JS如何实现人脸识别?
最近发现不少小伙伴都对文章很感兴趣,所以今天继续给大家介绍文章相关的知识,本文《JS如何实现人脸识别?》主要内容涉及到等等知识点,希望能帮到你!当然如果阅读本文时存在不同想法,可以在评论中表达,但是请勿使用过激的措辞~
在JavaScript中实现人脸识别最直接的方案是使用face-api.js库,其典型流程为:1. 通过navigator.mediaDevices.getUserMedia()获取摄像头视频流并显示在video元素中;2. 使用Promise.all()加载face-api.js提供的预训练模型,包括人脸检测、特征点识别、人脸识别和表情识别模型;3. 创建canvas并调用faceapi.detectAllFaces()对视频帧进行实时检测,通过setInterval控制检测频率,并将结果绘制到canvas上。性能优化需考虑模型选择、图像降采样、Web Workers异步处理、模型量化与缓存;替代方案包括OpenCV.js、云服务API和自定义TensorFlow.js模型;实际应用中还需应对隐私保护、准确性、兼容性、部署更新和伦理问题,通过本地处理、用户引导、降级方案和公平性测试等策略解决,确保安全可靠的人脸识别功能落地。

在JavaScript中实现人脸识别,通常不是直接通过JS语言本身从零开始处理图像像素,而是依赖于强大的机器学习库,尤其是那些能在浏览器端运行的,比如基于TensorFlow.js的face-api.js。它将复杂的模型推理封装起来,让我们能用前端代码轻松调用。

解决方案
要在浏览器端用JavaScript实现人脸识别,最直接且广泛采用的路径是利用像face-api.js这样的高层库。这个库基于TensorFlow.js,提供了预训练的人脸检测、特征点识别和人脸识别模型,大大简化了开发流程。
一个典型的实现流程会是这样:

获取视频流: 使用
navigator.mediaDevices.getUserMedia()API获取用户的摄像头视频流。这是所有视觉处理的基础,它允许你将实时画面捕获到元素中。const video = document.getElementById('video'); navigator.mediaDevices.getUserMedia({ video: true }) .then(stream => { video.srcObject = stream; video.onloadedmetadata = () => { video.play(); }; }) .catch(err => { console.error("无法获取摄像头权限: ", err); alert("请允许访问摄像头以进行人脸识别。"); });加载模型:
