大模型迎来「开源季」,盘点过去一个月那些开源的LLM和数据集
IT行业相对于一般传统行业,发展更新速度更快,一旦停止了学习,很快就会被行业所淘汰。所以我们需要踏踏实实的不断学习,精进自己的技术,尤其是初学者。今天golang学习网给大家整理了《大模型迎来「开源季」,盘点过去一个月那些开源的LLM和数据集》,聊聊,我们一起来看看吧!
前段时间,谷歌泄露的内部文件表达了这样一个观点,虽然表面看起来 OpenAI 和谷歌在 AI 大模型上你追我赶,但真正的赢家未必会从这两家中产生,因为有一个第三方力量正在悄然崛起。这个力量就是「开源」。
围绕 Meta 的 LLaMA 开源模型,整个社区正在迅速构建与 OpenAI、谷歌大模型能力类似的模型,而且开源模型的迭代速度更快,可定制性更强,更有私密性。
近日,前威斯康星大学麦迪逊分校助理教授、初创公司 Lightning AI 首席 AI 教育官 Sebastian Raschka 表示,对于开源而言,过去一个月很伟大。
不过,那么多大语言模型(LLM)纷纷出现,要紧紧把握住所有模型并不容易。所以,Sebastian 在本文中分享了关于最新开源 LLM 和数据集的资源和研究洞见。
论文与趋势
过去一个月出现了很多研究论文,因此很难从中挑选出最中意的几篇进行深入的探讨。Sebastian 更喜欢提供额外洞见而非简单展示更强大模型的论文。鉴于此,引起他注意力的首先是 Eleuther AI 和耶鲁大学等机构研究者共同撰写的 Pythia 论文。

论文地址:https://arxiv.org/pdf/2304.01373.pdf
Pythia:从大规模训练中得到洞见
开源 Pythia 系列大模型真的是其他自回归解码器风格模型(即类 GPT 模型)的有趣平替。论文中揭示了关于训练机制的一些有趣洞见,并介绍了从 70M 到 12B 参数不等的相应模型。
Pythia 模型架构与 GPT-3 相似,但包含一些改进,比如 Flash 注意力(像 LLaMA)和旋转位置嵌入(像 PaLM)。同时 Pythia 在 800GB 的多样化文本数据集 Pile 上接受了 300B token 的训练(其中在常规 Pile 上训练 1 个 epoch,在去重 Pile 上训练 1.5 个 epoch )。
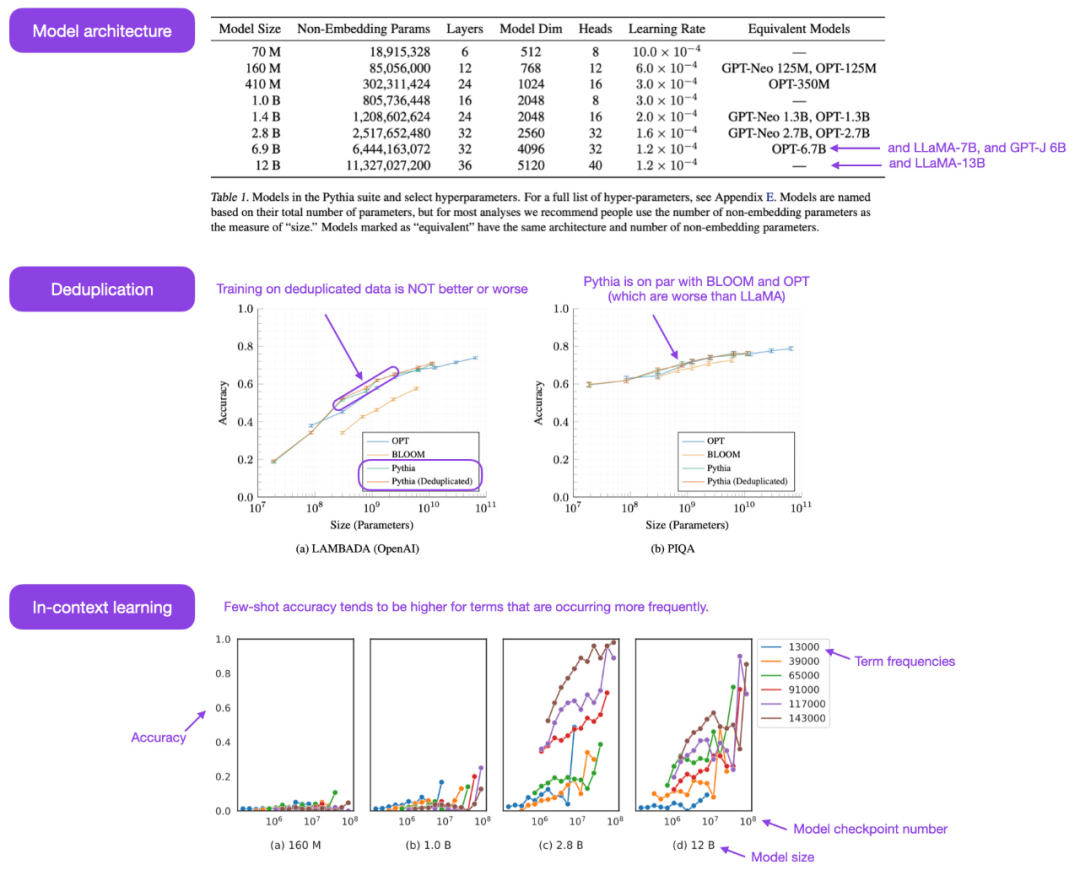
下面为一些从 Pythia 论文中得到的洞见和思考:
- 在重复数据上的训练(即训练 epoch>1)会不会有什么影响?结果表明,数据去重不会改善或损害性能;
- 训练命令会影响记忆吗?遗憾的是,结果表明并不会。之所以说遗憾,是因为如果影响的话,则可以通过训练数据的重新排序来减轻讨厌的逐字记忆问题;
