Graphql实战系列(下)
小伙伴们有没有觉得学习数据库很有意思?有意思就对了!今天就给大家带来《Graphql实战系列(下)》,以下内容将会涉及到MySQL、graphql、koa2、apollo-server、rest-api,若是在学习中对其中部分知识点有疑问,或许看了本文就能帮到你!
前情介绍
在《Graphql实战系列(上)》中我们已经完成技术选型,并将graphql桥接到凝胶gels项目中,并动手写了schema,并可以通过 http://localhost:5000/graphql 查看效果。这一节,我们根据数据库表来自动生成基本的查询与更新schema,并能方便的扩展schema,实现我们想要的业务逻辑。
效果图
用navicat在数据库中设计的表

自动生成的graphql测试

设计思路
对象定义在apollo-server中是用字符串来做的,而Query与Mutation只能有一个,而我们的定义又会分散在多个文件中,因此只能先以一定的形式把它们存入数组中,在生成schema前一刻再组合。
业务逻辑模块模板设计:
const customDefs = {
textDefs: `
type ReviseResult {
id: Int
affectedRows: Int
status: Int
message: String
},
queryDefs: [],
mutationDefs: []
}
const customResolvers = {
Query: {
},
Mutation: {
}
}
export { customDefs, customResolvers }
schema合并算法
let typeDefs = []
let dirGraphql = requireDir('../../graphql') //从手写schema业务模块目录读入文件
G.L.each(dirGraphql, (item, name) => {
if (item && item.customDefs && item.customResolvers) {
typeDefs.push(item.customDefs.textDefs || '') //合并文本对象定义
typeDefObj.query = typeDefObj.query.concat(item.customDefs.queryDefs || []) //合并Query
typeDefObj.mutation = typeDefObj.mutation.concat(item.customDefs.mutationDefs || []) //合并Matation
let { Query, Mutation, ...Other } = item.customResolvers
Object.assign(resolvers.Query, Query) //合并resolvers.Query
Object.assign(resolvers.Mutation, Mutation) //合并resolvers.Mutation
Object.assign(resolvers, Other) //合并其它resolvers
}
})
//将query与matation查询更新对象由自定义的数组转化成为文本形式
typeDefs.push(Object.entries(typeDefObj).reduce((total, cur) => {
return total += `
type ${G.tools.bigCamelCase(cur[0])} {
${cur[1].join('')}
}
`
}, ''))
从数据库表动态生成schema
自动生成内容:
- 一个表一个对象;
