JavaScript埋点实现全解析
文章不知道大家是否熟悉?今天我将给大家介绍《JavaScript前端埋点实现方法详解》,这篇文章主要会讲到等等知识点,如果你在看完本篇文章后,有更好的建议或者发现哪里有问题,希望大家都能积极评论指出,谢谢!希望我们能一起加油进步!
前端埋点通过JavaScript监听用户行为与页面状态,经数据结构化后发送至服务端,实现用户行为洞察。核心步骤为:1. 利用事件监听(如click、load)、路由劫持(SPA场景)和Intersection Observer(元素曝光)捕获行为;2. 按统一规范结构化事件名称、用户信息、页面及业务参数;3. 通过fetch(配合keepalive)或sendBeacon可靠发送数据,确保页面卸载时数据不丢失。数据设计需围绕业务目标,明确事件命名、参数标准,平衡粒度与隐私。SPA中面临页面视图追踪难、动态元素监听等问题,可通过劫持history API、框架路由钩子、事件委托与MutationObserver解决。准确性保障依赖手动与自动化测试(如Cypress验证请求)、灰度发布及try-catch错误隔离,确保埋点稳定可靠。

利用JavaScript进行前端埋点,核心在于通过监听用户在页面上的行为(点击、滚动、表单提交等)和页面的状态变化(路由切换、加载时间等),并将这些数据结构化后发送到数据收集服务。这能帮助我们洞察用户行为,优化产品体验。说白了,就是用代码在用户和产品之间搭建一座数据桥梁,让我们能“看见”用户在做什么,想什么。
解决方案
前端埋点,在我看来,就像在用户旅程的关键节点上安放一个个小探头。最基础的思路,无非是“监听-收集-发送”这三步。
1. 监听用户行为和页面状态
这部分是基础。我们用JavaScript的事件监听机制来捕捉用户的各种操作。
点击事件 (Clicks): 这是最常见的。比如,一个按钮被点击了,一个链接被访问了。
document.addEventListener('click', function(event) { const target = event.target; // 过滤掉不感兴趣的点击,或者只关注特定元素 if (target.matches('.track-btn') || target.closest('.track-card')) { const eventName = target.dataset.eventName || 'click'; const eventProps = { elementId: target.id, elementText: target.innerText.substring(0, 50), // 截取避免过长 pageUrl: window.location.href, // ... 其他你感兴趣的属性 }; sendTrackingData(eventName, eventProps); } });这里我用了
matches和closest,因为直接监听document效率高,但需要内部逻辑来判断哪些点击是有效的、有意义的。dataset属性是个好东西,能直接在HTML里定义一些埋点参数。页面浏览 (Page Views): 传统多页应用(MPA)会在每次页面加载时发送。单页应用(SPA)则需要监听路由变化。
// MPA 场景,页面加载时发送 window.addEventListener('load', function() { sendTrackingData('page_view', { pageUrl: window.location.href, pageTitle: document.title, referrer: document.referrer }); }); // SPA 场景,监听路由变化 (以 history API 为例) (function(history){ const pushState = history.pushState; history.pushState = function() { if (typeof pushState == 'function') { pushState.apply(history, arguments); } // 路由变化后发送页面浏览事件 sendTrackingData('page_view', { pageUrl: window.location.href, pageTitle: document.title, referrer: document.referrer // SPA场景下referrer可能不准确,需要额外处理 }); }; })(window.history); // 还需要监听 popstate 事件处理浏览器前进/后退 window.addEventListener('popstate', function() { sendTrackingData('page_view', { pageUrl: window.location.href, pageTitle: document.title, referrer: document.referrer }); });SPA的路由监听是个小麻烦,需要劫持
pushState和replaceState,同时别忘了popstate。元素曝光 (Element Exposure): 当某个元素进入用户视口时触发。这对于广告、推荐位或重要信息展现的统计很有用。
Intersection Observer是现代浏览器中实现这个的最佳实践。const observer = new IntersectionObserver((entries) => { entries.forEach(entry => { if (entry.isIntersecting && entry.target.dataset.tracked !== 'true') { // 元素进入视口,且尚未被追踪过 sendTrackingData('element_exposure', { elementId: entry.target.id, elementType: entry.target.tagName, // ... }); entry.target.dataset.tracked = 'true'; // 标记为已追踪,避免重复发送 } }); }, { threshold: 0.5 }); // 当元素50%进入视口时触发 document.querySelectorAll('.track-on-view').forEach(el => { observer.observe(el); });我喜欢
