FastAPI 写 demo 很快,真正上生产以后,麻烦通常不是路由不会写,而是请求生命周期被塞得太满:启动时临时创建连接池,接口里直接跑阻塞导出,响应后用 BackgroundTasks 改关键订单状态,最后 P99 飙高、任务丢失、关闭进程还卡住。
这篇文章不做 FastAPI 入门,也不复述官方文档。我按一次真实后端排障来写:一个 Python API 服务从“偶尔慢、偶尔丢后台任务”开始,怎么把应用级资源放进 lifespan,把阻塞调用隔离到线程池,把关键任务移出请求生命周期,并给外部调用加上超时和可观测性。
业务场景:订单导出接口拖垮了整个服务
一个订单系统有个导出接口,产品要求点一下就生成 Excel,并把导出结果通知到用户。最初代码看着很直白:接口里查订单、生成文件、调内部通知服务,最后顺手把审计日志丢到后台任务。
import time
from fastapi import BackgroundTasks, FastAPI
app = FastAPI()
def write_audit_log(order_id: str) -> None:
time.sleep(2)
print(f"audit {order_id}")
@app.get("/orders/{order_id}/export")
async def export_order(order_id: str, background_tasks: BackgroundTasks):
rows = query_orders_from_db(order_id) # 同步阻塞
file_url = build_excel(rows) # CPU/文件阻塞
notify_user(order_id, file_url) # 同步 HTTP 调用
background_tasks.add_task(write_audit_log, order_id)
return {"file_url": file_url}
低流量时它能跑;并发一上来,现象就很熟悉:接口偶尔超过网关超时,其他无关接口也变慢,发布重启时后台任务没跑完,审计日志有缺口。问题不在 FastAPI 慢,而是我们把太多不可控工作塞进了一次请求里。
先画清请求边界
FastAPI 的优势是异步友好,但 async def 不是免死金牌。只要你在异步接口里直接执行阻塞函数,事件循环就会被卡住。同步数据库驱动、同步 HTTP 客户端、大文件生成、压缩、复杂 CPU 运算,都需要单独处理。
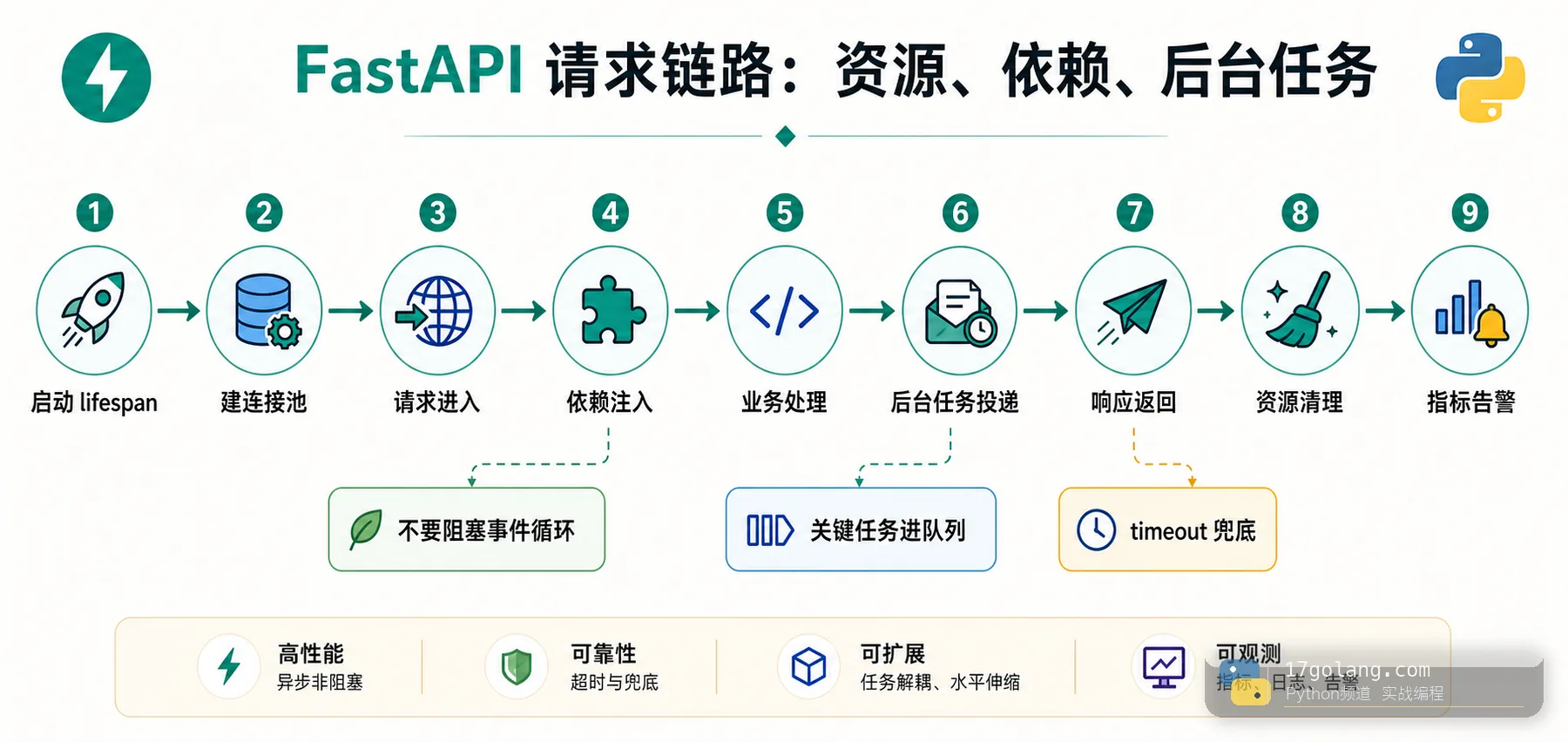
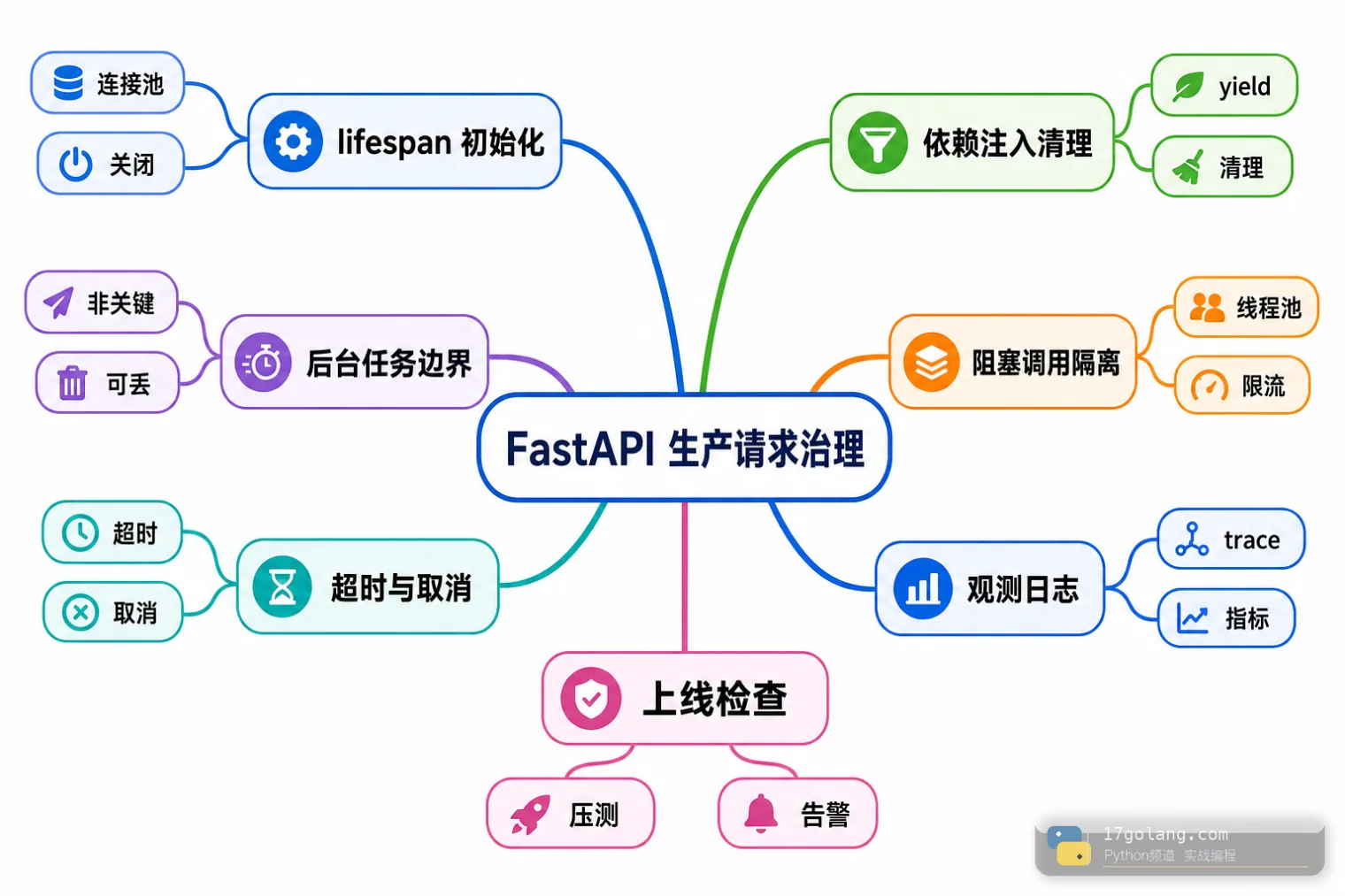
