量子分类器简介:Variational Quantum Classifier (VQC)
学习科技周边要努力,但是不要急!今天的这篇文章《量子分类器简介:Variational Quantum Classifier (VQC)》将会介绍到等等知识点,如果你想深入学习科技周边,可以关注我!我会持续更新相关文章的,希望对大家都能有所帮助!
变分量子分类器(Variational Quantum Classifier,简称VQC)是一种利用量子计算技术进行分类任务的机器学习算法。这句话可以重写为:该算法是一种量子机器学习算法,旨在利用量子计算机的能力潜在地提升经典机器学习方法的性能。
VQC的核心理念是通过应用变分量子电路,将输入数据编码并映射到量子态上。接下来,我们会采用量子门和测量操作来操控这些量子态,以提取与分类任务相关的特征。最后,处理测量结果,并将其用于为输入数据分配类别标签。
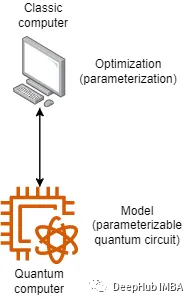
VQC将经典优化技术与量子计算相结合。在训练中,通过在量子计算机或模拟器上重复执行变分量子电路,将其结果与训练数据的真实标签进行对比。以最小化代价函数为目标,通过迭代地调整变分量子电路的参数,使其预测标签与真实标签之间的差异减小。旨在寻找最优的量子电路配置,以提高分类准确性为目标的优化过程。虽然看起来很简单,但这种混合计算体系结构存在很多的挑战。
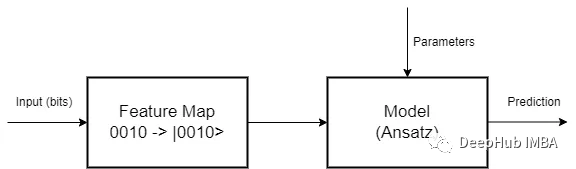
特征映射是第一阶段,其中数据必须编码为量子位。由于特征映射是将一个向量空间转换为另一个向量空间的数学变换,因此有多种编码方法可供选择。所以研究如何为每个问题找到最佳映射,就是一个待研究的问题
有了映射,还要设计一个量子电路作为模型,这是第二阶段。在这里我们可以随心所愿地发挥创意,但必须考虑到同样的旧规则仍然很重要:对于简单的问题,不要使用太多的参数来避免过拟合,也不能使用太少的参数来避免偏差,并且由于我们正在使用量子计算,为了从量子计算范式中获得最佳效果,必须与叠加(superposition )和纠缠(entanglement)一起工作。
并且量子电路是线性变换,我们还需要对其输出进行处理。比如非线性化的激活。
数据集和特征
这里我们将基于泰坦尼克号数据集设计一个分类器,我们的数据集有以下特征:
- PassengerID
- Passenger name
- Class (First, second or third)
- Gender
- Age
- SibSP (siblings and/or spouses aboard)
- Parch (parents or children aboard)
- Ticket
- Fare
- Cabin
- Embarked
- Survived
我们要构建一个根据乘客的特征预测乘客是否幸存的分类器。所以我们只选择几个变量作为示例:
- is_child (if age <12)
- is_class1 (if person is in the first class)
- is_class2
- is_female
由于仅有四个变量可用,我们将采用基础嵌入。我们只需将经典位转换为等效量子位。如果我们的四个变量为1010,则表示为|1010>。
模型
我们的模型是可参数化量子电路。为了验证使用量子组件的合理性,我们的模型要求电路必须具备适度的叠加和纠缠特性
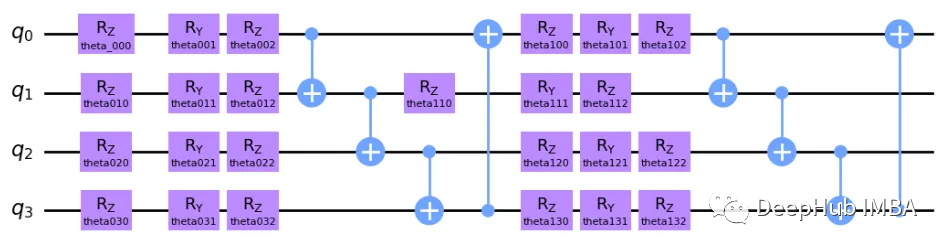
这个模型可能看起来很复杂,但他的想法相当简单。 这是一个双层电路,因为核心结构重复了 2 次。我们首先在每个量子位上实施 Z、Y 和 Z 轴旋转,旨在在每个量子位上分别插入一种程度的叠加。这些参数化旋转在每次算法交互中都由经典计算机更新。接下来是在Y轴和Z轴上的旋转,因为量子位的矢量空间可被描述为一个球体,即布洛赫球体。RZ仅修改量子比特的相位,而RY则调整量子比特与|0⟩和|1⟩的相似程度。
每对量子位之间有四个受控非 (CNOT) 状态,这是一个量子门,根据另一个量子位(分别为目标和控制)的状态反转一个量子位状态。这个门导致我们电路中的所有量子位纠缠,从而导致所有状态的纠缠。 在第二层中,我们应用了一组新的旋转,这不仅仅是第一层的逻辑重复,因为现在所有状态都纠缠在一起,这意味着旋转第一个量子比特也会影响其他量子比特! 最后我们有了一组新的 CNOT 门。
这是对我们上面模型的非常简单的解释,下面代码会让这些内容变得更清晰。
优化器
我使用的是Adam Optimizer,但是这个优化器是经过特殊处理的,我们直接使用pennylane 库。
代码实现
这里我们直接使用Pennylane和sklearn实现代码。
