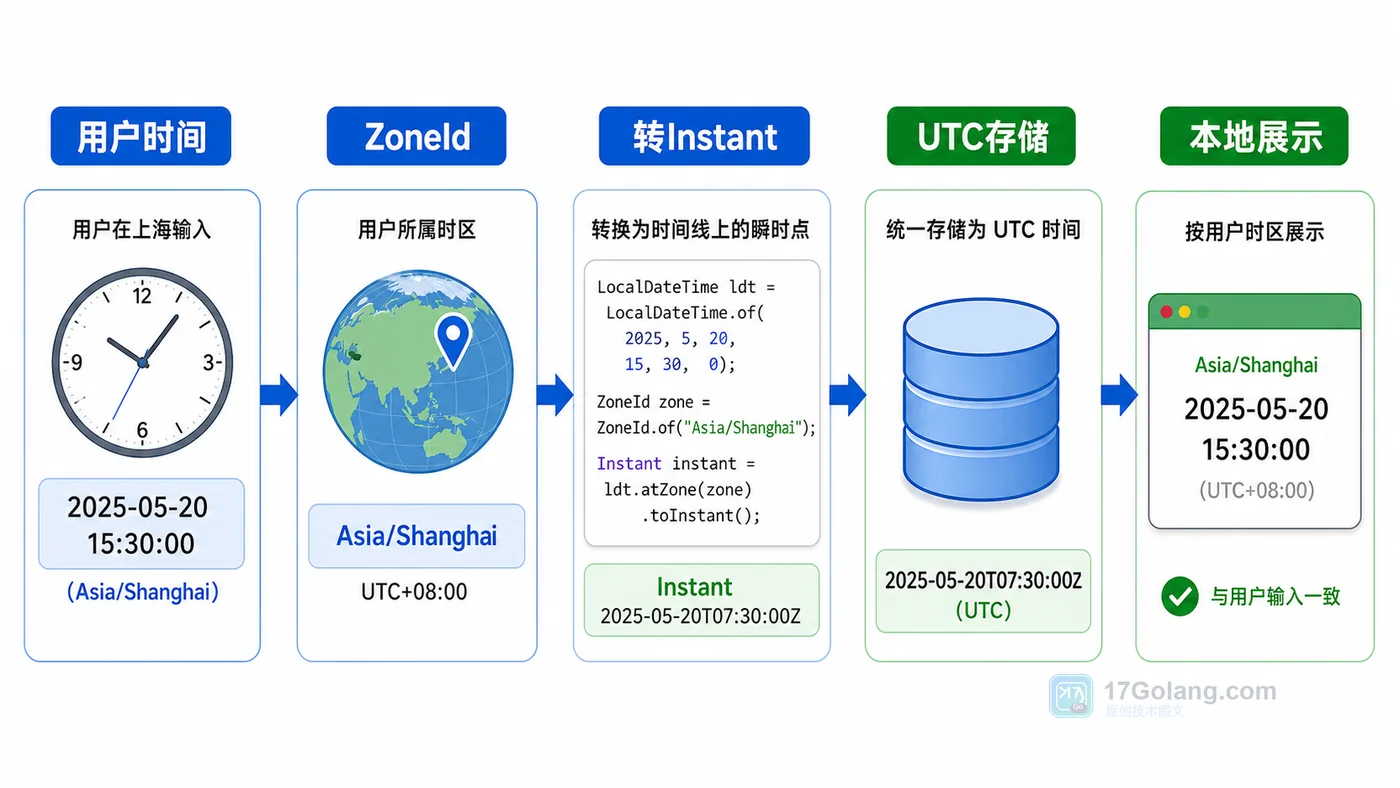
- 文章 · java教程 | 1天前 | 时间处理 · instant · Java教程 · 时区转换 · DateTimeFormatter · java DateTimeFormatter java.time 时区处理 ZoneId INSTANT
- Java 时间与时区处理实战:Instant、ZoneId 和 DateTimeFormatter 怎么配
- 461浏览 收藏
-
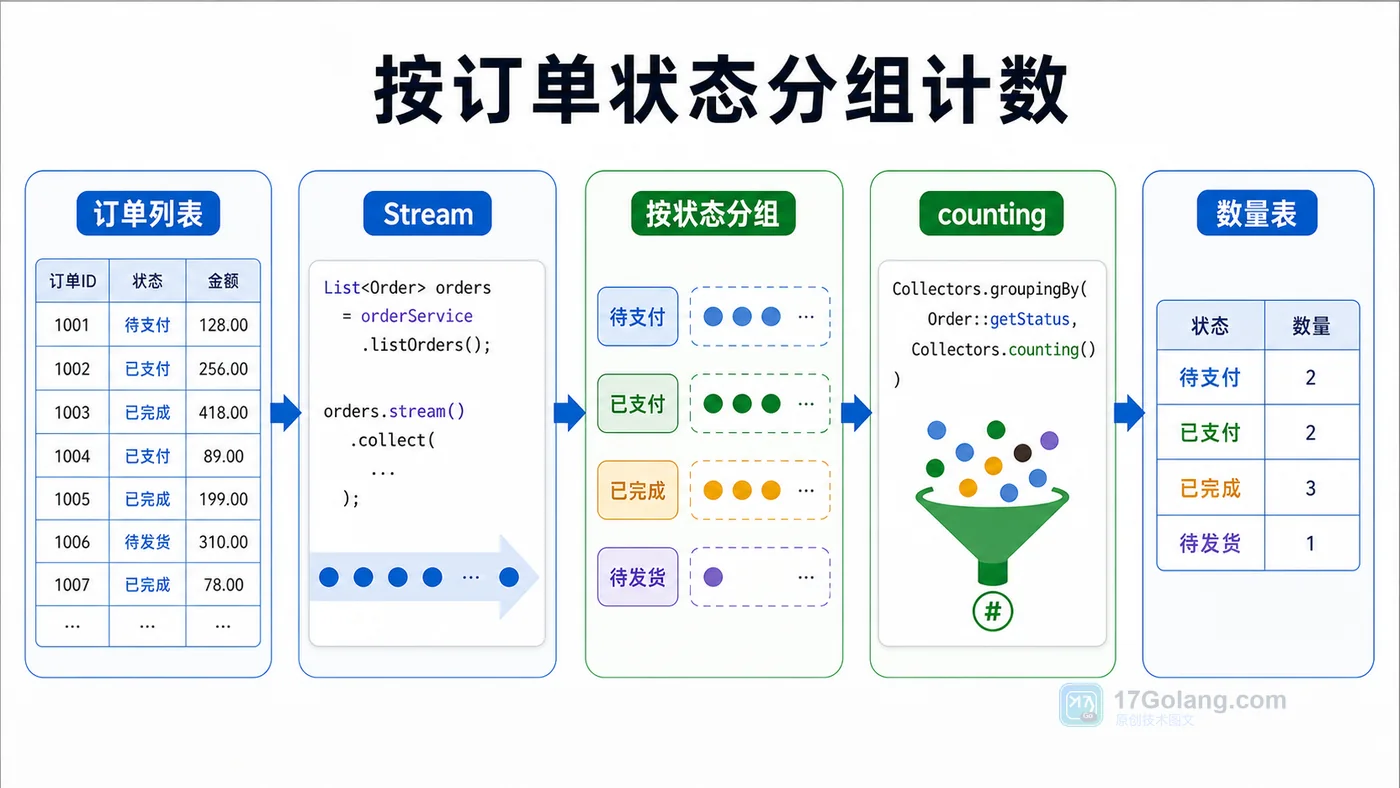