face-api.js需要加载预训练的神经网络模型文件。这些模型通常是.json和.weights文件,决定了识别的准确性和速度。
Promise.all([ faceapi.nets.tinyFaceDetector.loadFromUri('/models'), // 轻量级人脸检测模型 faceapi.nets.faceLandmark68Net.loadFromUri('/models'), // 68个人脸特征点模型 faceapi.nets.faceRecognitionNet.loadFromUri('/models'), // 人脸识别(嵌入向量生成)模型 faceapi.nets.faceExpressionNet.loadFromUri('/models') // 表情识别(可选) ]).then(startDetection) .catch(err => console.error("模型加载失败:", err));(注意:
/models应指向你的模型文件存放路径)实时检测与绘制: 在视频流播放时,你需要定时从视频帧中检测人脸,并把结果绘制到
canvas上。let detections; let canvas; function startDetection() { canvas = faceapi.createCanvasFromMedia(video); document.body.append(canvas); // 或者添加到你想要的容器 const displaySize = { width: video.width, height: video.height }; faceapi.matchDimensions(canvas, displaySize); setInterval(async () => { detections = await faceapi.detectAllFaces(video, new faceapi.TinyFaceDetectorOptions()) .withFaceLandmarks() .withFaceExpressions(); // 如果加载了表情模型 const resizedDetections = faceapi.resizeResults(detections, displaySize); canvas.getContext('2d').clearRect(0, 