有次支付网关接口抖动,团队第一反应是“加 Retry”。结果重试一开,平均耗时没降,p99 反而飙得更高,连接池也开始排队。问题不是 Resilience4j 不好用,而是 Timeout、Retry、CircuitBreaker、Bulkhead 的边界没算清楚。
Resilience4j 官方支持在 Spring Boot 里配置 CircuitBreaker、Retry、RateLimiter、Bulkhead、TimeLimiter 等实例。资料可以帮我们核对能力,但线上真正难的是:什么错误该重试,超时预算怎么算,熔断统计看到的是哪一层失败,fallback 会不会把真实问题吞掉。
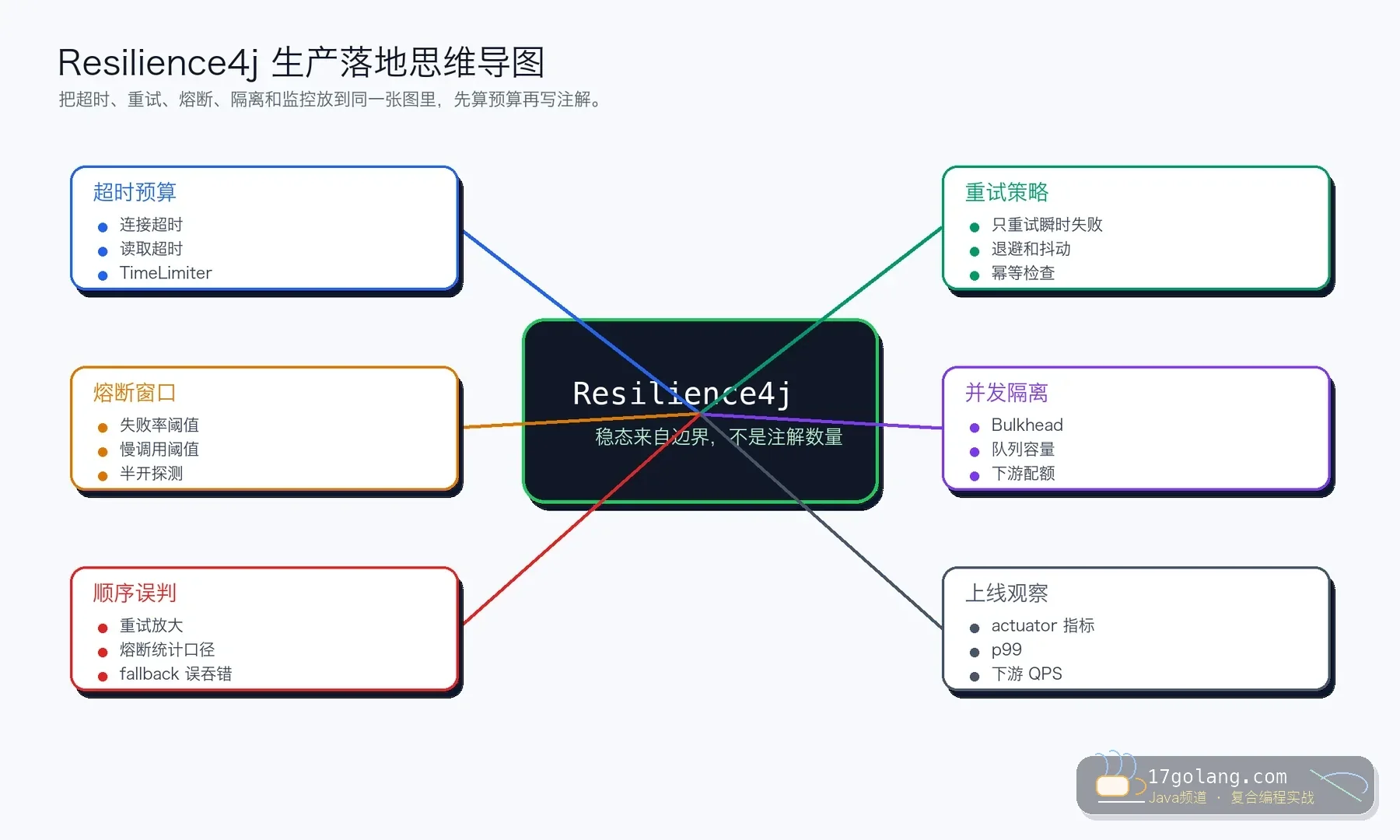
先问:这个调用能不能重试
查询类接口、幂等写接口、明确支持 requestId 去重的下游,才适合重试。扣款、发券、创建订单这类操作,如果没有幂等键,重试就是风险。很多事故不是没有重试,而是把不该重试的失败重试了。
我会把重试限制在连接瞬断、少量 5xx、短暂网络抖动这类瞬时失败上。下游已经过载、响应已经超过业务预算、或者返回明确业务错误时,不应该继续重试。
超时预算要早于重试次数
如果用户接口 SLA 是 1 秒,下游一次调用 800ms,还配置 3 次重试,那光等待就可能超过 2 秒。正确顺序是先算总预算,再拆单次超时、等待间隔和最大尝试次数。
resilience4j:
timelimiter:
instances:
payClient:
timeout-duration: 700ms
retry:
instances:
payClientRetry:
