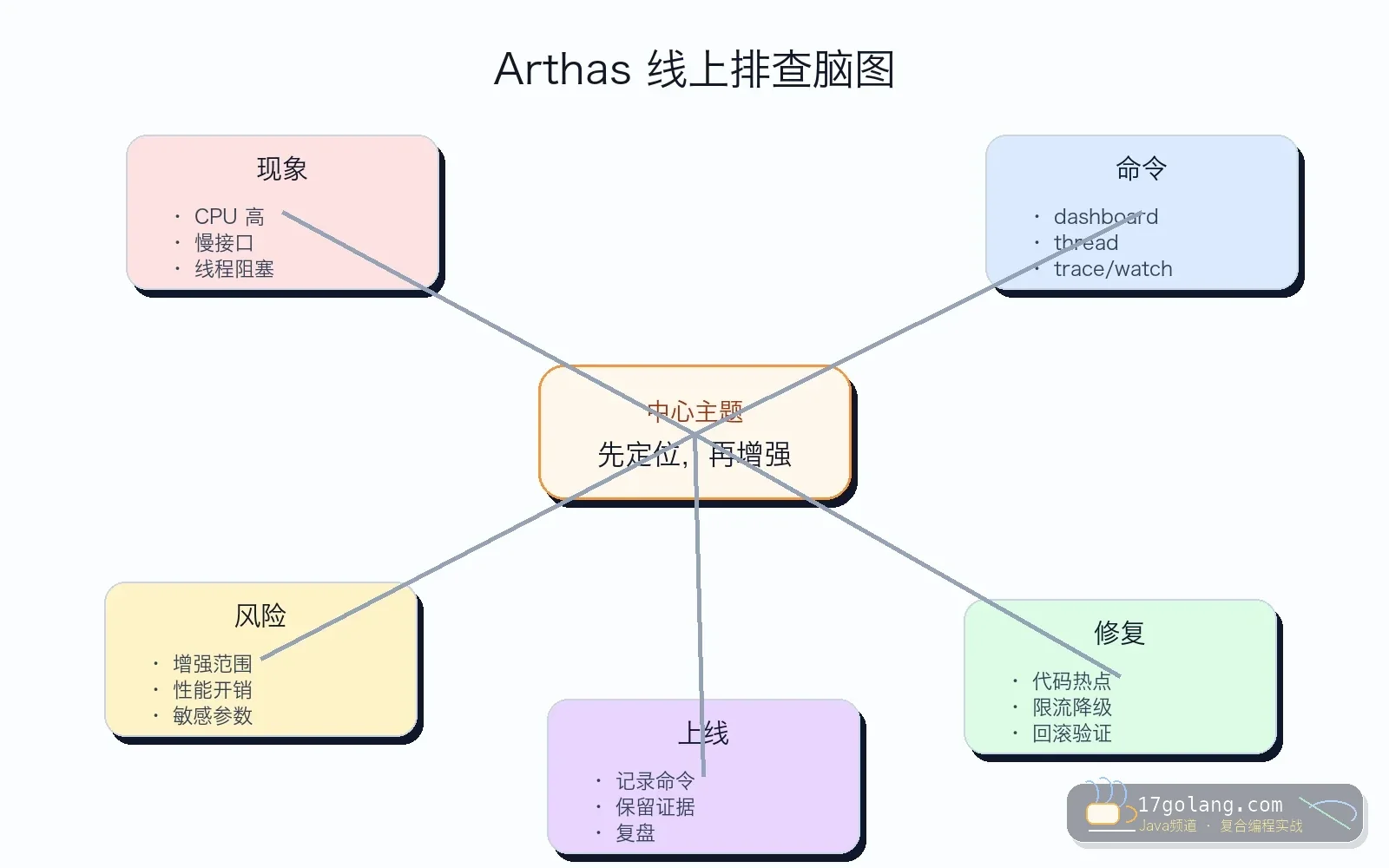
这篇写一个 Java 线上排查里很实用的场景:CPU 突然飙高,接口 p99 抬起来,日志没有明显异常。以前我们会先 jstack、top、grep 一通,现在如果机器允许接入 Arthas,可以更快把热点线程、慢方法和异常参数串起来。
本文适用于 Java 17/21、Spring Boot 线上服务、Arthas 3.x。资料只用于核对事实:Arthas 提供 dashboard、thread、trace、watch、profiler 等命令,能查看 JVM 运行状态、线程栈和方法调用耗时。正文按生产复盘写,不照搬命令手册。
