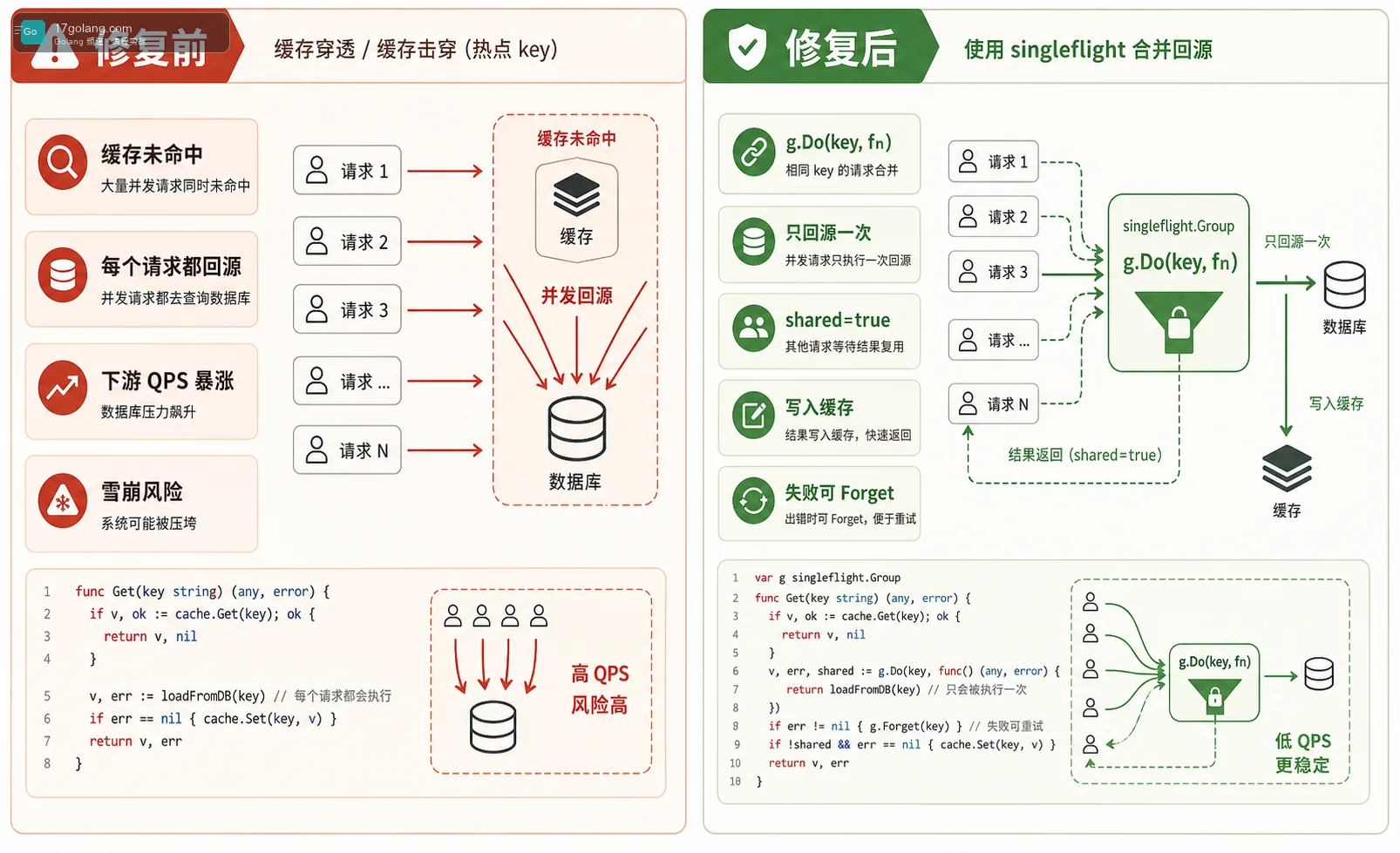
缓存击穿这事,我见过最典型的现场是这样的:一个热门商品刚好过期,几百个请求同时打进来,全都发现缓存没命中,然后一起回源查数据库或者调用下游接口。业务日志看起来只是“缓存 miss 多了一点”,但下游 QPS 会突然尖起来,慢一点就是连锁超时。
Go 里处理这种“同一个 key 的重复请求”有一个很顺手的工具:golang.org/x/sync/singleflight。它不是缓存,也不是限流器,它做的事情很窄:把同一个 key 上同时发生的重复函数调用合并起来,让真正回源的调用只执行一次,其他请求等结果并共享。
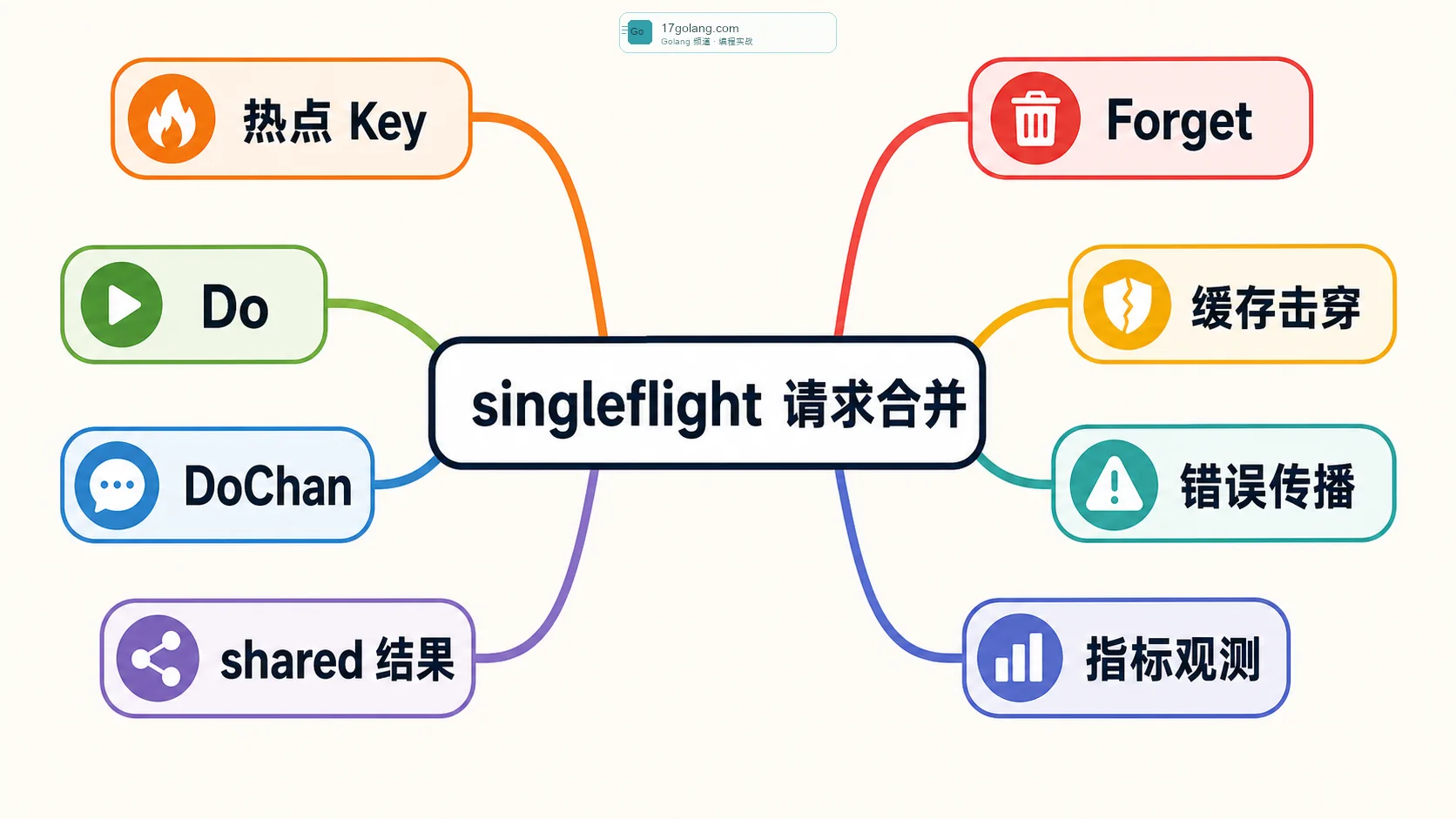
先把边界说清楚:singleflight 不是万能缓存
我最怕团队把 singleflight 当成“高级缓存”。它本身不存业务数据,也不会替你设置 TTL,更不会判断数据新不新。它只管一件事:当前这一小段时间里,某个 key 的回源函数是不是已经有人在跑了。如果有人在跑,后来的请求就等这个结果。
官方包里的 Group.Do 会按 key 执行函数,返回值里有一个 shared,表示结果是否被多个调用者共享。这个字段很适合打指标:如果 shared 比例突然升高,通常说明热点 key、缓存失效或者下游变慢正在出现。
事故复现:缓存 miss 后每个请求都回源
先看一个很常见的写法。代码没有语法问题,也能上线跑很久,但在热门 key 失效时,它会把并发请求原封不动地打到下游。
func (s *Service) GetProduct(ctx context.Context, id string) (*Product, error) {
key := "product:" + id
if v, ok := s.cache.Get(key); ok {
return v.(*Product), nil
}
// 热点 key 过期时,每个请求都会走到这里
p, err := s.repo.LoadProduct(ctx, id)
if err != nil {
return nil, err
}
s.cache.Set(key, p, 30*time.Second)
