如何实现等待所有线程完成工作,当任何一个线程发现新信息时?
欢迎各位小伙伴来到golang学习网,相聚于此都是缘哈哈哈!今天我给大家带来《如何实现等待所有线程完成工作,当任何一个线程发现新信息时?》,这篇文章主要讲到等等知识,如果你对Golang相关的知识非常感兴趣或者正在自学,都可以关注我,我会持续更新相关文章!当然,有什么建议也欢迎在评论留言提出!一起学习!
一个看似简单的同步问题
tl;dr
多个线程相互依赖。每当他们中的一个发现一些新信息时,他们所有人都需要处理该信息。如何确定所有线程都已准备好?
背景
我(几乎)并行化了一个函数 foo(input) 来解决一个问题,已知该函数是 p 完全的,并且可以被认为是某种类型的搜索。毫不奇怪,到目前为止,没有人能够成功地利用两个线程之外的并行性来解决该问题。然而,我有一个很有前途的想法,并设法完全实现它,除了这个看似简单的问题。
详细信息
每个线程之间的信息是使用某种类型为 g 的共享图形数据库 g 隐式交换的,这样线程就可以立即拥有所有信息,并且实际上不需要显式地相互通知。更准确地说,每次某个线程找到信息 i 时,该线程都会调用线程安全函数 g.addinformation(i) ,该函数基本上将信息 i 放置在某个数组的末尾。我的新实现的一方面是,线程可以在搜索过程中使用信息 i,甚至在 i 已排入数组末尾之前。然而,每个线程在信息 i 入队后还需要单独处理该信息。添加 i 的线程从 g.addinformation(i) 返回后,可能会发生 i 排队。这是因为其他一些线程可能会接管将 i 排队的责任。
每个线程 s 调用函数 s.processallinformation() 以便按顺序处理 g 中该数组中的所有信息。某个线程对 s.processallinformation 的调用是 noop,即,如果该线程已经处理了所有信息或没有(新)信息,则不执行任何操作。
一旦线程处理完所有信息,它就应该等待所有其他线程完成。如果任何其他线程发现一些新信息 i,它应该恢复工作。 ie。每次某个线程调用 g.addinformation(i) 时,所有已完成处理所有先前已知信息的线程都需要恢复其工作并处理该(以及任何其他)新添加的信息。
我的问题
我认为的任何解决方案都不起作用,并且会遇到同一问题的变体:一个线程完成了所有信息的处理,然后看到所有其他线程也都准备好了。因此,该线程离开。但随后另一个线程注意到添加了一些新信息,恢复工作并找到新信息。新的信息将不会被已经离开的线程处理。
解决这个问题的方法可能很简单,但我想不出一个。理想情况下,此问题的解决方案不应依赖于每当发现新信息时对 g.addinformation(i) 的函数调用期间的耗时操作,因为预计这种情况每秒会出现多少次(1 或 2每秒百万次,见下文)。
更多背景
在我最初的顺序应用程序中,函数 foo(input) 在现代硬件上每秒被调用大约 100k 次,并且我的应用程序花费 80% 到 90% 的时间执行 foo(input)。实际上,对 foo(input) 的所有函数调用都是相互依赖的,我们有点以迭代的方式在一个非常大的空间中搜索某些东西。使用应用程序的顺序版本时,解决合理大小的问题通常需要大约一两个小时。
每次调用 foo(input) 时,都会发现零到数百个新信息。在我的应用程序执行期间,平均每秒会发现 1 或 200 万条信息,即我们在对 foo(input) 的每个函数调用中发现 10 到 20 个新信息。所有这些统计数据可能都有非常高的标准差(不过我还没有测量)。
目前我正在用 go 编写 foo(input) 并行版本的原型。我更喜欢 go 中的答案。顺序应用程序是用 c 编写的(实际上是 c++,但其编写方式就像用 c 编写的程序)。所以 c 或 c++(或伪代码)的答案是没有问题的。我还没有对我的原型进行基准测试,因为错误的代码比慢速代码要慢得多。
代码
此代码示例是为了澄清。由于我还没有解决问题,请随意考虑对代码进行任何更改。 (我也很欣赏无关的有用评论。)
全球形势
我们有一些类型 g 和 foo() 是 g 的方法。如果 g 是 g 类型的对象,并且当调用 g.foo(input) 时,g 创建一些获取指向 zqbc 指针的工作线程 s[1], ..., s[g.numthreads] zqbg,这样它们可以访问 g 的成员变量,并且每当发现新信息时都可以调用 g.addinformation(i) 。然后,对于每个worker s[j],并行调用方法fooinparallel()。
type g struct {
s []worker
numthreads int
// some data, that the workers need access to
}
func (g *g) initializewith(input inputtype) {
// some code...
