阿里巨型模型再次开源!图像理解与物体识别功能一应俱全,基于通用问题集7B训练,商业应用可行
积累知识,胜过积蓄金银!毕竟在科技周边开发的过程中,会遇到各种各样的问题,往往都是一些细节知识点还没有掌握好而导致的,因此基础知识点的积累是很重要的。下面本文《阿里巨型模型再次开源!图像理解与物体识别功能一应俱全,基于通用问题集7B训练,商业应用可行》,就带大家讲解一下知识点,若是你对本文感兴趣,或者是想搞懂其中某个知识点,就请你继续往下看吧~
阿里巴巴开源了一个新的大模型,非常令人兴奋~
继通义千问-7B(Qwen-7B)之后,阿里云又推出了大规模视觉语言模型Qwen-VL,并且一上线就直接开源。

Qwen-VL是一种基于通义千问-7B的多模态大模型,具体而言,它支持图像、文本和检测框等多种输入,并且不仅仅可以输出文本,还可以输出检测框
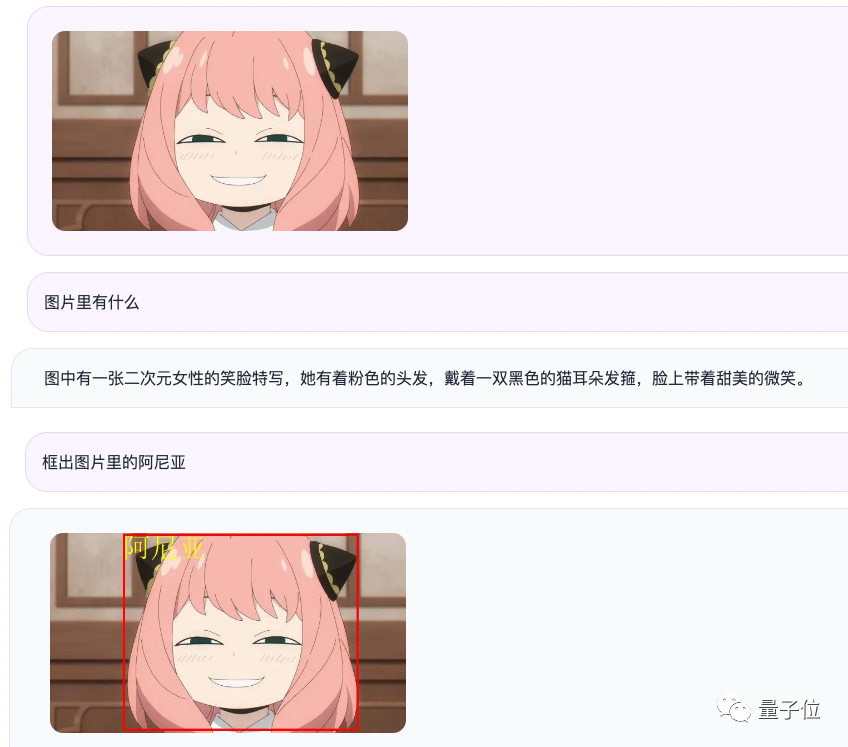
举个例子,我们输入一张阿尼亚的图片,通过问答的形式,Qwen-VL-Chat能够总结图片内容,并且能够准确地定位到图片中的阿尼亚
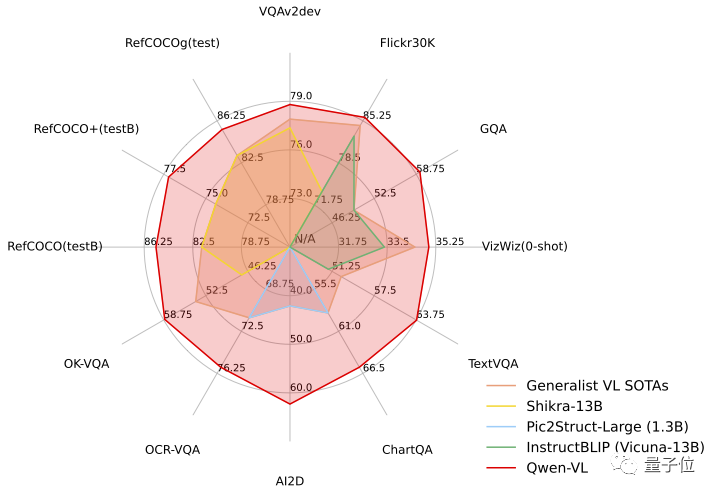
在测试任务中,Qwen-VL展现出了“六边形战士”的实力,在四大类多模态任务的标准英文测评中(Zero-shot Caption/VQA/DocVQA/Grounding)上,都取得了最先进的成果
一经开源消息传出,立刻引起了广泛关注