0, canvas.width, canvas.height); faceapi.draw.drawDetections(canvas, resizedDetections); faceapi.draw.drawFaceLandmarks(canvas, resizedDetections); faceapi.draw.drawFaceExpressions(canvas, resizedDetections); // 绘制表情 }, 100); // 每100毫秒检测一次 }
这个核心流程搭建起来后,你就可以在此基础上进行更复杂的功能,比如人脸识别(通过比较面部嵌入向量)、活体检测等。
浏览器端人脸识别的性能考量与优化
在浏览器里跑人脸识别,性能是个绕不开的大问题。毕竟,我们面对的是用户的各种设备,从老旧的笔记本到最新的旗舰手机,硬件能力千差万别。我个人在做一些实验性项目时,就遇到过在某些设备上卡顿得像幻灯片的情况,而在另一些设备上却流畅得让人惊讶。这背后的主要考量点有几个:
首先是模型大小与加载时间。face-api.js提供了不同大小和精度的模型,比如tinyFaceDetector就比ssdMobilenetv1小很多,加载速度快,但检测精度可能会略低。选择合适的模型是第一步,如果你只是需要快速检测人脸位置,而不是高精度识别,那么小型模型是首选。模型文件通常以几十MB计,通过CDN加载或缓存,能显著提升首次加载体验。
其次是实时处理的帧率。视频流是连续的,每一帧都需要进行推理计算。这个计算量是巨大的,尤其是当画面中有多个人脸时。如果你的代码尝试以30帧/秒的速度进行全尺寸图像推理,那几乎肯定会崩溃。我的经验是,通常每秒10帧左右的检测频率已经足够用户感知为“实时”了,甚至更低一些也行。可以通过setInterval或requestAnimationFrame来控制检测频率,而不是每一帧都跑。
再者,设备本身的硬件能力是决定性因素。拥有独立显卡或较新集成显卡的设备,通过WebGL加速TensorFlow.js的计算,性能会好很多。而老旧的CPU设备,纯靠CPU计算,就显得力不从心了。
为了优化,可以尝试以下策略:
- 降采样图像: 在将视频帧送入模型之前,将其尺寸缩小。例如,将1080p的视频帧缩放到480p或更小。虽然会损失一些细节,但计算量会呈指数级下降,对检测精度影响不一定很大。