}
func (g *g) foo(input inputtype) int {
// initialize data-structures:
g.initializewith(input)
// initialize workers:
g.s := make([]worker, g.numthreads)
for j := range g.s {
g.s[j] := newworker(g) // workers get a pointer to g
}
// note: this wait group doesn't solve the problem. see remark below.
wg := new(sync.waitgroup)
wg.add(g.numthreads)
// actual computation in parallel:
for j := 0 ; j < g.numthreads - 1 ; j++ {
// start g.numthread - 1 go-routines in parrallel
go g.s[j].fooinparallel(wg)
}
// last thread is this go-routine, such that we have
// g.numthread go-routines in total.
g.s[g.numthread-1].fooinparallel(wg)
wg.wait()
}
// this function is thread-safe in so far as several
// workers can concurrently add information.
//
// the function is optimized for heavy contention; most
// threads can leave almost immediately. one threads
// cleans up any mess they leave behind (and even in
// bad cases that is not too much).
func (g *g) addinformation(i infotype) {
// step 1: make information available to all threads.
// step 2: enqueue information at the end of some array.
// step 3: possibly, call g.notifyall()
}
// if a new information has been added, we must ensure,
// that every thread, that had finished, resumes work
// and processes any newly added informations.
func (g *g) notifyall() {
// todo:
// this is what i fail to accomplish. i include
// my most successful attempt in the corresponding.
// section. it doesn't work, though.
}
// if a thread has finished processing all information
// it must ensure that all threads have finished and
// that no new information have been added since.
func (g *g) allthreadsready() bool {
// todo:
// this is what i fail to accomplish. i include
// my most successful attempt in the corresponding.
// section. it doesn't work, though.
}
备注:等待组的唯一目的是确保在最后一个工作程序返回之前不会再次调用 foo(input)。但是,您可以完全忽略这一点。
当地情况
每个工作线程都包含一个指向全局数据结构的指针,并搜索宝藏或新信息,直到处理完由该线程或其他线程排队的所有信息。如果它找到新信息 i,它将调用函数 g.addinformation(i) 并继续其搜索。如果它找到宝藏,它会通过作为参数获得的通道发送宝藏并返回。如果所有线程都准备好处理所有信息,则每个线程都可以向通道发送一个虚拟宝藏并返回。然而,确定所有线程是否准备就绪正是我的问题。
type worker struct {
// each worker contains a pointer to g
// such that it has access to its member
// variables and is able to call the
// function g.addinformation(i) as soon
// as it finds some information i.
g *g
// also contains some other stuff.
}
func (s *worker) fooinparallel(wg *sync.waitgroup) {
defer wg.done()
for {
a := s.processallinformation()
// the following is the problem. feel free to make any
// changes to the following block.
s.notifyall()
for !s.needstoresumework() {
if s.allthreadsready() {
return
}
}
}
}
func (s *worker) notifyall() {
// todo:
// this is what i fail to accomplish. i include
// my most successful attempt in the corresponding.
// section. it doesn't work, though.
// an example:
// step 1: possibly, do something else first.
// step 2: call g.notifyall()
}
func (s *worker) needstoresumework() bool {
// todo:
// this is what i fail to accomplish. i include
// my most successful attempt in the corresponding.
