李飞飞划重点的「具身智能」,走到哪一步了?
今日不肯埋头,明日何以抬头!每日一句努力自己的话哈哈~哈喽,今天我将给大家带来一篇《李飞飞划重点的「具身智能」,走到哪一步了?》,主要内容是讲解等等,感兴趣的朋友可以收藏或者有更好的建议在评论提出,我都会认真看的!大家一起进步,一起学习!
2009 年,当时在普林斯顿大学工作的计算机科学家李飞飞主导构建了一个改变人工智能历史的数据集——ImageNet。它包含了数百万张有标签的图像,可以用来训练复杂的机器学习模型,以识别图像中的物体。
2015 年,机器的识别能力超过了人类。李飞飞也在不久之后转向了新的目标,去寻找她所说的另一颗「北极星」(此处的「北极星」指的是研究人员所专注于解决的关键科学问题,这个问题可以激发他们的研究热情并取得突破性的进展)。

她通过回溯 5.3 亿年前的寒武纪生命大爆发找到了灵感,当时,许多陆生动物物种首次出现。一个有影响力的理论认为,新物种的爆发部分是由眼睛的出现所驱动的,这些眼睛让生物第一次看到周围的世界。李飞飞认为,动物的视觉不会孤零零地产生,而是「深深地嵌在一个整体中,这个整体需要在快速变化的环境中移动、导航、生存、操纵和改变,」她说道,「所以我就很自然地转向了一个更加活跃的 AI 领域。」

如今,李飞飞的工作重点集中在 AI 智能体上,这种智能体不仅能接收来自数据集的静态图像,还能在三维虚拟世界的模拟环境中四处移动,并与周围环境交互。
这是一个被称为「具身 AI」的新领域的广泛目标。它与机器人技术有所重叠,因为机器人可以看作是现实世界中具身 AI 智能体和强化学习的物理等价物。李飞飞等人认为,具身 AI 可能会给我们带来一次重大的转变,从识别图像等机器学习的简单能力,转变到学习如何通过多个步骤执行复杂的类人任务,如制作煎蛋卷。
今天,具身 AI 的工作包括任何可以探测和改变自身环境的智能体。在机器人技术中,AI 智能体总是生活在机器人身体中,而真实模拟中的智能体可能有一个虚拟的身体,或者可能通过一个移动的相机机位来感知世界,而且还能与周围环境交互。「具身的含义不是身体本身,而是与环境交互以及在环境中做事的整体需求和功能,」李飞飞解释说。
这种交互性为智能体提供了一种全新的——在许多情况下是更好的——了解世界的方式。这就相当于,之前你只是观察两个物体之间可能的关系,而现在,你可以亲自实验并让这种关系发生。有了这种新的理解,想法就会付诸实践,更大的智慧也会随之而来。随着一套新的虚拟世界的建立和运行,具身 AI 智能体已经开始发挥这种潜力,在他们的新环境中取得了重大进展。
「现在,我们没有任何证据证明存在不通过与世界互动来学习的智能,」德国奥斯讷布吕克大学的具身 AI 研究者 Viviane Clay 说。
走向完美模拟
虽然研究人员早就想为 AI 智能体创造真实的虚拟世界来探索,但真正创建的时间才只有五年左右。这种能力来自于电影和视频游戏行业对图像的改进。2017 年,AI 智能体可以像在家里一样逼真地描绘室内空间——虽然是虚拟的,但却是字面上的「家」。艾伦人工智能研究所的计算机科学家构建了一个名为 AI2-Thor 的模拟器,让智能体在自然的厨房、浴室、客厅和卧室中随意走动。智能体可以学习三维视图,这些视图会随着他们的移动而改变,当他们决定近距离观察时,模拟器会显示新的角度。
这种新世界也给了智能体一个机会去思考一个新维度「时间」中的变化。西蒙弗雷泽大学的计算机图形学研究员 Manolis savva 说,「这是一个很大的变化。在具身 AI 设定中,你有这些时间上的连贯信息流,你可以控制它。」
这些模拟的世界现在已经足够好,可以训练智能体完成全新的任务。它们不仅可以识别一个物体,还可以与它互动,捡起它并在它周围导航。这些看似很小的步骤对任何智能体来说都是理解其环境的必要步骤。2020 年,虚拟智能体拥有了视觉以外的能力,可以听到虚拟事物发出的声音,这为其了解物体及其在世界上的运行方式提供了一种新的视角。