- Web Workers: 将模型加载和推理计算放到Web Worker中进行。这样可以避免阻塞主线程,让UI保持响应。用户就不会觉得页面“卡死”了,即使后台计算很忙。不过,数据在主线程和Worker之间传递也需要开销,需要权衡。
- 模型选择与量化: 如前所述,选择更轻量级的模型。或者,如果可能,使用经过量化(quantized)的模型。量化可以显著减小模型体积和计算量,但可能会牺牲一点精度。
- 缓存模型: 利用Service Worker或IndexedDB缓存模型文件,避免每次访问都重新下载。
总的来说,性能优化是一个不断权衡和测试的过程,没有一劳永逸的方案,得根据具体应用场景和目标用户群来调整。
选择合适的人脸识别库:face-api.js与其它选项
在JavaScript生态里做人脸识别,face-api.js无疑是目前最受欢迎和成熟的选择之一。但它并非唯一,了解其他选项能帮助你根据项目需求做出更明智的决策。
face-api.js: 这是我个人最常用也最推荐的。它的核心优势在于:
- 易用性: API设计直观,上手快。几行代码就能实现人脸检测、特征点、表情识别等。
- 基于TensorFlow.js: 意味着它能充分利用浏览器端的硬件加速(WebGL),性能相对有保障。
- 功能全面: 不仅有基础的检测,还有特征点、表情、年龄性别、以及生成面部嵌入向量用于人脸识别(Face Recognition)的功能。
- 活跃的社区和文档: 遇到问题时容易找到解决方案和参考。
- 预训练模型: 提供了多种预训练模型,开箱即用,省去了自己训练的麻烦。
然而,face-api.js也有它的局限性。它主要面向浏览器端,模型相对固定,如果你需要非常定制化的模型或者更底层的控制,可能就不那么合适了。
其他选项:
- OpenCV.js: 这是OpenCV这个C++计算机视觉库的JavaScript版本。它提供了更广泛的计算机视觉功能,不仅仅是人脸识别。
- 优点: 功能极其强大,几乎涵盖了所有计算机视觉领域。如果你需要进行图像处理、物体检测、图像分割等更复杂的任务,OpenCV.js是更好的选择。
- 缺点: 库文件体积较大,学习曲线较陡峭,API不如
face-api.js那么“开箱即用”地针对人脸识别进行优化。对于单纯的人脸识别任务,可能会显得“杀鸡用牛刀”。我曾经尝试用它来做一些简单的图像滤镜,发现其灵活性很高,但配置和调试确实比专门的库要复杂。
- 商业云服务API(例如:AWS Rekognition, Azure Face API, Google Cloud Vision AI): 这些服务通常提供RESTful API,你可以在前端通过JavaScript调用它们。