- 文章 · java教程 | 1天前 | Java · Stream · 集合统计 · 分组聚合 · Collectors · java Stream Collectors groupingBy counting summarizingInt
- Java Stream 分组统计实战:groupingBy、counting 和 summarizingInt 怎么用
- 478浏览 收藏
-
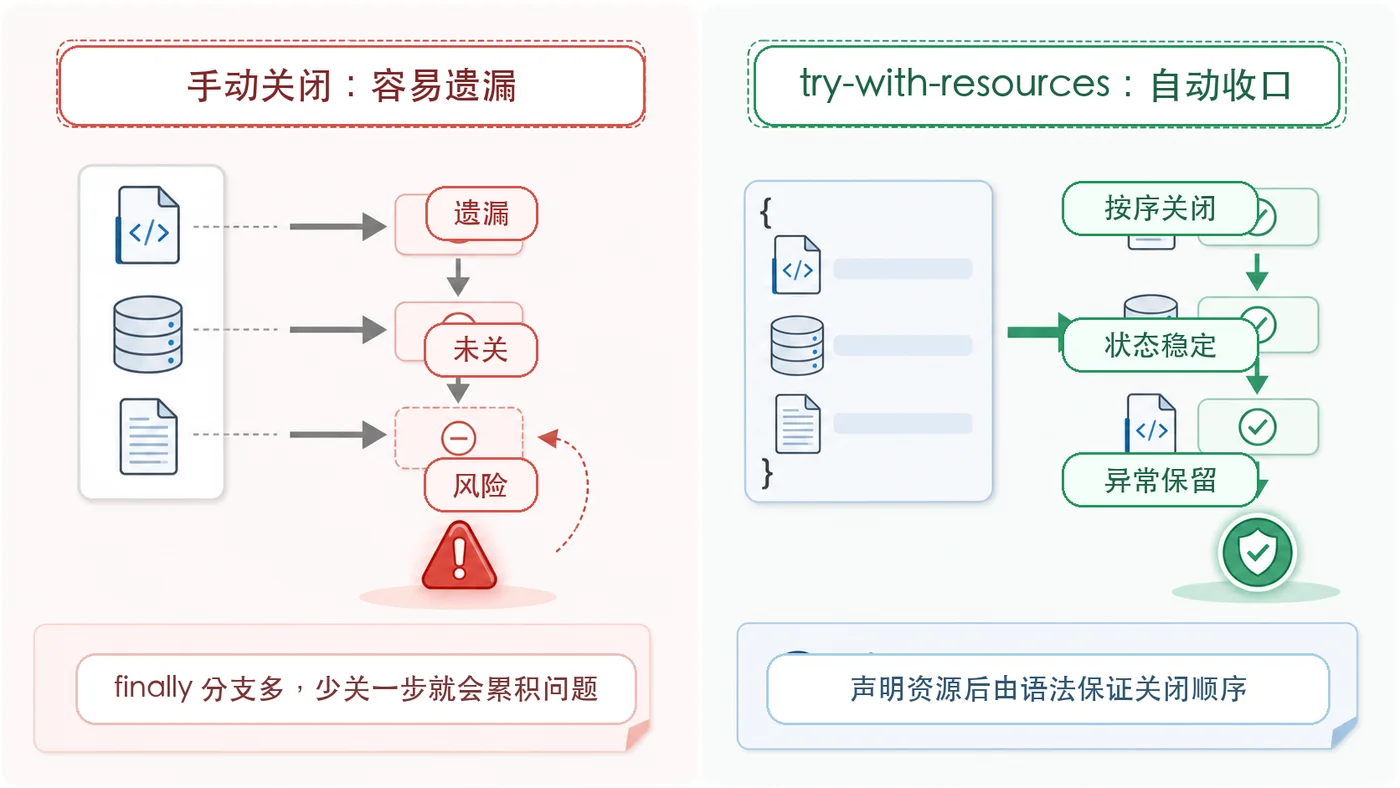
- 文章 · java教程 | 1天前 | Java · 文件读取 · 异常处理 · 资源管理 · try-with-resources · java 异常处理 try-with-resources 资源关闭 AutoCloseable 文件流
- Java try-with-resources 资源关闭实战:文件流和目录扫描这样写更稳
- 268浏览 收藏
-
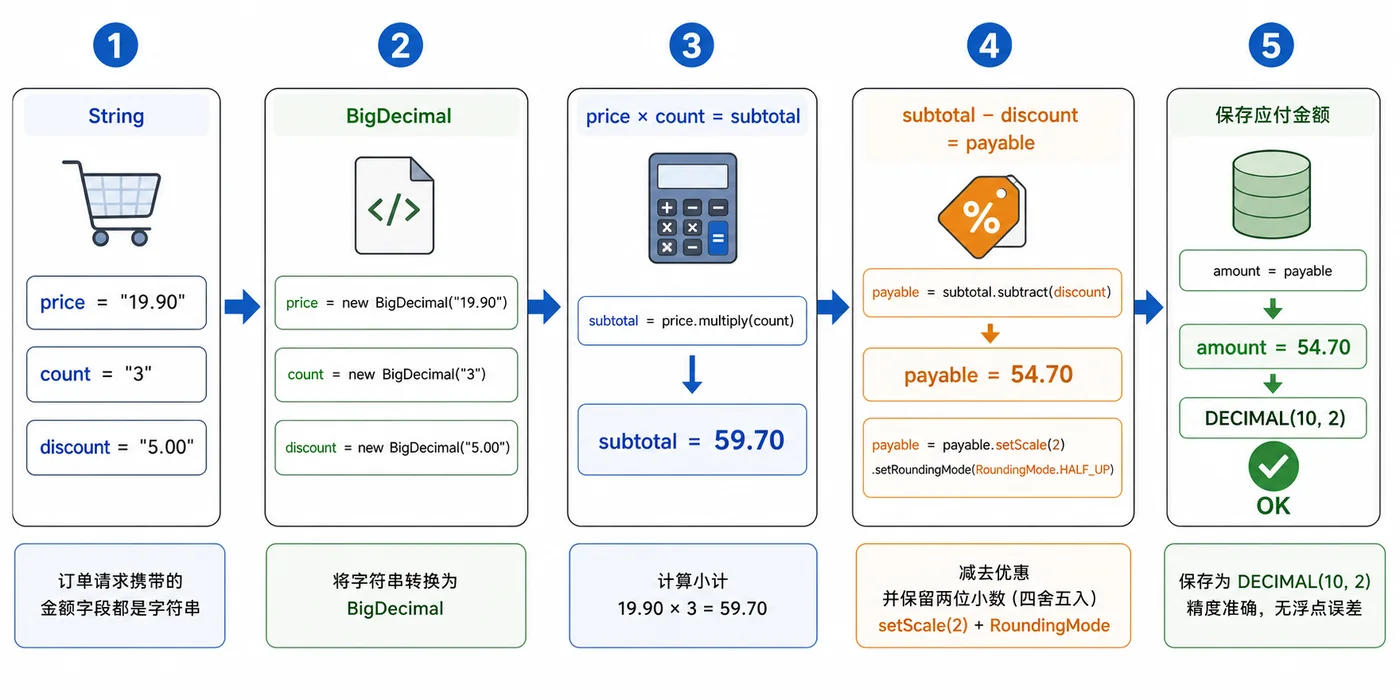
- 文章 · java教程 | 1天前 | Java教程 · 后端开发 · BigDecimal · 金额计算 · java 舍入 bigdecimal 浮点误差 金额计算 RoundingMode
- Java BigDecimal 金额计算实战:避免浮点误差和舍入问题