可以在虚拟世界(ManipulaTHOR environment)中运行的具身 AI 智能体以不同的方式学习,可能更适合更复杂的、类人的任务。
不过,模拟器也有自己的局限。「即使最好的模拟器也远不如现实世界真实,」斯坦福大学计算机科学家 Daniel Yamins 说。Yamins 与麻省理工学院和 IBM 的同事共同开发了 ThreeDWorld,该项目重点关注在虚拟世界中模拟现实生活中的物理现象,如液体的行为以及一些物体如何在一个区域是刚性的,而在另一个区域又是柔性的。
这是一项非常具有挑战性的任务,需要让 AI 以新的方式去学习。
与神经网络进行比较
到目前为止,衡量具身 AI 进展的一种简单方法是:将具身智能体的表现与在更简单的静态图像任务上训练的算法进行比较。研究人员指出,这些比较并不完美,但早期结果确实表明,具身 AI 的学习方式不同于它们的前辈,有时候比它们的前辈学得还好。
在最近的一篇论文(《Interactron: Embodied Adaptive Object Detection》)中,研究人员发现,一个具身 AI 智能体在检测特定物体方面更准确,比传统方法提高了近 12%。该研究的合著者、艾伦人工智能研究所计算机科学家 Roozbeh Mottaghi 表示,「目标检测领域花了三年多的时间才实现这种水平的改进。而我们仅通过与世界的交互就取得了很大的进步。」
其他论文已经表明,当你把目标检测算法做成具身 AI 的形式,并让它们探索一次虚拟空间或者随处走动收集对象的多视图信息时,该算法会取得进步。
研究人员还发现,具身算法和传统算法的学习方式完全不同。要想证明这一点,可以想想神经网络,它是每个具身算法和许多非具身算法学习能力背后的基本成分。神经网络由许多层的人工神经元节点连接而成,它松散地模仿人类大脑中的网络。在两篇独立的论文中,研究人员发现,在具身智能体的神经网络中,对视觉信息作出反应的神经元较少,这意味着每个单独的神经元在作出反应时更有选择性。非具身网络的效率要低得多,需要更多的神经元在大部分时间保持活跃。其中一个研究小组(由即将任纽约大学教授的 Grace Lindsay 领导)甚至将具身和非具身的神经网络与活体大脑中的神经元活动(老鼠的视觉皮层)进行了比较,发现具身的神经网路最接近活体。
Lindsay 很快指出,这并不一定意味着具身化的版本更好,它们只是不同。与物体检测论文不同的是,Lindsay 等人的研究比较了相同神经网络的潜在差异,让智能体完成了完全不同的任务,因此他们可能需要工作方式不同的神经网络来完成他们的目标。
虽然将具身神经网络与非具身神经网络相比是一种衡量改进的方法,但研究人员真正想做的并不是在现有的任务上提升具身智能体的性能,他们的真正目标是学习更复杂、更像人类的任务。这是最令研究人员兴奋的地方,他们看到了令人印象深刻的进展,尤其是在导航任务方面。在这些任务中,智能体必须记住其目的地的长期目标,同时制定一个到达目的地的计划,而不会迷路或撞到物体。
在短短几年的时间里,Meta AI 的一位研究主管、佐治亚理工学院计算机科学家 Dhruv Batra 领导的团队在一种被称为「point-goal navigation」的特定导航任务上取得了很大进展。在这项任务中,智能体被放在一个全新的环境中,它必须在没有地图的情况下走到某个坐标(比如「Go to the point that is 5 meters north and 10 meters east」)。
Batra 介绍说,他们在一个名叫「AI Habitat」的 Meta 虚拟世界中训练智能体,并给了它一个 GPS 和一个指南针,结果发现它可以在标准数据集上获得 99.9% 以上的准确率。最近,他们又成功地将结果扩展到一个更困难、更现实的场景——没有指南针和 GPS。结果,智能体仅借助移动时看到的像素流来估计自身位置就实现了 94% 的准确率。

Meta AI Dhruv Batra 团队创造的「AI Habitat」虚拟世界。他们希望提高模拟的速度,直到具身 AI 可以在仅仅 20 分钟的挂钟时间内达到 20 年的模拟经验。