return p, nil
}
这个问题低峰不明显,因为并发不够大;压测如果没有故意打同一个 key,也很容易漏掉。真正上生产后,爆点通常发生在首页推荐、商品详情、权限配置、汇率价格、风控规则这类热点数据上。
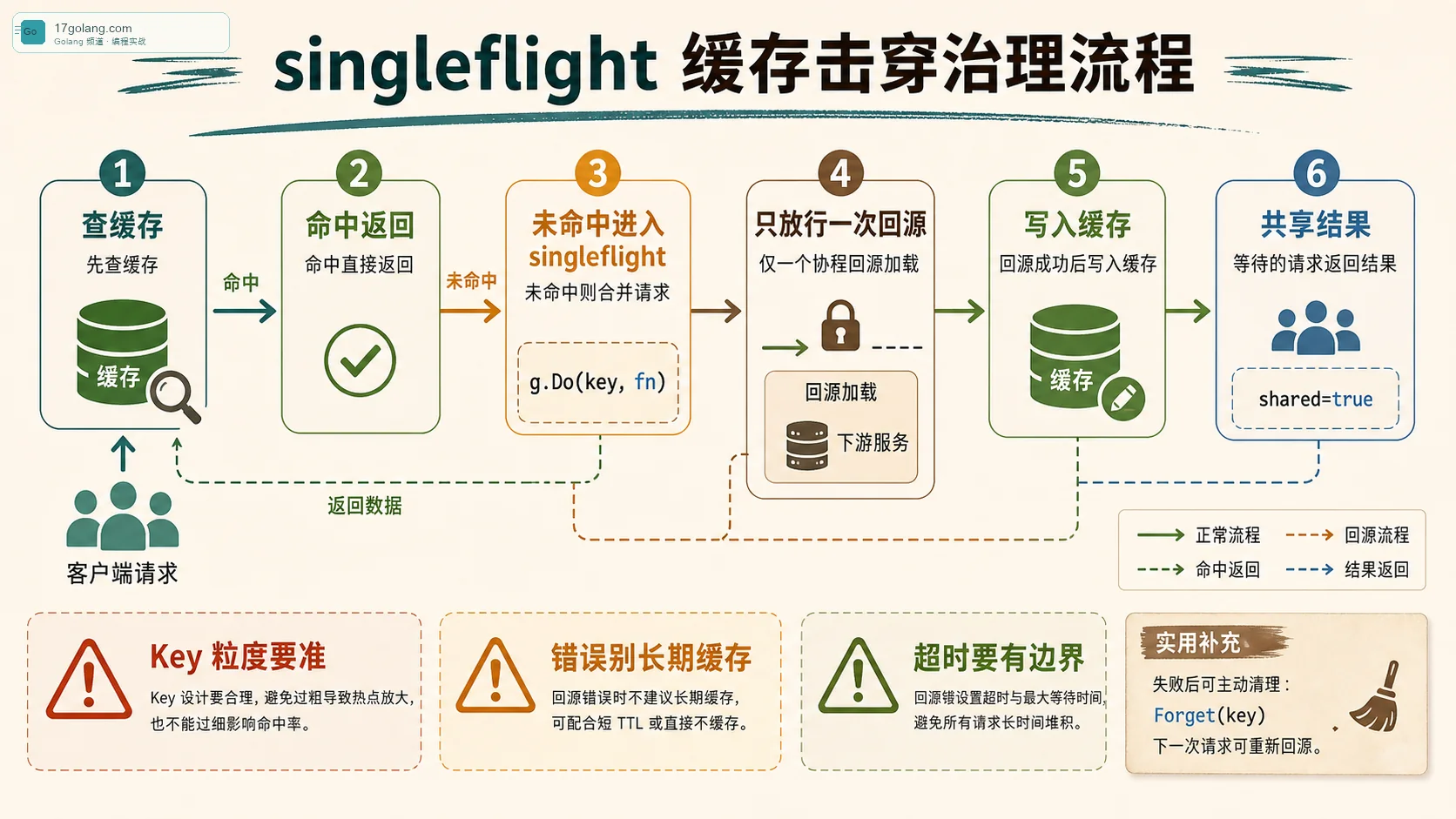
落地写法:缓存 miss 后再进入 singleflight
我一般不会把 singleflight 放在最外层。正确顺序是:先查缓存,命中直接返回;未命中,再用 singleflight 合并同一个 key 的回源动作;回源成功后写缓存,等待方共享结果。
type Service struct {
cache Cache
repo ProductRepo
group singleflight.Group
}
func (s *Service) GetProduct(ctx context.Context, id string) (*Product, error) {
key := "product:" + id
if v, ok := s.cache.Get(key); ok {
return v.(*Product), nil
}
v, err, shared := s.group.Do(key, func() (any, error) {
if v, ok := s.cache.Get(key); ok {
return v.(*Product), nil
}
p, err := s.repo.LoadProduct(ctx, id)
if err != nil {
return nil, err
}
s.cache.Set(key, p, 30*time.Second)
return p, nil
})
if err != nil {
return nil, fmt.Errorf("load product %s: %w", id, err)
}
observeSingleflight("product", shared)
return v.(*Product), nil
}
注意函数内部我又查了一次缓存,这不是多余。因为在当前 goroutine 等待排队期间,可能已经有别的请求把缓存写回去了。这个二次检查能避免一些无意义的回源,尤其是你在外层还有本地缓存、二级缓存的时候。