- 324浏览 收藏
-
- 文章 · java教程 | 2天前 | 异步编程 · Java教程 · 超时治理 · CompletableFuture · java 异步任务 超时处理 completablefuture orTimeout completeOnTimeout
- Java CompletableFuture 超时处理实战:orTimeout 和兜底结果怎么选
- 421浏览 收藏
-

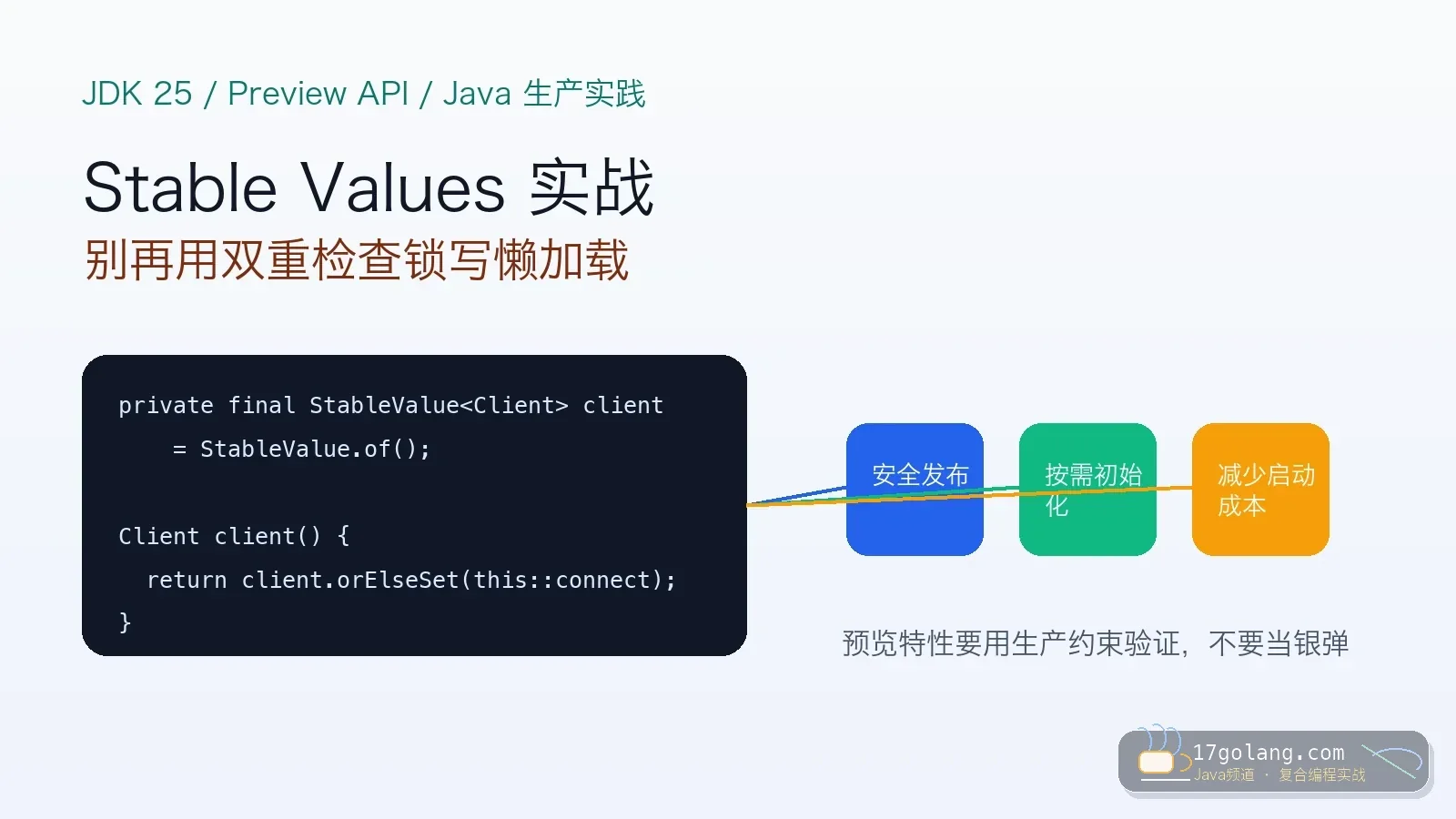
