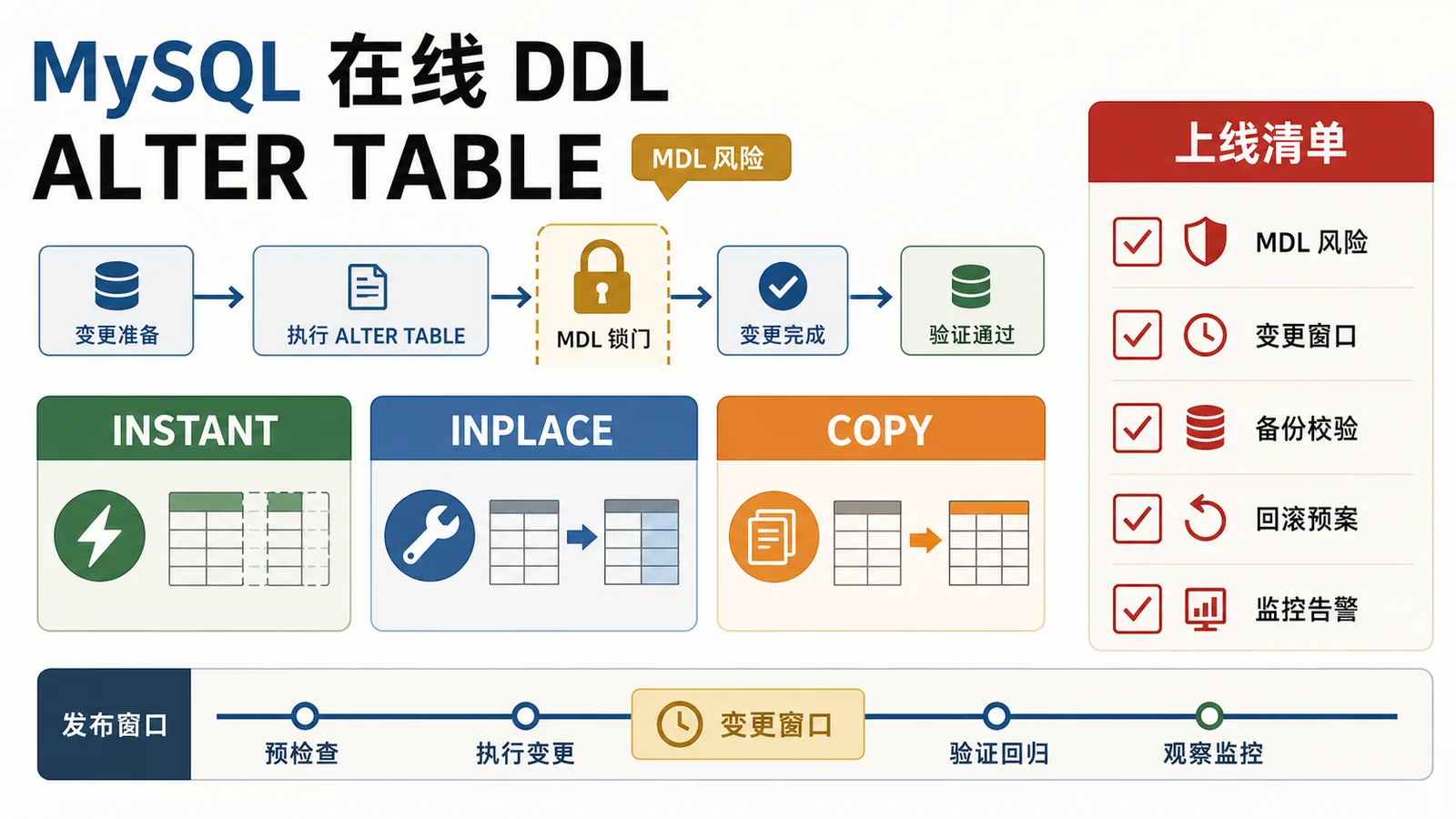
很多人学 MySQL 复合索引,第一句就是左前缀原则:索引是 (region_id, user_id),查询只有 user_id,那就用不上。这个判断大多数时候没错,但在 MySQL 8.x 的优化器里,还有一个容易被忽略的访问路径:Skip Scan。
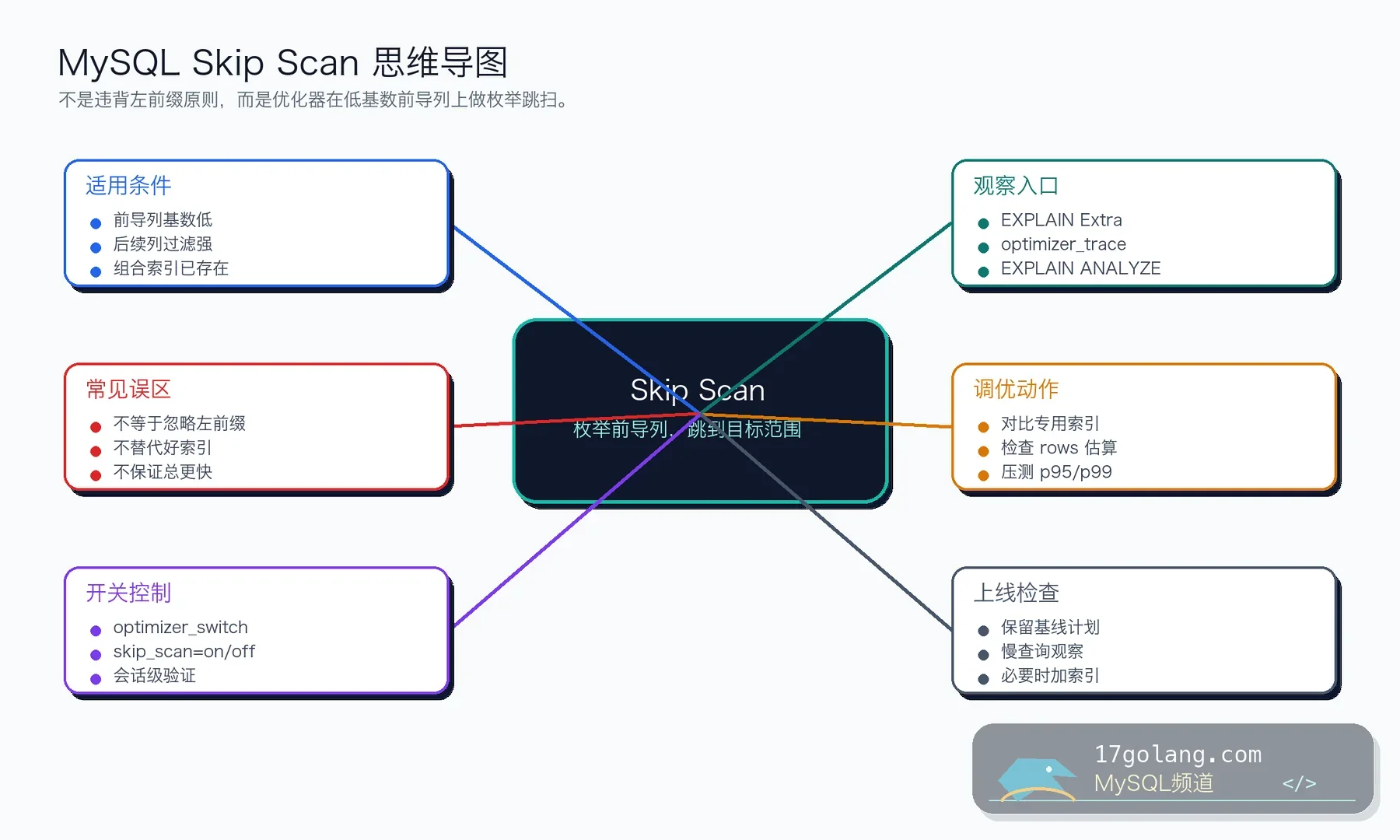
Skip Scan 不是推翻左前缀原则。它更像优化器帮你做了一轮枚举:当前导列不同值很少,后续列过滤性又不错时,优化器可以枚举前导列的每个值,再在复合索引里跳到对应范围查后续列。用得好能避免全表扫,用不好也可能只是把扫描方式换得更绕。
先看一个真实业务场景
订单表有一个索引 idx_region_user(region_id, user_id)。最早业务都是按地区查用户订单,后来客服系统直接按用户查订单:
SELECT * FROM orders WHERE user_id = 10086 ORDER BY created_at DESC LIMIT 20;
如果 region_id 只有几十个值,而 user_id 选择性很强,MySQL 可能不会直接全表扫描,而是对每个 region_id 值尝试在复合索引里查 user_id。这就是 Skip Scan 的典型机会。
怎么确认是不是 Skip Scan
不要靠感觉判断,先看执行计划。MySQL 的 EXPLAIN、EXPLAIN ANALYZE 和 optimizer_trace 都能帮助你确认优化器到底做了什么。
