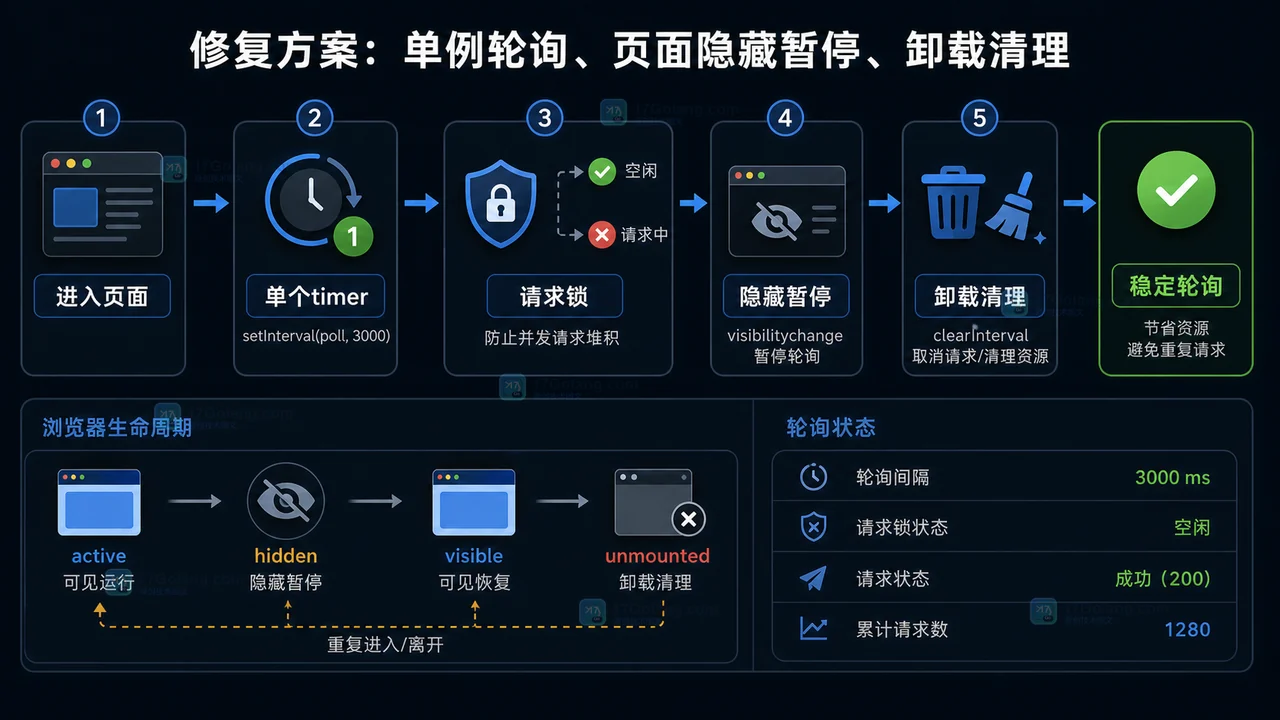
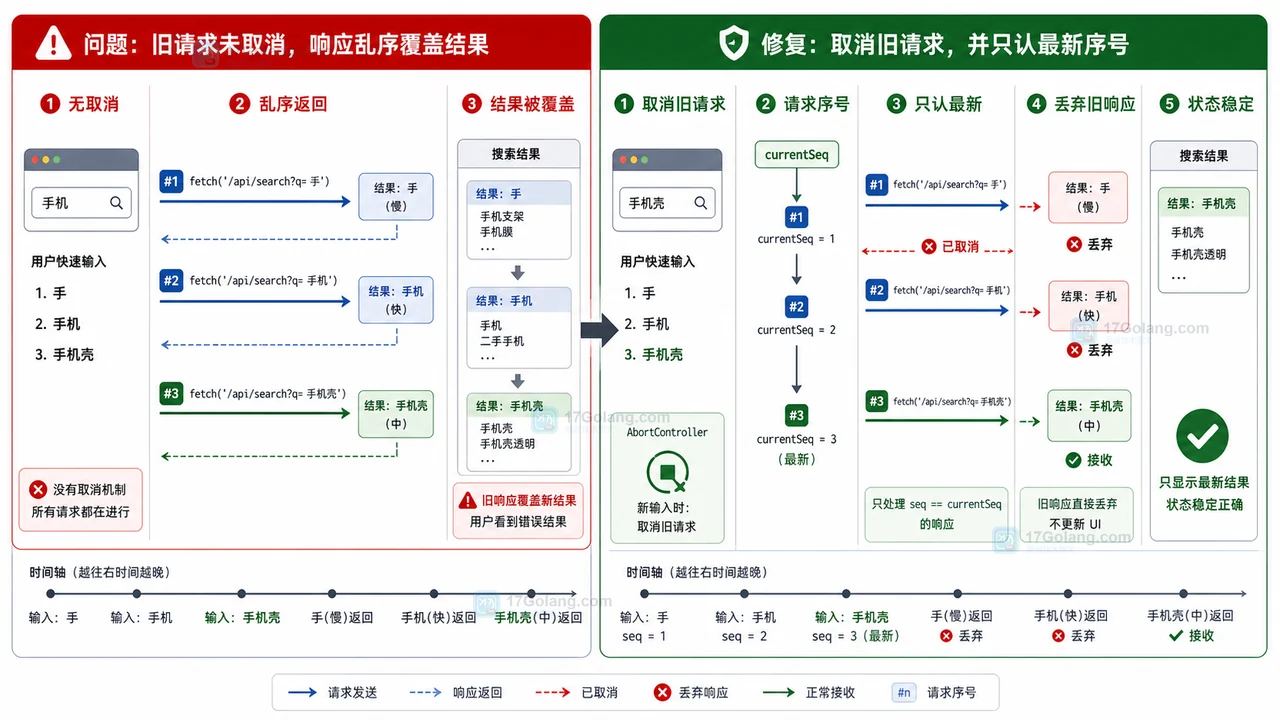