让我们一起来看看具体的表现如何吧!
首个支持中文开放域定位的通用模型
首先,让我们来整体看一下Qwen-VL系列模型的特点:
- 多语言对话:支持多语言对话,端到端支持图片里中英双语的长文本识别;
- 多图交错对话:支持多图输入和比较,指定图片问答,多图文学创作等;
- 首个支持中文开放域定位的通用模型:通过中文开放域语言表达进行检测框标注,也就是能在画面中精准地找到目标物体;
- 细粒度识别和理解:相比于目前其它开源LVLM(大规模视觉语言模型)使用的224分辨率,Qwen-VL是首个开源的448分辨率LVLM模型。更高分辨率可以提升细粒度的文字识别、文档问答和检测框标注。
在不改变原意的情况下,需要重写的内容是:Qwen-VL可以在知识问答、图像问答、文档问答、细粒度视觉定位等场景中使用
例如,有一个外国朋友不懂中文去医院看病,对着导览图感到困惑,不知道如何前往相应的科室,可以直接将图和问题交给Qwen-VL,让它根据图片信息充当翻译

再次进行多图输入和比较的测试
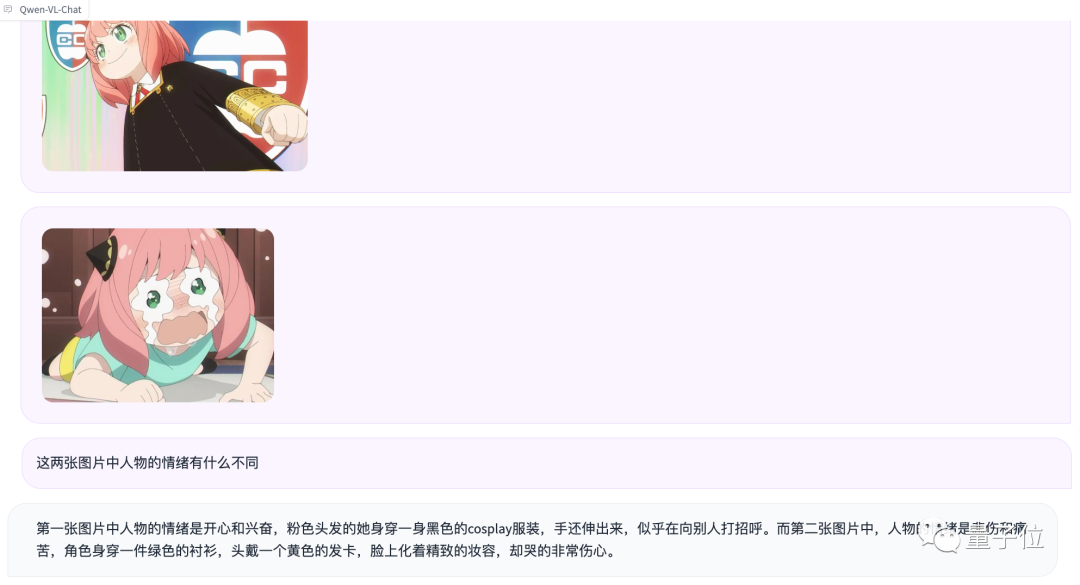
尽管没有认出阿尼亚,但情绪判断确实相当准确(手动狗头)
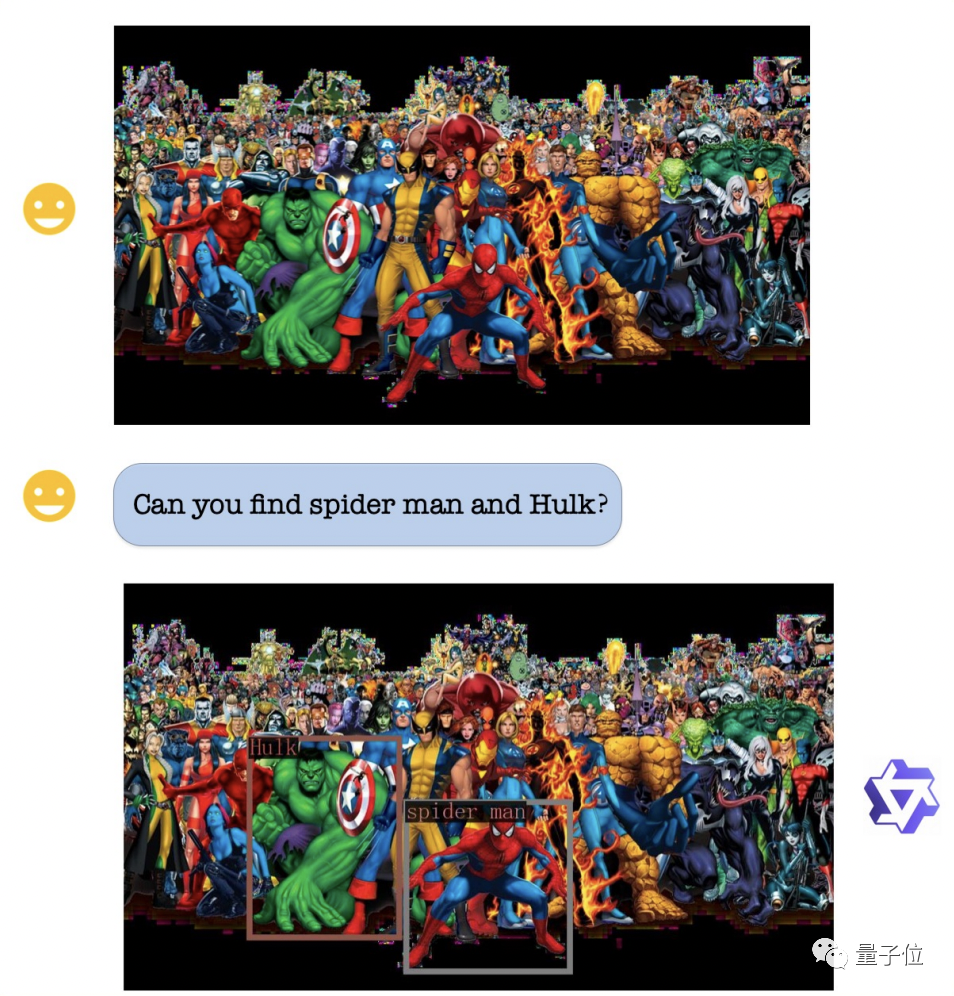