业务场景:价格服务 CPU 飙高
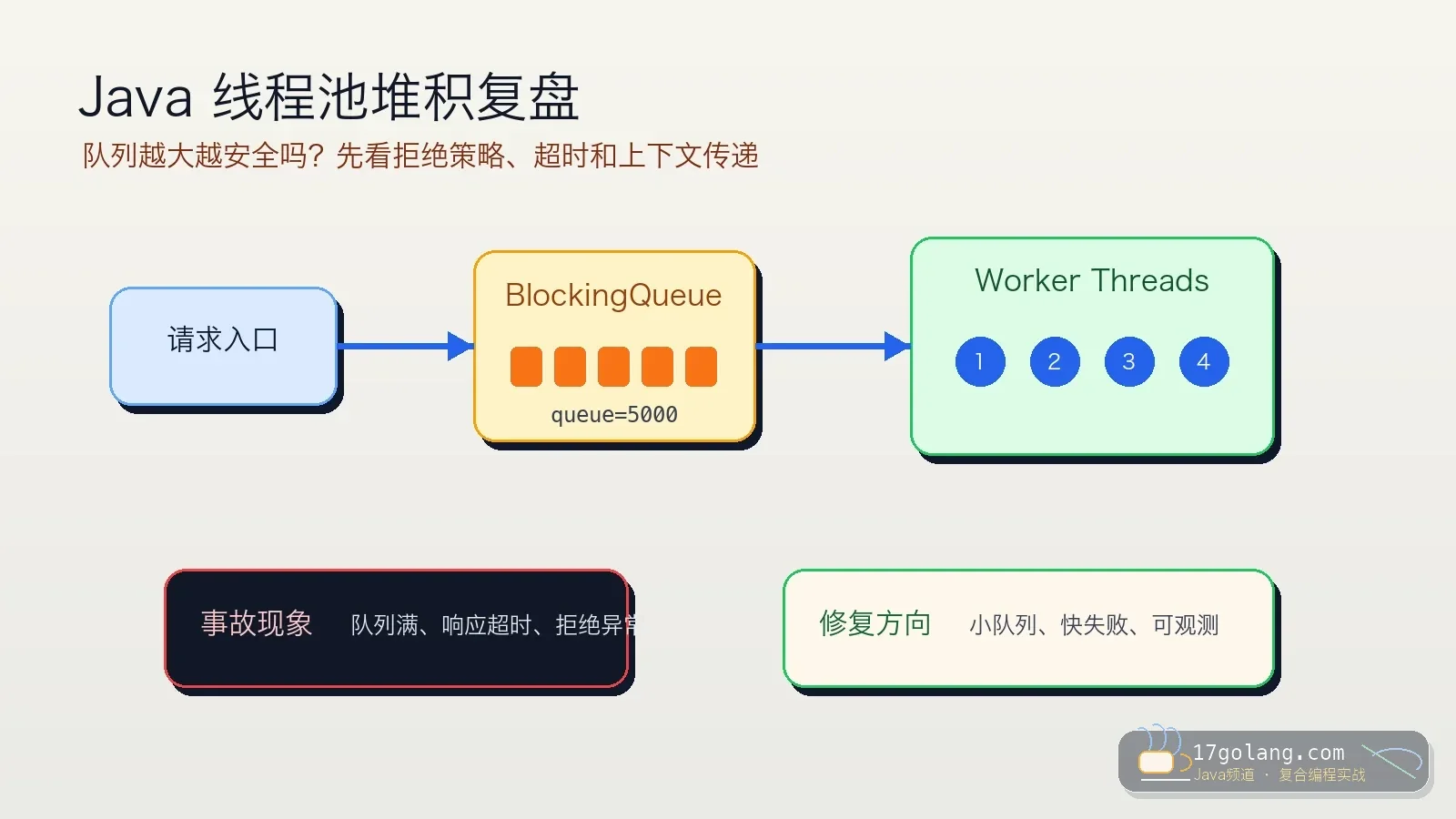
活动期间价格服务 CPU 从 40% 打到 160%,订单确认页 p99 从 120ms 变成 1.5s。GC 不明显,数据库没慢,线程池队列也没爆。业务日志只有大量正常请求,看不出哪段代码在烧 CPU。
这种场景不要急着重启。先保留现场,用 Arthas 进程内观察热点线程和方法耗时。目标不是炫命令,而是在最短时间回答三个问题:谁在烧 CPU?哪段方法慢?慢的时候参数有什么特征?
