Celery 任务“偶尔重复执行”不是罕见事故。线上更常见的场景是:订单结算任务调用第三方接口超时,工程师给任务加了 autoretry_for,结果失败率降下去了,重复扣库存、重复发券、重复写状态的问题冒出来了。重试本身不是问题,没做幂等才是问题。
这篇按 Python Celery 5.4 的生产任务来写:如何用业务幂等键保护副作用,什么时候开 acks_late,怎么配置 retry_backoff 和 retry_jitter,以及上线前怎样确认任务不会变成高频重试风暴。示例适用于 Python 3.12/3.13 与 Celery 5.4。
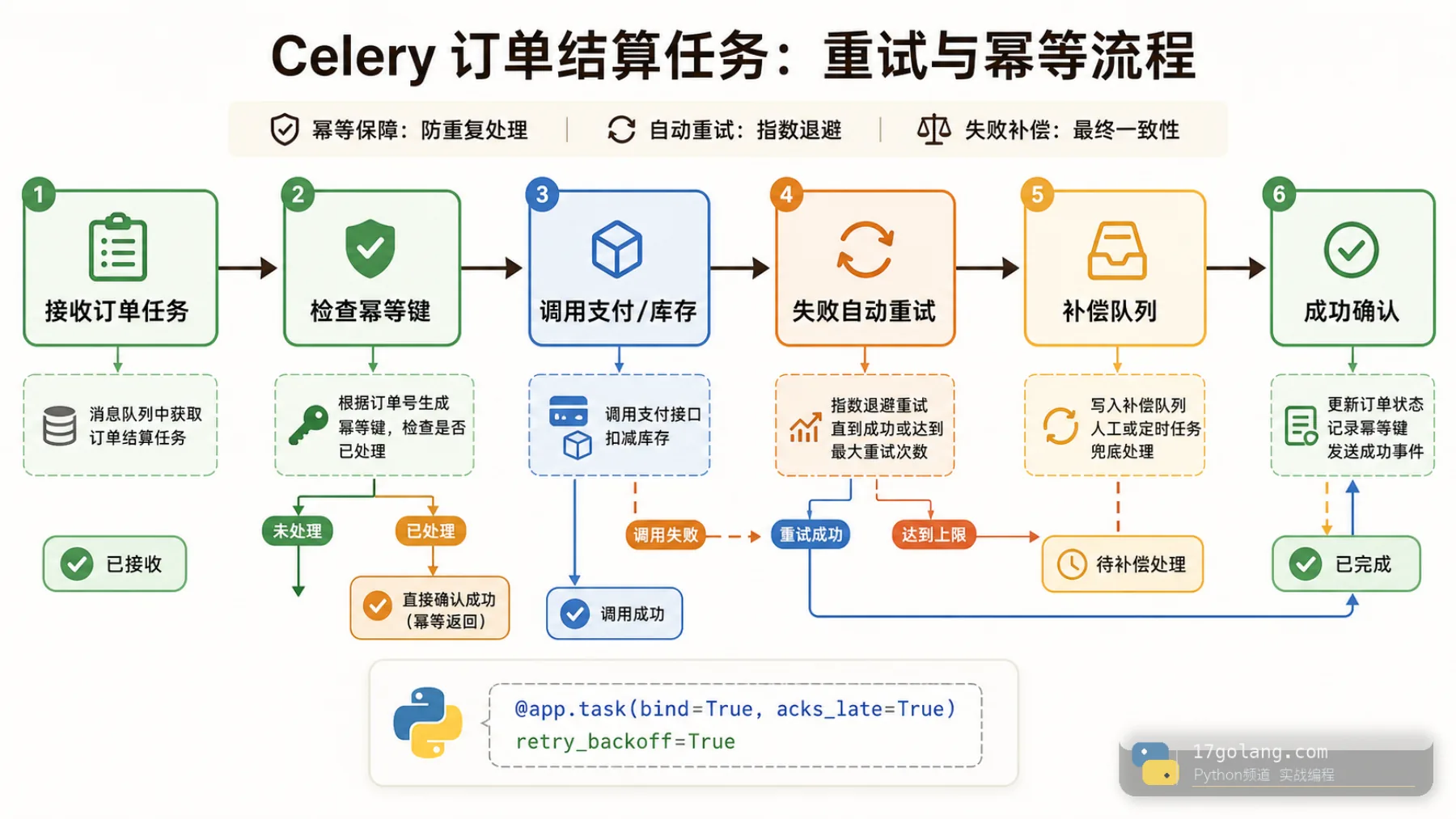
业务场景:订单结算任务重复扣了一次库存
假设下单后我们异步执行结算任务:扣库存、生成权益、通知 CRM。任务代码最开始很朴素。
# tasks.py
from celery import Celery
app = Celery("shop")
@app.task
def settle_order(order_id: str) -> None:
order = load_order(order_id)
charge_wallet(order.user_id, order.amount)
decrease_stock(order.sku_id, order.quantity)
grant_coupon(order.user_id, order.coupon_id)
mark_order_settled(order_id)
这段代码的问题不是“没有 Celery 高级配置”,而是它把多个有副作用的动作放在一个没有幂等保护的函数里。只要 worker 崩溃、网络抖动、第三方接口超时、人工重放消息,副作用就可能执行多次。
第一步:先定义业务幂等键
Celery 的 task_id 适合追踪一次任务投递,但业务幂等通常要绑定业务对象。结算任务的幂等键可以是 settle_order:{order_id},发短信可以是 sms:{template}:{phone}:{biz_id},同步账单可以是 bill_sync:{account}:{period}。
from dataclasses import dataclass
from enum import StrEnum
class JobStatus(StrEnum):
RUNNING = "running"
DONE = "done"
FAILED = "failed"
@dataclass
class IdempotencyRecord:
key: str
status: JobStatus
task_id: str
def reserve_once(key: str, task_id: str) -> bool:
# 真实项目里应使用唯一索引或原子 set-if-not-exists。
try:
insert_idempotency_record(key, status=JobStatus.RUNNING, task_id=task_id)
return True
except DuplicateKeyError:
return False
重点是“抢占记录”必须原子化。不要先查再插,那是两个动作;并发任务同时进来时会穿透。数据库唯一索引、Redis SET key value NX EX、或者业务表里的唯一约束都可以,但要明确失败后的补偿规则。