- 优点: 精度高,性能由云端保障,无需担心客户端设备性能,功能通常更丰富(如大规模人脸库管理、名人识别等)。部署和维护成本低,不需要自己管理模型。
- 缺点: 成本按调用量计费,可能会比较高。数据需要上传到云端,存在隐私和网络延迟问题。对于需要严格离线或本地处理的场景不适用。
- 自定义TensorFlow.js模型: 如果你有特定的需求,比如需要识别的特征非常独特,或者想要更小的模型、更快的推理速度,可以自己使用TensorFlow.js训练和部署模型。
- 优点: 极致的定制化和优化空间。
- 缺点: 需要深入的机器学习知识,包括模型设计、训练、优化和转换。这对于前端开发者来说,通常是个不小的挑战。
总结来说,对于大多数Web端人脸检测和基本识别需求,face-api.js是最高效、最便捷的路径。如果你需要更底层的图像处理能力,考虑OpenCV.js。而对于大规模、高精度、且对网络延迟不敏感的场景,云服务API是更优解。
人脸识别在Web应用中的常见挑战与解决方案
在Web应用中集成人脸识别,听起来很酷,但实际操作起来会遇到不少“坑”。这些挑战不仅限于技术层面,也涉及到用户体验、隐私和伦理等多个维度。我曾在一个内部项目中尝试做人脸签到,就遇到了各种意想不到的问题。
1. 隐私与用户信任问题: 这是最核心也是最敏感的挑战。用户对于摄像头访问和生物特征数据的使用非常警惕。
- 挑战: 未经许可的摄像头访问、数据如何存储和处理、数据泄露风险。
- 解决方案:
- 明确告知与授权: 在获取摄像头权限前,清晰地告知用户为何需要访问摄像头,数据将如何使用,是否会上传、存储,以及如何保护。使用
getUserMedia时,浏览器会弹出权限请求,但你可以在这之前提供更详细的说明。 - 本地处理优先: 尽可能在用户浏览器本地进行人脸识别处理,避免将原始图像或面部特征数据上传到服务器,除非业务逻辑确实需要。
face-api.js等库的优势就在于此。 - 数据匿名化: 如果确实需要上传数据,只上传经过哈希或加密的面部嵌入向量,而不是原始图像。
- 删除机制: 提供用户删除其生物特征数据的选项。
- 明确告知与授权: 在获取摄像头权限前,清晰地告知用户为何需要访问摄像头,数据将如何使用,是否会上传、存储,以及如何保护。使用
2. 准确性与鲁棒性不足: 在真实世界中,光照、角度、遮挡等因素都会严重影响识别效果。
- 挑战: 低光照、逆光、侧脸、戴眼镜/帽子、面部表情变化、多人同时入镜、背景复杂。
- 解决方案:
- 用户引导: 提示用户保持良好光照、正对摄像头、移除遮挡物(如口罩、墨镜)。