在视觉定位能力方面,即使图片非常复杂且人物众多,Qwen-VL仍然可以根据要求准确地找出绿巨人和蜘蛛侠
Qwen-VL在技术细节上以Qwen-7B为基座语言模型,并通过引入视觉编码器ViT和位置感知的视觉语言适配器,使得模型能够支持视觉信号输入
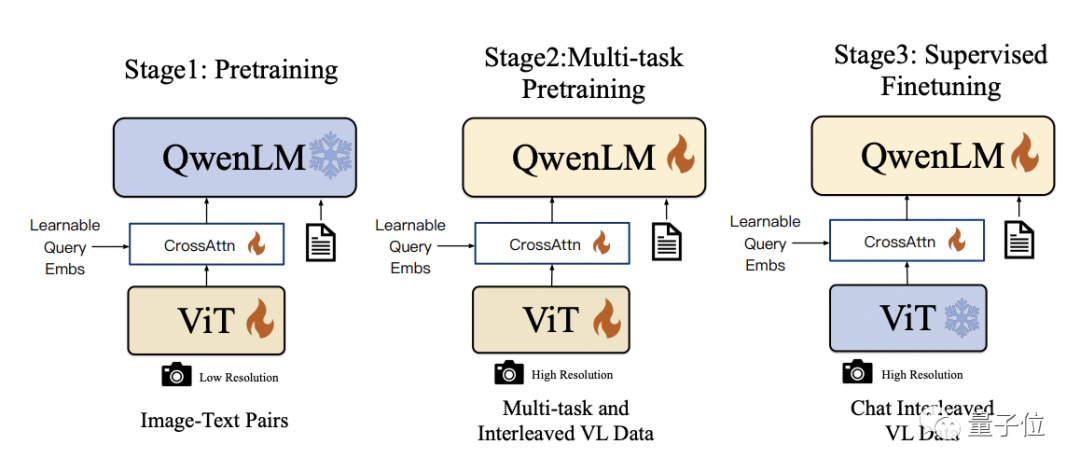
具体的训练过程分为三步:
- 预训练:只优化视觉编码器和视觉语言适配器,冻结语言模型。使用大规模图像-文本配对数据,输入图像分辨率为224x224。
- 多任务预训练:引入更高分辨率(448x448)的多任务视觉语言数据,如VQA、文本VQA、指称理解等,进行多任务联合预训练。
- 监督微调:冻结视觉编码器,优化语言模型和适配器。使用对话交互数据进行提示调优,得到最终的带交互能力的Qwen-VL-Chat模型。
在Qwen-VL的标准英文测评中,研究人员对四大类多模态任务(Zero-shot Caption/VQA/DocVQA/Grounding)进行了测试
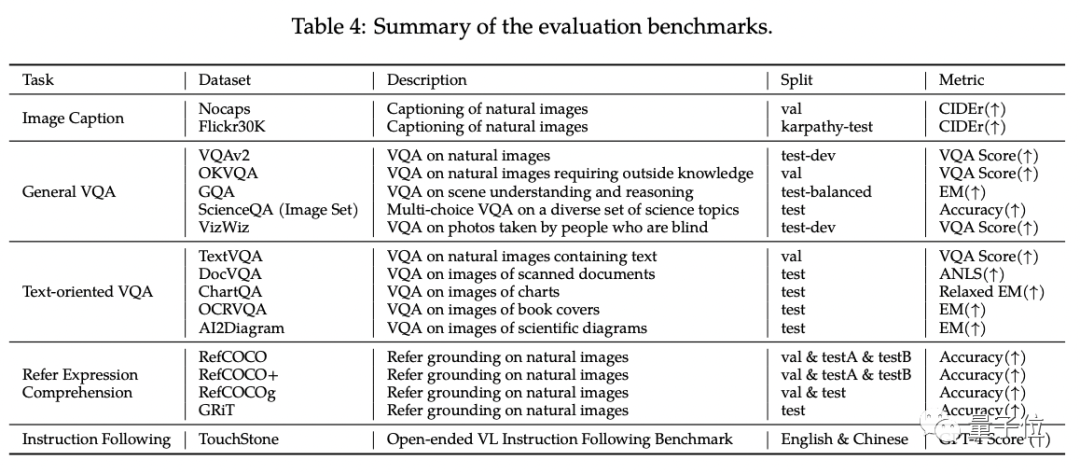
根据结果显示,Qwen-VL在与同等尺寸的开源LVLM进行比较时取得了最佳效果
另外,研究人员构建了一套基于GPT-4打分机制的测试集TouchStone。