- 每个表有两个Query,一是单条查询,二是列表查询;
- 三个Mutation,一是新增,二是更新,三是删除;
- 关联表以上篇中的Book与Author为例,Book中有author_id,会生成一个Author对象;而Author表中会生成一个对象列表[Book]
mysql类型 => graphql 类型转化常量定义
定义一类型转换,不在定义中的默认为String。
const TYPEFROMMYSQLTOGRAPHQL = {
int: 'Int',
smallint: 'Int',
tinyint: 'Int',
bigint: 'Int',
double: 'Float',
float: 'Float',
decimal: 'Float',
}
从数据库中读取数据表信息
let dao = new BaseDao()
let tables = await dao.querySql('select TABLE_NAME,TABLE_COMMENT from information_schema.`TABLES` ' +
' where TABLE_SCHEMA = ? and TABLE_TYPE = ? and substr(TABLE_NAME,1,2) ? order by ?',
[G.CONFIGS.dbconfig.db_name, 'BASE TABLE', 't_', 'TABLE_NAME'])
从数据库中读取表字段信息
tables.data.forEach((table) => {
columnRs.push(dao.querySql('SELECT `COLUMNS`.COLUMN_NAME,`COLUMNS`.COLUMN_TYPE,`COLUMNS`.IS_NULLABLE,' +
'`COLUMNS`.CHARACTER_SET_NAME,`COLUMNS`.COLUMN_DEFAULT,`COLUMNS`.EXTRA,' +
'`COLUMNS`.COLUMN_KEY,`COLUMNS`.COLUMN_COMMENT,`STATISTICS`.TABLE_NAME,' +
'`STATISTICS`.INDEX_NAME,`STATISTICS`.SEQ_IN_INDEX,`STATISTICS`.NON_UNIQUE,' +
'`COLUMNS`.COLLATION_NAME ' +
'FROM information_schema.`COLUMNS` ' +
'LEFT JOIN information_schema.`STATISTICS` ON ' +
'information_schema.`COLUMNS`.TABLE_NAME = `STATISTICS`.TABLE_NAME ' +
'AND information_schema.`COLUMNS`.COLUMN_NAME = information_schema.`STATISTICS`.COLUMN_NAME ' +
'AND information_schema.`STATISTICS`.table_schema = ? ' +
'where information_schema.`COLUMNS`.TABLE_NAME = ? and `COLUMNS`.table_schema = ?',
[G.CONFIGS.dbconfig.db_name, table.TABLE_NAME, G.CONFIGS.dbconfig.db_name]))
})
几个工具函数
取数据库表字段类型,去除圆括号与长度信息
getStartTillBracket(str: string) {
return str.indexOf('(') > -1 ? str.substr(0, str.indexOf('(')) : str
