在线 DDL 最容易坑人的地方,是名字里有“在线”两个字。很多同学看到 ALGORITHM=INSTANT、LOCK=NONE,就以为生产表加字段可以随手敲。真到业务高峰,一个长事务挂着,ALTER TABLE 等 MDL,后面的查询也跟着排队,这才发现事故不是发生在改表本身,而是发生在改表前没做判断。
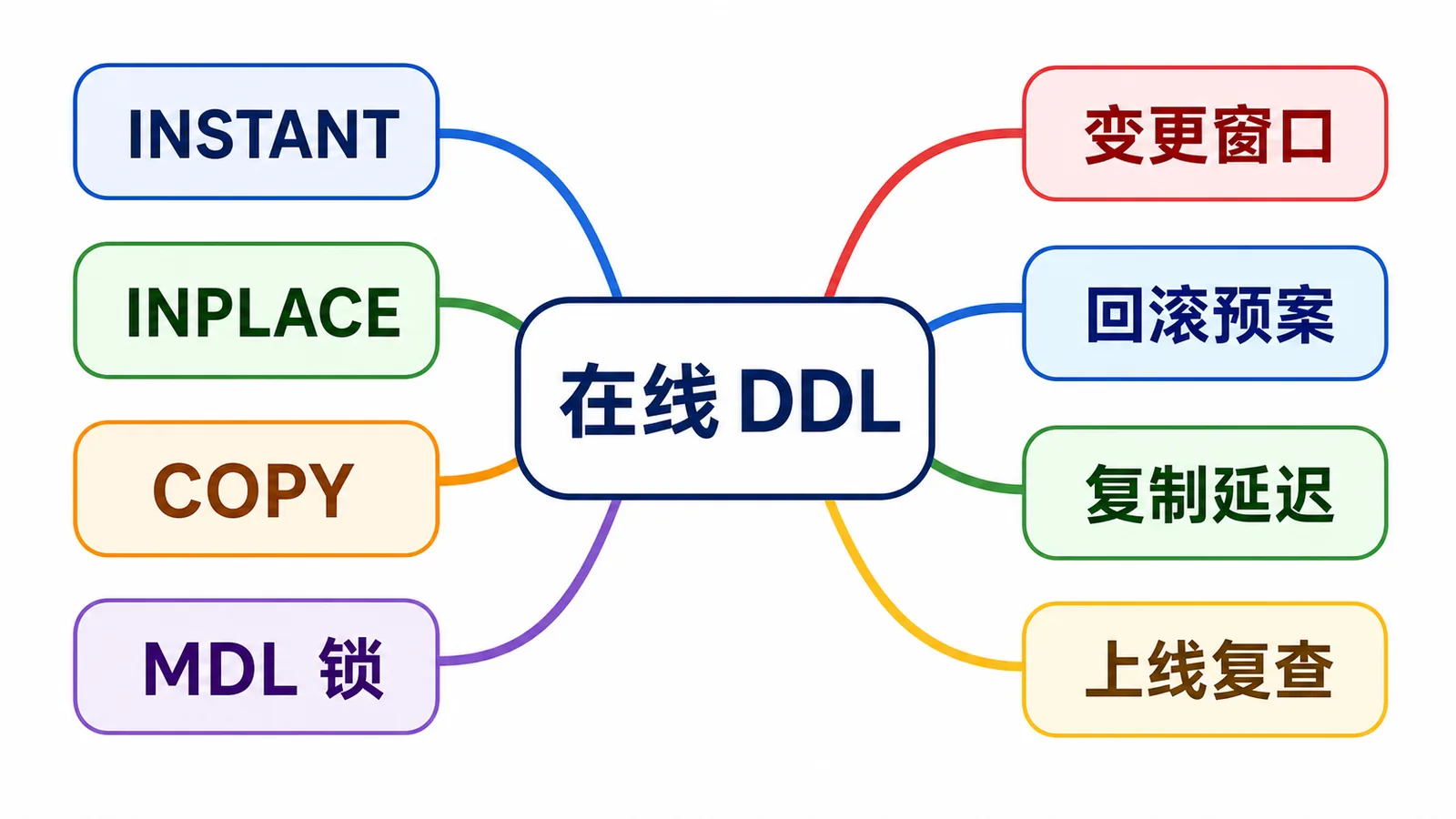
这篇不按官方手册逐条翻译。我按线上变更的视角来写:一张订单大表要加字段,怎么判断能不能走 INSTANT,怎么提前发现 MDL 风险,怎么执行,怎么观察复制延迟,最后怎么复查。适用范围以 MySQL 8.x / InnoDB 为主,具体操作仍要按你线上小版本和表结构再确认。
业务场景:给 orders 表加一个来源字段
假设订单库里有一张 orders 表,八千万行,白天每秒几百到几千次写入。产品要补一个 source 字段,用来区分小程序、H5、直播间和第三方渠道。需求看起来很简单:
ALTER TABLE orders ADD COLUMN source VARCHAR(32) NULL, ALGORITHM=INSTANT, LOCK=NONE;
这条 SQL 本身没什么花活。真正的问题是:这张表当前有没有长事务?这个字段操作在你当前 MySQL 版本和表定义下是否支持 INSTANT?表已经做过多少次 instant add/drop column?复制链路能不能扛住这次 DDL?如果这些问题没答清楚,我不建议直接点执行。
先讲清楚三个算法:INSTANT、INPLACE、COPY
INSTANT 可以理解成“尽量只改数据字典和元信息”,对支持的操作非常快,比如某些加列、删列、索引元数据调整。但它不是万能钥匙,字段位置、字段类型、行格式、全文索引、压缩表等条件都可能影响是否支持。
INPLACE 听起来像“不复制表”,但它仍可能重建聚簇索引或消耗大量临时空间、redo、undo 和 I/O。它通常比 COPY 对业务友好,但不能简单等同于无成本。