// section. it doesn't work, though.
}
func (s *worker) allthreadsready() bool {
// todo:
// this is what i fail to accomplish. i include
// my most successful attempt in the corresponding.
// section. it doesn't work, though.
// if all threads are ready, return true.
// otherwise, return false.
// alternatively, spin as long as no new information
// has been added, and return false as soon as some
// new information has been added, or true if no new
// information has been added and all other threads
// are ready.
//
// however, this doesn't really matter, because a
// function call to processallinformation is cheap
// if no new informations are available.
}
// a call to this function is cheap if no new work has
// been added since the last function call.
func (s *worker) processallinformation() treasuretype {
// access member variables of g and search
// for information or treasures.
// if a new information i is found, calls the
// function g.addinformation(i).
// if all information that have been enqueued to
// g have been processed by this thread, returns.
}
我为解决问题所做的最大尝试
好吧,现在我已经很累了,所以我稍后可能需要仔细检查我的解决方案。然而,即使我的 correct 尝试也不起作用。因此,为了让您了解我迄今为止所做的尝试(以及许多其他事情),我立即分享。
我尝试了以下方法。每个worker都包含一个成员变量needstoresumework,每当添加新信息时,该变量就会自动设置为1。多次将此成员变量设置为 1 不会造成任何损害,唯一重要的是线程在添加最后一个信息后恢复工作。
为了减少每当找到信息 i 时调用 g.addinformation(i) 的线程的工作负载,不是单独通知所有线程,而是将信息入队的线程(不一定是调用 g 的线程) .addinformation(i))随后将notifyallflag的一个成员变量g设置为1,表示需要通知所有线程最新的信息。
每当一个处理完已排队的所有信息的线程调用函数 g.notifyall() 时,它都会检查成员变量 notifyallflag 是否设置为 1。如果是这样,它会尝试以原子方式将 g.allinformedflag 与 1 进行比较,并与 0 交换。如果它无法写入 g.allinformedflag,它会假设某个其他线程已负责通知所有线程。如果此操作成功,则该线程已接管通知所有线程的责任,并通过将每个线程的成员变量 needstoresumeworkflag 设置为 1 来继续执行此操作。然后,它自动将 g.numthreadsready 和 g.notifyallflag 设置为零,并将 g.allinformedflag 设置为 1。
type g struct {
numthreads int
numthreadsready *uint32 // initialize to 0 somewhere appropriate
notifyallflag *uint32 // initialize to 0 somewhere appropriate
allinformedflag *uint32 // initialize to 1 somewhere appropriate (1 is not a typo)
// some data, that the workers need access to
}
// this function is thread-safe in so far as several
// workers can concurrently add information.
//
// the function is optimized for heavy contention; most
// threads can leave almost immediately. one threads
// cleans up any mess they leave behind (and even in
// bad cases that is not too much).
func (g *g) addinformation(i infotype) {
// step 1: make information available to all threads.
// step 2: enqueue information at the end of some array.
// since the responsibility to enqueue an information may
// be passed to another thread, it is important that the
// last step is executed by the thread which enqueues the
// information(s) in order to ensure, that the information
// successfully has been enqueued.
// step 3:
atomic.storeuint32(g.notifyallflag,1) // all threads need to be notified
}
// if a new information has been added, we must ensure,
// that every thread, that had finished, resumes work
// and processes any newly added informations.
func (g *g) notifyall() {
if atomic.loaduint32(g.notifyall) == 1 {
// somebody needs to notify all threads.
if atomic.compareandswapuint32(g.allinformedflag, 1, 0) {
// this thread has taken over the responsibility to inform
// all other threads. all threads are hindered to access
// their member variable s.needstoresumeworkflag
for j := range g.s {
atomic.storeuint32(g.s[j].needstoresumeworkflag, 1)
}
atomic.storeuint32(g.notifyallflag, 0)
atomic.storeuint32(g.numthreadsready, 0)
atomic.storeuint32(g.allinformedflag, 1)
} else {
// some other thread has taken responsibility to inform
// all threads.