}
下划线分隔的表字段转化为big camel-case
bigCamelCase(str: string) {
return str.split('_').map((al) => {
if (al.length > 0) {
return al.substr(0, 1).toUpperCase() + al.substr(1).toLowerCase()
}
return al
}).join('')
}
下划线分隔的表字段转化为small camel-case
smallCamelCase(str: string) {
let strs = str.split('_')
if (strs.length {
if (al.length > 0) {
return al.substr(0, 1).toUpperCase() + al.substr(1).toLowerCase()
}
return al
}).join('')
return strs[0] + tail
}
}
字段是否以_id结尾,是表关联的标志
不以_id结尾,是正常字段,判断是否为null,处理必填
typeDefObj[table].unshift(`${col['COLUMN_NAME']}: ${typeStr}${col['IS_NULLABLE'] === 'NO' ? '!' : ''}\n`)
以_id结尾,则需要处理关联关系
//Book表以author_id关联单个Author实体
typeDefObj[table].unshift(`"""关联的实体"""
${G.L.trimEnd(col['COLUMN_NAME'], '_id')}: ${G.tools.bigCamelCase(G.L.trimEnd(col['COLUMN_NAME'], '_id'))}`)
resolvers[G.tools.bigCamelCase(table)] = {
[G.L.trimEnd(col['COLUMN_NAME'], '_id')]: async (element) => {
let rs = await new BaseDao(G.L.trimEnd(col['COLUMN_NAME'], '_id')).retrieve({ id: element[col['COLUMN_NAME']] })
return rs.data[0]
}
}
//Author表关联Book列表
let fTable = G.L.trimEnd(col['COLUMN_NAME'], '_id')
if (!typeDefObj[fTable]) {
typeDefObj[fTable] = []
}
if (typeDefObj[fTable].length >= 2)
typeDefObj[fTable].splice(typeDefObj[fTable].length - 2, 0, `"""关联实体集合"""${table}s: [${G.tools.bigCamelCase(table)}]\n`)
else
typeDefObj[fTable].push(`${table}s: [${G.tools.bigCamelCase(table)}]\n`)
resolvers[G.tools.bigCamelCase(fTable)] = {
[`${table}s`]: async (element) => {
let rs = await new BaseDao(table).retrieve({ [col['COLUMN_NAME']]: element.id})
return rs.data
}
}
生成Query查询