问题复现:一个 BigDecimal 热点藏在循环里
最后定位到价格计算里有一段折扣叠加逻辑,促销规则多时会在循环里反复创建 BigDecimal 并做除法,还触发了异常兜底分支。单次看不慢,高并发下就变成 CPU 热点。
这类问题用普通日志很难发现,因为每个请求都“成功”了。Arthas 的价值在于可以直接看热点线程栈,再对目标方法做小范围 trace。
踩坑原因:排查命令范围太大
Arthas 很强,但线上使用也有风险。最常见的错误是一上来就 trace com.demo..* * 或者 watch 整个包。增强范围太大,会带来额外开销,输出也会把终端刷爆。
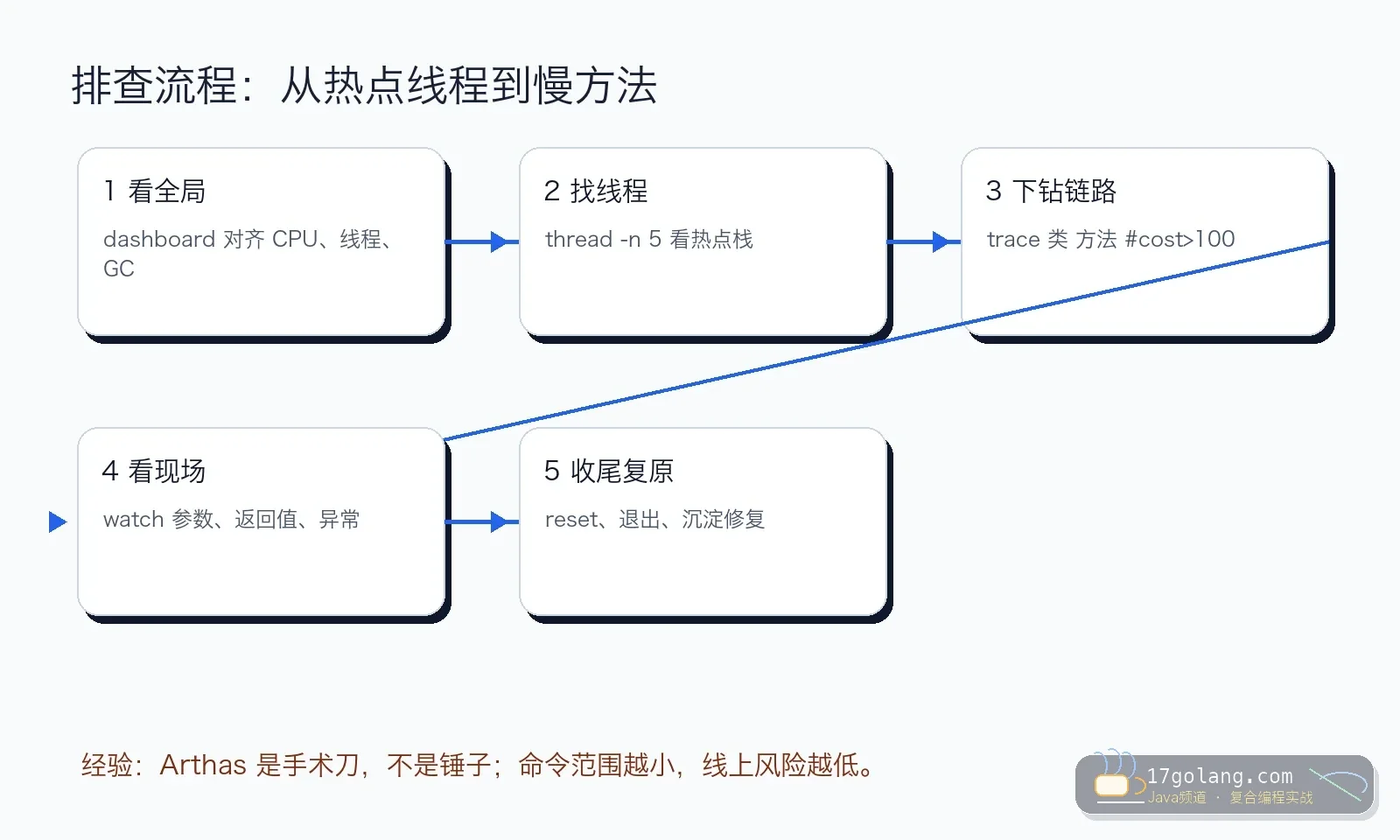
我的原则是从粗到细:先 dashboard 看整体,再 thread -n 5 找热点线程,确认类和方法后再 trace。每一步都缩小范围。
命令案例:小范围、短时间、可回收
下面的对比是我在生产环境最常提醒团队的点。Arthas 命令不是越猛越好,越精准越安全。

dashboard
thread -n 5 -i 1000
trace com.demo.price.PriceService calc '#cost>100' -n 5
watch com.demo.price.PriceService calc '{params, throwExp}' -n 3 -x 2
reset com.demo.price.PriceService
#cost>100 很关键,它能减少无意义输出,只看超过阈值的调用。-n 控制次数,-x 控制对象展开深度,排查完记得 reset 清理增强类。
诊断步骤:我会这样操作