- 多角度捕捉: 如果是注册或验证,可以引导用户在不同角度下捕捉多张照片,提高识别模型的鲁棒性。
- 活体检测: 引入活体检测机制(如眨眼、摇头、张嘴),防止照片或视频欺骗。
face-api.js本身不直接提供活体检测,但可以通过结合面部特征点变化和自定义逻辑来实现。 - 模型优化: 选择更强大的模型,或针对特定场景进行模型微调(如果资源允许)。
3. 跨浏览器兼容性与设备性能差异:
不同的浏览器对WebRTC(getUserMedia)和WebGL的支持程度有差异,设备性能更是千差万别。
- 挑战:
getUserMedia在某些老旧浏览器或特定版本中可能存在兼容性问题;低端设备运行机器学习模型时性能低下,导致卡顿甚至崩溃。 - 解决方案:
- 渐进增强: 提供优雅降级方案。如果浏览器不支持
getUserMedia或性能不足,可以退回到传统的图片上传方式。 - 性能优化: (如前文所述)降采样、Web Workers、选择轻量级模型、限制检测频率。
- 错误处理: 对
getUserMedia的权限拒绝、设备不可用等错误进行友好提示。
- 渐进增强: 提供优雅降级方案。如果浏览器不支持
4. 模型部署与更新: 如何高效地将模型文件部署到Web服务器,并确保用户能及时获取最新模型。
- 挑战: 模型文件体积大,加载慢;模型更新后,用户可能仍在缓存旧模型。
- 解决方案:
- CDN部署: 将模型文件部署到CDN上,利用其全球分发和缓存优势,加速加载。
- 版本控制: 在模型文件路径中加入版本号(如
/models/v2/),或在文件名中加入哈希值,确保每次更新都能强制用户加载最新版本。 - Service Worker缓存: 利用Service Worker对模型文件进行离线缓存和更新策略管理。
5. 伦理与社会影响: 人脸识别技术可能引发的偏见、歧视和滥用问题。
- 挑战: 模型可能存在偏见(例如对某些肤色或性别的人识别率较低);技术可能被用于监控或侵犯个人自由。
- 解决方案:
- 公平性测试: 在开发和测试阶段,确保模型在不同人群(肤色、性别、年龄等)上的表现公平。
- 透明度: 告知用户技术的使用范围和限制。
- 负责任的使用: 避免将技术应用于具有歧视性或侵犯人权的目的。
这些挑战都需要在设计和开发阶段就充分考虑,并采取相应的策略来规避或解决,确保技术能以负责任和用户友好的方式落地。
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于文章的相关知识,也可关注golang学习网公众号。