单条查询
if (paramId.length > 0) {
typeDefObj['query'].push(`${G.tools.smallCamelCase(table)}(${paramId}!): ${G.tools.bigCamelCase(table)}\n`)
resolvers.Query[`${G.tools.smallCamelCase(table)}`] = async (_, { id }) => {
let rs = await new BaseDao(table).retrieve({ id })
return rs.data[0]
}
} else {
G.logger.error(`Table [${table}] must have id field.`)
}
列表查询
let complex = table.endsWith('s') ? (table.substr(0, table.length - 1) + 'z') : (table + 's')
typeDefObj['query'].push(`${G.tools.smallCamelCase(complex)}(${paramStr.join(', ')}): [${G.tools.bigCamelCase(table)}]\n`)
resolvers.Query[`${G.tools.smallCamelCase(complex)}`] = async (_, args) => {
let rs = await new BaseDao(table).retrieve(args)
return rs.data
}
生成Mutation查询
typeDefObj['mutation'].push(`
create${G.tools.bigCamelCase(table)}(${paramForMutation.slice(1).join(', ')}):ReviseResult
update${G.tools.bigCamelCase(table)}(${paramForMutation.join(', ')}):ReviseResult
delete${G.tools.bigCamelCase(table)}(${paramId}!):ReviseResult
`)
resolvers.Mutation[`create${G.tools.bigCamelCase(table)}`] = async (_, args) => {
let rs = await new BaseDao(table).create(args)
return rs
}
resolvers.Mutation[`update${G.tools.bigCamelCase(table)}`] = async (_, args) => {
let rs = await new BaseDao(table).update(args)
return rs
}
resolvers.Mutation[`delete${G.tools.bigCamelCase(table)}`] = async (_, { id }) => {
let rs = await new BaseDao(table).delete({ id })
return rs
}
项目地址
https://github.com/zhoutk/gels
使用方法
git clone https://github.com/zhoutk/gels cd gels yarn tsc -w nodemon dist/index.js
然后就可以用浏览器打开链接:http://localhost:5000/graphql 查看效果了。
小结