max-attempts: 2
wait-duration: 100ms
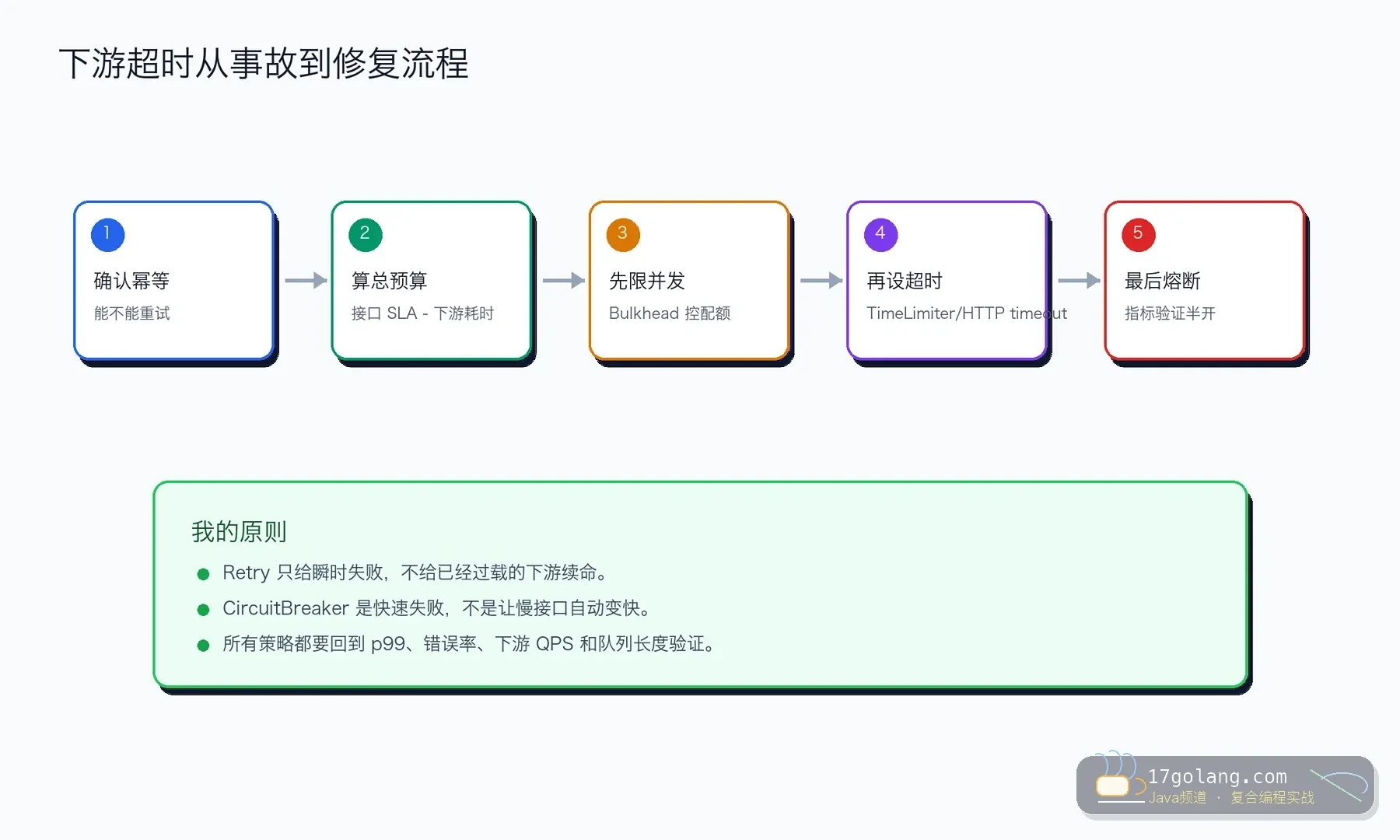
熔断不是让慢接口变快
CircuitBreaker 的价值是快速失败,避免每个请求都继续打到已经明显异常的下游。它不会让慢接口自动恢复,也不该替代连接池、线程池和 Bulkhead。下游慢时,先限制并发入口,再用熔断保护调用方。
还有一个常见误判:重试放在熔断里面还是外面,统计口径不一样。你看到的失败率,可能是每次尝试的失败率,也可能是一次业务调用的失败率。上线前要用压测把指标解释清楚。

上线检查清单
- 调用是否幂等,是否有 requestId 或业务去重机制?
- 总超时预算是否覆盖单次超时、重试次数和等待间隔?
- Bulkhead 的并发数是否和下游配额、连接池容量匹配?
- CircuitBreaker 的 slow call 阈值是否贴近业务 SLA?
- fallback 是否区分超时、熔断、限流、业务失败,而不是统一返回空对象?
- Actuator/Micrometer 指标是否能看到重试次数、熔断状态和队列长度?
最后聊两句
Resilience4j 不是给接口贴几层注解就能自动稳定。它真正帮你做的是把边界显式化:最多等多久,最多并发多少,什么失败算失败,什么时候快速拒绝。
我的建议是:先写清楚业务预算,再配置技术策略。能不重试就不重试,必须重试就证明它幂等、短促、可观测。这样熔断和重试才是保护,而不是新事故的放大器。
 Go race detector 实战:别让数据竞争混进线上服务
Go race detector 实战:别让数据竞争混进线上服务