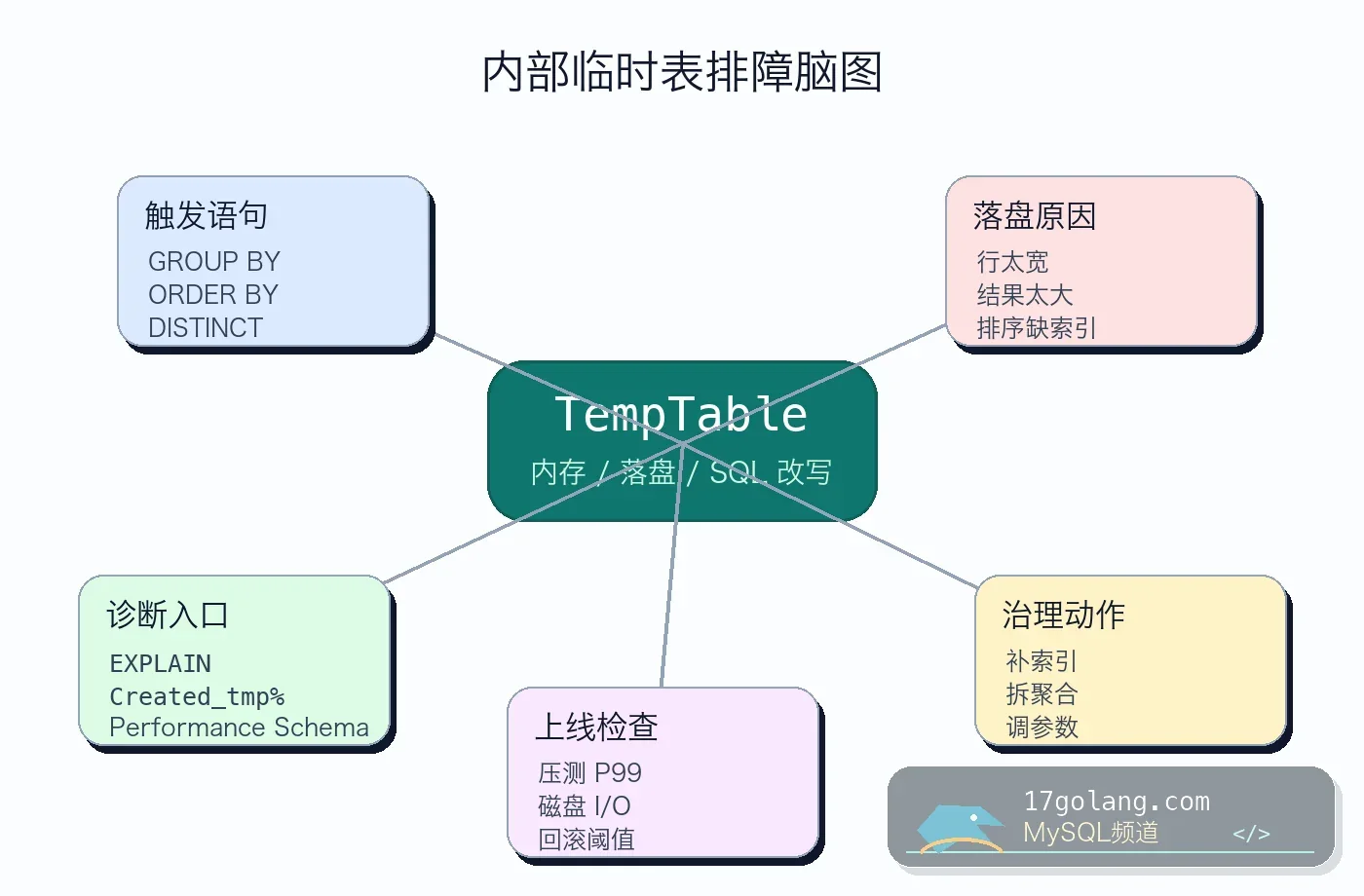
慢查询里最容易被低估的一类,是 GROUP BY、ORDER BY、DISTINCT 触发的内部临时表。业务看到的是“报表接口突然从 300ms 到 8s”,DBA 看到的是磁盘 I/O 抖动、Created_tmp_disk_tables 增长、执行计划里出现 Using temporary。这类问题别先调大参数,先确认 SQL 为什么要造临时表。
本文面向 MySQL 8.4。官方文档里内部临时表由 TempTable 等机制承载,超过内存限制或遇到不适合内存承载的场景会落盘。工程上要把它当成执行计划问题、内存容量问题和 SQL 设计问题的交叉点来处理。
一、业务场景:报表 SQL 把临时表打到磁盘
典型表结构如下,订单表有租户、状态、创建时间几个常用维度:
CREATE TABLE orders ( id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT, tenant_id BIGINT NOT NULL, status TINYINT NOT NULL, amount DECIMAL(12,2) NOT NULL, created_at DATETIME NOT NULL, PRIMARY KEY (id), KEY idx_created_at (created_at), KEY