Qwen-VL-Chat在这项对比测试中取得了最先进技术水平(SOTA)
如果你对Qwen-VL感兴趣,你可以在魔搭社区和huggingface上找到demo来直接试玩。链接在文末提供
Qwen-VL支持研究人员和开发者进行二次开发,并且允许商业使用。但需要注意的是,如果要进行商业使用,需要先填写问卷申请
项目链接:https://modelscope.cn/models/qwen/Qwen-VL/summary
https://modelscope.cn/models/qwen/Qwen-VL-Chat/summary
https://huggingface.co/Qwen/Qwen-VL
https://huggingface.co/Qwen/Qwen-VL-Chat
https://github.com/QwenLM/Qwen-VL
请点击以下链接查看论文:https://arxiv.org/abs/2308.12966
以上就是《阿里巨型模型再次开源!图像理解与物体识别功能一应俱全,基于通用问题集7B训练,商业应用可行》的详细内容,更多关于开源,模型的资料请关注golang学习网公众号!
 30秒内轻松完成3D模型纹理贴图,简单高效!
30秒内轻松完成3D模型纹理贴图,简单高效!
- 上一篇
- 30秒内轻松完成3D模型纹理贴图,简单高效!

- 下一篇
- 中国低价产品冲击韩国餐厅机器人市场,本土企业面临存亡挑战
-

- 科技周边 · 人工智能 | 2星期前 | AI绘画
- AI绘画工具安装与配置教程
- 339浏览 收藏
-

- 科技周边 · 人工智能 | 2星期前 |
- 海螺AI语音功能测评与体验分享
- 260浏览 收藏
-

- 科技周边 · 人工智能 | 2星期前 |
- ChatGPT读不了加密PDF?先解密再上传
- 438浏览 收藏
-

- 科技周边 · 人工智能 | 2星期前 |
- 千问AI测试规范与覆盖率提升技巧
- 152浏览 收藏
-

- 科技周边 · 人工智能 | 2星期前 |
- MiniMaxMusic2.0专业模式上线:音乐创作新神器
- 232浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- TRAE Work
- TRAE AI IDE | 国内首款 AI 原生集成开发环境,深度集成 Doubao-1.5-pro 与 DeepSeek 模型,支持中文自然语言一键生成完整代码框架,实时预览前端效果并智能修复 BUG。首创 Builder 模式实现需求到代码的自动化开发,兼容 Windows/macOS 系统,官网下载即用。
- 24次使用
-

- MeloLab
- MeloLab 是一款 AI 音乐生成工具,可根据文本创意生成歌曲、人声、混音、分轨和背景音乐,适合创作者快速制作音乐素材。
- 23次使用
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 8670次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 9083次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 8912次使用
-
- GPT-4王者加冕!读图做题性能炸天,凭自己就能考上斯坦福
- 2023-04-25 501浏览
-
- 单块V100训练模型提速72倍!尤洋团队新成果获AAAI 2023杰出论文奖
- 2023-04-24 501浏览
-
- ChatGPT 真的会接管世界吗?
- 2023-04-13 501浏览
-
- VR的终极形态是「假眼」?Neuralink前联合创始人掏出新产品:科学之眼!
- 2023-04-30 501浏览
-
- 实现实时制造可视性优势有哪些?
- 2023-04-15 501浏览