Intersection Observer,因为它性能好,比手动计算滚动位置靠谱多了。
2. 收集和结构化数据
收集到的数据需要有统一的格式,方便后端处理。一个事件对象通常包含:
eventName: 事件名称(如product_add_to_cart,banner_click)timestamp: 时间戳userId: 用户ID(如果登录)或匿名IDsessionId: 会话IDpageUrl: 当前页面URLuserAgent: 浏览器信息eventProperties: 事件相关的具体属性(如商品ID、点击位置等)
3. 发送数据
将结构化后的数据发送到数据收集服务(通常是后端API或第三方统计服务)。
XMLHttpRequest或fetch: 这是最常用的方式。function sendTrackingData(eventName, properties = {}) { const payload = { event: eventName, timestamp: Date.now(), common: { userId: getUserId(), // 获取用户ID,可能来自 cookie 或 localStorage sessionId: getSessionId(), userAgent: navigator.userAgent, platform: 'web', // ... }, properties: properties }; // 我通常会用一个队列来批量发送,减少网络请求 // 这里为了示例简洁,直接发送 fetch('/api/track', { method: 'POST', headers: { 'Content-Type': 'application/json', }, body: JSON.stringify(payload), keepalive: true // 确保页面关闭时请求也能发出去 }).catch(error => { console.error('埋点数据发送失败:', error); // 可以在这里进行错误日志记录或重试 }); }keepalive在fetch中非常重要,尤其是在页面跳转或关闭时,能保证请求不会被浏览器中断。navigator.sendBeacon: 专门为在页面卸载时发送少量数据而设计,它不会阻塞页面卸载,且能保证请求发出。window.addEventListener('beforeunload', function() { const payload = { /* 页面卸载前需要发送的数据 */ }; navigator.sendBeacon('/api/track/unload', JSON.stringify(payload)); });我个人觉得
sendBeacon在处理页面卸载这种场景时,简直是神器,比fetch加keepalive更稳定,毕竟它就是为此而生的。
前端埋点数据如何设计与选择?
数据设计,在我看来,是埋点成败的关键。如果数据收集得乱七八糟,或者根本没法回答业务问题,那埋点就成了无用功。我们不是为了埋点而埋点,是为了数据而埋点,更是为了洞察而埋点。
首先,要明确业务目标。在开始埋点之前,先问问自己:我们想通过这些数据解决什么问题?是想知道用户最喜欢哪个功能?还是想找出用户流失的环节?目标清晰,才能指导数据选择。
其次,制定统一的埋点规范。这包括事件命名规范、参数命名规范、数据类型等。比如,所有点击事件都以click_开头,所有页面浏览事件都叫page_view。参数名也得统一,比如商品ID始终是product_id,而不是一会儿pid一会儿itemId。这种规范化能大大降低后端数据处理的难度,也能避免分析时的歧义。
核心数据点选择:
- 事件类型 (Event Type): 这是最顶层的分类,如
click(点击)、view(浏览/曝光)、submit(提交)、error(错误)。 - 事件名称 (Event Name): 具体的操作或状态,必须足够具体且有业务含义。例如:
product_add_to_cart(商品加入购物车)、homepage_banner_click(首页Banner点击)、login_success(登录成功)。我倾向于用动词+名词的组合,清晰明了。 - 页面信息 (Page Info):
page_url: 当前页面的完整URL。page_title: 页面标题。referrer: 来源页面URL,了解用户从哪里来。
- 用户信息 (User Info):
user_id: 如果用户已登录,这是唯一标识符。anonymous_id: 未登录用户的匿名ID,通常通过Cookie或LocalStorage生成并维护,用于追踪匿名用户的行为。device_type: 设备类型(PC, Mobile, Tablet)。browser: 浏览器信息。os: 操作系统。
- 元素信息 (Element Info):
element_id: 被点击或曝光的元素的ID。element_text: 元素的文本内容,例如按钮上的文字。element_position: 元素在页面上的位置,有时对于A/B测试或热力图有用。
- 业务参数 (Business Parameters): 这是最能体现业务价值的部分。
- 商品详情页:
product_id,product_name,price,category。 - 搜索结果页:
search_keyword,search_result_count。 - 表单提交:
form_name,field_name(但要小心敏感信息)。
- 商品详情页:
数据粒度与隐私: 数据粒度要适中。收集太少,分析不出深度;收集太多,不仅增加传输和存储成本,还可能陷入数据噪音。我通常建议从宏观层面开始,然后根据分析需求,逐步细化到微观。
还有一点,数据隐私是重中之重。GDPR、CCPA等法规摆在那里,我们必须遵守。避免收集用户的敏感个人信息,对收集到的数据进行匿名化处理,并确保用户有权选择是否被追踪。这不仅是法律要求,也是对用户负责的表现。
单页应用(SPA)中前端埋点有哪些特殊挑战和解决方案?