idx_tenant_status_created (tenant_id, status, created_at) ) ENGINE=InnoDB; SELECT tenant_id, COUNT(*) AS cnt, SUM(amount) AS total_amount FROM orders WHERE created_at >= '2026-06-01' GROUP BY tenant_id ORDER BY cnt DESC LIMIT 20;
这个 SQL 看起来简单,但它需要过滤、聚合、排序。只靠 created_at 索引能过滤时间,却不一定能顺便完成 GROUP BY tenant_id 和 ORDER BY cnt。结果集一大,内部临时表就可能从内存走到磁盘。
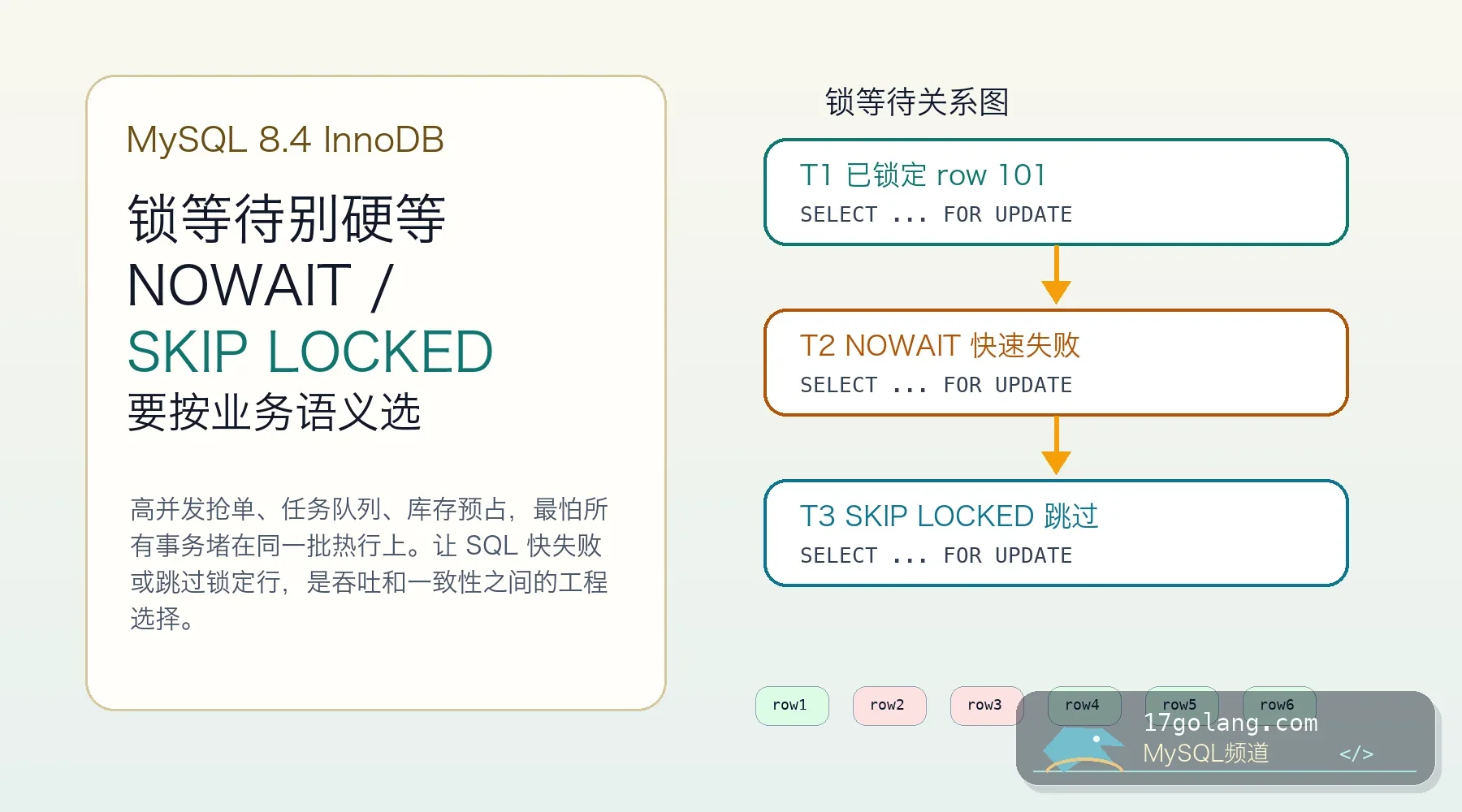
二、先抓证据:不要凭 Using temporary 一票否决
Using temporary 不是原罪。小临时表在内存里完成,可能完全可以接受。真正要警惕的是磁盘临时表持续增长、查询 P99 抖动、临时目录空间被吃掉。
EXPLAIN FORMAT=TREE SELECT tenant_id, COUNT(*) AS cnt, SUM(amount) AS total_amount FROM orders WHERE created_at >= '2026-06-01' GROUP BY