WorldGPT来了:打造类Sora视频AI智能体,「复活」图文
目前golang学习网上已经有很多关于科技周边的文章了,自己在初次阅读这些文章中,也见识到了很多学习思路;那么本文《WorldGPT来了:打造类Sora视频AI智能体,「复活」图文》,也希望能帮助到大家,如果阅读完后真的对你学习科技周边有帮助,欢迎动动手指,评论留言并分享~
OpenAI 的 Sora 在今年 2 月惊艳亮相,为文本生成视频带来了全新的突破。它可以根据文字输入创作出仿佛来自好莱坞的逼真且充满想象力的影片,让人叹为观止。许多人都对这一创新赞叹不已,认为OpenAI 的表现实现了巅峰之作。
Sora引发的热潮持续不减,同时研究者们也开始认识到AI视频生成技术的巨大潜力,这一领域正受到越来越多人的关注。
然而,当前 AI 视频生成领域,大部分算法研究将重点放在了通过文本提示生成视频,对于多模态输入,特别是图片与文本结合的场景,并没有进行深入探讨或广泛应用。这种偏向降低了生成视频的多样性和可控制性,限制了从静态图像到动态视频的转换能力。
另一方面,现有的大部分视频生成模型对生成视频内容缺乏可编辑性的支持,无法满足用户对生成视频进行个性化调整的需求。


提示:把熊猫变成熊,并且让它跳舞。(Change the panda to a bear and make it dance.)
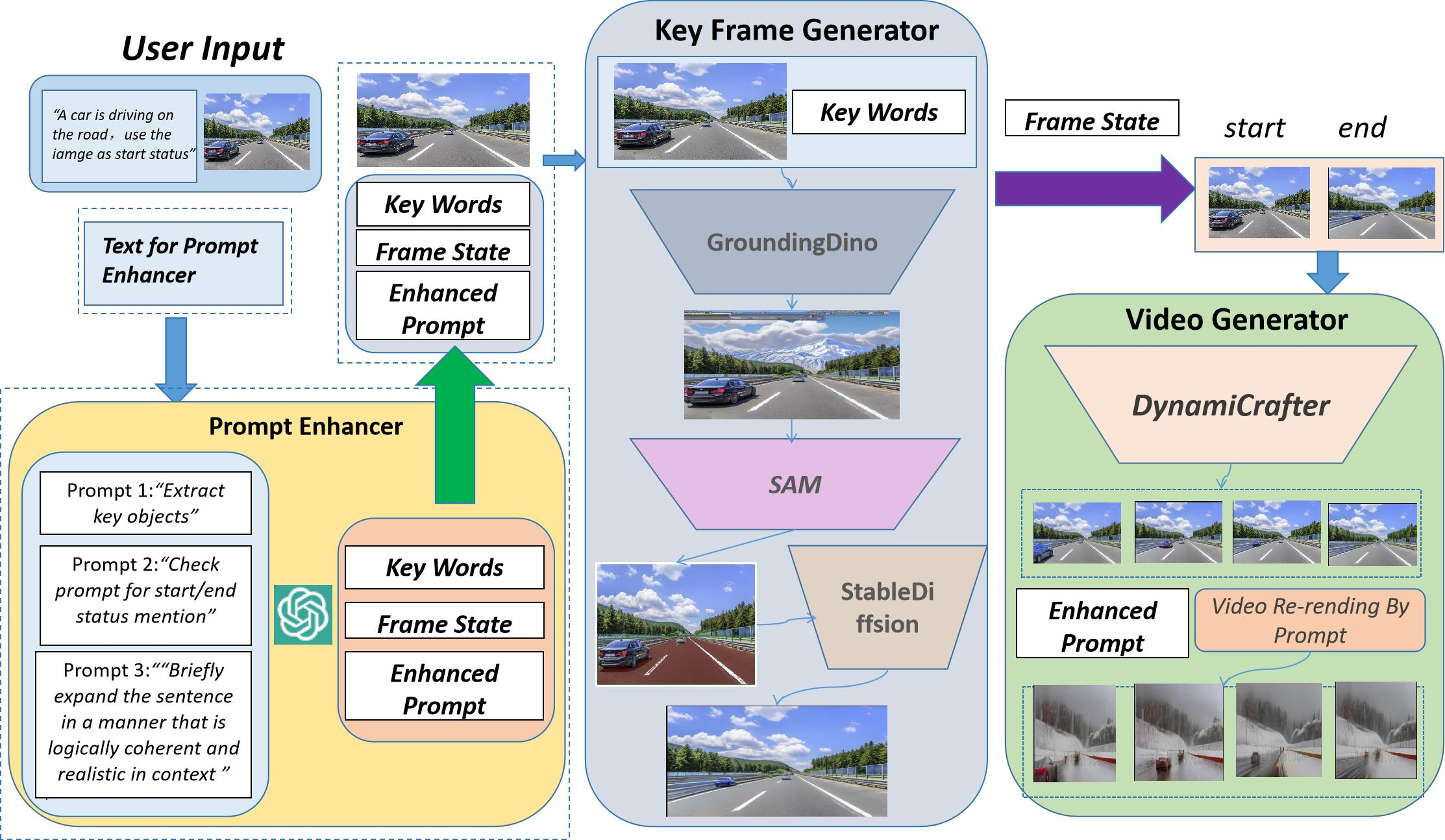
本文,来自 SEEKING AI、哈佛大学、斯坦福大学以及北京大学的研究者们共同提出了一种创新的基于图片 - 文本的视频生成编辑统一框架,名为 WorldGPT。该框架建立在 SEEKING AI 与上述顶尖高校共同研发的 VisionGPT 框架之上,不仅能够实现由图片和文本直接生成视频的功能,还支持通过简单的文本提示(prompt)对生成视频进行风格迁移、背景替换等一系列视频外观编辑操作。
该框架的另一个显著优势在于其无需进行训练,这使得技术门槛大幅降低,同时也使得部署和使用变得非常方便。用户可以直接使用模型进行创作,而无需关注背后繁琐的训练过程。