}
}
每当一个线程处理完已排队的所有信息时,它会通过原子地将其成员变量 needstoresumeworkflag 与 1 进行比较并与 0 进行交换来检查是否需要恢复工作。但是,由于其中一个线程负责通知所有其他线程,它不能立即这样做。
首先,它必须调用函数g.notifyall(),然后它必须检查最近调用g.notifyall()的线程是否完成通知所有线程。因此,在调用 g.notifyall() 之后,它必须旋转直到 g.allinformed 为 1,然后再检查其成员变量 s.needstoresumeworkflag 是否为 1,在这种情况下,自动将其设置为零并恢复工作。 (我猜这是一个错误,但我在这里也尝试了其他几件事,但没有成功。)如果 s.needstoresumeworkflag 已经为零,它会自动将 g.numthreadsready 加一(如果它之前没有这样做过)。 (回想一下,g.numthreadsready 在对 g.notifyall() 的函数调用期间重置。)然后它自动检查 g.numthreadsready 是否等于 g.numthreads,在这种情况下它可以离开(在将虚拟宝藏发送到这个频道)。否则我们会重新开始,直到该线程已收到通知(可能是由其本身)或所有线程都准备好为止。
type worker struct {
// Each worker contains a pointer to g
// such that it has access to its member
// variables and is able to call the
// function g.addInformation(i) as soon
// as it finds some information i.
g *G
// If new work has been added, the thread
// is notified by setting the uint32
// at which needsToResumeWorkFlag points to 1.
needsToResumeWorkFlag *uint32 // initialize to 0 somewhere appropriate
// Also contains some other stuff.
}
func (s *worker) FooInParallel(wg *sync.WaitGroup) {
defer wg.Done()
for {
a := s.processAllInformation()
numReadyIncremented := false
for !s.needsToResumeWork() {
if !numReadyIncremented {
atomic.AddUint32(g.numThreadsReady,1)
numReadyIncremented = true
}
if s.allThreadsReady() {
return
}
}
}
}
func (s *worker) needsToResumeWork() bool {
s.notifyAll()
for {
if atomic.LoadUint32(g.allInformedFlag) == 1 {
if atomic.CompareAndSwapUint32(s.needsToResumeWorkFlag, 1, 0) {
return true
} else {
return false
}
}
}
}
func (s *worker) notifyAll() {
g.notifyAll()
}
func (g *G) allThreadsReady() bool {
if atomic.LoadUint32(g.numThreadsReady) == g.numThreads {
return true
} else {
return false
}
}
如上所述,我的解决方案不起作用。
正确答案
我自己找到了解决方案。我们利用的是,如果没有添加新信息(并且成本低廉),则对 s.processallinformation() 的调用不会执行任何操作。诀窍是使用原子变量作为两者的锁,让每个线程在必要时通知所有线程并检查是否已收到通知。然后,如果无法获取锁,只需再次调用 s.processallinformation() 即可。然后,线程使用通知来检查是否必须增加就绪线程的计数器,而不是查看是否需要返回工作。
全球形势
type g struct {
numthreads int
numthreadsready *uint32 // initialize to 0 somewhere appropriate
notifyallflag *uint32 // initialize to 0 somewhere appropriate
allcangoflag *uint32 // initialize to 0 somewhere appropriate
lock *uint32 // initialize to 0 somewhere appropriate
// some data, that the workers need access to
}
// this function is thread-safe in so far as several
// workers can concurrently add information.
//
// the function is optimized for heavy contention; most
// threads can leave almost immediately. one threads
// cleans up any mess they leave behind (and even in
// bad cases that is not too much).
func (g *g) addinformation(i infotype) {
// step 1: make information available to all threads.
// step 2: enqueue information at the end of some array.
// since the responsibility to enqueue an information may
// be passed to another thread, it is important that the
// last step is executed by the thread which enqueues the
// information(s) in order to ensure, that the information
// successfully has been enqueued.