Mottaghi 说,「这是一个了不起的进步,但并不意味着彻底解决了导航问题。因为许多其他类型的导航任务需要使用更复杂的语言指令,比如「经过厨房去拿卧室床头柜上的眼镜」,其准确率仍然只有 30% 到 40% 左右。
但导航仍然是具身 AI 中最简单的任务之一,因为智能体在环境中移动时不需要操作任何东西。到目前为止,具身 AI 智能体还远远没有掌握任何与对象相关的任务。部分挑战在于,当智能体与新对象交互时,它可能会出现很多错误,而且错误可能会堆积起来。目前,大多数研究人员通过选择只有几个步骤的任务来解决这个问题,但大多数类人活动,如烘焙或洗碗,需要对多个物体进行长序列的动作。要实现这一目标,AI 智能体将需要更大的进步。
在这方面,李飞飞可能再次走在了前沿,她的团队开发了一个模拟数据集——BEHAVIOR,希望能像她的 ImageNet 项目为目标识别所做的那样,为具身 AI 作出贡献。

这个数据集包含 100 多项人类活动,供智能体去完成,测试可以在任何虚拟环境中完成。通过创建指标,将执行这些任务的智能体与人类执行相同任务的真实视频进行比较,李飞飞团队的新数据集将允许社区更好地评估虚拟 AI 智能体的进展。
一旦智能体成功完成了这些复杂的任务,李飞飞认为,模拟的目的就是为最终的可操作空间——真实世界——进行训练。
「在我看来,模拟是机器人研究中最重要、最令人兴奋的领域之一。」李飞飞说到。
机器人研究新前沿
机器人本质上是具身智能体。它们寄居在现实世界的某种物理身体内,代表了最极端的具身 AI 智能体形式。但许多研究人员发现,即使是这类智能体也能从虚拟世界的训练中受益。
Mottaghi 说,机器人技术中最先进的算法,如强化学习等,通常需要数百万次迭代来学习有意义的东西。因此,训练真实机器人完成艰巨任务可能需要数年时间。

机器人可以在现实世界中不确定的地形中导航。新的研究表明,虚拟环境中的训练可以帮助机器人掌握这些技能以及其他技能。
但如果先在虚拟世界中训练它们,速度就要快得多。数千个智能体可以在数千个不同的房间中同时训练。此外,虚拟训练对机器人和人来说都更安全。
2018 年,OpenAI 的研究人员证明了:智能体在虚拟世界中学到的技能可以迁移到现实世界,因此很多机器人专家开始更加重视模拟器。他们训练一只机械手去操作一个只在模拟中见过的立方体。最新的研究成果还包括让无人机学会在空中避免碰撞,将自动驾驶汽车部署在两个不同大陆的城市环境中,以及让四条腿的机器狗在瑞士阿尔卑斯山完成一小时的徒步旅行(和人类所花的时间一样)。
未来,研究人员还可能通过虚拟现实头显将人类送入虚拟空间,从而缩小模拟和现实世界之间的差距。英伟达机器人研究高级主管、华盛顿大学教授 Dieter Fox 指出,机器人研究的一个关键目标是构建在现实世界中对人类有帮助的机器人。但要做到这一点,它们必须首先接触并学习如何与人类交互。
Fox 说,利用虚拟现实技术让人类进入这些模拟环境,然后让他们做出演示、与机器人交互,这将是一种非常强大的方法。
无论身处模拟还是现实世界,具身 AI 智能体都在学习如何更像人,完成的任务更像人类的任务。这个领域在各个方面都在进步,包括新的世界、新的任务和新的学习算法。
「我看到了深度学习、机器人学习、视觉甚至语言的融合,」李飞飞说,「现在我认为,通过这个面向具身 AI 的『登月计划』或『北极星』,我们将学习智能的基础技术,这可以真正带来重大突破。」

李飞飞探讨计算机视觉「北极星」问题的文章。链接:https://www.amacad.org/publication/searching-computer-vision-north-stars
到这里,我们也就讲完了《李飞飞划重点的「具身智能」,走到哪一步了?》的内容了。个人认为,基础知识的学习和巩固,是为了更好的将其运用到项目中,欢迎关注golang学习网公众号,带你了解更多关于智能,计算机视觉的知识点!