Key 粒度别拍脑袋
singleflight 最容易写错的是 key。key 太粗,会把不该合并的请求合到一起,比如不同租户、不同语言、不同权限范围被合并,结果就有串数据风险。key 太细,又合并不了请求,等于只加了复杂度。
我的习惯是把影响结果的维度全部写进 key:业务对象 ID、租户、地区、语言、灰度版本、权限维度。只要这些维度里有一个会改变结果,就不能省。这个原则比“key 短一点好看”重要得多。
错误传播:别把失败放大,也别把错误缓存太久
singleflight 会把同一次执行的错误也共享给等待者。这是合理的,因为它们等的是同一个回源动作。但这也意味着,一次下游失败可能会让一批请求同时拿到错误。这里不要误会:singleflight 减少的是重复回源,不保证下游一定成功。
如果回源失败,我通常不会把错误长期缓存。最多做非常短的负缓存,而且要看业务能不能接受。比如商品详情失败,可能宁愿返回错误;权限配置失败,可能要降级到上一次可用版本;风控规则失败,就不能随便兜底。
Forget 什么时候用
Forget(key) 的意思是让 Group 忘掉某个 key,后续请求不再等当前这次调用。它不是日常必备动作,但在一些场景很有用:比如当前回源已经确定卡死、业务决定快速失败并允许下一批请求重新尝试,或者你做了更高层的熔断和降级。
别把 Forget 当成“修复错误”的按钮。乱用 Forget 会让请求重新并发回源,反而把 singleflight 的保护效果打没。我的建议是:只有当你明确知道当前这次调用不应该再被等待时,才使用它。
DoChan:异步等待也要有超时
如果你想用 select 同时等结果和 context 取消,可以用 DoChan。它会返回一个 channel,里面是结果、错误和 shared 标记。但这里有个坑:调用方取消等待,不代表回源函数自动停掉。回源函数自己也必须尊重 context。
ch := s.group.DoChan(key, func() (any, error) {
return s.repo.LoadProduct(ctx, id)
})
select {
case ret := <-ch:
if ret.Err != nil {
return nil, ret.Err
}
return ret.Val.(*Product), nil
case <-ctx.Done():
return nil, ctx.Err()
}
如果回源函数内部又自己创建了 context.Background(),那外层超时就失效了。这个问题我在代码 review 里会特别盯,因为它很隐蔽:表面上用了 DoChan 和 select,实际回源根本不听取消。
上线前我会加哪些指标
- shared 比例:shared=true 越高,说明请求合并越频繁,热点或缓存失效越明显。
- 回源耗时:只看接口耗时不够,要单独看回源函数耗时。
- 每个 key 的合并量:必要时采样记录热点 key,避免全量打爆日志。
- 错误类型:区分下游超时、业务不存在、序列化失败和 context 取消。
- 缓存命中率:singleflight 是止血,不是替代缓存命中率治理。
- 下游 QPS:上线前后对比同一热点场景下的回源次数。
我自己的使用边界
singleflight 适合“同一时刻、同一个 key、重复回源成本很高”的场景。它不适合替代队列,不适合做全局限流,也不适合解决所有慢查询。你要先确认问题是重复调用,而不是单次调用本身太慢。
如果下游本身已经慢到不可接受,singleflight 只能减少并发回源,不能让慢调用变快。这个时候还要配合超时、熔断、降级、缓存预热和容量治理。工具要放在正确的位置,才不会变成新的复杂度。
最后聊两句
我喜欢 singleflight 的原因是它足够小:不抢缓存的活,不抢限流的活,只负责把重复回源合并掉。也正因为它小,使用时更要把边界写清楚:key 怎么拼、错误怎么处理、超时怎么传、shared 怎么观测。
如果你的 Go 服务里有热点缓存、配置加载、权限查询、商品详情、价格汇率这类场景,建议专门做一次同 key 并发压测。你会很快看出来,singleflight 到底是在帮你挡缓存击穿,还是只是给代码加了一层看起来很高级的包装。
 Spring Boot 集成测试别再只靠 H2:Testcontainers 落地踩坑复盘
Spring Boot 集成测试别再只靠 H2:Testcontainers 落地踩坑复盘