COPY 基本就是高风险信号:MySQL 需要创建临时表、拷贝数据、切换表定义。大表上如果被迫走 COPY,我一般会改方案,比如用 gh-ost/pt-online-schema-change,或者拆分变更窗口。
最容易忽略的点:Online DDL 也要 MDL
很多事故不是 DDL 执行慢,而是 DDL 在等 metadata lock。MySQL 为了保护表定义一致性,DDL 在开始和提交表定义时需要元数据锁。在线 DDL 的排他锁时间通常很短,但如果前面有长事务一直占着表的元数据锁,这个“很短”就会变成“等不到”。
更麻烦的是,等待中的 DDL 往往会形成队列效应。比如一个报表连接开了事务读 orders 没提交,ALTER TABLE 开始等排他 MDL,后面新的订单查询又被这个 pending 的 DDL 卡住。线上表现可能是:连接数升高、SQL 变慢、接口超时,但慢查询里你只看到一堆普通 SELECT。
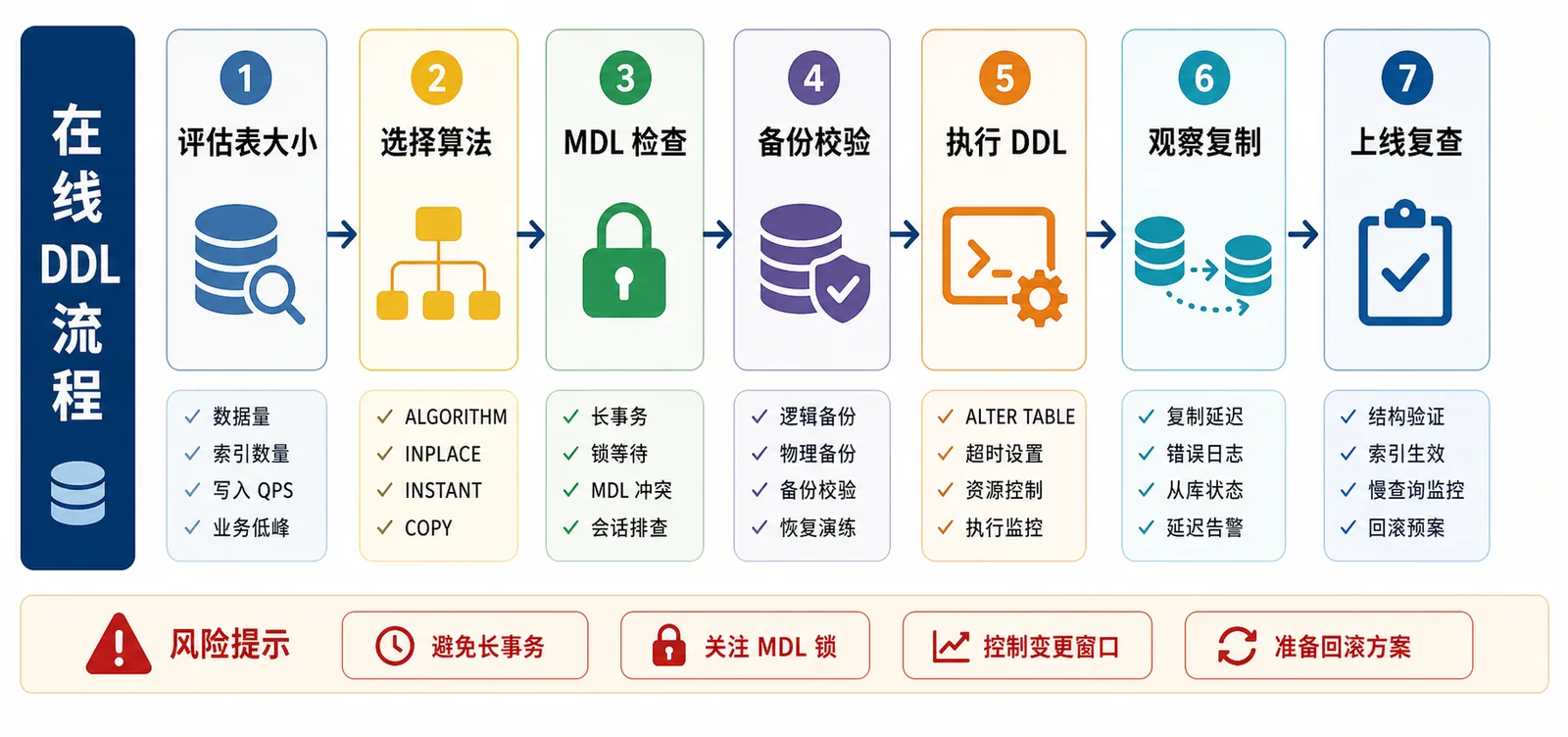
执行前检查:别等卡住了才去翻 processlist
第一步先看有没有长事务。尤其是报表、后台导出、手工查询、定时任务,它们经常是 MDL 事故的源头。
SELECT trx_id, trx_started, trx_mysql_thread_id, trx_query FROM information_schema.innodb_trx ORDER BY trx_started;
第二步看 metadata lock。生产上我更喜欢在变更前就准备好这条 SQL,出现 pending 能第一时间定位是哪张表、哪个线程。
SELECT OBJECT_TYPE, OBJECT_SCHEMA, OBJECT_NAME,
LOCK_TYPE, LOCK_STATUS, OWNER_THREAD_ID
FROM performance_schema.metadata_locks