- batch 大小加倍可以将训练时间减半但不损害收敛。
开源数据
对于开源 AI,过去一个月特别令人兴奋,出现了几个 LLM 的开源实现和一大波开源数据集。这些数据集包括 Databricks Dolly 15k、用于指令微调的 OpenAssistant Conversations (OASST1)、用于预训练的 RedPajama。这些数据集工作尤其值得称赞,因为数据收集和清理占了真实世界机器学习项目的 90%,但很少有人喜欢这项工作。
Databricks-Dolly-15 数据集
Databricks-Dolly-15 是一个用于 LLM 微调的数据集,它由数千名 DataBricks 员工编写了超过 15,000 个指令对(与训练 InstructGPT 和 ChatGPT 等系统类似)。
OASST1 数据集
OASST1 数据集用于在由人类创建和标注的类 ChatGPT 助手的对话集合上微调预训练 LLM,包含了 35 种语言编写的 161,443 条消息以及 461,292 个质量评估。这些是在超过 10,000 个完全标注的对话树中组织起来。
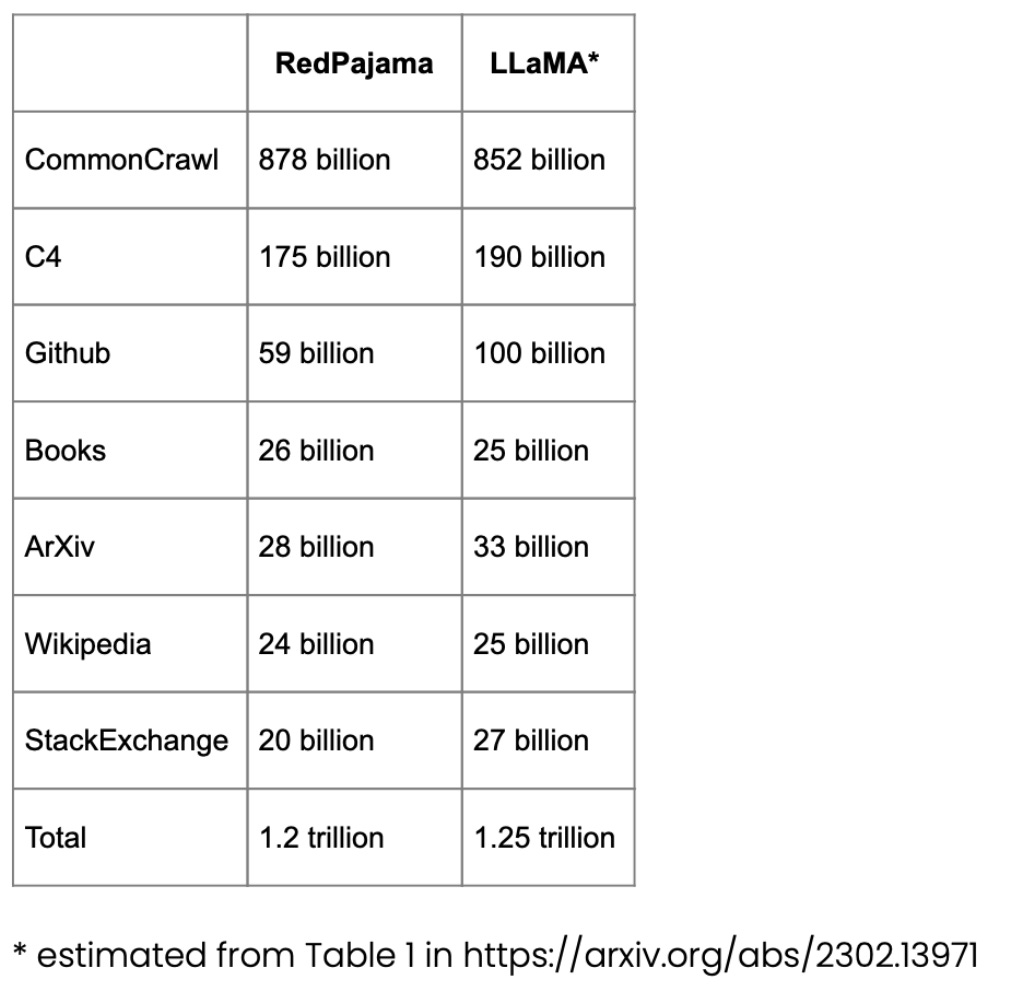
用于预训练的 RedPajama 数据集

RedPajama 是一个用于 LLM 预训练的开源数据集,类似于 Meta 的 SOTA LLaMA 模型。该数据集旨在创建一个媲美大多数流行 LLM 的开源竞争者,目前这些 LLM 要么是闭源商业模型要么仅部分开源。
RedPajama 的大部分由 CommonCrawl 组成,它对英文网站进行了过滤,但维基百科的文章涵盖了 20 种不同的语言。
LongForm 数据集
论文《The LongForm: Optimizing Instruction Tuning for Long Text Generation with Corpus Extraction》介绍了基于 C4 和 Wikipedia 等已有语料库的人工创作文档集合以及这些文档的指令,从而创建了一个适合长文本生成的指令调优数据集。
论文地址:https://arxiv.org/abs/2304.08460
Alpaca Libre 项目
Alpaca Libre 项目旨在通过将来自 Anthropics HH-RLHF 存储库的 100k + 个 MIT 许可演示转换为 Alpaca 兼容格式,以重现 Alpaca 项目。
扩展开源数据集
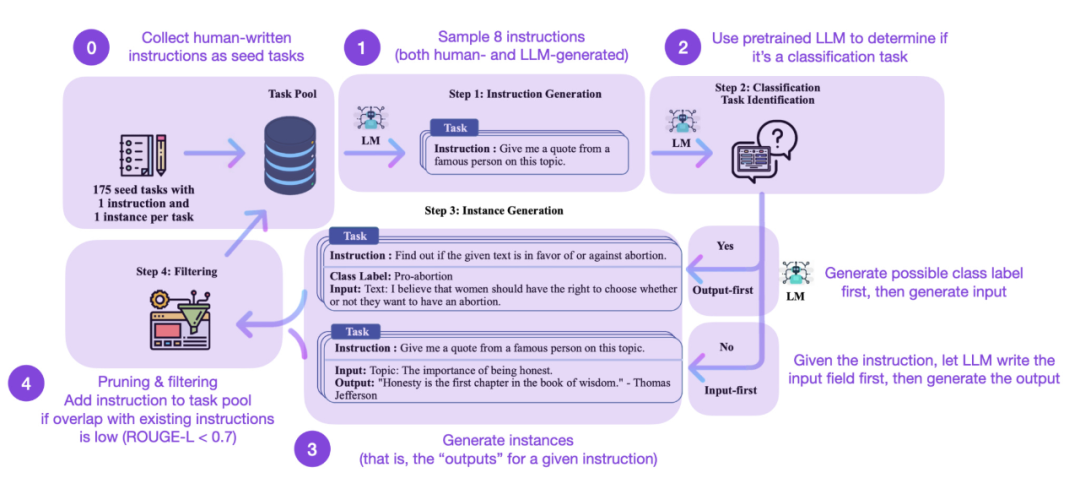