第一步,确认目标进程。 接入 Arthas 前先确认 PID、应用版本、机器是否正在承载核心流量。高峰期动作要更克制。
第二步,看 dashboard。 先看 CPU、线程、内存、GC、运行时间,确认是 Java 应用内问题,还是系统层资源问题。
第三步,找热点线程。 用 thread -n 5 -i 1000 采样热点线程。注意 Arthas 里的线程 CPU 是采样区间内的增量占比。
第四步,下钻 trace。 只 trace 明确的类和方法,并加 #cost 条件。Arthas trace 适合找第一层调用耗时,必要时再逐层下钻。
第五步,用 watch 看现场。 只看必要参数、返回值和异常,不要展开大对象,也不要打印敏感字段。
第六步,沉淀修复。 排查命令、截图、热点栈、修复 PR、灰度指标都要留档,避免下次重新摸黑。
上线检查:工具接入也要守规矩
- 生产执行 Arthas 前确认权限、审计和应急窗口。
- 命令范围必须具体到类和方法,避免全包增强。
- watch 参数时注意脱敏,不打印 token、手机号、身份证等敏感值。
- 排查结束执行
reset,确认增强类已清理。 - 把热点方法补上指标、压测和单元/性能回归。
我的经验总结
Arthas 最适合解决“现在线上到底发生了什么”这个问题。它不是替代日志、指标、JFR,而是补上临场观察能力。用得好,十分钟能定位;用得猛,也可能把现场搅乱。
我的建议是把命令当手术刀:范围小、时间短、证据清楚、排查完复原。Java 生产排查的高级感,不是命令背得多,而是知道什么时候该停手。
 Python Flask 实战:别把请求上下文当全局变量用
Python Flask 实战:别把请求上下文当全局变量用