tenant_id ORDER BY cnt DESC LIMIT 20; SHOW GLOBAL STATUS LIKE 'Created_tmp%'; SHOW VARIABLES LIKE 'tmp_table_size'; SHOW VARIABLES LIKE 'temptable_max_ram';
排查时我会记录执行前后的状态量差值,而不是只看全局累计值。否则高峰期别的 SQL 也在造临时表,你会把锅扣错。
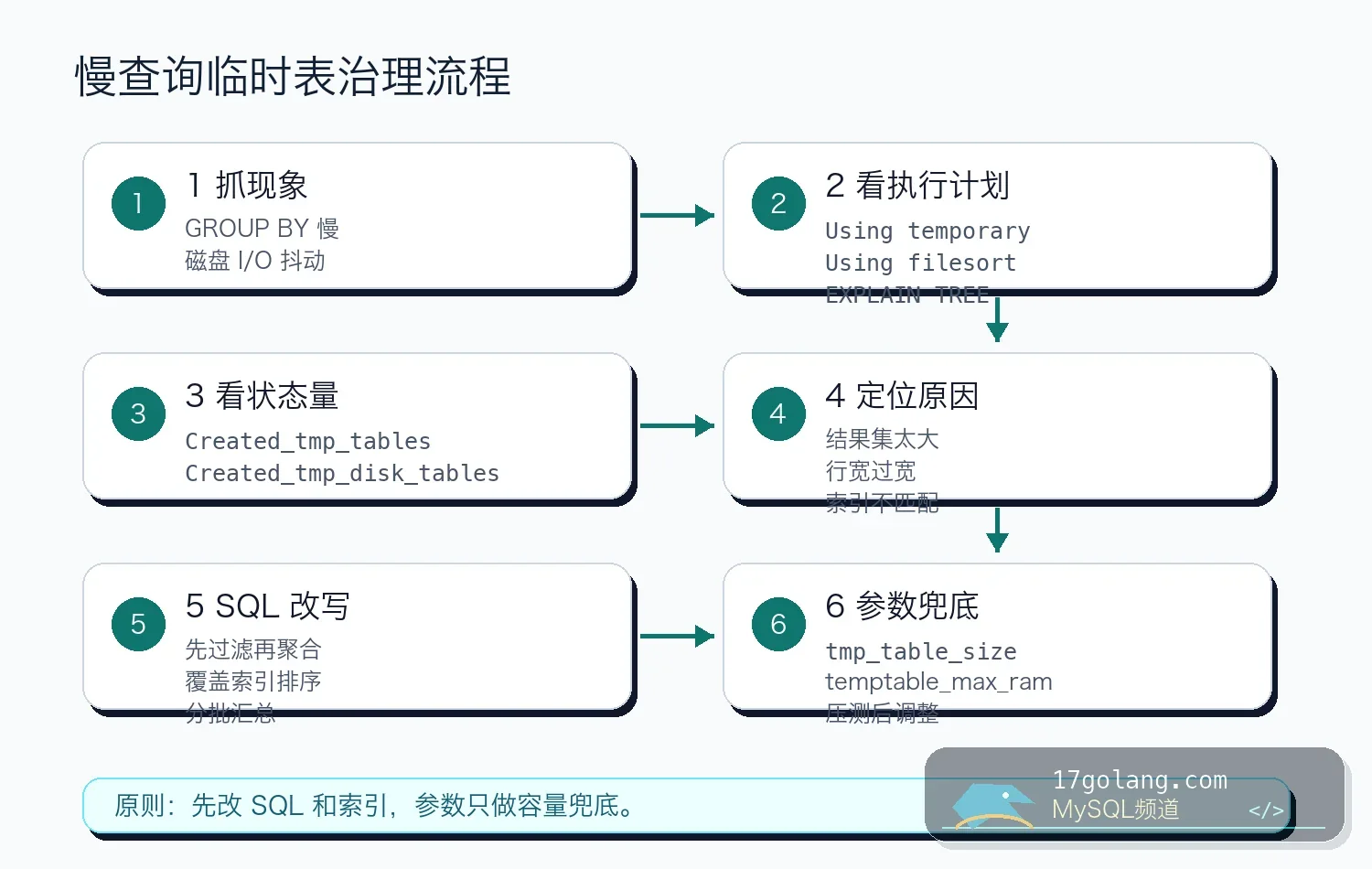
三、踩坑原因:行太宽、结果太大、排序无法走索引
内部临时表落盘通常不是单点原因。常见触发点有三类:
- 聚合结果太大:按高基数字段分组,例如用户、设备、订单号。
- 临时表行太宽:SELECT 带了大字段,或者聚合前保留了不必要列。
- 排序无法复用索引:按表达式、聚合结果或不同方向排序。
尤其是报表 SQL,开发经常先 SELECT * 写通逻辑,再补 GROUP BY。这会把临时表行宽放大,后面再怎么调参数都很被动。
四、SQL 改写:先缩小输入,再聚合排序
如果业务只要最近一个月活跃租户,可以先把过滤条件和必要列收窄:
SELECT tenant_id, COUNT(*) AS cnt, SUM(amount) AS total_amount
FROM (
SELECT tenant_id, amount