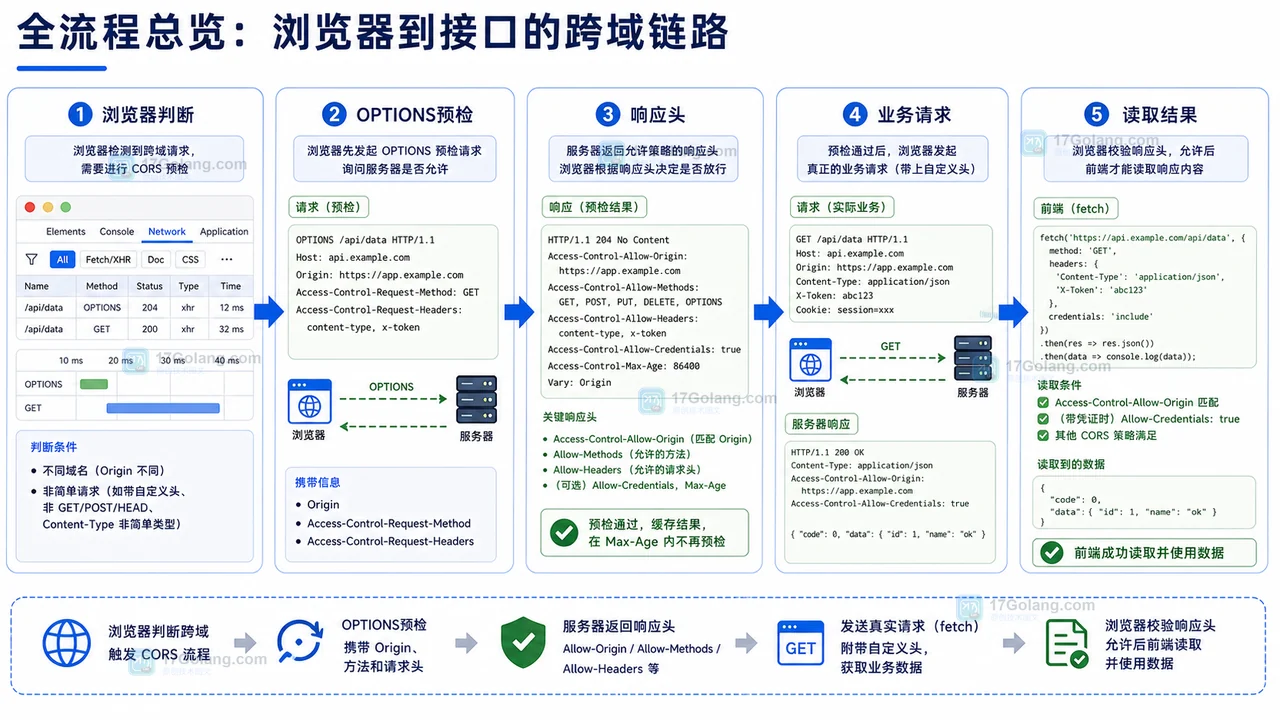
单页应用(SPA)的兴起,确实给前端埋点带来了不少“甜蜜的烦恼”。传统的多页应用(MPA)每次页面跳转都是一次完整的页面加载,浏览器事件(如load、DOMContentLoaded)清晰明了。但在SPA里,页面内容是动态替换的,URL变了,页面却没刷新,这就让传统的埋点方式有点水土不服。
主要挑战:
- 页面视图追踪不准确:
- 无完整页面刷新: SPA在路由切换时,并不会触发
window.onload或DOMContentLoaded事件。这意味着你不能简单地依赖这些事件来发送页面浏览(page_view)埋点。 - 虚拟URL: 虽然浏览器URL可能通过
history.pushState或hashchange改变了,但从技术层面看,它仍然是同一个HTML页面,只是DOM内容被JS动态替换了。
- 无完整页面刷新: SPA在路由切换时,并不会触发
- 动态内容和元素:
- 很多交互元素可能不是在页面初始加载时就存在的,而是随着用户操作或数据请求动态渲染出来的。这就导致你无法在页面加载时一次性给所有元素绑定事件监听器。
- 元素的生命周期也变得复杂,组件的挂载和卸载可能导致事件监听失效或重复绑定。
- 数据上下文的维护:
- SPA中,用户可能在不刷新页面的情况下进行大量操作。如何在这些操作中维护一致的用户ID、会话ID等上下文信息,并确保每次埋点都带上这些信息,需要更精细的设计。
解决方案:
路由监听(Router Listening): 这是解决SPA页面视图追踪的核心。
劫持
historyAPI: 对于使用history.pushState和replaceState的SPA,你需要劫持这些方法,在它们被调用后手动触发一个自定义事件,或者直接在劫持函数中发送page_view埋点。同时,别忘了监听popstate事件,以处理用户点击浏览器前进/后退按钮的情况。// 示例:劫持 pushState (function(history){ const pushState = history.pushState; history.pushState = function() { // 执行原始的 pushState const result = pushState.apply(history, arguments); // 触发自定义事件或直接发送埋点 window.dispatchEvent(new Event('spa-route-change')); return result; }; })(window.history); window.addEventListener('spa-route-change', function() { sendTrackingData('page_view', { pageUrl: window.location.href, pageTitle: document.title, // ... }); }); window.addEventListener('popstate', function() { sendTrackingData('page_view', { /* ... */ }); });利用前端框架的路由钩子: 如果你使用的是Vue Router、React Router等框架,它们通常提供了方便的路由生命周期钩子(如Vue Router的
beforeEach、afterEach,React Router的useEffect监听location对象),你可以在这些钩子中发送page_view埋点。这比手动劫持historyAPI要优雅和稳定得多。