第二步:把任务写成可重入函数
任务可重入的意思是:同一业务键重复执行,不会制造额外副作用。下面是一个更接近生产的写法,任务绑定 self,用 self.request.id 写入幂等记录,方便把日志、任务状态和业务记录串起来。
from requests import Timeout, ConnectionError
class PermanentBusinessError(Exception):
pass
@app.task(
bind=True,
acks_late=True,
autoretry_for=(Timeout, ConnectionError),
retry_backoff=True,
retry_backoff_max=300,
retry_jitter=True,
retry_kwargs={"max_retries": 6},
)
def settle_order(self, order_id: str) -> str:
idem_key = f"settle_order:{order_id}"
if not reserve_once(idem_key, self.request.id):
return "duplicate_ignored"
try:
order = load_order_for_update(order_id)
if order.settled_at:
mark_idempotency_done(idem_key)
return "already_done"
charge_wallet_once(order.wallet_txn_id, order.user_id, order.amount)
decrease_stock_once(order.stock_txn_id, order.sku_id, order.quantity)
grant_coupon_once(order.coupon_txn_id, order.user_id, order.coupon_id)
mark_order_settled(order_id)
mark_idempotency_done(idem_key)
return "settled"
except PermanentBusinessError:
mark_idempotency_failed(idem_key, reason="permanent")
raise
except Exception:
release_running_record(idem_key)
raise
这里有两个容易踩坑的点。第一,autoretry_for 只放可恢复异常,别把所有 Exception 都塞进去。参数错误、余额不足、订单状态非法,这类永久失败重试多少次都没意义。第二,任务失败时是否释放 RUNNING 记录要按业务决定;如果保留记录,就需要补偿任务扫描超时记录。
第三步:理解 retry 和 acks_late 的边界
Celery 5.4 文档里有两个事实很关键:retry() 会发送新的任务消息,并沿用同一个 task id;acks_late=True 会让消息在任务执行之后再确认。后者意味着 worker 执行中崩溃时任务可能被再次投递,所以官方也明确要求任务应当是幂等的。
我通常这样定规则:
- 任务没有外部副作用,比如只生成临时统计,可以按吞吐优先配置。
- 任务有副作用但已经有业务幂等键,才考虑