- 文章 · java教程 | 6天前 | 并发编程 · 生产实践 · Java教程 · JDK25 · 虚拟线程 · 虚拟线程 Java 25 JEP 505 Structured Concurrency StructuredTaskScope
- Java 25 Structured Concurrency 实战:别让 CompletableFuture 把超时拖散
- 443浏览 收藏
-
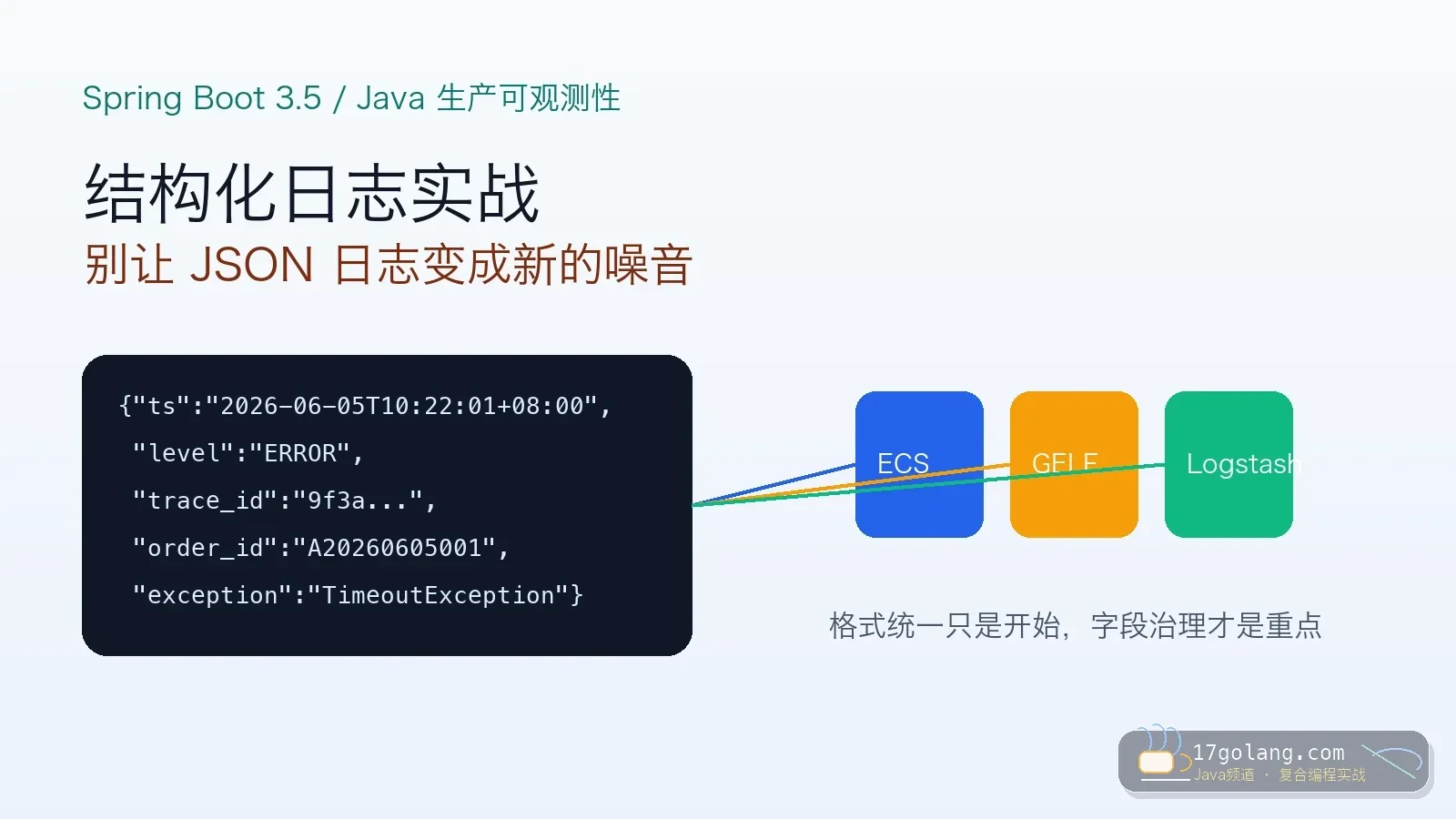
- 文章 · java教程 | 1星期前 | 日志 · Spring Boot · 生产实践 · 可观测性 · Java教程 · java 可观测性 MDC 结构化日志 Spring Boot 3.5