指令微调是我们从类 GPT-3 预训练基础模型演化到更强大类 ChatGPT 大语言模型的关键方式。Databricks-Dolly-15 等开源人工生成指令数据集有助于实现这一点。但我们如何进一步扩展呢?是否可以不收集额外数据呢?一种方法是从自身的迭代中bootstrap 一个 LLM。虽然 Self-Instruct 方法在 5 个月前提出(以如今标准来看过时了),但它仍是一种非常有趣的方法。值得强调的是,由于 Self-Instruct 一种几乎不需要注释的方法,因而可以将预训练 LLM 与指令对齐。
如何运作呢?简而言之可以分为以下四个步骤:
- 首先是具有一组人工编写指令(本例中为 175)和样本指令的种子任务池;
- 其次使用一个预训练 LLM(如 GPT-3)来确定任务类别;
- 接着给定新指令,使预训练 LLM 生成响应;
- 最后在将指令添加到任务池之前收集、修剪和过滤响应。
在实践中,基于 ROUGE 分数的工作会比较有效、例如 Self-Instruct 微调的 LLM 优于 GPT-3 基础 LLM,并可以在大型人工编写指令集上预训练的 LLM 竞争。同时 self-instruct 也可以使在人工指令上微调过的 LLM 收益。
但是当然,评估 LLM 的黄金标准是询问人类评分员。基于人类评估,Self-Instruct 优于基础 LLM、以及以监督方式在人类指令数据集上训练的 LLM(比如 SuperNI, T0 Trainer)。不过有趣的是,Self-Instruct 的表现并不优于通过人类反馈强化学习(RLHF)训练的方法。
人工生成 vs 合成训练数据集
人工生成指令数据集和 self-instruct 数据集,它们两个哪个更有前途呢?Sebastian 认为两者皆有前途。为什么不从人工生成指令数据集(例如 15k 指令的 databricks-dolly-15k)开始,然后使用 self-instruct 对它进行扩展呢?论文《Synthetic Data from Diffusion Models Improves ImageNet Classification》表明,真实图像训练集与 AI 生成图像相结合可以提升模型性能。探究对于文本数据是否也是这样是一件有趣的事情。
论文地址:https://arxiv.org/abs/2304.08466
最近的论文《Better Language Models of Code through Self-Improvement》就是关于这一方向的研究。研究者发现如果一个预训练 LLM 使用它自己生成的数据,则可以改进代码生成任务。
论文地址:https://arxiv.org/abs/2304.01228
少即是多(Less is more)?