 Prisma查询不返回数组?解决方法大全
Prisma查询不返回数组?解决方法大全
- 上一篇
- Prisma查询不返回数组?解决方法大全

- 下一篇
- Win11显示我的电脑图标教程
-
- 文章 · 前端 | 14小时前 | 定时器 · 前端 · 性能排查 · 接口请求 · 轮询 · setInterval · setInterval 页面可见性 clearInterval 前端轮询 请求堆积 定时器清理
- 前端轮询接口越打越多怎么办:从重复定时器到清理机制一步步排查
- 490浏览 收藏
-
- 文章 · 前端 | 16小时前 | 前端 · 搜索框 · AbortController · 接口请求 · 状态管理 · Fetch AbortController 前端搜索 请求乱序 旧响应覆盖
- 前端搜索结果倒退怎么办:AbortController 取消旧请求和序号兜底
- 295浏览 收藏
-
- 文章 · 前端 | 19小时前 | 前端 · 性能优化 · cls · 懒加载 · Core Web Vitals · 前端 图片懒加载 IntersectionObserver CLS 布局稳定
- 前端图片懒加载布局抖动治理完整流程:占位比例、按需加载和 CLS 复查
- 128浏览 收藏
-

- 文章 · 前端 | 1天前 | 工程化 · 前端 · javascript · css · 弹窗 · 前端 z-index 遮罩层 stacking context Portal 弹窗层级
- 前端弹窗层级治理工作流:从 z-index 混乱到 Portal 容器规范
- 350浏览 收藏
-
- 文章 · 前端 | 1天前 | 前端 · javascript · URL参数 · 列表筛选 · 页面状态 · 前端 筛选条件 列表页 history.replaceState URLSearchParams 刷新还原
- 前端筛选条件刷新后丢失怎么办:从内存状态到 URL 参数一步步排查
- 348浏览 收藏
-
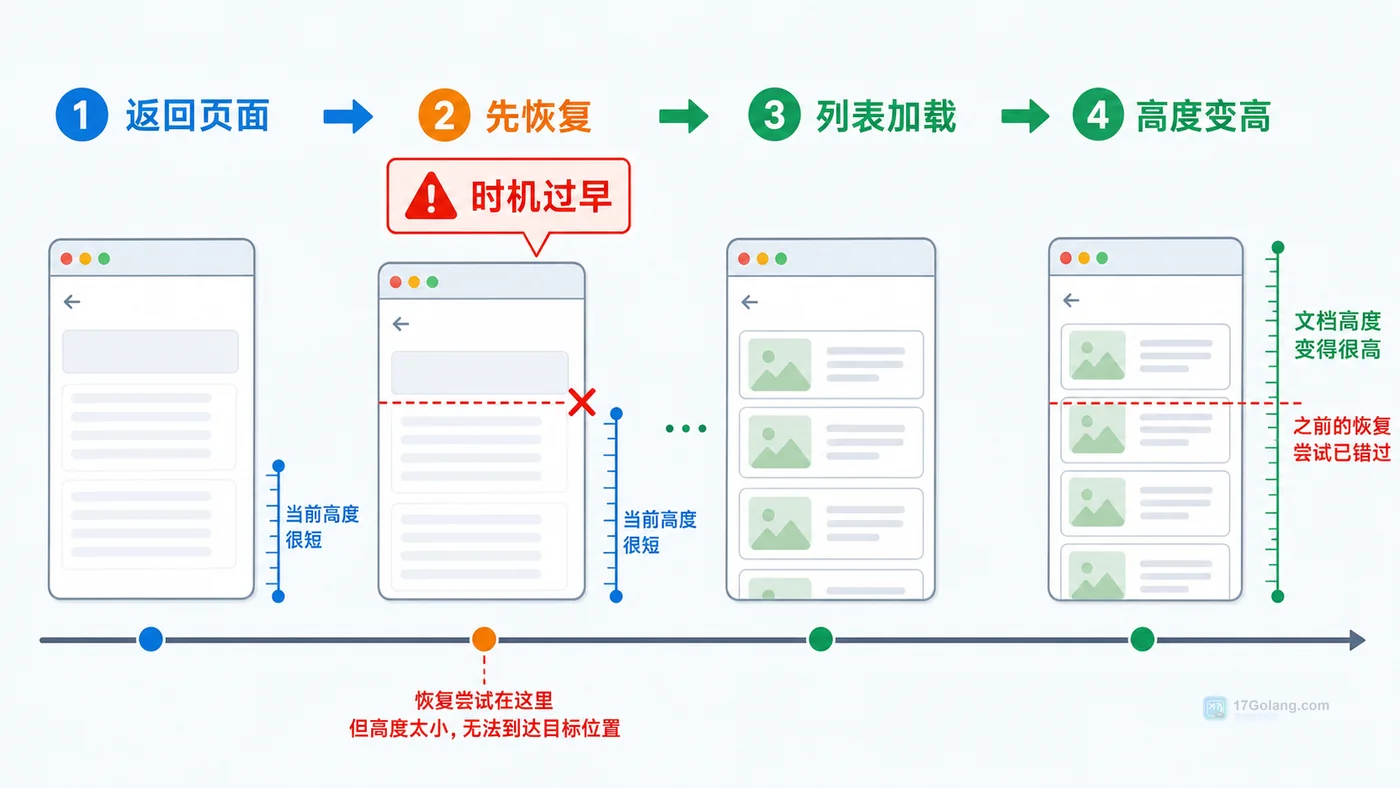
- 文章 · 前端 | 1天前 | 前端 · 性能优化 · 路由 · javascript · 前端 用户体验 滚动位置 路由缓存 scrollRestoration
- 前端详情页返回列表丢失滚动位置怎么办:从复现到恢复一步步排查
- 458浏览 收藏
-
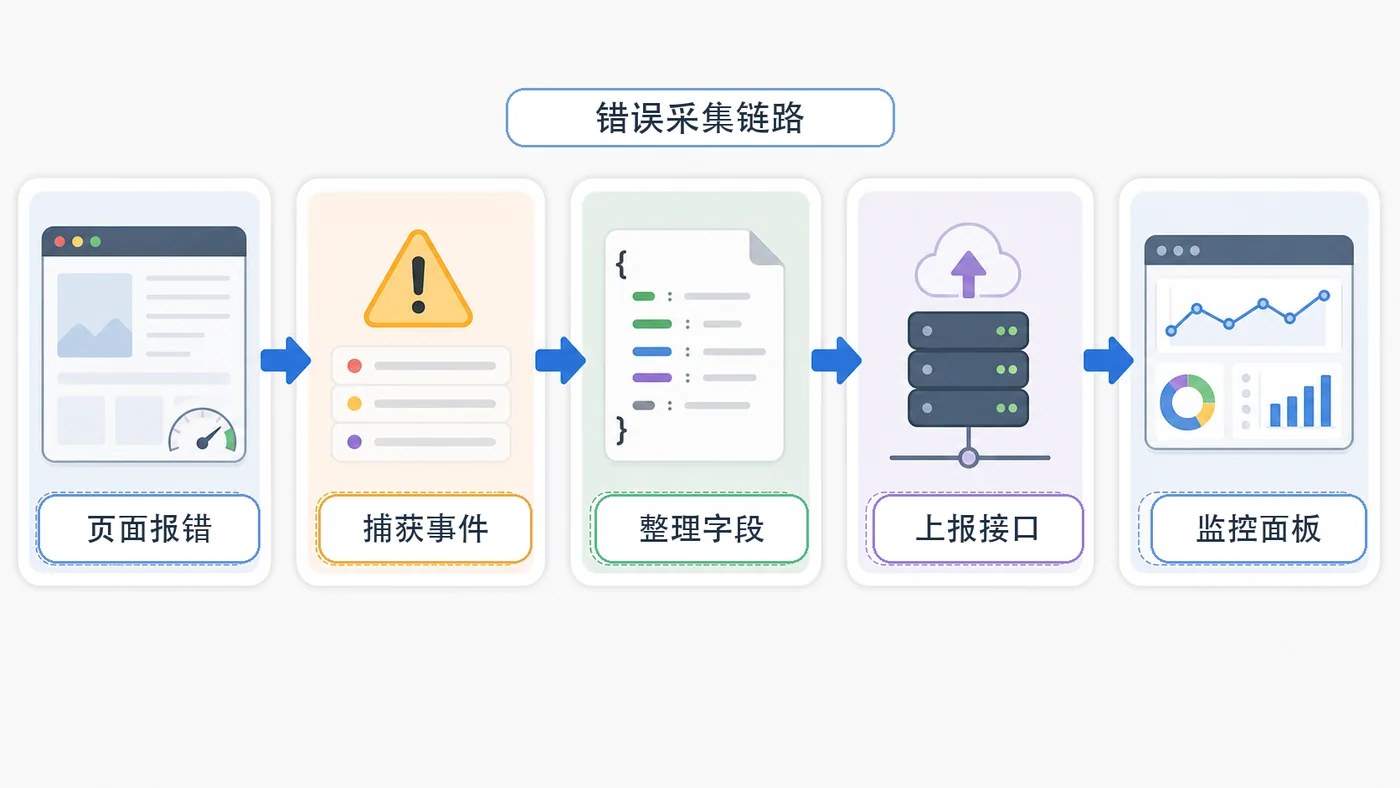