动态元素事件委托与
MutationObserver:- 事件委托(Event Delegation): 对于动态添加的交互元素,最佳实践是使用事件委托。将事件监听器绑定到文档根元素(如
document或body),然后通过事件冒泡机制,在处理函数中判断事件的target是否是你关心的元素。这样,无论元素何时被添加到DOM中,其事件都能被捕获。document.addEventListener('click', function(event) { const target = event.target; if (target.matches('.dynamic-track-btn')) { sendTrackingData('dynamic_button_click', { elementText: target.innerText }); } }); MutationObserver: 当你需要追踪元素曝光或在元素被动态添加到DOM时执行某些操作时,MutationObserver非常有用。它可以监听DOM树的变化(节点添加、删除、属性修改等),帮助你捕捉到动态内容的出现。const observer = new MutationObserver(mutations => { mutations.forEach(mutation => { if (mutation.type === 'childList' && mutation.addedNodes.length > 0) { mutation.addedNodes.forEach(node => { if (node.nodeType === 1 && node.matches('.track-on-view')) { // 新增的元素符合曝光追踪条件,开始观察 intersectionObserverForExposure.observe(node); } }); } }); }); observer.observe(document.body, { childList: true, subtree: true });这能确保即使是异步加载或延迟渲染的元素,也能被正确地纳入埋点系统。
- 事件委托(Event Delegation): 对于动态添加的交互元素,最佳实践是使用事件委托。将事件监听器绑定到文档根元素(如
统一的埋点服务与上下文管理:
- 封装一个统一的埋点SDK/服务: 将所有埋点逻辑封装在一个JavaScript模块或类中。这个服务负责管理用户ID、会话ID、设备信息等通用上下文数据。所有组件或业务逻辑都通过调用这个统一服务来发送埋点,而不是直接调用
fetch或sendBeacon。 - 上下文数据传递: 在SPA中,用户ID、会话ID等信息通常在应用启动时获取或生成。确保这些信息在整个用户会话中保持一致,并在每次埋点时作为公共参数附加。这可以通过闭包、全局对象或React Context/Vue Provide/Inject等方式实现。
- 清除旧数据: 在路由切换时,如果需要,清除或重置与旧页面相关的埋点数据,避免数据混淆。
- 封装一个统一的埋点SDK/服务: 将所有埋点逻辑封装在一个JavaScript模块或类中。这个服务负责管理用户ID、会话ID、设备信息等通用上下文数据。所有组件或业务逻辑都通过调用这个统一服务来发送埋点,而不是直接调用
SPA埋点确实需要更多思考和更精细的实现,但只要理解其动态特性,并善用现代浏览器API和框架特性,这些挑战都是可以克服的。
如何确保前端埋点数据的准确性与稳定性?