EXPLAIN FORMAT=TREE SELECT * FROM orders WHERE user_id = 10086; EXPLAIN ANALYZE SELECT * FROM orders WHERE user_id = 10086;
我会重点看三件事:估算 rows 是否离谱,实际扫描行数是否可接受,Extra 或 trace 里是否出现 skip scan 相关信息。只看到用了索引还不够,真正要看它有没有让延迟分位稳定下来。
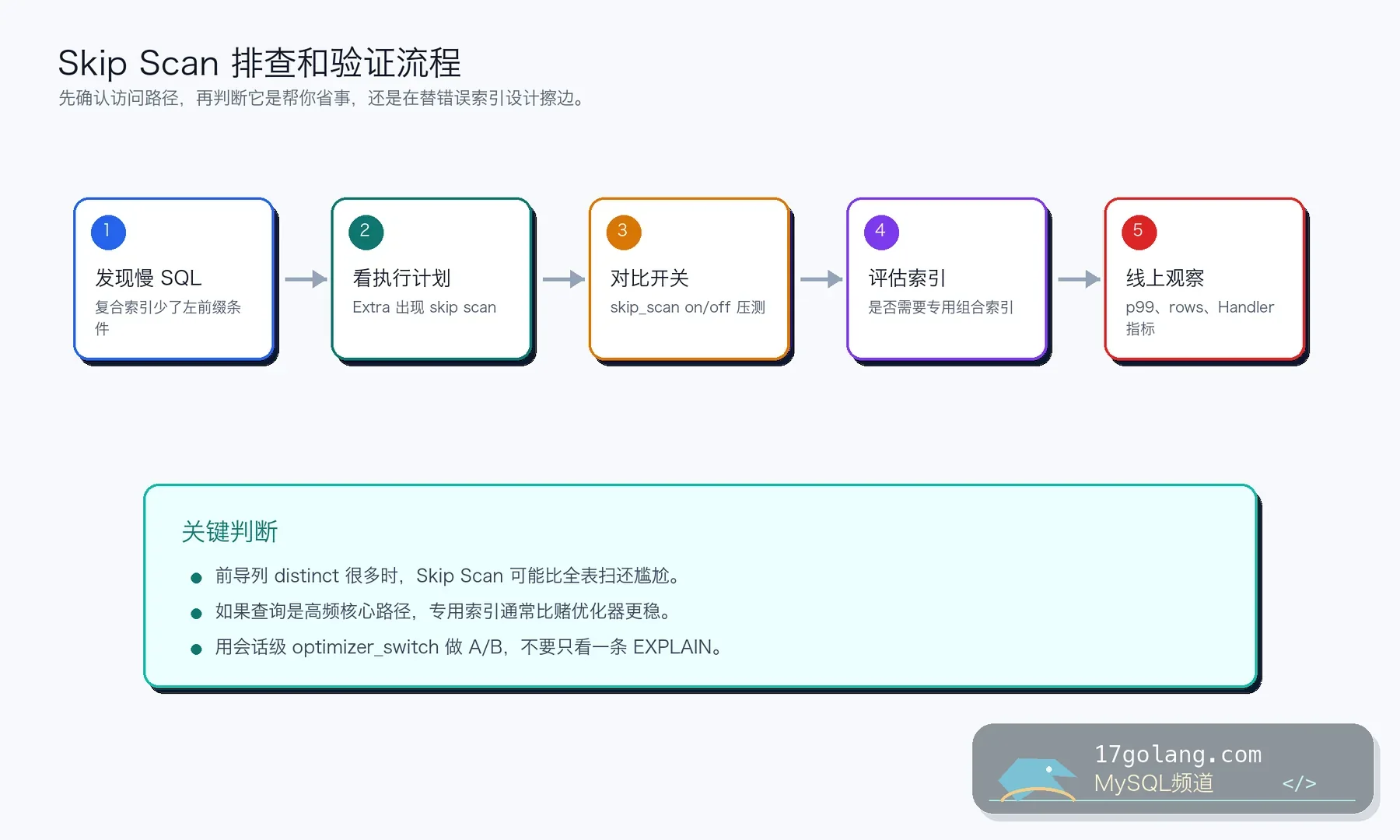
用 optimizer_switch 做 A/B
生产排查时,我不会直接改全局开关,而是在测试连接或灰度会话里对比:
SET optimizer_switch='skip_scan=off'; EXPLAIN ANALYZE SELECT * FROM orders WHERE user_id = 10086; SET optimizer_switch='skip_scan=on'; EXPLAIN ANALYZE SELECT * FROM orders WHERE user_id = 10086;
如果打开 Skip Scan 后 rows 和实际耗时明显下降,而且在高峰流量下 p95/p99 也更稳,那它就是有效路径。如果只是 EXPLAIN 看起来漂亮,实际执行还是抖,就别把它当救命稻草。