我排查 FastAPI 慢请求时会先把链路拆成四块:应用启动/关闭、请求进入/依赖注入、业务处理/外部调用、响应之后的副作用。拆完以后,哪些工作该放进请求内,哪些必须移出去,就清楚很多。
第一刀:用 lifespan 管应用级资源
连接池、HTTP 客户端、模型句柄、缓存客户端这类对象,不应该在每次请求里临时创建,也不应该靠模块 import 时偷偷初始化。更稳的做法是在应用 lifespan 里创建,在关闭时释放。
from contextlib import asynccontextmanager
import httpx
from fastapi import FastAPI, Request
@asynccontextmanager
async def lifespan(app: FastAPI):
app.state.notify_client = httpx.AsyncClient(
base_url="https://notify.internal",
timeout=httpx.Timeout(2.0, connect=0.5),
)
yield
await app.state.notify_client.aclose()
app = FastAPI(lifespan=lifespan)
def notify_client(request: Request) -> httpx.AsyncClient:
return request.app.state.notify_client
这个结构有两个好处:启动失败会尽早暴露,关闭时资源能正常释放。线上服务最怕“请求里第一次用才发现连接池建不起来”,也怕滚动发布时旧进程带着未关闭连接慢慢退出。
第二刀:异步接口里不要直接跑阻塞函数
如果依赖还没换成异步版本,至少先把阻塞函数隔离到线程池。Starlette 提供的 run_in_threadpool 是 FastAPI 项目里常见的兜底手段,但它不是无限资源,仍然要配合限流、超时和监控。
from starlette.concurrency import run_in_threadpool
@app.get("/orders/{order_id}/export")
async def export_order(order_id: str):
rows = await run_in_threadpool(query_orders_from_db, order_id)
file_url = await run_in_threadpool(build_excel, rows)
return {"file_url": file_url}