// step 3:
atomic.storeuint32(g.notifyallflag,1) // all threads need to be notified
}
// if a new information has been added, we must ensure,
// that every thread, that had finished, resumes work
// and processes any newly added informations.
//
// this function is not thread-safe. make sure not to
// have several threads call this function concurrently
// if these calls are not guarded by some lock.
func (g *g) notifyall() {
if atomic.loaduint32(g.notifyallflag,1) {
for j := range g.s {
atomic.storeuint32(g.s[j].needstoresumeworkflag, 1)
}
atomic.storeuint32(g.notifyallflag,0)
atomic.storeuint32(g.numthreadsready,0)
}
当地情况
type worker struct {
// Each worker contains a pointer to g
// such that it has access to its member
// variables and is able to call the
// function g.addInformation(i) as soon
// as it finds some information i.
g *G
// If new work has been added, the thread
// is notified by setting the uint32
// at which needsToResumeWorkFlag points to 1.
needsToResumeWorkFlag *uint32 // initialize to 0 somewhere appropriate
incrementedNumReadyFlag *uint32 // initialize to 0 somewhere appropriate
// Also contains some other stuff.
}
func (s *worker) FooInParallel(wg *sync.WaitGroup) {
defer wg.Done()
for {
a := s.processAllInformation()
if atomic.LoadUint32(s.g.allCanGoFlag, 1) {
return
}
if atomic.CompareAndSwapUint32(g.lock,0,1) { // If possible, lock.
s.g.notifyAll() // It is essential, that this is also guarded by the lock.
if atomic.LoadUint32(s.needsToResumeWorkFlag) == 1 {
atomic.StoreUint32(s.needsToResumeWorkFlag,0)
// Some new information was found, and this thread can't be sure,
// whether it already has processed it. Since the counter for
// how many threads are ready had been reset, we must increment
// that counter after the next call processAllInformation() in the
// following iteration.
atomic.StoreUint32(s.incrementedNumReadyFlag,0)
} else {
// Increment number of ready threads by one, if this thread had not
// done this before (since the last newly found information).
if atomic.CompareAndSwapUint32(s.incrementedNumReadyFlag,0,1) {
atomic.AddUint32(s.g.numThreadsReady,1)
}
// If all threads are ready, give them all a signal.
if atomic.LoadUint32(s.g.numThreadsReady) == s.g.numThreads {
atomic.StoreUint32(s.g.allCanGo, 1)
}
}
atomic.StoreUint32(g.lock,0) // Unlock.
}
}
}
稍后我可能会添加一些顺序,以便线程在严重争用的情况下访问锁,但现在就这样了。
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于Golang的相关知识,也可关注golang学习网公众号。
 通过使用 Go 的 SSL 和证书连接到 MySQL/MariaDB
通过使用 Go 的 SSL 和证书连接到 MySQL/MariaDB
- 上一篇
- 通过使用 Go 的 SSL 和证书连接到 MySQL/MariaDB