 生成式AI:解锁时尚行业的未来
生成式AI:解锁时尚行业的未来
- 上一篇
- 生成式AI:解锁时尚行业的未来

- 下一篇
- Apple 工程师测试 ChatGPT 风格的技术,因为 Siri 面临“笨拙的代码”和其他障碍
-
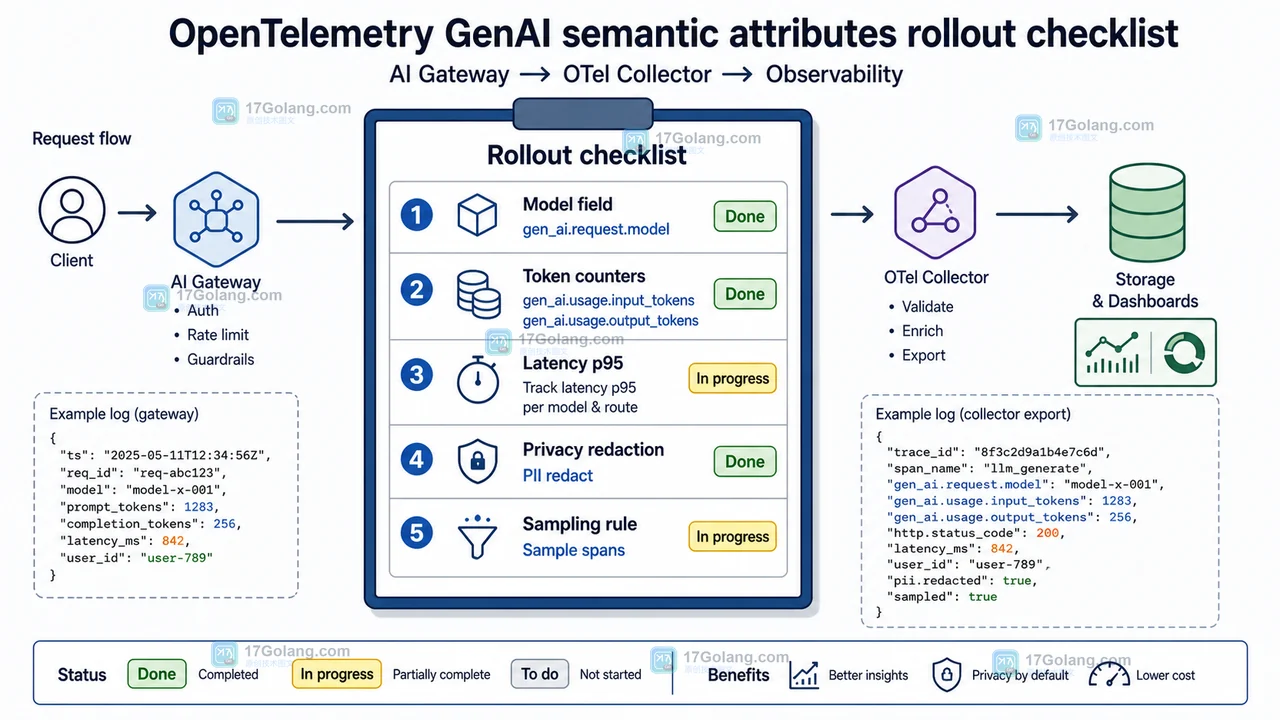
- 科技周边 · 人工智能 | 1星期前 | 人工智能 · GenAI · opentelemetry · 可观测性 · AI工程 · 人工智能 链路追踪 GenAI OpenTelemetry AI可观测性 LLM网关 Token统计