- Spring Boot 3.5 结构化日志实战:别让 JSON 日志变成新的噪音
- 332浏览 收藏
-
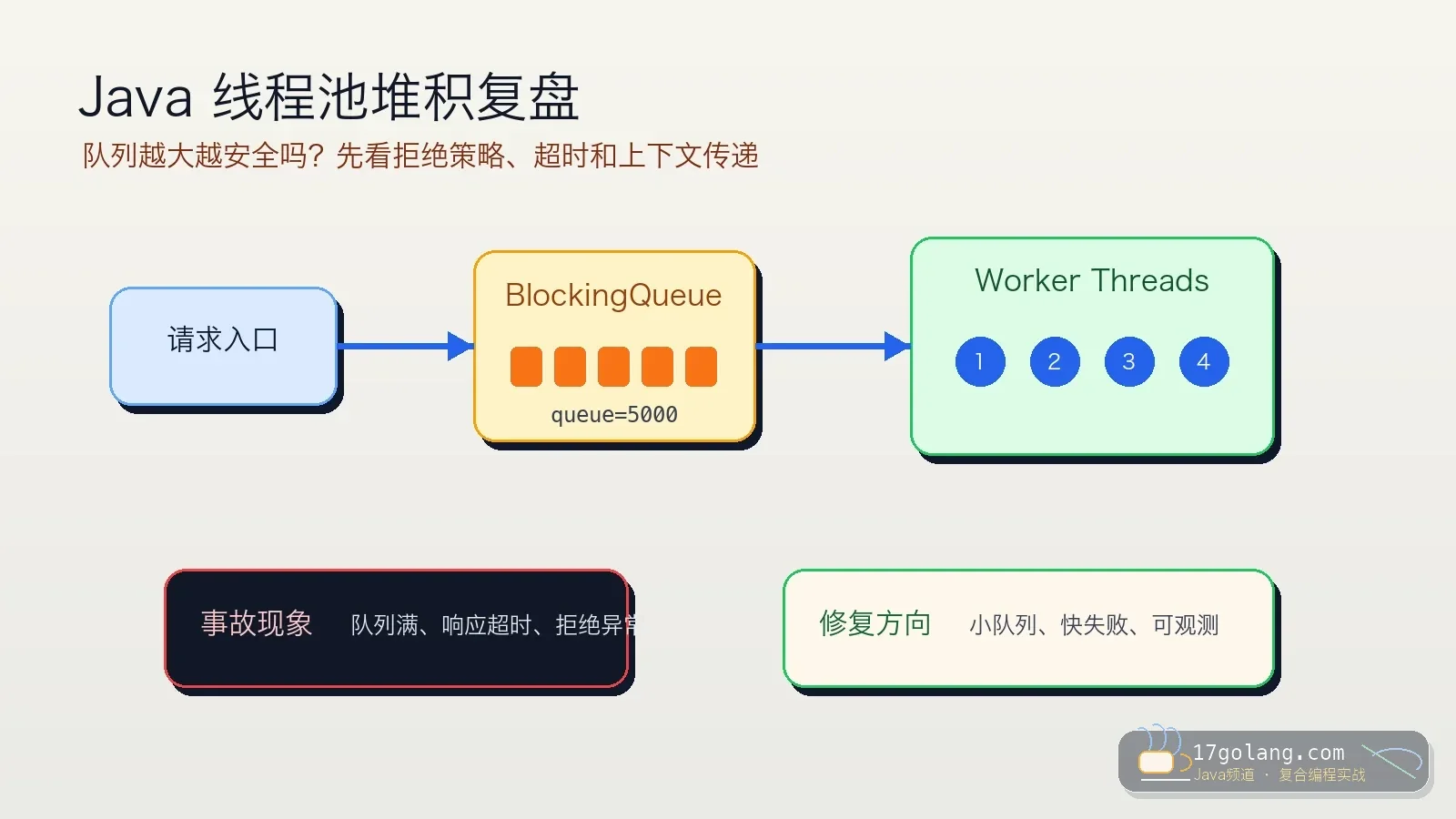
- 文章 · java教程 | 1星期前 | 线程池 · Spring Boot · 生产实践 · Java教程 · ThreadPoolExecutor · java 性能优化 线程池 spring boot threadpoolexecutor
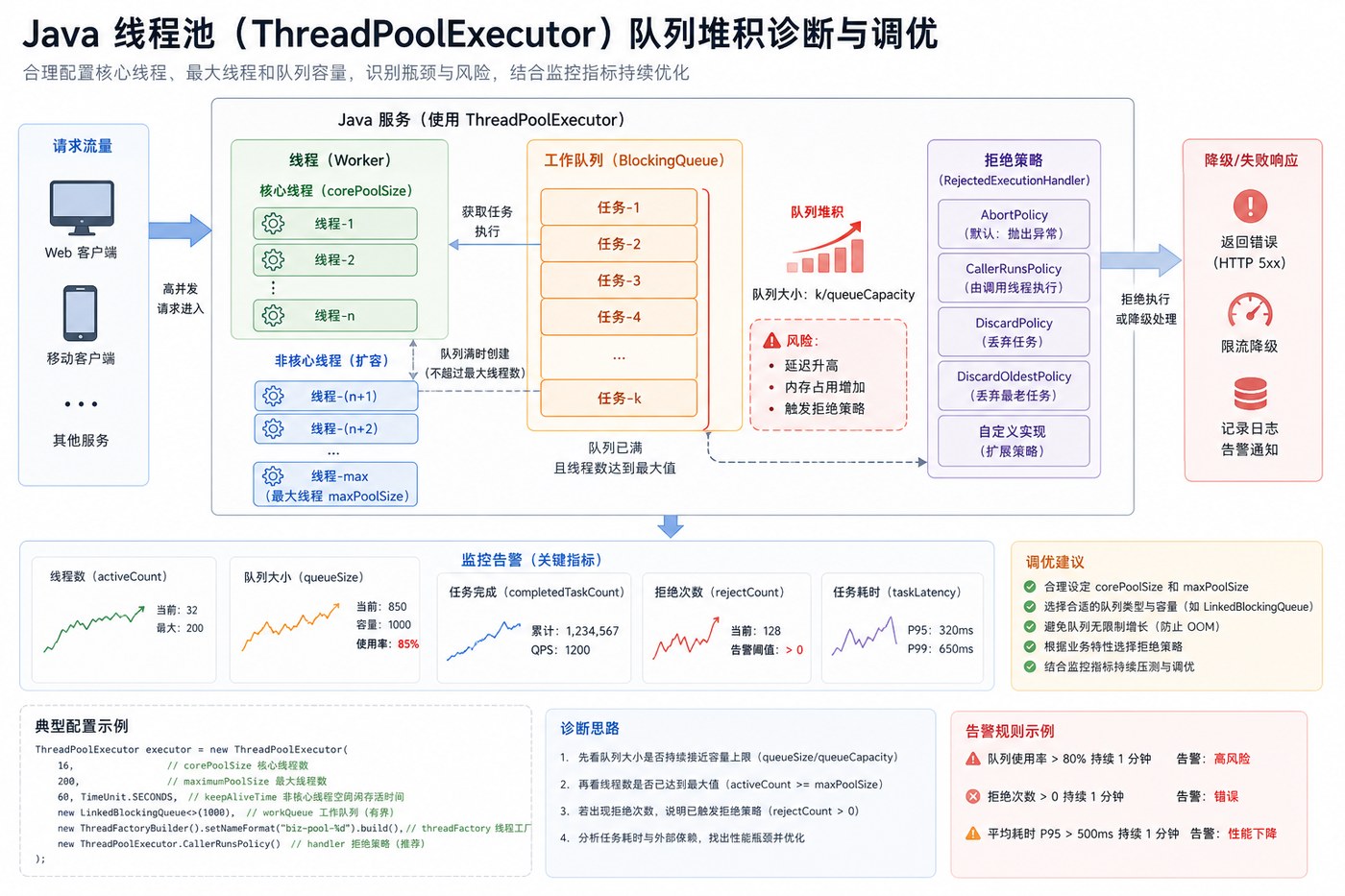
- Java 线程池队列堆积复盘:别让无界队列把慢故障藏起来
- 326浏览 收藏

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 8487次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 8900次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 8731次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 10635次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 9563次使用
-
- 提升Java功能开发效率的有力工具:微服务架构
- 2023-10-06 501浏览
-
- 掌握Java海康SDK二次开发的必备技巧
- 2023-10-01 501浏览
-
- 如何使用java实现桶排序算法
- 2023-10-03 501浏览
-
- Java开发实战经验:如何优化开发逻辑
- 2023-10-31 501浏览
-
- 如何使用Java中的Math.max()方法比较两个数的大小?
- 2023-11-18 501浏览