- 下一篇
- gorm如何查询非空列的数据
-

- Golang · Go问答 | 9小时前 | 字符串 · 性能 · Go问答 · strings.Builder · Go panic Pointer 传值 strings.Builder
- Go strings.Builder 为什么不能复制:传值参数、append 和 panic 的边界
- 246浏览 收藏
-

- Golang · Go问答 | 10小时前 | HTTP · 静态资源 · Go问答 · 浏览器缓存 · 浏览器缓存 Cache-Control ETag http.FileServer Go静态文件
- Go 静态文件更新了浏览器还是旧版本:Cache-Control、ETag 和文件名指纹怎么配
- 251浏览 收藏
-

- Golang · Go问答 | 11小时前 | 依赖注入 · 设计模式 · api设计 · Go问答 · Functional Options · API设计 默认值 依赖注入 Go问答 Functional Options 函数选项
- Go Functional Options 怎么设计:默认值、必填依赖和不该使用的场景
- 153浏览 收藏
-
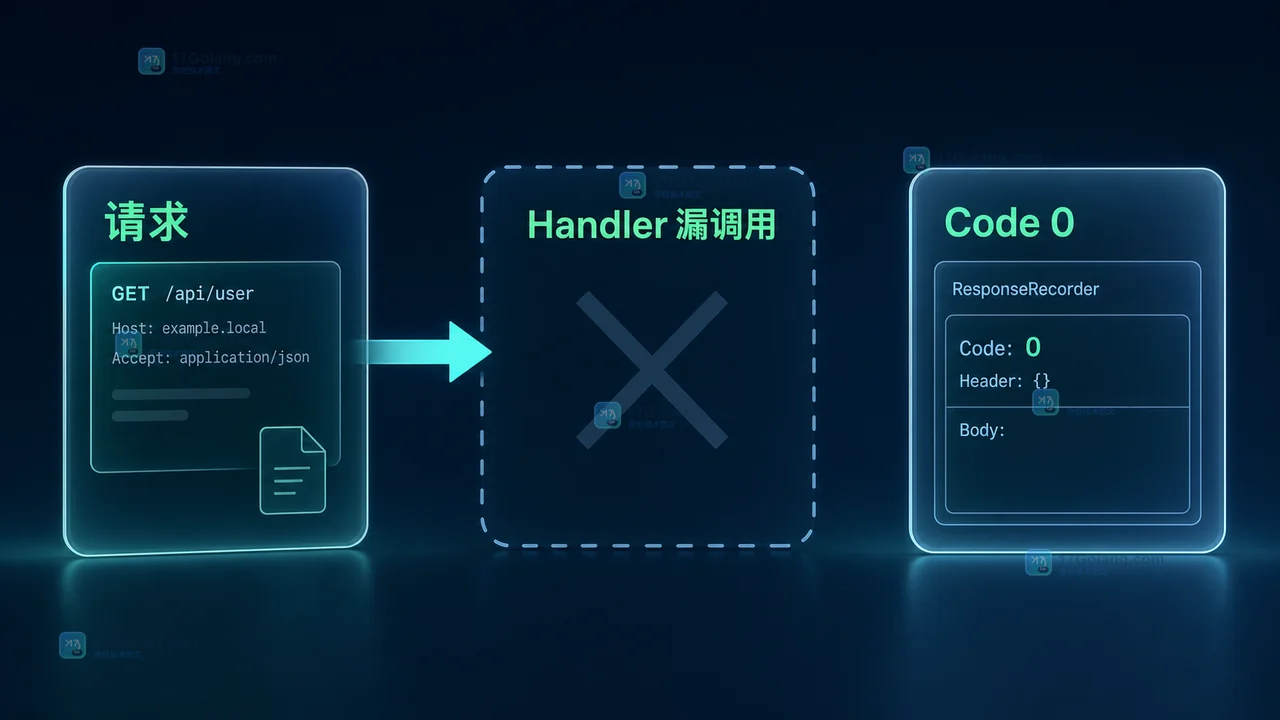
- Golang · Go问答 | 11小时前 | 单元测试 · HTTP · Go问答 · httptest · ResponseRecorder · 单元测试 HTTP响应 httptest Go问答 ResponseRecorder Handler测试
- Go 用 httptest 测 Handler,为什么响应体是空的:WriteHeader、Result 与断言顺序
- 481浏览 收藏
-

- Golang · Go问答 | 11小时前 | 并发 · 性能优化 · sync.Pool · bytes.Buffer · Go问答 · reset bytes.Buffer 对象复用 Go sync.Pool 数据串行
- Go sync.Pool 复用 bytes.Buffer 为什么会串数据:Reset 位置和归还时机
- 294浏览 收藏
-
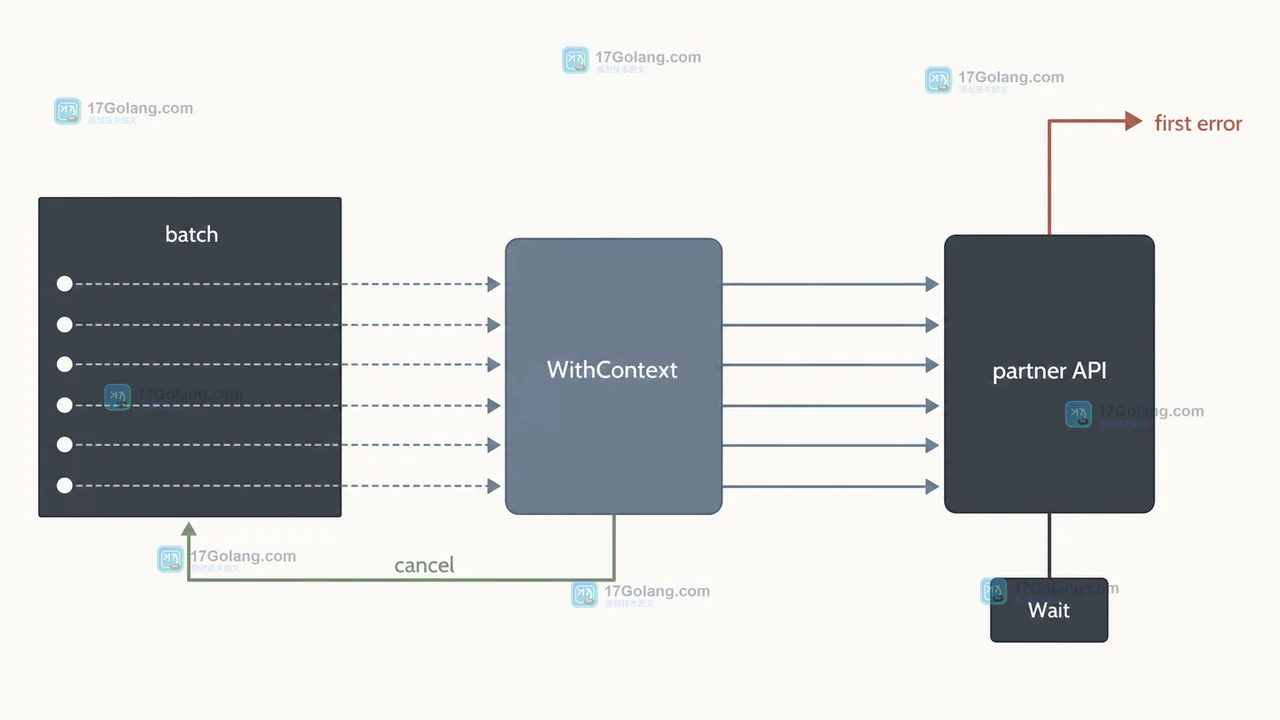
- Golang · Go问答 | 17小时前 | golang · errgroup · Context · 并发控制 · Go问答 · SetLimit · 错误传播 Go errgroup.SetLimit errgroup.WithContext Go 并发限制 批量调用 context 取消
- Go errgroup.SetLimit 怎么用:批量调用下游时限制并发、保留取消与错误
- 467浏览 收藏
-

- Golang · Go问答 | 1天前 | [] · []
- Go 服务怎么用 Sec-Fetch-Site 拦住跨站请求:Fetch Metadata 的最小中间件