我通常把这一步当过渡方案:先止血,让事件循环不被卡死;下一步再评估是否替换异步数据库驱动、拆分导出任务,或者把大文件生成挪到独立 worker。
第三刀:BackgroundTasks 不是任务队列
BackgroundTasks 的定位很实用:响应返回后做一点小副作用,比如写访问日志、轻量通知、清理临时文件。但它不适合承载关键业务状态变更。进程被杀、任务异常、实例重启、发布滚动,都可能让你失去可追踪性。
from fastapi import BackgroundTasks
def cleanup_tmp_file(path: str) -> None:
remove_file_if_exists(path)
@app.post("/reports")
async def create_report(background_tasks: BackgroundTasks):
path = await run_in_threadpool(render_small_report)
background_tasks.add_task(cleanup_tmp_file, path)
return {"path": path}
如果任务影响订单状态、扣款、发货、结算、重要通知,我会把它投递到有持久化和重试能力的队列里。Celery、RQ、Arq 都可以,具体选型另说;关键原则是:关键任务要能记录、重试、告警、补偿,不能只挂在一次 HTTP 响应后面。

第四刀:所有外部调用都要有超时
Python API 服务慢下来,很多时候不是自己代码慢,而是等下游等到天荒地老。外部 HTTP、RPC、数据库、缓存都要有明确 timeout。没有 timeout 的调用,本质上是在把你的 worker 借给别人无限使用。
from typing import Annotated
import httpx
from fastapi import Depends, HTTPException, Request
async def get_notify_client(request: Request) -> httpx.AsyncClient:
return request.app.state.notify_client
@app.post("/orders/{order_id}/notify")
async def notify_order(
order_id: str,
client: Annotated[httpx.AsyncClient, Depends(get_notify_client)],
):
try:
resp = await client.post("/messages", json={"order_id": order_id})
resp.raise_for_status()
except httpx.TimeoutException as exc:
raise HTTPException(status_code=504, detail="notify timeout") from exc
return {"ok": True}
这里我没有把异常吞掉。线上排障时,超时、连接失败、下游 5xx 要能被日志和指标看见。否则你看到的只是“业务偶尔没通知”,而不是“notify 服务 13:20 到 13:24 P99 飙高”。
诊断步骤:从事件循环被阻塞开始查
如果线上 FastAPI 服务出现“一个慢接口拖慢所有接口”,我会按这个顺序查:
- 打开 access log 和慢请求日志,按 path、P95、P99 排序。
- 检查慢接口里是否有同步 I/O、
time.sleep、大文件处理、CPU 密集循环。 - 检查
BackgroundTasks是否承担关键业务动作,失败是否可追踪。 - 检查 HTTP 客户端、数据库连接池是否在请求内重复创建。
- 检查所有下游调用是否有 timeout,异常是否进入日志、指标和告警。
- 用压测复现:一个慢导出接口并发打满时,健康检查和普通查询是否被拖慢。
上线检查清单
- 应用级资源统一放进
lifespan,关闭阶段释放连接池和客户端。 async def接口里禁止直接调用阻塞函数;临时方案用线程池隔离。- 线程池隔离要配合限流,不把大批 CPU/文件任务无限塞进去。
BackgroundTasks只做轻量、非关键、可容忍失败的副作用。- 关键任务进入持久化队列,具备重试、幂等、告警和补偿。
- 所有外部调用都有 connect/read timeout,异常能被日志和指标捕获。
- 压测必须包含慢接口和普通接口混合流量,观察是否互相拖累。
总结
FastAPI 的生产稳定性,不是把所有函数改成 async def 就结束了。真正要治理的是请求生命周期:启动时准备资源,请求中只做必要工作,阻塞调用隔离,响应后的后台任务守住边界,外部调用用 timeout 收口。
我的经验是:越是“顺手”的代码,越容易成为线上事故入口。顺手创建客户端、顺手跑同步导出、顺手把关键状态丢到后台任务,短期看省事,长期看都会在高并发和发布重启时还回来。把边界画清楚,FastAPI 才能既快又稳。
 Go HTTP 客户端超时实战:别让默认 Client 拖垮 goroutine
Go HTTP 客户端超时实战:别让默认 Client 拖垮 goroutine