WHERE OBJECT_SCHEMA = 'shop'
AND OBJECT_NAME = 'orders';
第三步看 instant row version。MySQL 8.4 文档里,INSTANT 加列/删列会产生 row version,INFORMATION_SCHEMA.INNODB_TABLES.TOTAL_ROW_VERSIONS 可以看到累计值;MySQL 8.4 的上限是 64。这个值太高时,继续 INSTANT 可能直接报错,别等发布窗口里才发现。
SELECT NAME, TOTAL_ROW_VERSIONS FROM INFORMATION_SCHEMA.INNODB_TABLES WHERE NAME = 'shop/orders';
我的执行方式:让失败尽快暴露
真正上线时,我不会让 DDL 无限等锁。可以在执行会话里设置一个比较短的 lock_wait_timeout,拿不到 MDL 就快速失败,先处理阻塞源,而不是把业务流量拖进来一起等。
SET SESSION lock_wait_timeout = 5; ALTER TABLE orders ADD COLUMN source VARCHAR(32) NULL, ALGORITHM=INSTANT, LOCK=NONE;
这里显式写 ALGORITHM=INSTANT 和 LOCK=NONE 的意义,是让 MySQL 帮你拒绝“悄悄降级”。如果当前操作不支持这个算法或锁级别,语句应该失败,而不是在你没意识到的情况下走一个更重的路径。
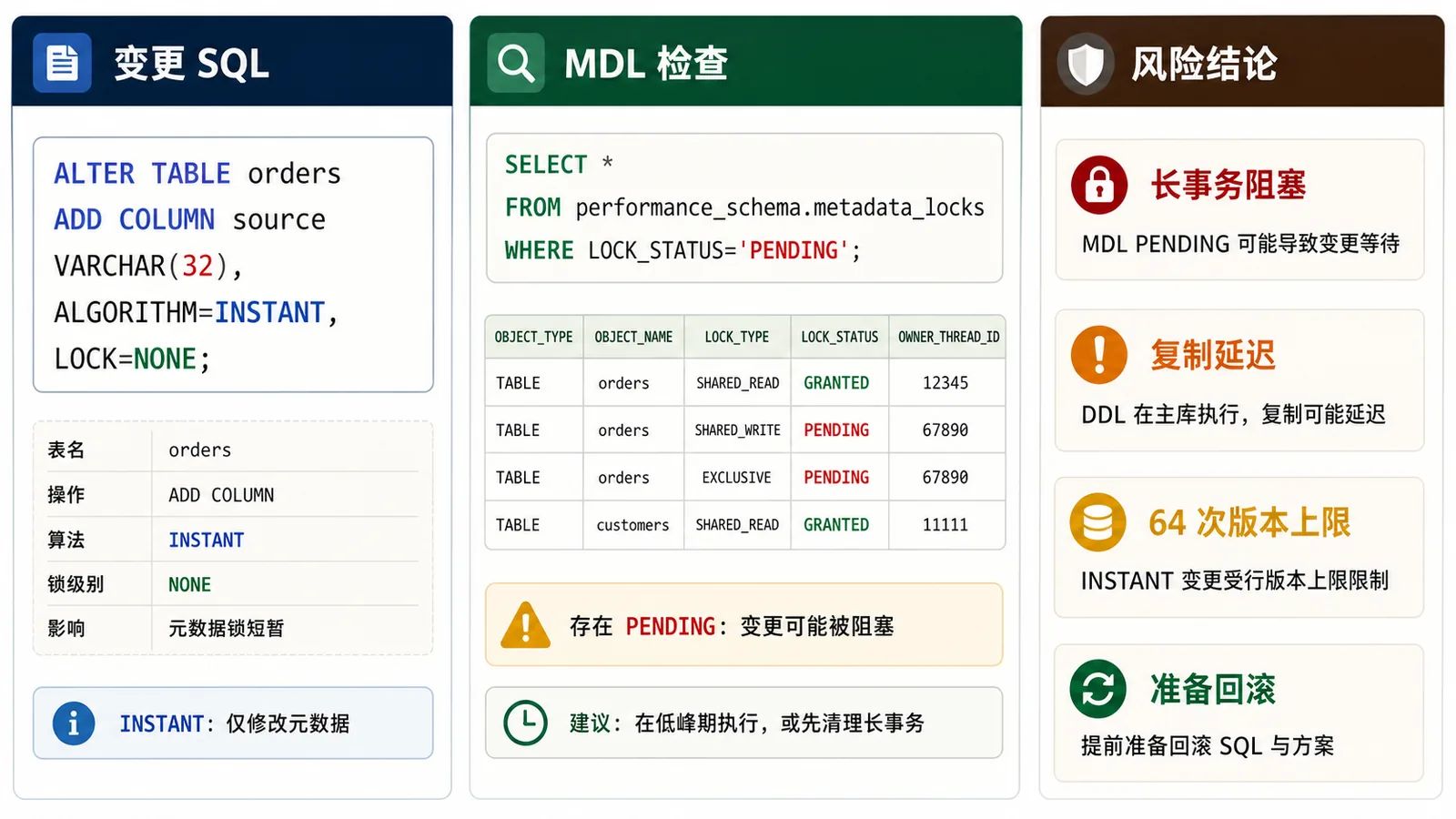
复制延迟也要算进风险
很多团队只盯主库执行成功,忽略从库。DDL 会写入 binlog 并在复制链路上执行,如果从库机器规格差、SQL 线程被别的任务拖住,读流量可能先在从库上慢下来。变更期间至少观察 Seconds_Behind_Source、复制错误、从库 CPU/I/O,以及业务读延迟。