- 349浏览 收藏
-

- Golang · Go问答 | 1天前 | 云原生 · golang · 性能优化 · kubernetes · HPA · Go HPA不扩容 Kubernetes HPA CPU resources requests HPA并发指标 Go服务扩缩容
- Go 服务上 Kubernetes 后 HPA 为什么不扩容:requests、CPU 和并发指标怎么选
- 111浏览 收藏
-

- Golang · Go问答 | 1天前 | golang · 消息队列 · 性能优化 · websocket · 高并发 · Go WebSocket广播 Go慢客户端 WebSocket发送队列 Go Hub分片 WebSocket背压
- Go WebSocket 广播为什么会被慢客户端拖住:发送队列、丢弃策略和分片 Hub
- 146浏览 收藏
-

- Golang · Go问答 | 1天前 | 性能排查 · net/http · HTTP客户端 · Go问答 · 连接复用 · 连接复用 keep-alive http.Transport Response.Body Go HTTP Client
- Go HTTP Client 为什么频繁建连接:Response.Body 没读完和没关闭的排查
- 241浏览 收藏
![Go 接口返回 null 而不是 []:nil slice 和空切片怎么选](/uploads/20260717/1784268467-go-list-contract-trace.webp)
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 4554次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 4214次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 4175次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 4396次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 4347次使用
-
- 用Nginx反向代理部署go写的网站。
- 2023-01-17 502浏览
-
- GoLand调式动态执行代码
- 2023-01-13 502浏览
-
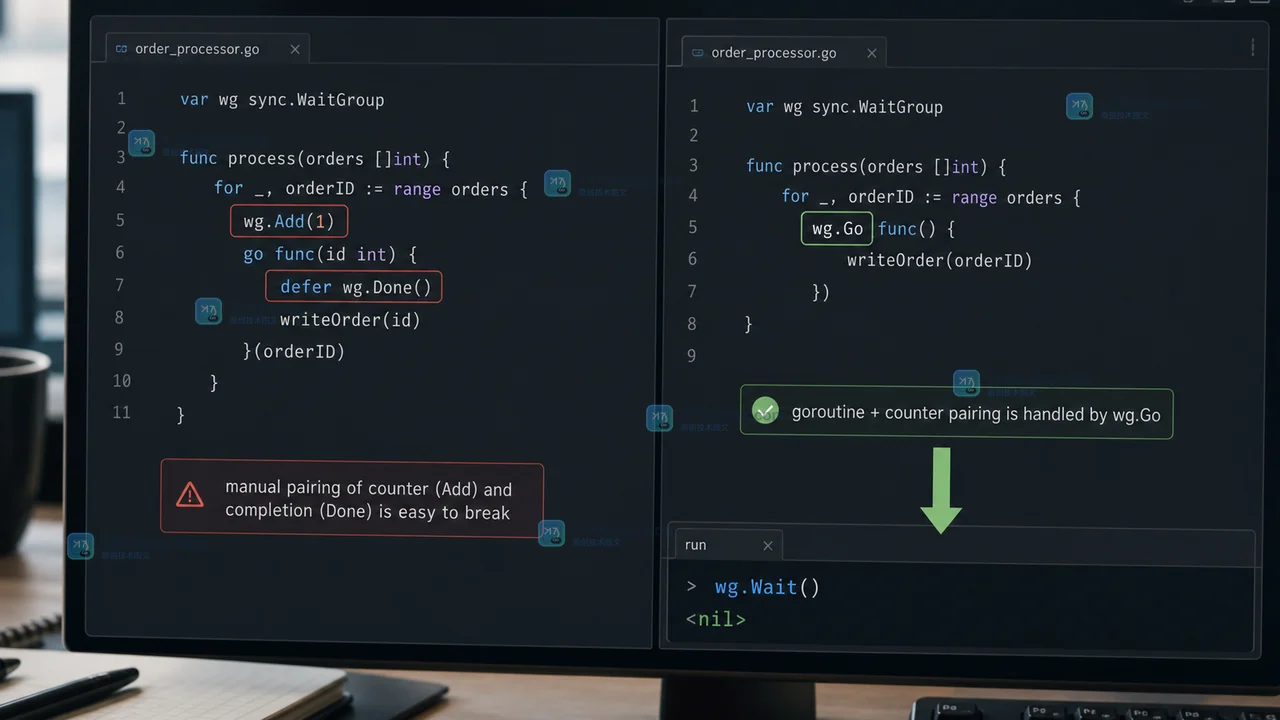
- 从不同的 go 例程将数据写入同一通道无需等待组即可正常工作
- 2024-04-29 501浏览
-
- Golang rsa-oaep解密失败,前端使用webcrypto
- 2024-04-26 501浏览
-
- 如何从用户输入以惰性方式初始化包的全局变量?
- 2024-04-24 501浏览