我只能把大概思路写出来,让大家有个整体的概念,若想很好的理解,得自己把项目跑起来,根据我提供的思想,慢慢的去理解。因为我在编写的过程中还是遇到了不少的难点,这块既要自动化,还要能方便的接受手动编写的schema模块,的确有点难度。
今天关于《Graphql实战系列(下)》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于mysql的内容请关注golang学习网公众号!
 透过 Crontab 排程备份 Mariadb (Mysql)使用 php
透过 Crontab 排程备份 Mariadb (Mysql)使用 php
- 上一篇
- 透过 Crontab 排程备份 Mariadb (Mysql)使用 php

- 下一篇
- 社区征稿 | 价值3200RMB的DTCC门票免费送!
-
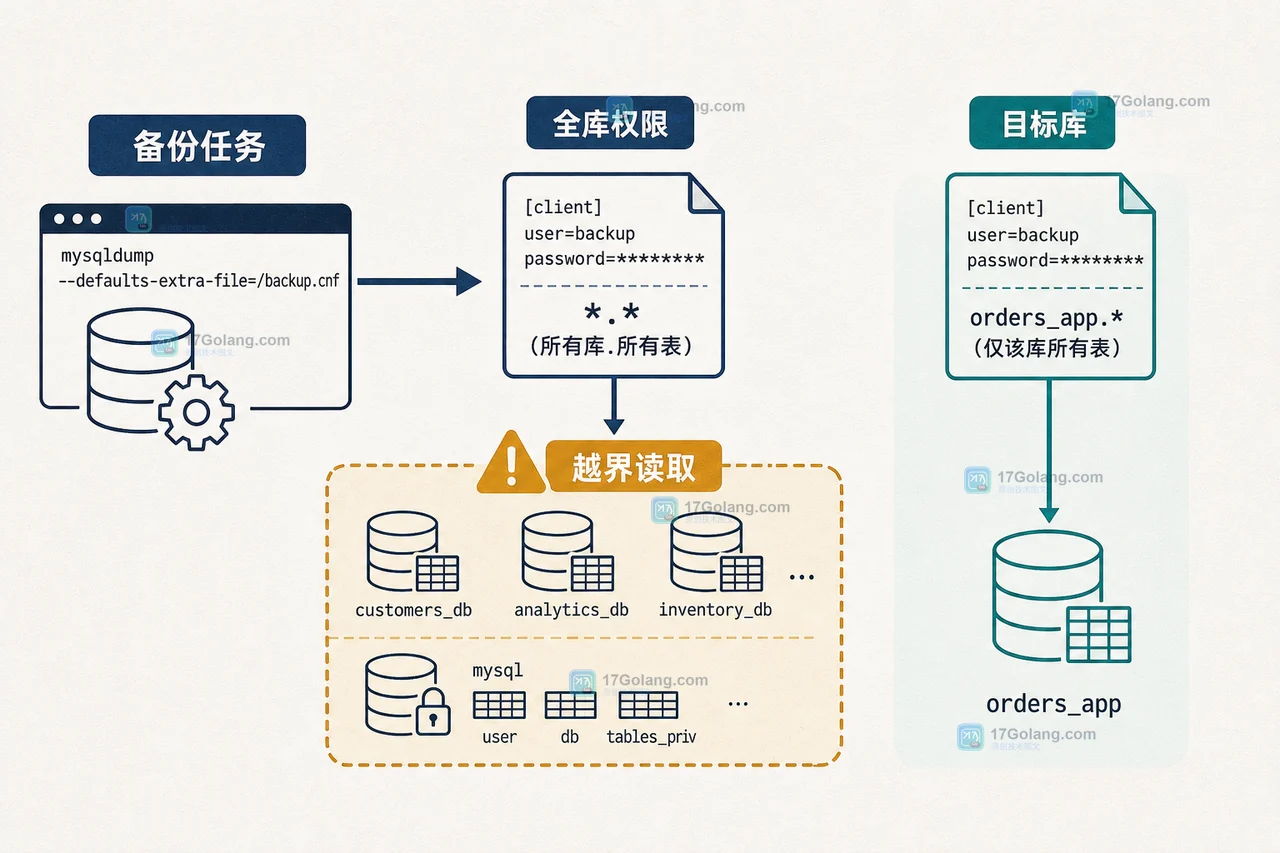
- 数据库 · MySQL | 1小时前 | MySQL · 权限管理 · 备份 · mysqldump · 数据库安全 · 最小权限 mysqldump备份账号 MySQL角色 partial_revokes 备份权限
- mysqldump 备份账号如何避免全库越权:MySQL 角色与 partial_revokes 实战
- 413浏览 收藏
-
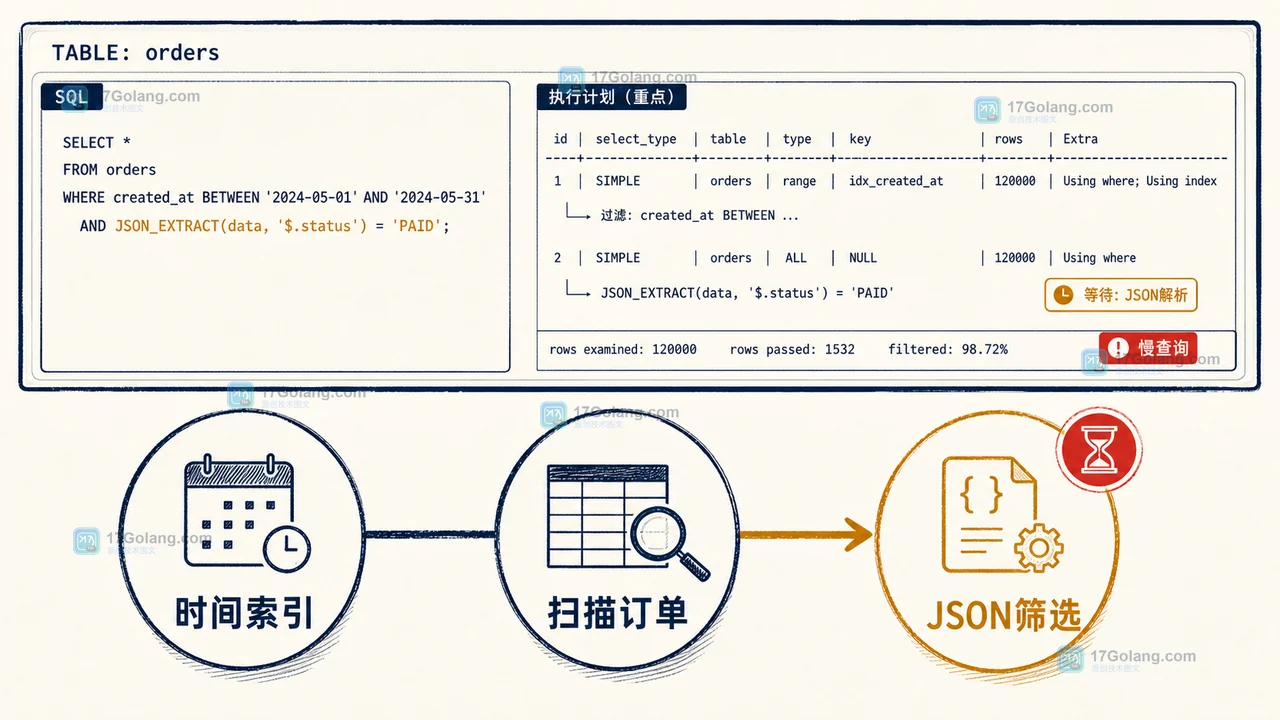
- 数据库 · MySQL | 3小时前 |
- MySQL JSON_EXTRACT 查询为什么慢:用生成列索引做一次可验证优化实验
- 278浏览 收藏
-

- 数据库 · MySQL | 1天前 | MySQL · JSON · 索引 · 数据库 · 查询优化 · 生成列 · json_extract 索引优化 列表筛选 生成列 MySQL JSON JSON索引
- MySQL JSON 字段怎么给列表筛选提速:生成列、索引与 NULL 边界
- 351浏览 收藏
-
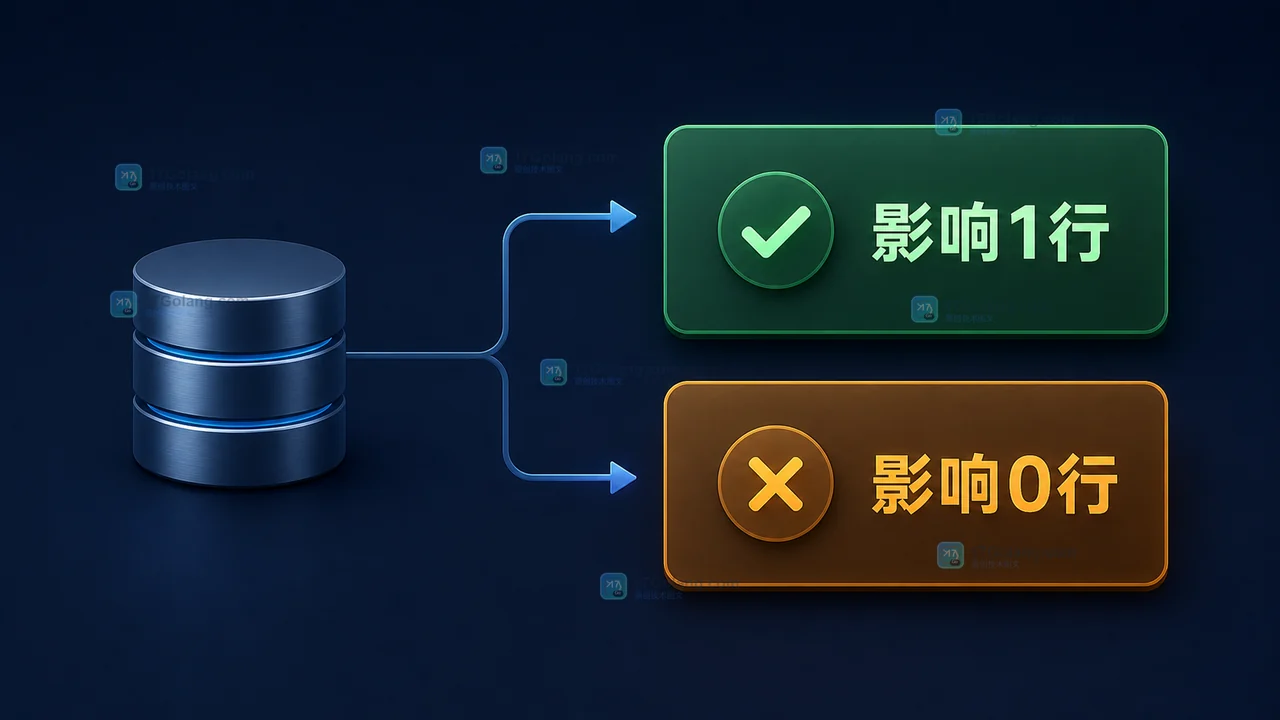
- 数据库 · MySQL | 6天前 | 并发 · MySQL · InnoDB · update · 库存扣减 · innodb MySQL 库存扣减 条件 UPDATE 防超卖 affected rows
- MySQL 库存怎么安全扣减?条件 UPDATE、防超卖和受影响行判断
- 470浏览 收藏


-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 4627次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 4244次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 4199次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 4423次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 4378次使用
-
- MySQL 明明加了索引,为什么查询还是很慢?先查这 6 个点
- 2026-06-27 374浏览
-
- golang MySQL实现对数据库表存储获取操作示例
- 2022-12-22 499浏览
-
- golang 基于 mysql 简单实现分布式读写锁
- 2023-01-07 384浏览
-
- 详解如何利用GORM实现MySQL事务
- 2023-01-07 184浏览
-
- Go语言实现操作MySQL的基础知识总结
- 2023-01-23 265浏览