什么时候该补专用索引
Skip Scan 适合“已有索引刚好能帮一把”的场景,不适合长期支撑核心查询。如果用户查询订单是高频路径,我更愿意建 (user_id, created_at) 这样的专用索引,让访问路径更确定。
尤其当前导列 distinct 很多时,Skip Scan 要枚举的范围会变多,成本可能迅速变差。你不能只看今天的数据量,还要看业务增长后前导列基数会不会扩张。
上线检查清单
- 确认 MySQL 版本和
optimizer_switch中skip_scan状态。 - 保存 skip_scan on/off 两组
EXPLAIN ANALYZE结果。 - 观察 rows、filtered、执行时间和线上 p95/p99,不只看是否“用了索引”。
- 前导列基数增长快的表,不要长期依赖 Skip Scan。
- 核心高频查询优先设计专用组合索引。
- 上线后盯慢查询、Handler_read_next 和扫描行数变化。
我的经验结论
Skip Scan 是一个很实用的优化器能力,但它不是索引设计的免死金牌。它能让某些“不满足左前缀”的查询少走弯路,也可能在数据分布变化后突然变得不划算。
我的做法是:发现它、验证它、利用它,但不迷信它。只要这条 SQL 是核心路径,最后还是要回到稳定的索引设计和真实线上指标。
 Spring Security JWT 401/403 排查:别再把过滤链和权限前缀搅在一起
Spring Security JWT 401/403 排查:别再把过滤链和权限前缀搅在一起