acks_late=True。 - 任务调用外部系统,必须给 HTTP、数据库、RPC 调用设置显式超时。
- 重试只覆盖短暂网络错误、限流、临时不可用,不覆盖业务校验失败。
def call_payment_api(payload: dict) -> dict:
response = http.post(
"https://payment.example/charge",
json=payload,
timeout=(3.0, 15.0), # connect timeout, read timeout
)
response.raise_for_status()
return response.json()
不要把 worker time limit 当作主要超时控制。硬超时会强制终止执行进程,更适合作为兜底保护;正常路径应该让网络库、数据库驱动和业务代码自己在可控位置抛出异常。
第四步:退避和抖动要配,不要固定 3 秒重试
固定间隔重试很容易把故障扩大:第三方服务抖动时,所有失败任务按同一节奏冲回去。Celery 的 retry_backoff=True 会使用指数退避;默认还会带随机抖动,并且退避上限默认是 10 分钟。生产里我会显式写出上限,避免读代码的人误解。
@app.task(
bind=True,
autoretry_for=(Timeout, ConnectionError),
retry_backoff=True,
retry_backoff_max=300,
retry_jitter=True,
retry_kwargs={"max_retries": 6},
)
def sync_invoice(self, invoice_id: str) -> None:
sync_invoice_to_partner(invoice_id)
如果任务有强 SLA,比如 2 分钟内必须完成,不要只靠 max_retries 控制。要记录首次创建时间,超过业务截止时间就停止重试,转人工补偿或状态机兜底。
第五步:长任务要控制预取
长任务最怕 worker 一次预取太多消息。Celery 优化文档建议长任务可以把 worker_prefetch_multiplier 设为 1;如果还希望 worker 只保留接近并发数的未确认任务,就需要配合 task_acks_late=True。这又回到前提:任务必须幂等。
# celeryconfig.py task_acks_late = True worker_prefetch_multiplier = 1 task_track_started = True task_time_limit = 900 task_soft_time_limit = 840
不要让所有任务共享一组 worker。短任务追吞吐,长任务追公平和可控内存,最好拆队列:quick、settlement、reports 分别配置 worker 并发和预取。
诊断步骤:重复执行时先问 6 个问题
- 重复的是同一个
task_id,还是同一个业务order_id被投递了多次? - 任务是否开启了
acks_late,worker 是否发生过重启、OOM 或硬超时? - 幂等记录是否有唯一约束,失败时是否被错误释放?
autoretry_for是否覆盖了永久业务异常?- 外部 I/O 是否有明确 timeout,还是任务卡住后被 time limit 杀掉?
- 队列长度、重试次数、失败原因是否能按任务名和业务键聚合?