- AI 调用可观测架构:从散乱日志到 OpenTelemetry GenAI 字段统一
- 427浏览 收藏
-
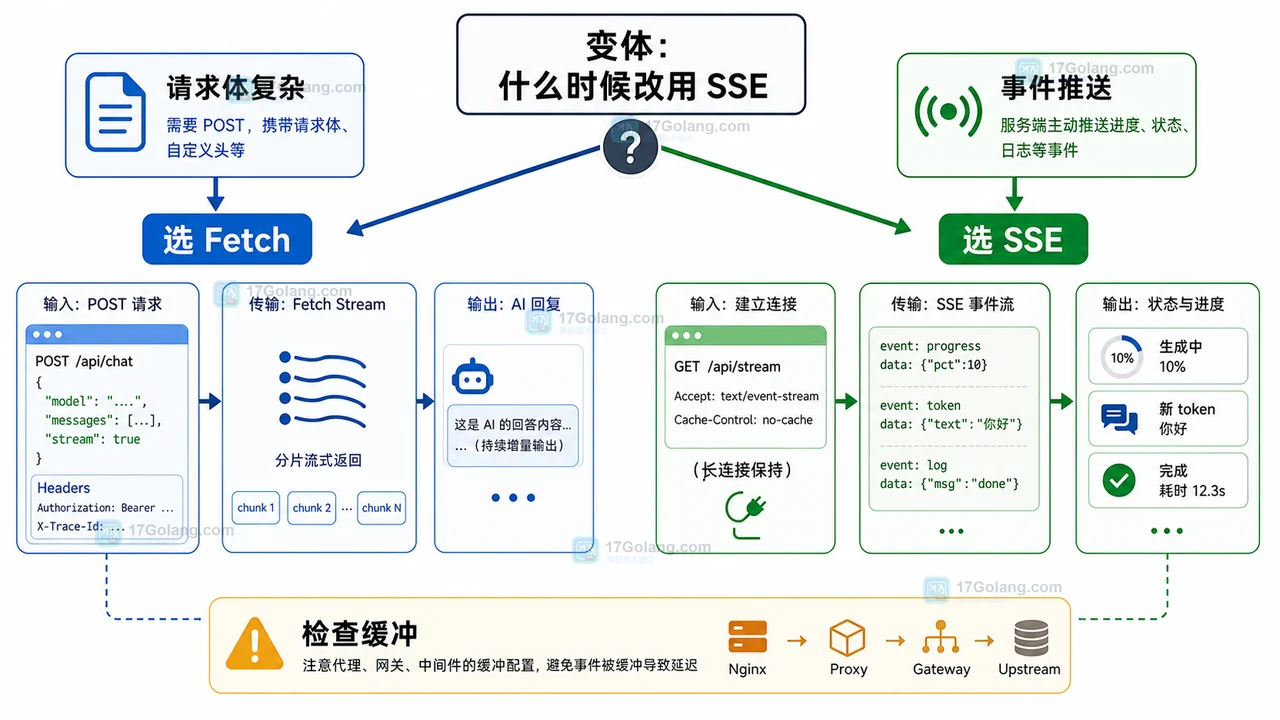
- 科技周边 · 人工智能 | 2星期前 | 人工智能 · 前端流式输出 · AI聊天 · Fetch Stream · 前端 AI聊天 流式输出 ReadableStream TextDecoder Fetch Stream