FROM orders FORCE INDEX (idx_created_at)
WHERE created_at >= '2026-06-01'
AND status IN (1, 2, 3)
) AS x
GROUP BY tenant_id
ORDER BY cnt DESC
LIMIT 20;
这不是说所有子查询都会更快,而是强调一个原则:让进入聚合的数据更少、行更窄。对高频报表,最好进一步做日维度汇总表,不要每次从明细表实时扫。

五、索引策略:不是所有 GROUP BY 都能靠一个索引解决
如果查询形态固定,比如按租户和状态过滤,再按时间范围统计,索引可以这样评估:
ALTER TABLE orders ADD INDEX idx_status_created_tenant (status, created_at, tenant_id);
但 ORDER BY cnt DESC 这种按聚合结果排序,通常仍需要临时结果集。索引能减少扫描和分组输入,不一定能消灭临时表。判断标准是执行计划和实际耗时,不是“有没有 Using temporary”。
六、参数只做兜底:别把内存开成事故源
MySQL 8.4 里和内部临时表相关的变量包括 tmp_table_size、max_heap_table_size、temptable_max_ram 等。调大它们可以减少一部分落盘,但风险是并发查询同时申请内存,实例内存压力被放大。
-- 示例:先在压测环境验证,不要直接照抄到生产 SET PERSIST tmp_table_size = 268435456; SET PERSIST max_heap_table_size = 268435456; SET PERSIST temptable_max_ram = 1073741824;
我通常要求参数变更必须带并发压测报告:同时跑报表查询、在线查询和写入,观察 MySQL 进程 RSS、磁盘 I/O、P99 和 OOM 风险。
七、上线检查单
- 慢 SQL 样本必须保留
EXPLAIN FORMAT=TREE和执行耗时。 - 记录执行前后
Created_tmp_tables、Created_tmp_disk_tables差值。 - 确认是否能通过过滤前置、减少列、汇总表降低临时表体积。
- 新增索引前评估写入成本和重复索引。
- 参数变更必须压测并设置回滚阈值。
八、我的结论
内部临时表不是坏东西,它是优化器完成复杂 SQL 的工作台。真正的问题是工作台太大,或者工作台被搬到了磁盘上。生产治理顺序很明确:先看计划和状态量,再改 SQL 和索引,最后才是参数兜底。只要顺序对,GROUP BY 慢查询通常不会变成一场玄学排障。
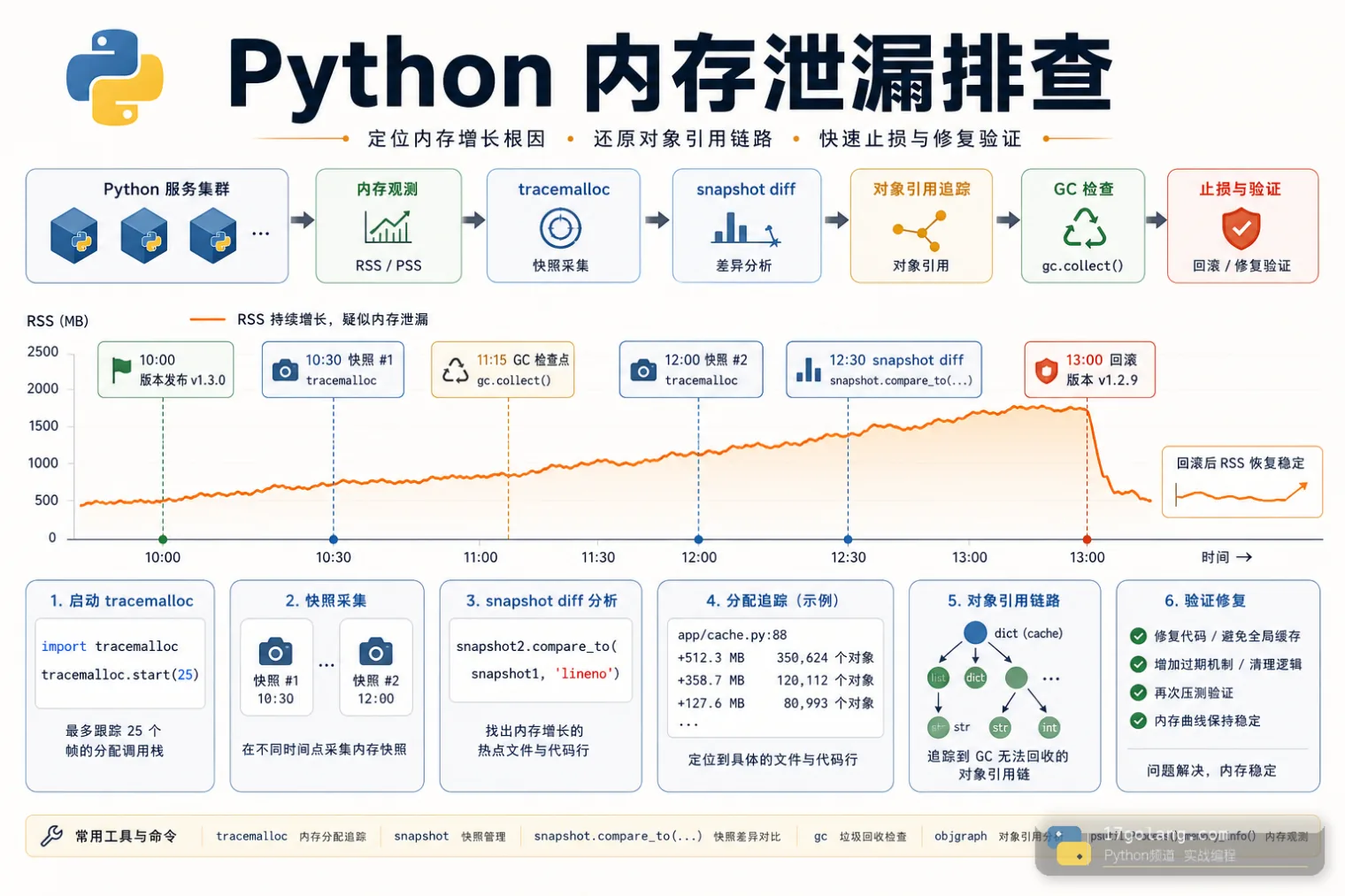 Python 内存泄漏排查实战:用 tracemalloc 找到失控引用
Python 内存泄漏排查实战:用 tracemalloc 找到失控引用