import pennylane as qml from pennylane import numpy as np from pennylane.optimize import AdamOptimizer from sklearn.model_selection import train_test_split import pandas as pd from sklearn.metrics import accuracy_score from sklearn.metrics import f1_score from sklearn.metrics import precision_score from sklearn.metrics import recall_score import math num_qubits = 4 num_layers = 2 dev = qml.device("default.qubit", wires=num_qubits) # quantum circuit functions def statepreparation(x): qml.BasisEmbedding(x, wires=range(0, num_qubits)) def layer(W): qml.Rot(W[0, 0], W[0, 1], W[0, 2], wires=0) qml.Rot(W[1, 0], W[1, 1], W[1, 2], wires=1) qml.Rot(W[2, 0], W[2, 1], W[2, 2], wires=2) qml.Rot(W[3, 0], W[3, 1], W[3, 2], wires=3) qml.CNOT(wires=[0, 1]) qml.CNOT(wires=[1, 2]) qml.CNOT(wires=[2, 3]) qml.CNOT(wires=[3, 0]) @qml.qnode(dev, interface="autograd") def circuit(weights, x): statepreparation(x) for W in weights: layer(W) return qml.expval(qml.PauliZ(0)) def variational_classifier(weights, bias, x): return circuit(weights, x) + bias def square_loss(labels, predictions): loss = 0 for l, p in zip(labels, predictions): loss = loss + (l - p) ** 2 loss = loss / len(labels) return loss def accuracy(labels, predictions): loss = 0 for l, p in zip(labels, predictions): if abs(l - p) < 1e-5: loss = loss + 1 loss = loss / len(labels) return loss def cost(weights, bias, X, Y): predictions = [variational_classifier(weights, bias, x) for x in X] return square_loss(Y, predictions) # preparaing data df_train = pd.read_csv('train.csv') df_train['Pclass'] = df_train['Pclass'].astype(str) df_train = pd.concat([df_train, pd.get_dummies(df_train[['Pclass', 'Sex', 'Embarked']])], axis=1) # I will fill missings with the median df_train['Age'] = df_train['Age'].fillna(df_train['Age'].median()) df_train['is_child'] = df_train['Age'].map(lambda x: 1 if x < 12 else 0) cols_model = ['is_child', 'Pclass_1', 'Pclass_2', 'Sex_female'] X_train, X_test, y_train, y_test = train_test_split(df_train[cols_model], df_train['Survived'], test_size=0.10, random_state=42, stratify=df_train['Survived']) X_train = np.array(X_train.values, requires_grad=False) Y_train = np.array(y_train.values * 2 - np.ones(len(y_train)), requires_grad=False) # setting init params np.random.seed(0) weights_init = 0.01 * np.random.randn(num_layers, num_qubits, 3, requires_grad=True) bias_init = np.array(0.0, requires_grad=True) opt = AdamOptimizer(0.125) num_it = 70 batch_size = math.floor(len(X_train)/num_it) weights = weights_init bias = bias_init for it in range(num_it): # Update the weights by one optimizer step batch_index = np.random.randint(0, len(X_train), (batch_size,)) X_batch = X_train[batch_index] Y_batch = Y_train[batch_index] weights, bias, _, _ = opt.step(cost, weights, bias, X_batch, Y_batch) # Compute accuracy predictions = [np.sign(variational_classifier(weights, bias, x)) for x in X_train] acc = accuracy(Y_train, predictions) print( "Iter: {:5d} | Cost: {:0.7f} | Accuracy: {:0.7f} ".format( it + 1, cost(weights, bias, X_train, Y_train), acc)) X_test = np.array(X_test.values, requires_grad=False) Y_test = np.array(y_test.values * 2 - np.ones(len(y_test)), requires_grad=False) predictions = [np.sign(variational_classifier(weights, bias, x)) for x in X_test] accuracy_score(Y_test, predictions) precision_score(Y_test, predictions) recall_score(Y_test, predictions) f1_score(Y_test, predictions, average='macro')最后得到的结果如下:
Accuracy: 78.89% Precision: 76.67% Recall: 65.71% F1: 77.12%
为了比较,我们使用经典的逻辑回归作为对比,
Accuracy: 75.56% Precision: 69.70% Recall: 65.71% F1: 74.00%
可以看到VQC比逻辑回归模型稍微好一点!这并不意味着VQC一定更好,因为只是这个特定的模型和特定的优化过程表现得更好。然而,重点仍然是将构建一个简单且有效的量子分类器展示出来。
总结
VQC算法需要同时利用经典资源和量子资源。经典部分处理优化和参数更新,而量子部分在量子态上执行计算。VQC的性能和潜在优势取决于诸如分类问题的复杂性、量子硬件的质量以及合适的量子特征映射和量子门的可用性等因素。
最重要的是:量子机器学习领域仍处于早期阶段,VQC的实际实现和有效性目前受到构建大规模、纠错的量子计算机的挑战所限制。未来,随着量子硬件和算法的不断进步,可以预见在该领域的研究将持续进行,并且可能会出现更强大和高效的量子分类器。
今天关于《量子分类器简介:Variational Quantum Classifier (VQC)》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于机器学习的内容请关注golang学习网公众号!
