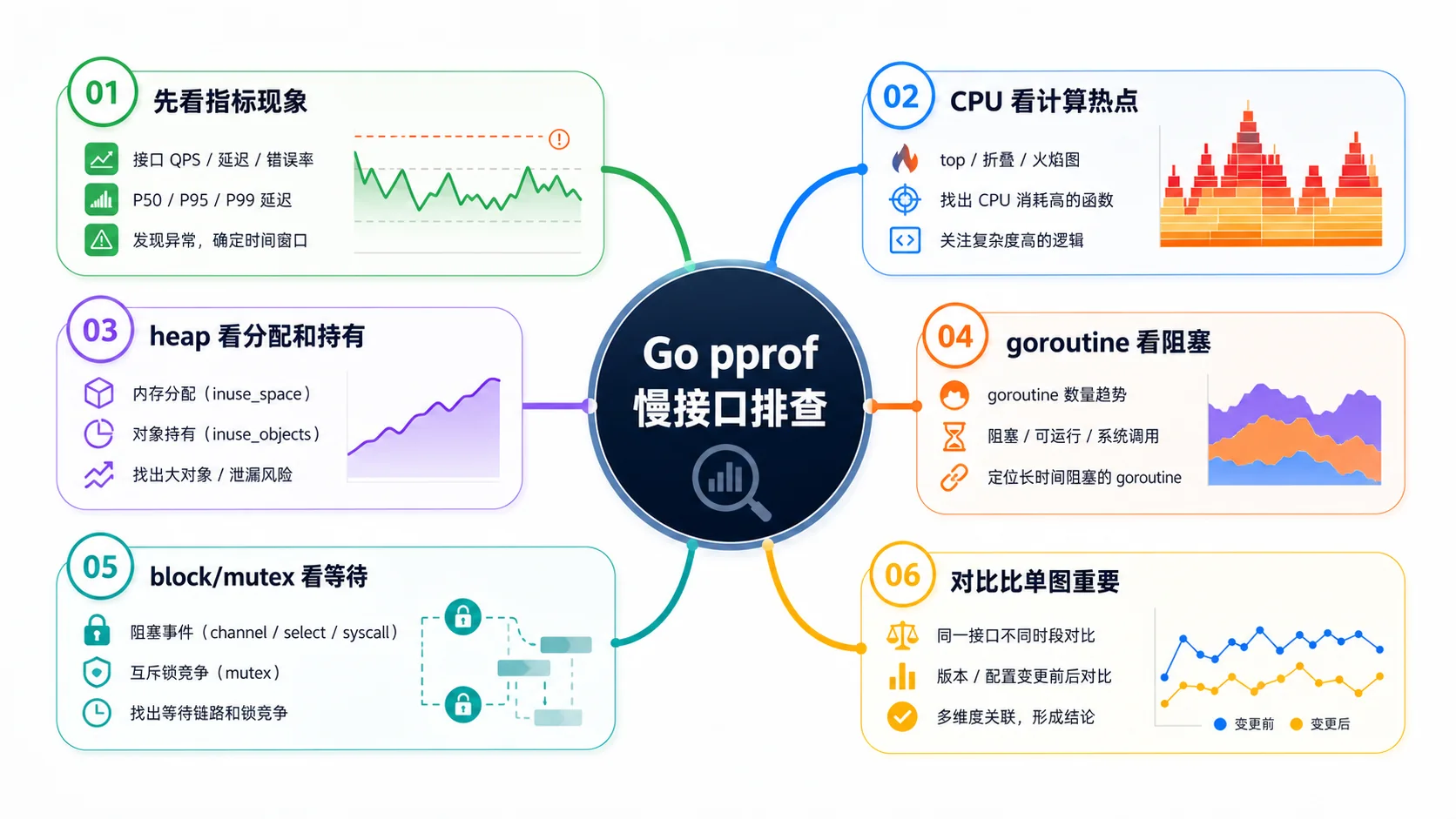
pprof 不是玄学工具,也不是打开火焰图就能自动给答案。我的习惯是先问清楚:慢的是 CPU、内存、锁等待、I/O,还是 goroutine 卡住?问题问错了,图看得越认真越容易跑偏。
这篇还是按我平时写博客的方式来:不堆概念,先讲为什么会踩坑,再讲怎么判断场景,最后给一份能落地的代码和 review 清单。你可以把它当成一篇上线前的自查笔记。
先看现象,不要直接开图
接口慢要先看延迟分位、错误率、CPU、GC、连接池、下游耗时。pprof 是证据,不是起点。
如果 CPU 不高却接口慢,你盯着 CPU profile 看半天,很可能什么也看不出来。
几个 profile 我怎么用
CPU profile 看谁在消耗计算;heap 看谁在分配和持有内存;goroutine 看谁卡在哪里;block 和 mutex 看等待。
线上抓 profile 要控制时间和频率,别为了排查把服务自己打趴下。
最常见的误判
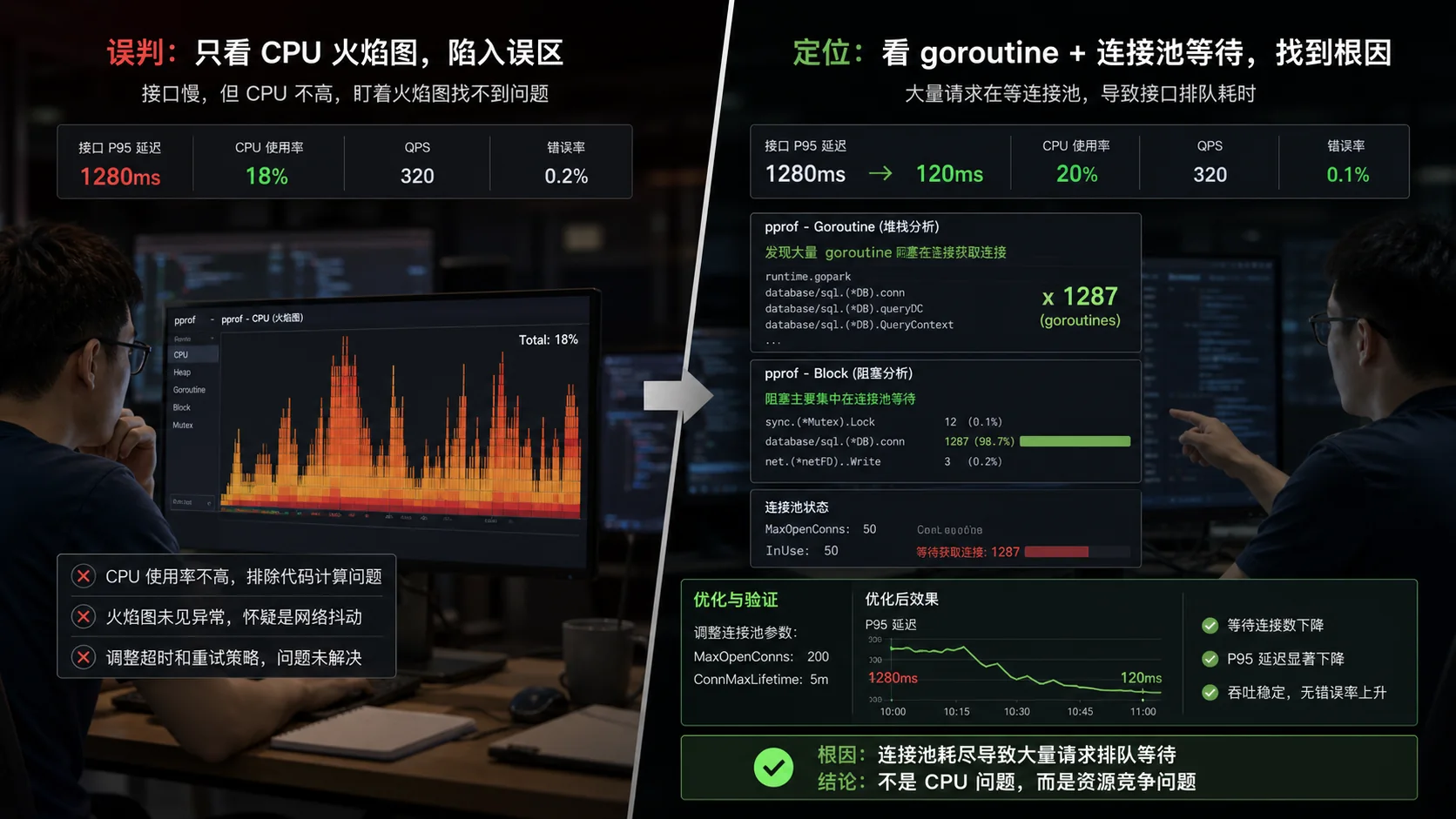
火焰图最宽的不一定是问题,它可能只是正常热点。要结合最近变更、流量路径和业务耗时。
我更喜欢对比:正常版本和异常版本、低峰和高峰、改动前和改动后。没有对比,profile 很容易变成猜谜。

代码案例:别只看能跑,要看能不能扛线上场景
下面这个对比是我在项目里经常会提醒团队注意的点。坏写法通常不是语法错,而是边界错:低并发没问题,高峰、失败、重试、超时一来就露馅。
我的 review 清单
- 这个改动解决的是指标里的真实问题,还是只是看起来更高级?
- 失败、超时、并发、重试这些场景下,代码有没有明确的退出路径?
- 有没有用 benchmark、pprof 或压测数据证明收益?
- 日志里能不能看出关键业务 id、错误原因和调用链位置?
- 这段代码半年后新人接手,能不能一眼看懂为什么这么写?
最后聊两句
案例:CPU 不高但接口慢,最后 goroutine profile 发现大量请求卡在连接池等待,不是算法慢。 这类问题最怕的不是不会修,而是上线前没人意识到它会发生。Go 的很多工具都很锋利,真正难的是知道什么时候该用,什么时候该忍住。
我的建议很简单:先写清楚,再用数据证明哪里慢,最后只在必要的位置优化。这样写出来的 Go 服务,通常比一开始就堆技巧更稳。
 Go error wrapping 实战:别让错误日志只剩一句 failed
Go error wrapping 实战:别让错误日志只剩一句 failed 






