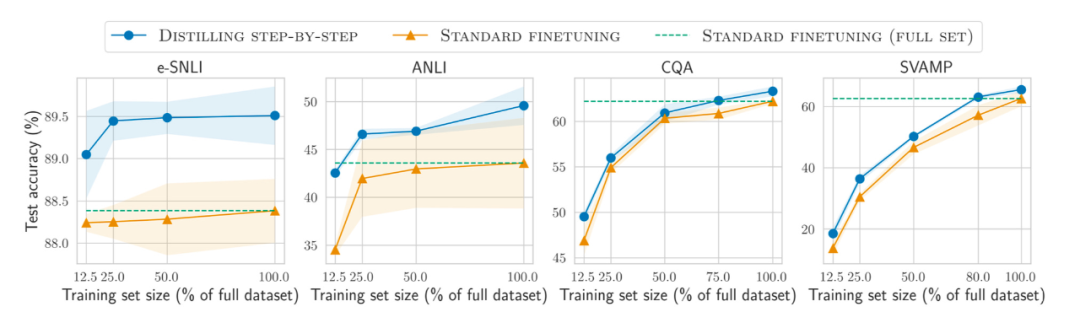
此外,除了在越来越大的数据集上预训练和微调模型之外,又如何提高在更小数据集上的效率呢?论文《Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes》中提出使用一种蒸馏机制来管理任务特定的更小模型,它们使用更少的训练数据却超越了标准微调的性能。
论文地址:https://arxiv.org/abs/2305.02301
追踪开源 LLM
开源 LLM 的数量呈爆炸式增长,一方面是非常好的发展趋势(相较于通过付费 API 控制模型),但另一方面追踪这一切可能很麻烦。以下四种资源提供了大多数相关模型的不同摘要,包括它们的关系、底层数据集和各种许可信息。
第一种资源是基于论文《Ecosystem Graphs: The Social Footprint of Foundation Models》的生态系统图网站,提供如下表格和交互式依赖图(这里未展示)。
这个生态系统图是 Sebastian 迄今为止见过的最全面的列表,但由于包含了很多不太流行的 LLM,因而可能显得有点混乱。检查相应的 GitHub 库发现,它已经更新了至少一个月。此外尚不清楚它会不会添加更新的模型。
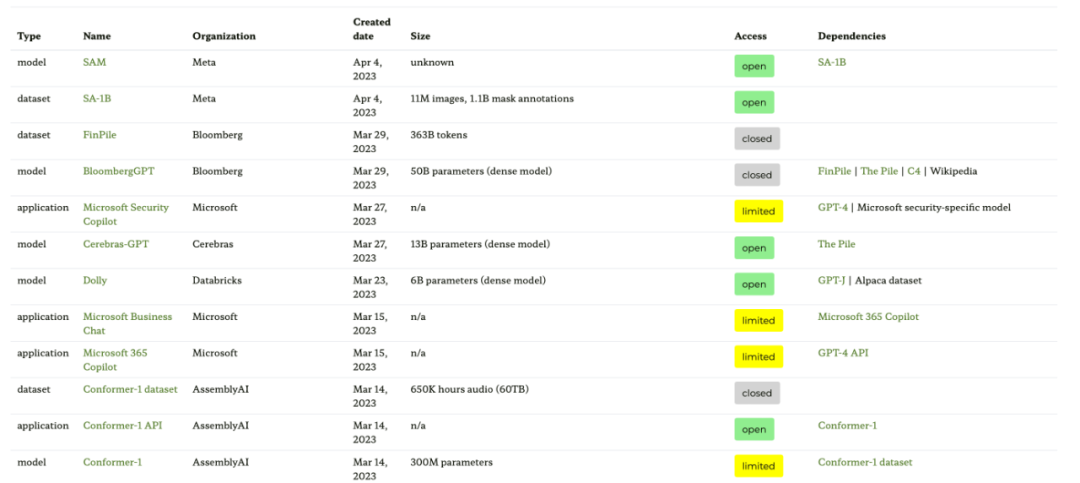
- 论文地址:https://arxiv.org/abs/2303.15772
- 生态系统图网站地址:https://crfm.stanford.edu/ecosystem-graphs/index.html?mode=table
第二种资源是最近论文《Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond》中绘制精美的进化树,该论文侧重于最流行的 LLM 和它们的关系。
虽然读者看到了非常美观和清晰的可视化 LLM 进化树,但也有一些小的疑惑。例如不清楚为什么底部没有从原始 transformer 架构开始。此外开源标签并不是非常的准确,例如 LLaMA 被列为开源,但权重在开源许可下不可用(只有推理代码是这样的)。