- 论文地址:https://arxiv.org/pdf/2403.07944.pdf
- 论文标题:WorldGPT: A Sora-Inspired Video AI Agent as Rich World Models from Text and Image Inputs
接下来我们看看 WorldGPT 在多种复杂视频生成控制场景中的示例展示。
背景替换 + 生成视频
提示:「一支船队在呼啸的风暴中奋力前行,他们的船帆在无情风暴的巨浪中航行。(A fleet of ships pressed on through the howling tempest, their sails billowing as they navigated the towering waves of the relentless storm.)」


背景替换 + 风格化 + 生成视频
提示:「一条可爱的龙在城市的街道上喷火。(A cute dragon is spitting fire on an urban street.)」


对象替换 + 背景替换 + 生成视频
提示:「一个赛博朋克风格的机器人在霓虹灯照亮的反乌托邦城市景观中疾驰,高耸的全息图和数字衰变的反射投影到其光滑的金属机身上。(A cyberpunk-style automaton raced through the neon-lit, dystopian cityscape, reflections of towering holograms and digital decay playing across its sleek, metallic body.)」


从上面的示例可以看出,WorldGPT 在面对复杂视频生成指令时具有以下优点:
1)较好的保持了原输入图像的结构和环境;
2)生成符合图片 - 文本描述的生成视频,展现出了强大的视频生成定制能力;
3)可以通过 prompt 对生成视频进行定制化编辑。
了解更多有关 WorldGPT 的原理、实验和用例的信息,请查看原论文。
VisonGPT
前面已经提到,WorldGPT 框架建立在 VisionGPT 框架之上。接下来我们简单介绍一下有关 VisionGPT 的信息。
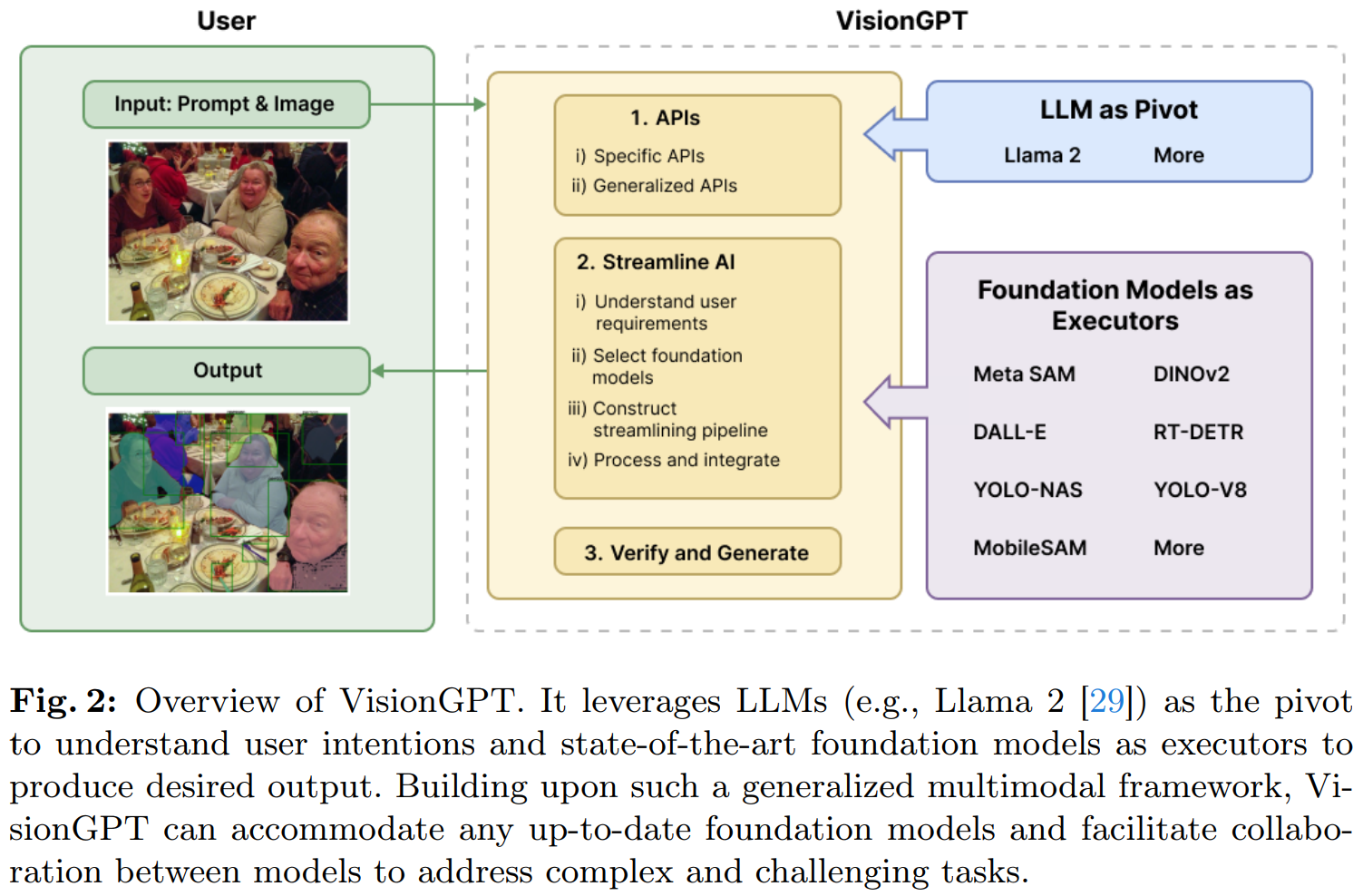
VisionGPT 是由 SeekingAI、斯坦福大学、哈佛大学及北京大学等世界顶尖机构联合研发,是一款开创性的开放世界视觉感知大模型框架。该框架通过智能整合和决策选择最先进的 SOTA 大模型,提供了强大的 AI 多模态图像处理功能。
VisionGPT 的创新之处主要体现在三个方面:
- 首先,它以大型语言模型(例如 LLaMA-2)为核心,将用户的 prompt 请求分解成详细的步骤需求,并自动化调用最合适的大模型进行处理;
- 其次,VisionGPT 自动接受并融合来自多个 SOTA 大模型产生的多模态输出,从而生成针对用户需求的图像处理结果;
- 最后,VisionGPT 具有极高的灵活性和多功能性,无需用户对模型进行微调,就能够支持包括文本驱动的图像理解、生成、编辑在内的广泛应用场景。