如果你的服务读写分离比较重,我建议在发布单里明确:变更前从库延迟必须为 0 或处于可接受范围;变更中有人盯复制状态;变更后抽查主从表结构一致。不要等用户投诉“刚下单查不到来源字段”才发现从库还没追上。
上线清单:我会逐项打勾
- 确认 MySQL 版本、表引擎、行格式、字段位置和目标 DDL 是否支持预期算法。
- 确认
ALGORITHM、LOCK显式写在 SQL 里,避免线上悄悄走重路径。 - 检查长事务、metadata locks、业务定时任务和手工查询窗口。
- 确认备份可用,并准备回滚方案。新增字段通常让旧代码忽略即可,删字段则要更谨慎。
- 设置短
lock_wait_timeout,拿不到锁先失败,不把业务拖进等待队列。 - 执行期间观察连接数、QPS、错误率、主从延迟、慢查询和 MDL pending。
- 执行后验证表结构、row version、索引生效情况和关键接口链路。
我踩过的坑:真正危险的是“以为很快”
我见过最典型的事故,是一个后台导出开事务读大表,没人注意;DBA 执行了一个看起来很轻的加字段;DDL 在等 MDL,后续业务 SELECT 又排在 DDL 后面。最后大家盯着接口超时找代码问题,其实根因是一条没提交的查询。
所以我的经验是:在线 DDL 不要只问“这个操作是不是 online”,要问“它在哪些阶段需要锁、拿不到锁时会怎么影响队列、失败后业务有没有损失”。这几个问题想清楚,很多事故在执行前就已经被挡住了。
总结
MySQL 8.x 的在线 DDL 确实比早年好用很多,尤其是 INSTANT 让不少表结构变更变得非常轻。但轻不代表无风险,ALTER TABLE 仍然是一次生产发布。我的建议是:小版本核实、算法显式、MDL 预查、短等待失败、复制观察、事后复查。做到这些,你才是真的在做在线 DDL,而不是赌这次运气不错。
 MySQL InnoDB 死锁实战:别只会等 lock wait timeout
MySQL InnoDB 死锁实战:别只会等 lock wait timeout