 用Golang实现微信支付的Web应用程序
用Golang实现微信支付的Web应用程序
- 上一篇
- 用Golang实现微信支付的Web应用程序

- 下一篇
- 英特尔公布Innovation 2023大会日期,即将发布全新第14代酷睿处理器
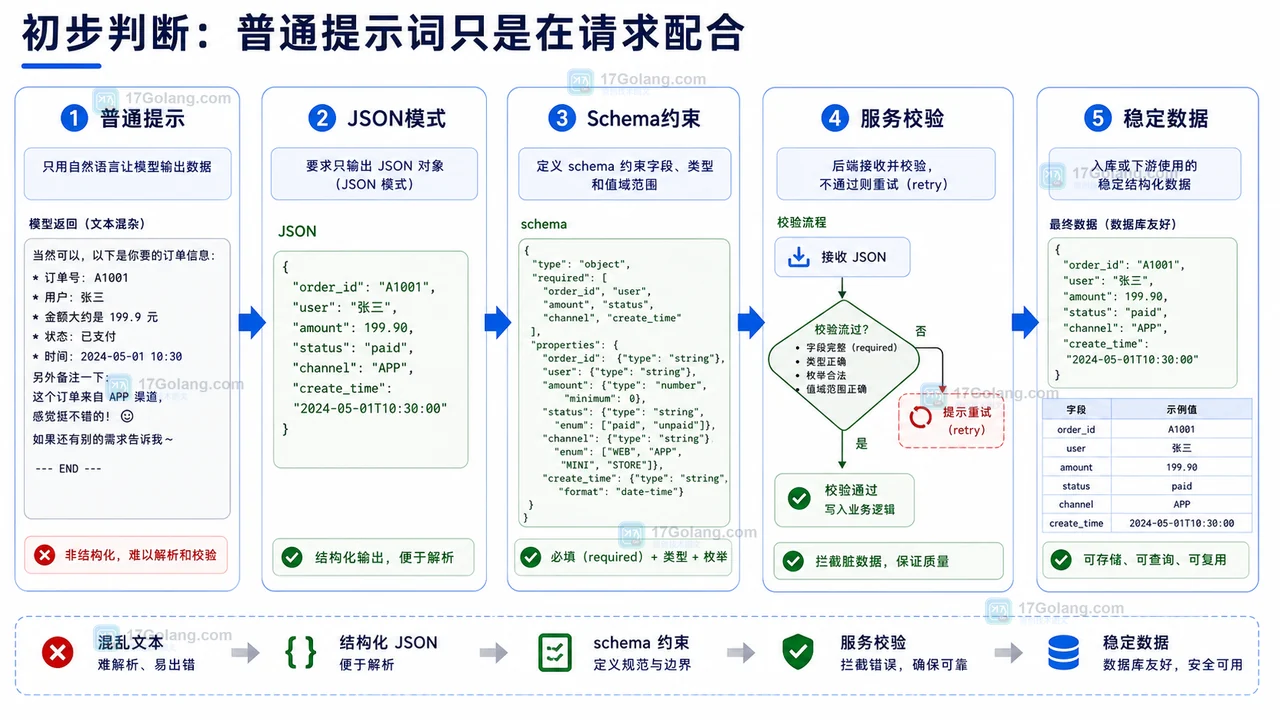
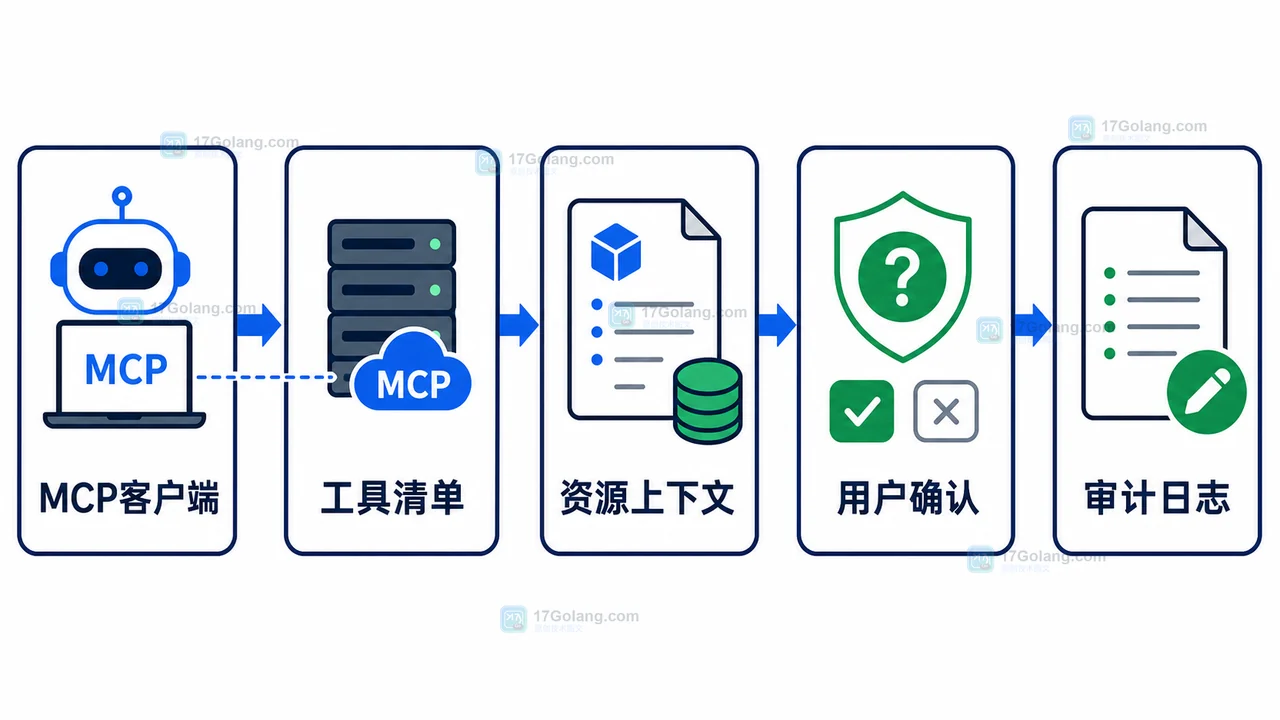
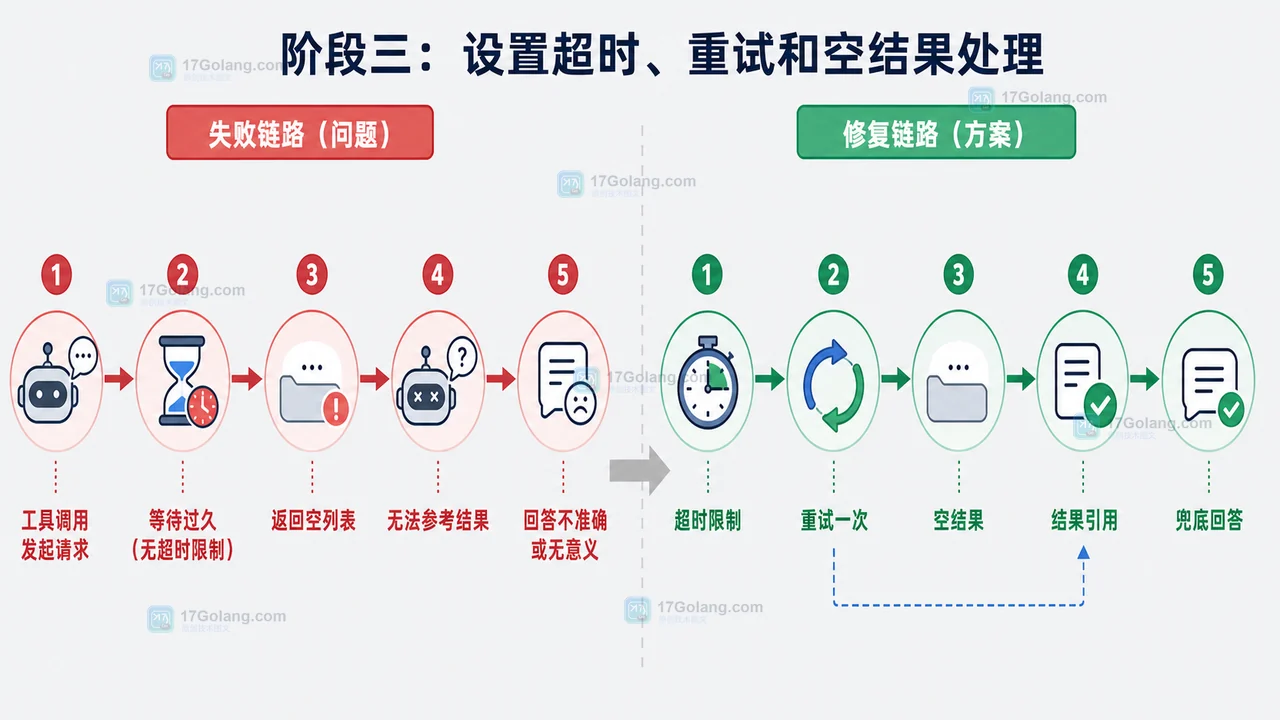
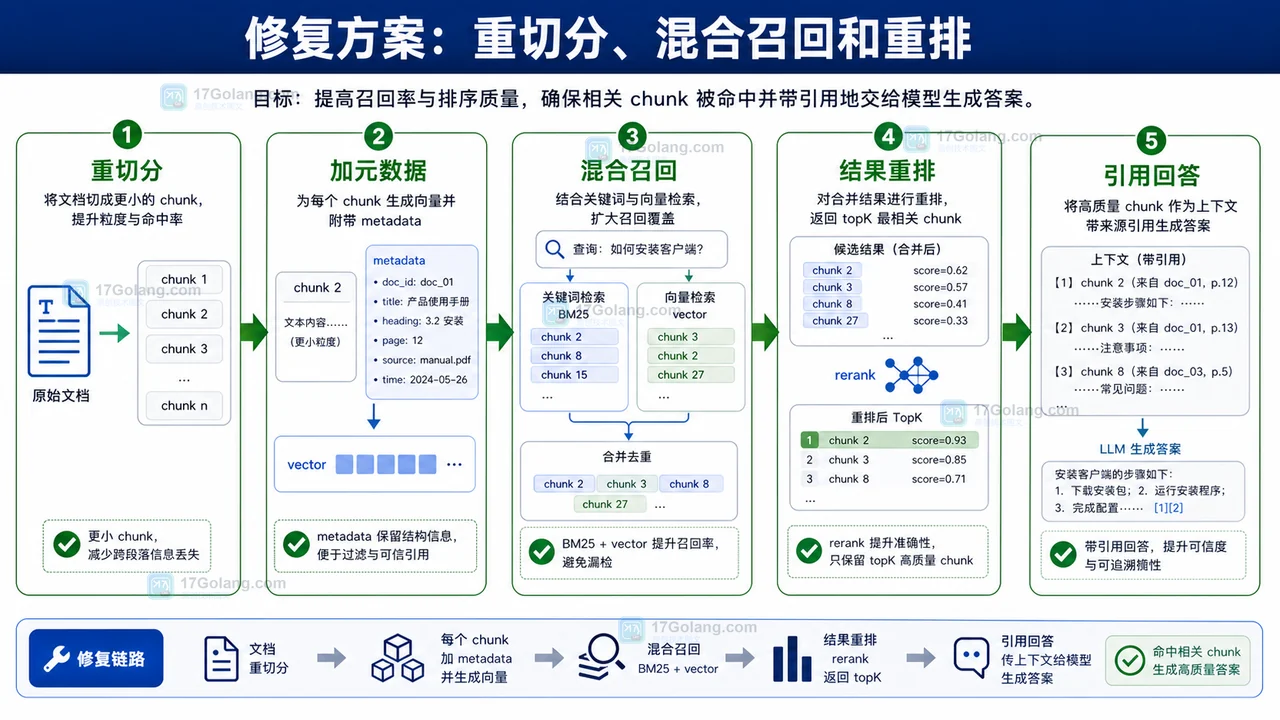

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 1834次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 1752次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 1703次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 1894次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 1881次使用
-
- AI写作工具免费版安装教程(含豆包Clawdbot)
- 2026-05-30 501浏览
-
- WPS AI能自动生成PPT吗?输入主题一键制作演示文稿
- 2026-05-27 501浏览
-
- Canva手机闪退解决方法及适配指南
- 2026-05-25 501浏览
-
- Hermes Agent依赖的工具链有哪些 必备工具链介绍
- 2026-05-05 501浏览
-
- 千问AI官网地址链接入口_千问AI官方网站登陆入口
- 2026-05-05 501浏览