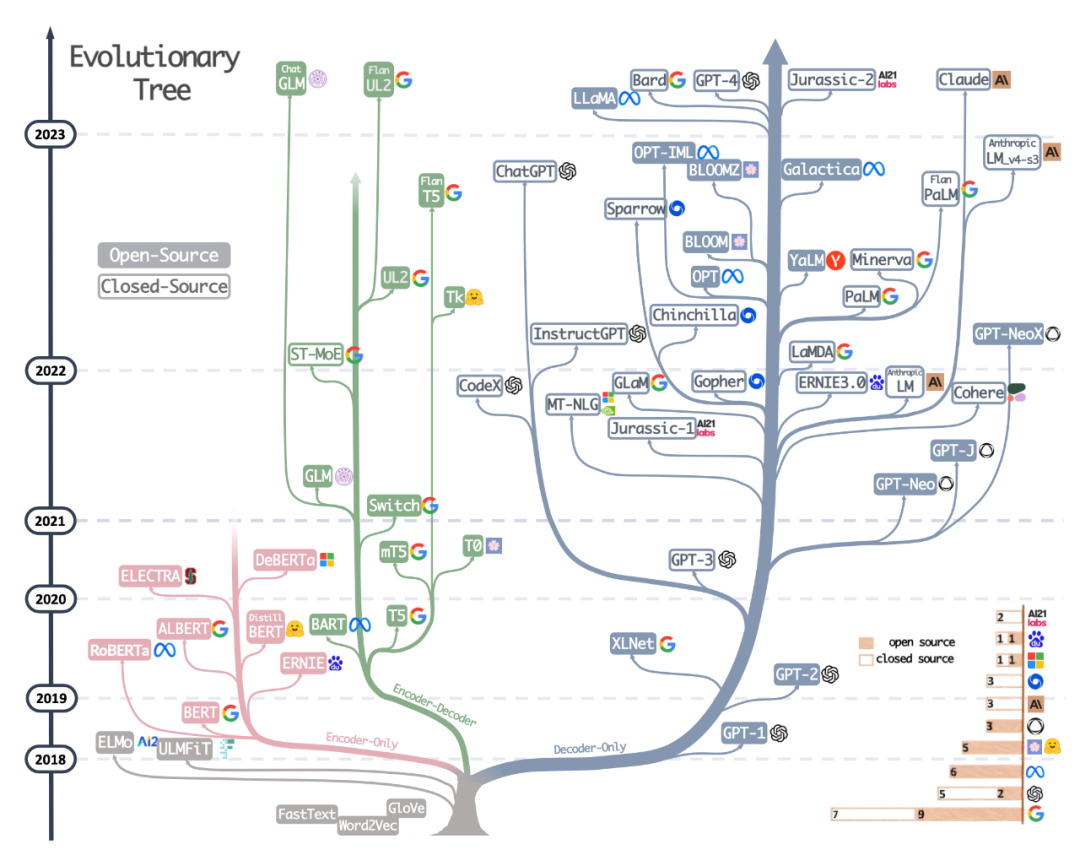
论文地址:https://arxiv.org/abs/2304.13712
第三种资源是 Sebastian 同事 Daniela Dapena 绘制的表格,出自于博客《The Ultimate Battle of Language Models: Lit-LLaMA vs GPT3.5 vs Bloom vs …》。
虽然下述表格比其他资源要小,但其优点在于包含了模型尺寸和许可信息。如果你计划在任何项目中采用这些模型,则该表格会非常有实用性。
博客地址:https://lightning.ai/pages/community/community-discussions/the-ultimate-battle-of-language-models-lit-llama-vs-gpt3.5-vs-bloom-vs/
第四种资源是 LLaMA-Cult-and-More 总览表,它提供了有关微调方法和硬件成本的额外信息。
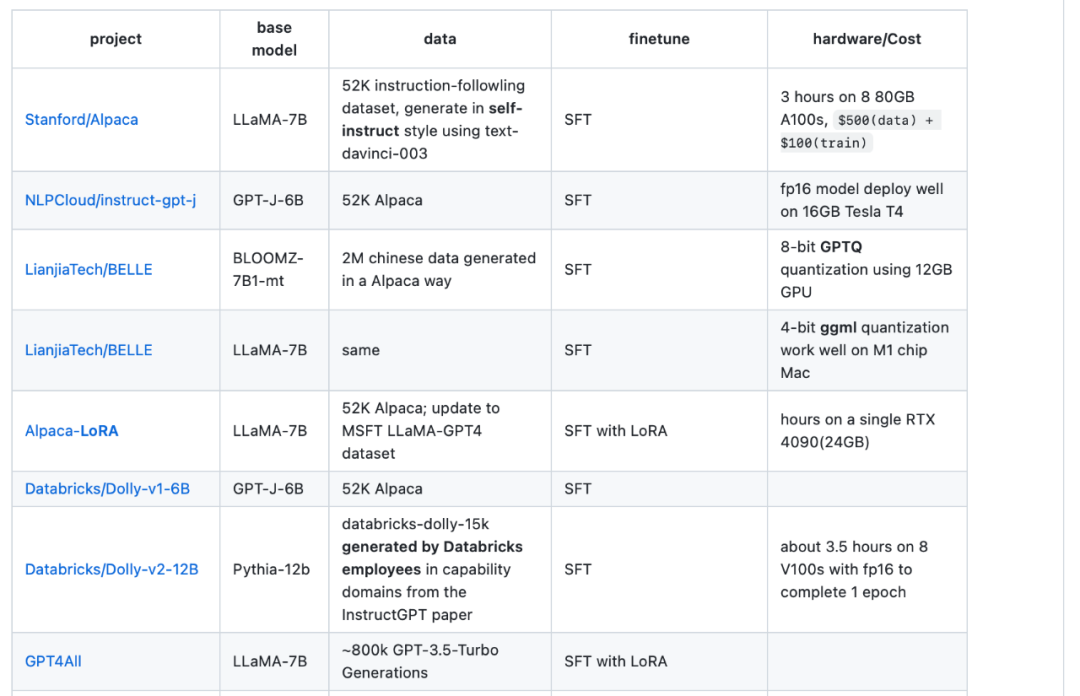
总览表地址:https://github.com/shm007g/LLaMA-Cult-and-More/blob/main/chart.md
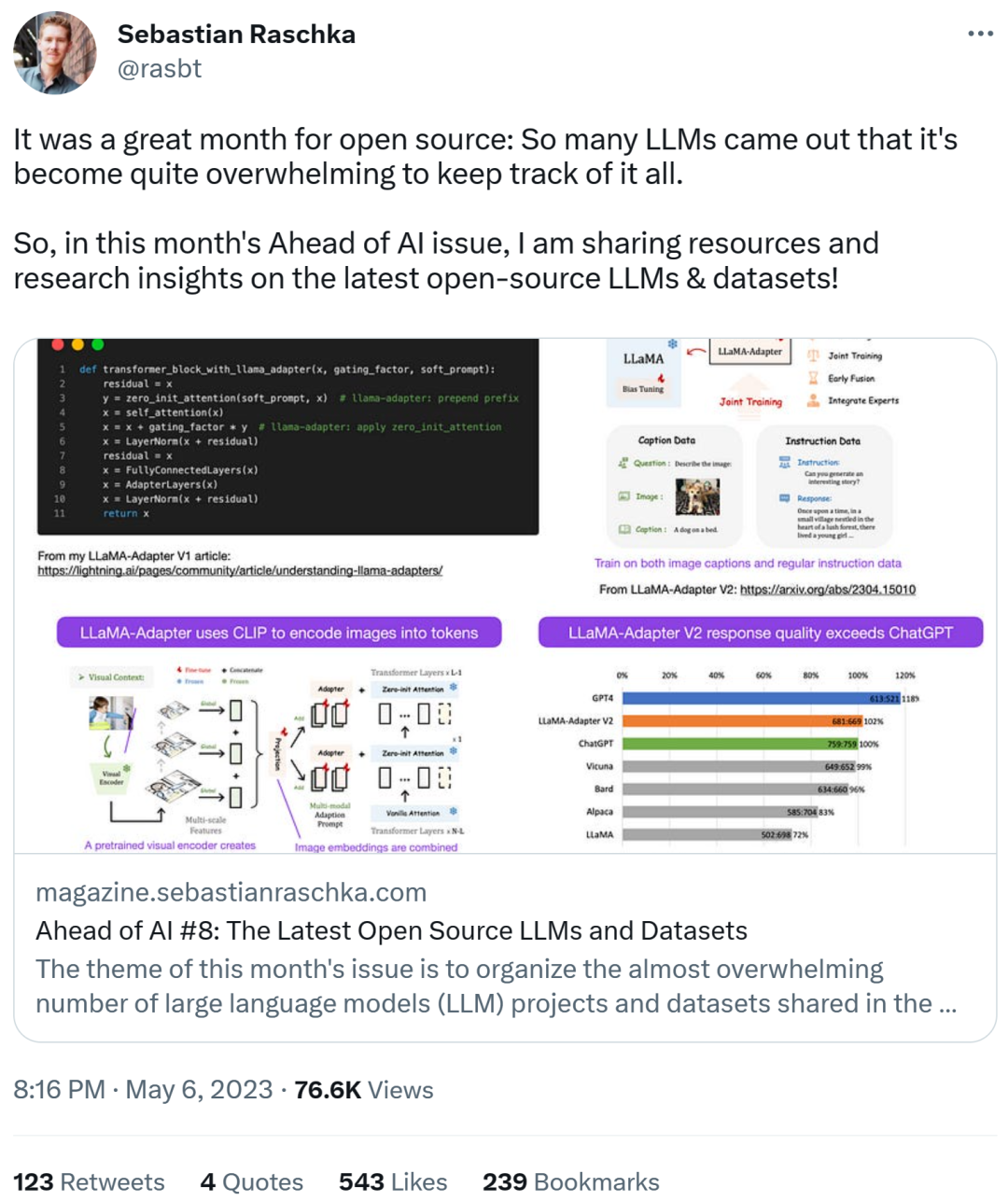
利用 LLaMA-Adapter V2 微调多模态 LLM
Sebastian 预测本月会看到更多的多模态 LLM 模型,因此不得不谈到不久前发布的论文《LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model》。先来回顾一下什么是 LLaMA-Adapter?它是一种参数高效的 LLM 微调技术,修改了前面几个 transformer 块并引入一种门控机制来稳定训练。
论文地址:https://arxiv.org/abs/2304.15010