埋点数据就像是产品的眼睛,如果这双眼睛看东西不准或者时不时失明,那我们做的决策就可能南辕北辙。所以,确保埋点数据的准确性和稳定性,我觉得,和写业务代码一样重要,甚至在某些关键路径上更重要。
完善的测试策略
- 手动验证: 这是最直接的方式。开发或QA人员在页面上进行各种操作,同时打开浏览器的开发者工具,查看网络请求中是否有埋点数据发出,以及数据的payload是否正确。我通常会用Chrome的Network Tab,过滤关键词比如
/api/track,然后仔细检查每个请求的参数。 - 自动化测试(E2E测试): 将埋点验证集成到端到端测试流程中。使用Cypress、Playwright或Selenium等工具模拟用户操作,并在断言中检查埋点请求是否被发送,以及请求体中的数据是否符合预期。
// Cypress 伪代码示例 cy.intercept('POST', '/api/track').as('trackRequest'); cy.get('#add-to-cart-button').click(); cy.wait('@trackRequest').then((interception) => { expect(interception.request.body.event).to.eq('product_add_to_cart'); expect(interception.request.body.properties.productId).to.eq('123'); });这种方式能大大提高测试效率和覆盖率,尤其是在频繁迭代的项目中。
- 灰度发布与AB测试: 在全量上线前,先将新埋点代码在小部分用户群体中灰度发布。观察这部分用户的埋点数据是否正常,是否有异常波动。这能帮助我们发现一些在测试环境难以复现的问题。
- 手动验证: 这是最直接的方式。开发或QA人员在页面上进行各种操作,同时打开浏览器的开发者工具,查看网络请求中是否有埋点数据发出,以及数据的payload是否正确。我通常会用Chrome的Network Tab,过滤关键词比如
健壮的错误处理机制
try-catch包裹: 埋点代码本身不应该影响用户体验。任何可能导致错误的逻辑(如获取DOM元素失败、数据处理异常)都应该用try-catch包裹起来。即使埋点失败,页面功能也应该正常运行。
文中关于JavaScript,用户行为,SPA,前端埋点,数据发送的知识介绍,希望对你的学习有所帮助!若是受益匪浅,那就动动鼠标收藏这篇《JavaScript埋点实现全解析》文章吧,也可关注golang学习网公众号了解相关技术文章。
 HTML代码优化结构的步骤有哪些
HTML代码优化结构的步骤有哪些
- 上一篇
- HTML代码优化结构的步骤有哪些

- 下一篇
- Win11夜间模式设置教程
-
- 文章 · 前端 | 4天前 | 定时器 · 前端 · 性能排查 · 接口请求 · 轮询 · setInterval · setInterval 页面可见性 clearInterval 前端轮询 请求堆积 定时器清理
- 前端轮询接口越打越多怎么办:从重复定时器到清理机制一步步排查
- 490浏览 收藏
-
- 文章 · 前端 | 4天前 | 前端 · 搜索框 · AbortController · 接口请求 · 状态管理 · Fetch AbortController 前端搜索 请求乱序 旧响应覆盖
- 前端搜索结果倒退怎么办:AbortController 取消旧请求和序号兜底
- 295浏览 收藏
-
- 文章 · 前端 | 4天前 | 前端 · 性能优化 · cls · 懒加载 · Core Web Vitals · 前端 图片懒加载 IntersectionObserver CLS 布局稳定
- 前端图片懒加载布局抖动治理完整流程:占位比例、按需加载和 CLS 复查
- 128浏览 收藏
-

- 文章 · 前端 | 5天前 | 工程化 · 前端 · javascript · css · 弹窗 · 前端 z-index 遮罩层 stacking context Portal 弹窗层级
- 前端弹窗层级治理工作流:从 z-index 混乱到 Portal 容器规范
- 350浏览 收藏
-
- 文章 · 前端 | 5天前 | 前端 · javascript · URL参数 · 列表筛选 · 页面状态 · 前端 筛选条件 列表页 history.replaceState URLSearchParams 刷新还原
- 前端筛选条件刷新后丢失怎么办:从内存状态到 URL 参数一步步排查
- 348浏览 收藏

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 1186次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 1138次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 1075次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 1263次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 1252次使用
-
- JavaScript函数定义及示例详解
- 2025-05-11 502浏览
-
- 优化用户界面体验的秘密武器:CSS开发项目经验大揭秘
- 2023-11-03 501浏览
-
- 使用微信小程序实现图片轮播特效
- 2023-11-21 501浏览
-
- 解析sessionStorage的存储能力与限制
- 2024-01-11 501浏览
-
- 探索冒泡活动对于团队合作的推动力
- 2024-01-13 501浏览