- AI 聊天流式输出前端配方:用 Fetch Stream 实现逐字渲染和中断控制
- 448浏览 收藏


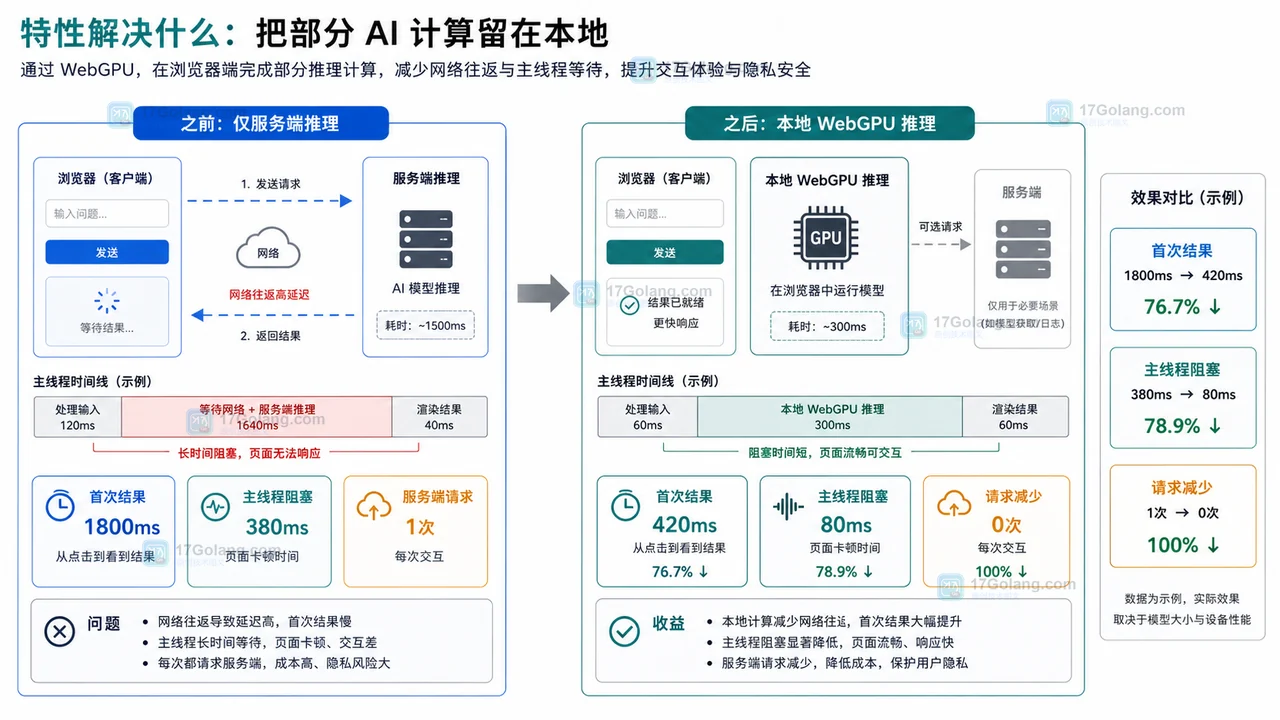
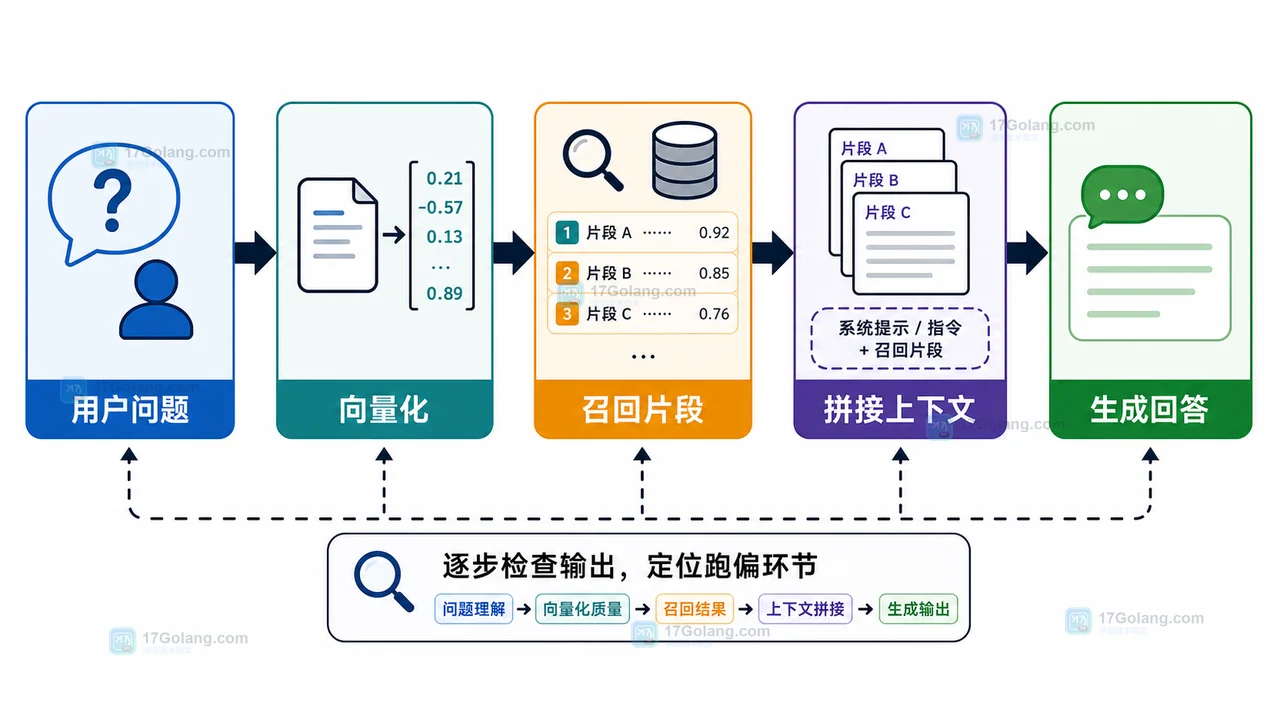
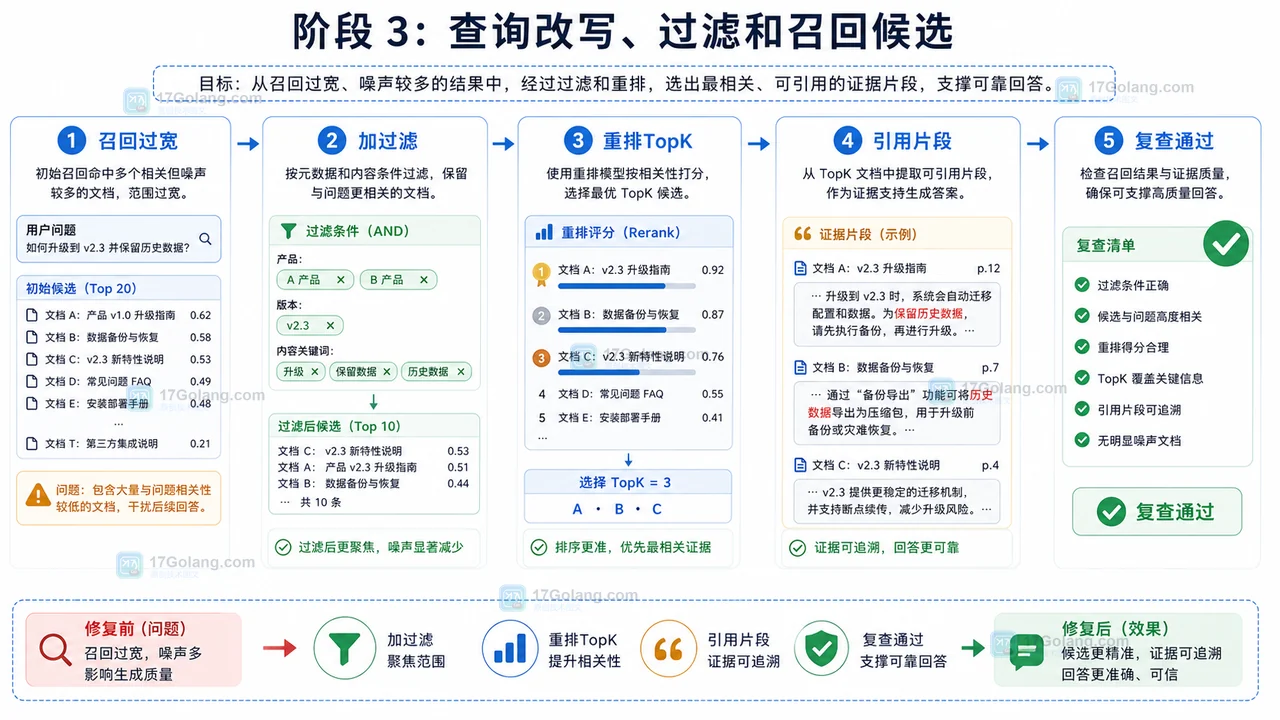
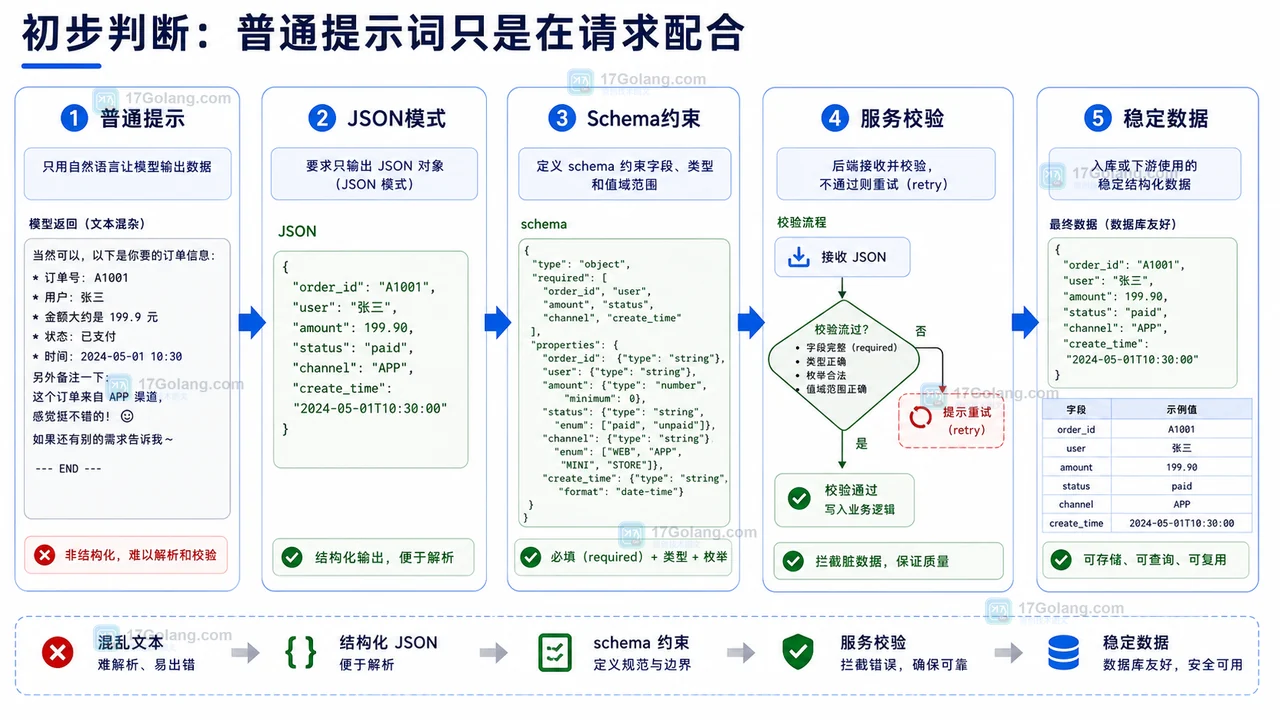
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 4495次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 4175次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 4144次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 4369次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 4313次使用
-
- AI写作工具免费版安装教程(含豆包Clawdbot)
- 2026-05-30 501浏览
-
- WPS AI能自动生成PPT吗?输入主题一键制作演示文稿
- 2026-05-27 501浏览
-
- Canva手机闪退解决方法及适配指南
- 2026-05-25 501浏览
-
- Hermes Agent依赖的工具链有哪些 必备工具链介绍
- 2026-05-05 501浏览
-
- 千问AI官网地址链接入口_千问AI官方网站登陆入口
- 2026-05-05 501浏览