上线检查清单
- 所有有副作用的 Celery 任务都有业务幂等键,不只依赖 task id。
- 幂等键写入是原子的,有唯一索引或等价的原子占位机制。
acks_late=True只用于可重入任务,并和worker_prefetch_multiplier=1的影响一起压测。autoretry_for只包含可恢复异常,永久业务异常直接失败。- 重试开启
retry_backoff和retry_jitter,并设置合理的max_retries。 - HTTP/RPC/数据库调用都有手动 timeout,worker time limit 只做兜底。
- 日志里带
task_id、业务键、request_id、retries和失败分类。 - 压测用同一业务键重复投递,确认不会重复扣款、扣库存或发消息。
总结
Celery 的重试能力很强,但它解决的是“临时失败后再执行一次”,不解决“再执行一次是否安全”。只要任务有外部副作用,先设计业务幂等键,再谈 acks_late、自动重试、退避和 worker 配置。
我的经验是:把 Celery 任务当成可能至少执行一次的 Python 函数来写。能重复运行、能清楚停止、能解释失败原因,这样的任务上线后才不会因为一次网络抖动变成业务事故。
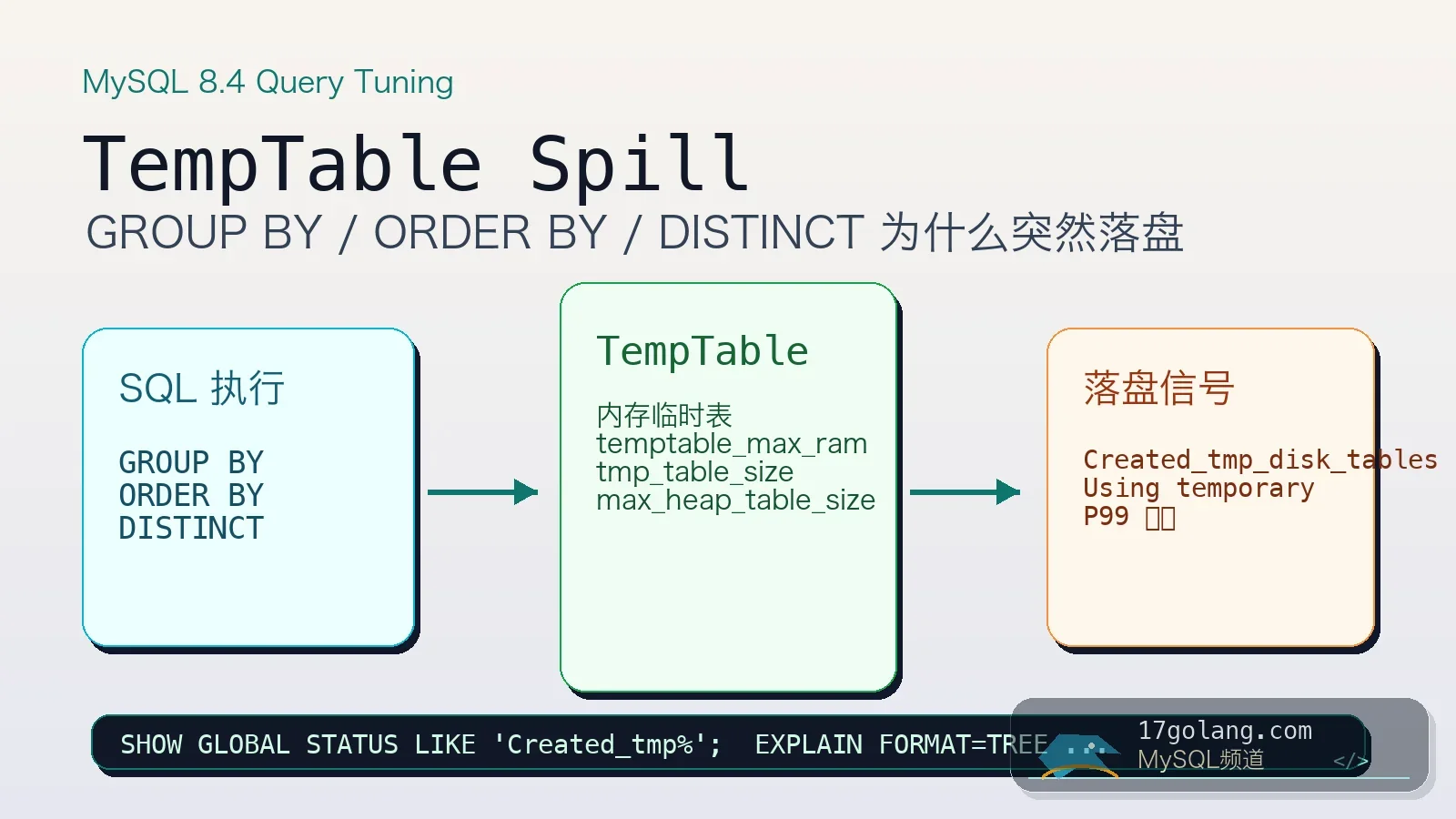 MySQL 8.4 内部临时表实战:GROUP BY 一慢就先查 TempTable 有没有落盘
MySQL 8.4 内部临时表实战:GROUP BY 一慢就先查 TempTable 有没有落盘