使用 LLaMA-Adapter 方法,研究人员能够在 52k 个指令对上仅用 1 小时(8 块 A100 GPU)来微调一个 7B 参数的 LLaMA 模型。虽然仅对新添加的 1.2M 参数(adapter 层)进行了微调,但 7B LLaMA 模型仍处于冻结(frozen)状态。
LLaMA-Adapter V2 的重点在多模态,即构建一个可以接收图像输入的视觉指令模型。最初的 V1 虽然可以接收文本 token 和图像 token,但在图像方面没有得到充分探索。
LLaMA-Adapter 从 V1 到 V2,研究人员通过以下三个主要技巧来改进 adapter 方法。
- 早期视觉知识融合:不再在每个 adapted 层融合视觉和 adapted 提示,而是在第一个 transformer 块中将视觉 token 与单词 token 连接起来;
- 使用更多参数:解冻(unfreeze)所有归一化层,并将偏置单元和缩放因子添加到 transformer 块中每个线性层;
- 具有不相交参数的联合训练:对于图文字幕数据,仅训练视觉投影层;针对指令遵循的数据仅训练 adaption 层(以及上述新添加的参数)。
LLaMA V2(14M)比 LLaMA V1 (1.2 M) 的参数多了很多,但它仍是轻量级,仅占 65B LLaMA 总参数的 0.02%。特别令人印象深刻的是,通过仅对 65B LLaMA 模型的 14M 参数进行微调,得到的 LLaMA-Adapter V2 在性能上媲美 ChatGPT(当使用 GPT-4 模型进行评估)。LLaMA-Adapter V2 还优于使用全微调方法的 13B Vicuna 模型。
遗憾的是,LLaMA-Adapter V2 论文省略了 V1 论文中包含的计算性能基准,但我们可以假设 V2 仍然比全微调方法快得多。

其他开源 LLM
大模型的发展速度奇快,我们无法一一列举,本月推出的一些著名的开源 LLM 和聊天机器人包括 Open-Assistant、Baize、StableVicuna、ColossalChat、Mosaic 的 MPT 等。此外,下面是两个特别有趣的多模态 LLM。
OpenFlamingo