- 论文地址:https://arxiv.org/pdf/2403.09027.pdf
- 论文标题:VisionGPT: Vision-Language Understanding Agent Using Generalized Multimodal Framework
VisionGPT 用例

从上面可以看出,VisionGPT 无需 fine-tune,即可以轻松实现 1)开放世界的实例分割;2)基于 prompt 的图像生成和编辑功能等。VisionGPT 的工作流程如下图所示。
更多详细信息可以参考论文。
VisionGPT-3D
此外,研究者们还推出了 VisionGPT-3D,旨在解决从文本到视觉元素转换中的一大挑战:如何高效、准确地将 2D 图像转换成 3D 表示。在这个过程中,经常面临算法与实际需求不匹配的问题,从而影响最终结果的质量。VisionGPT-3D 通过整合多种最先进的 SOTA 视觉大模型,提出了一个多模态框架,优化了这一转换流程。其核心创新点在于自动选择最适合的视觉 SOTA 模型和 3D 点云创建算法,并且根据文本提示等多模态输入生成最符合用户需求的输出的能力。

- 论文地址:https://arxiv.org/pdf/2403.09530v1.pdf
- 论文标题: VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
了解更多信息,请参考原论文。
本篇关于《WorldGPT来了:打造类Sora视频AI智能体,「复活」图文》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于科技周边的相关知识,请关注golang学习网公众号!
 返回 Golang 中的联合类型
返回 Golang 中的联合类型
- 上一篇
- 返回 Golang 中的联合类型

- 下一篇
- java创建jar包并被项目引用的方法
-

- 科技周边 · 人工智能 | 1星期前 | AI绘画
- AI绘画工具安装与配置教程
- 339浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- 海螺AI语音功能测评与体验分享
- 260浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- ChatGPT读不了加密PDF?先解密再上传
- 438浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- 千问AI测试规范与覆盖率提升技巧
- 152浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- MiniMaxMusic2.0专业模式上线:音乐创作新神器
- 232浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- 即梦AI音乐可视化效果评测
- 280浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 | 豆包AI 豆包AI助手
- 豆包AI写诗技巧与教程分享
- 152浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 | openclaw
- OpenClawAI摘要生成技巧全解析
- 102浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- 百度发布DuMate智能体,李彦宏解读DAA新定义
- 247浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- 智谱清影制作鸟瞰街景镜头教程
- 306浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 | openclaw
- OpenClaw框架解析与技术亮点揭秘
- 357浏览 收藏
-

- 科技周边 · 人工智能 | 1星期前 |
- 即梦AI美妆详情页提示词技巧
- 334浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 7479次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 7900次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 7708次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 9649次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 8439次使用
-
- GPT-4王者加冕!读图做题性能炸天,凭自己就能考上斯坦福
- 2023-04-25 501浏览
-
- 单块V100训练模型提速72倍!尤洋团队新成果获AAAI 2023杰出论文奖
- 2023-04-24 501浏览
-
- ChatGPT 真的会接管世界吗?
- 2023-04-13 501浏览
-
- VR的终极形态是「假眼」?Neuralink前联合创始人掏出新产品:科学之眼!
- 2023-04-30 501浏览
-
- 实现实时制造可视性优势有哪些?
- 2023-04-15 501浏览