- 文章 · 前端 | 3天前 | 前端 · javascript · sourcemap · 错误监控 · 线上排查 · 前端 错误监控 告警 onerror sourcemap unhandledrejection
- 前端错误监控实战:onerror、unhandledrejection 和 sourcemap 定位问题
- 331浏览 收藏
-
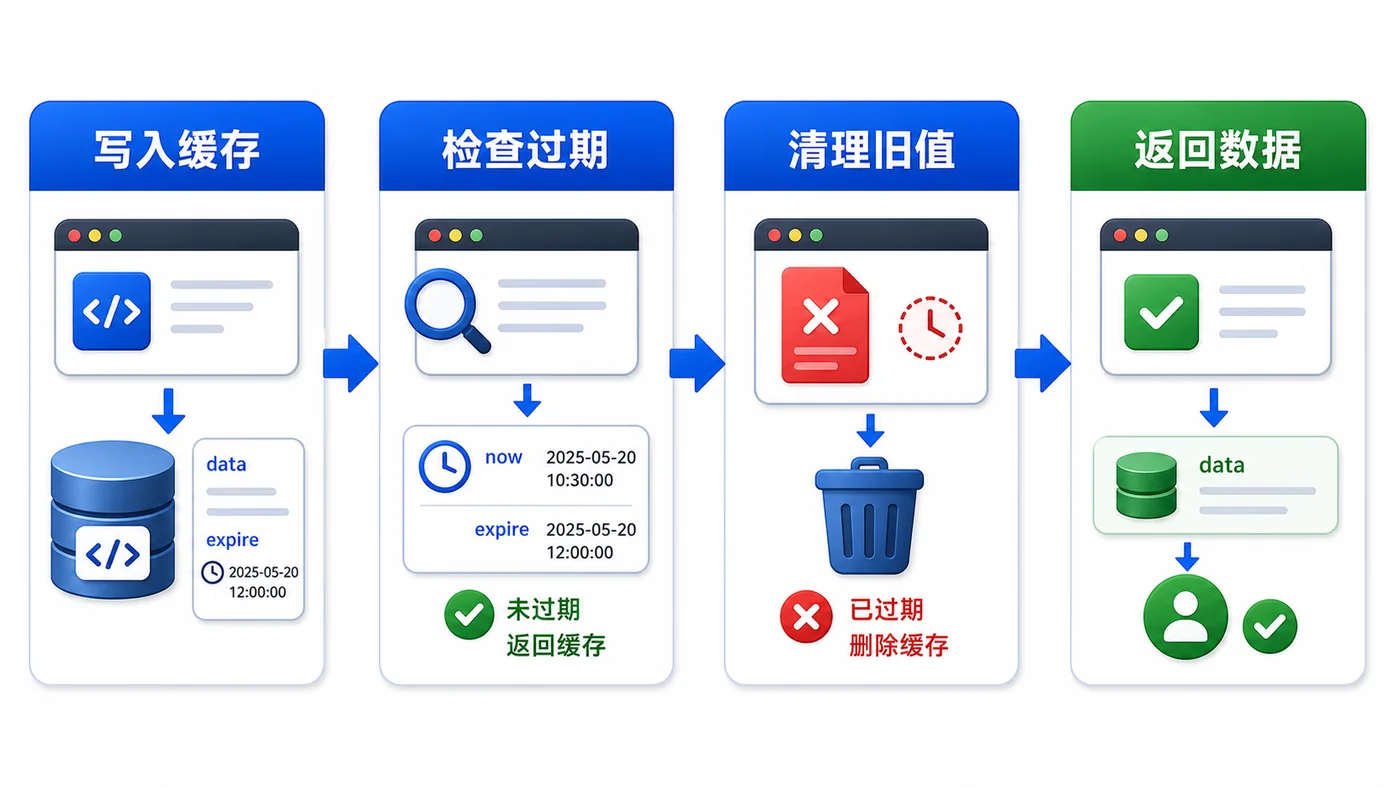
- 文章 · 前端 | 3天前 | 前端 · javascript · 缓存治理 · localStorage · Web性能 · 前端 本地缓存 localStorage 过期时间 版本迁移 异常兜底
- 前端 localStorage 缓存治理实战:过期时间、版本号和异常兜底
- 480浏览 收藏
-
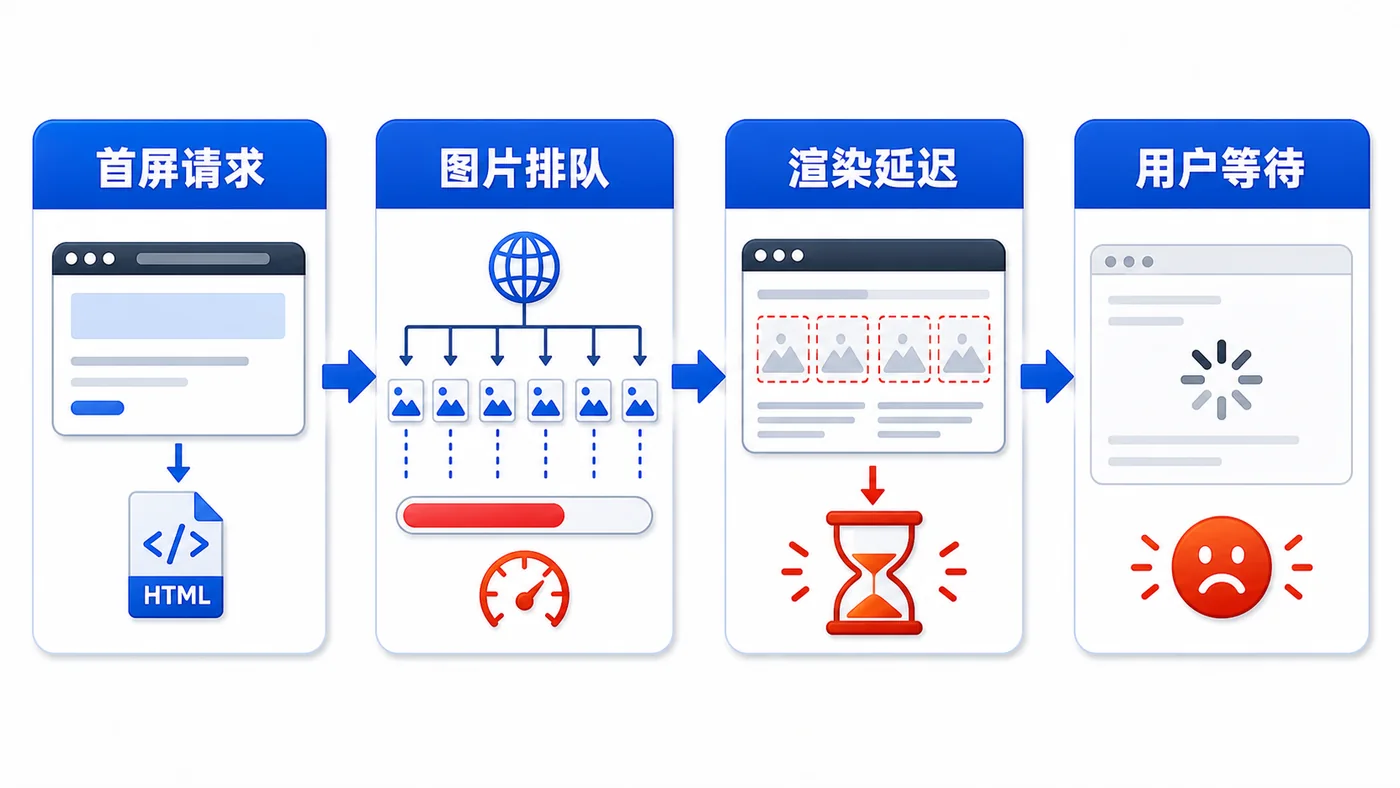
- 文章 · 前端 | 3天前 | 前端 · 性能优化 · javascript · 图片优化 · IntersectionObserver · 前端 性能优化 图片懒加载 IntersectionObserver Web性能 首屏优化
- 前端图片懒加载实战:用 IntersectionObserver 降低首屏压力
- 184浏览 收藏

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 216次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 239次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 208次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 374次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 372次使用
-
- JavaScript函数定义及示例详解
- 2025-05-11 502浏览
-
- 优化用户界面体验的秘密武器:CSS开发项目经验大揭秘
- 2023-11-03 501浏览
-
- 使用微信小程序实现图片轮播特效
- 2023-11-21 501浏览
-
- 解析sessionStorage的存储能力与限制
- 2024-01-11 501浏览
-
- 探索冒泡活动对于团队合作的推动力
- 2024-01-13 501浏览