OpenFlamingo 是 Google DeepMind 去年发布的 Flamingo 模型的开源复制版。OpenFlamingo 旨在为 LLM 提供多模式图像推理功能,让人们能够交错输入文本和图像。
MiniGPT-4
MiniGPT-4 是另一种具有视觉语言功能的开源模型。它基于 BLIP-27 的冻结视觉编码器和冻结的 Vicuna LLM。
NeMo Guardrails
随着这些大语言模型的出现,许多公司都在思考如何以及是否应该部署它们,安全方面的担忧尤为突出。目前还没有好的解决方案,但至少有一个更有前途的方法:英伟达开源了一个工具包来解决 LLM 的幻觉问题。
简而言之,它的工作原理是此方法使用数据库链接到硬编码的 prompt,这些 prompt 必须手动管理。然后,如果用户输入 prompt,该内容将首先与该数据库中最相似的条目相匹配。然后数据库返回一个硬编码的 prompt,然后传递给 LLM。因此,如果有人仔细测试硬编码 prompt,就可以确保交互不会偏离允许的主题等。
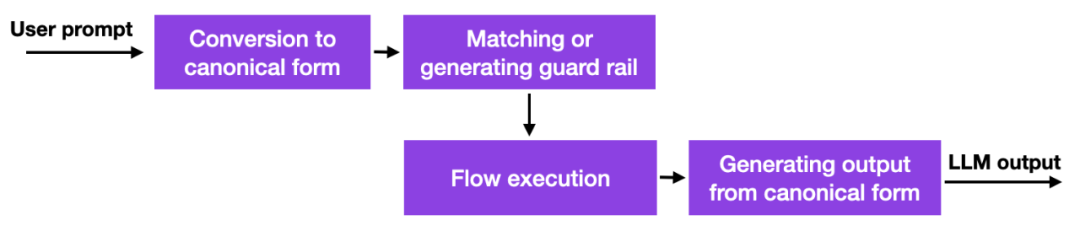
这是一种有趣但不是开创性的方法,因为它没有为 LLM 提供更好的或新的能力,它只是限制了用户可以与 LLM 交互的程度。尽管如此,在研究人员找到减轻 LLM 中的幻觉问题和负面行为的替代方法之前,这可能是一种可行的方法。
guardrails 方法还可以与其他对齐技术相结合,例如作者在上一期 Ahead of AI 中介绍的流行的人类反馈强化学习训练范例。
一致性模型
谈论 LLM 以外的有趣模型是一个不错的尝试,OpenAI 终于开源了他们一致性模型的代码:https://github.com/openai/consistency_models。
一致性模型被认为是扩散模型的可行、有效的替代方案。你可以在一致性模型的论文中获得更多信息。
本篇关于《大模型迎来「开源季」,盘点过去一个月那些开源的LLM和数据集》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于科技周边的相关知识,请关注golang学习网公众号!
 微服务架构中如何进行服务的版本管理?
微服务架构中如何进行服务的版本管理?
- 上一篇
- 微服务架构中如何进行服务的版本管理?

- 下一篇
- Golang函数的字节流处理技巧
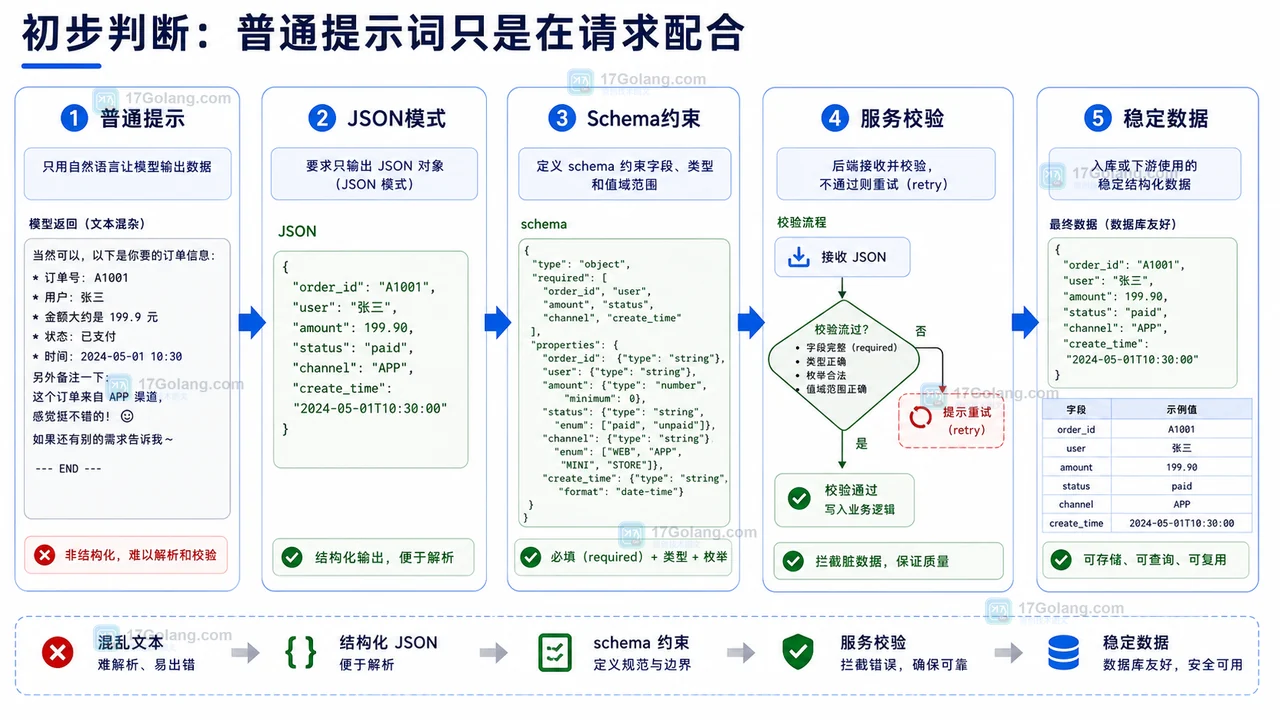

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 1370次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 1312次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 1255次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 1434次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 1433次使用
-
- GPT-4王者加冕!读图做题性能炸天,凭自己就能考上斯坦福
- 2023-04-25 501浏览
-
- 单块V100训练模型提速72倍!尤洋团队新成果获AAAI 2023杰出论文奖
- 2023-04-24 501浏览
-
- ChatGPT 真的会接管世界吗?
- 2023-04-13 501浏览
-
- VR的终极形态是「假眼」?Neuralink前联合创始人掏出新产品:科学之眼!
- 2023-04-30 501浏览
-
- 实现实时制造可视性优势有哪些?
- 2023-04-15 501浏览