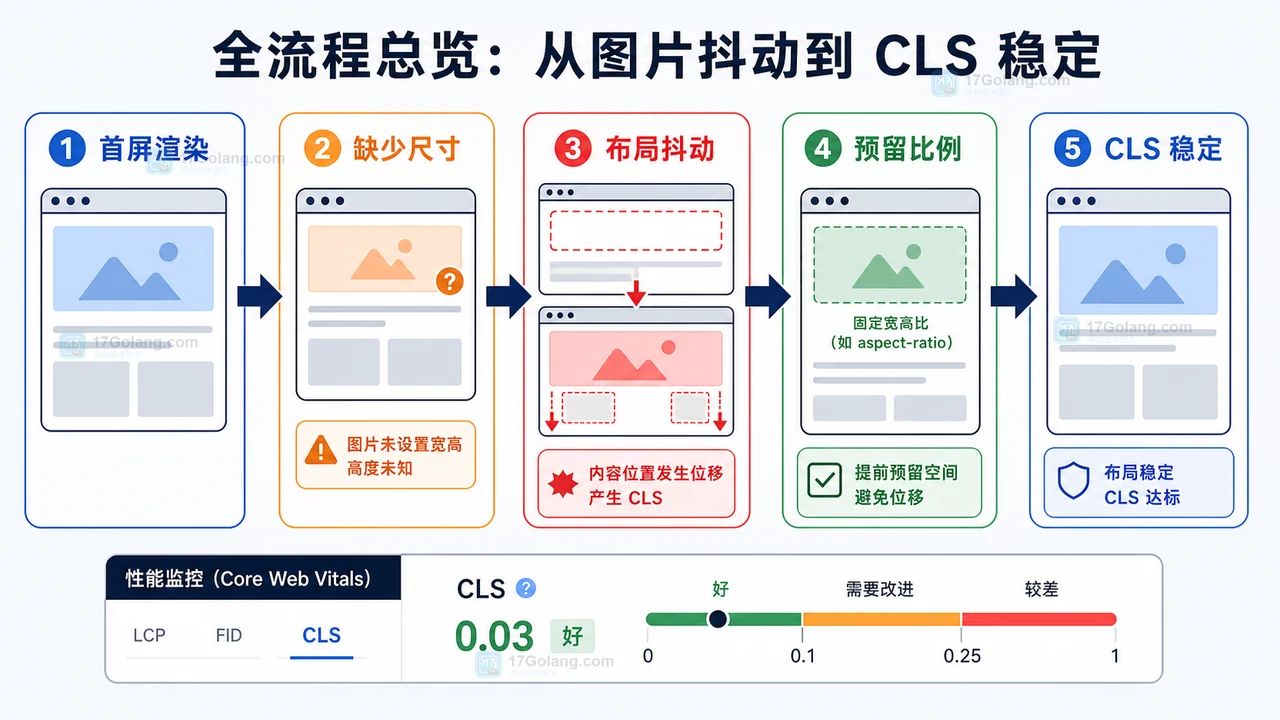
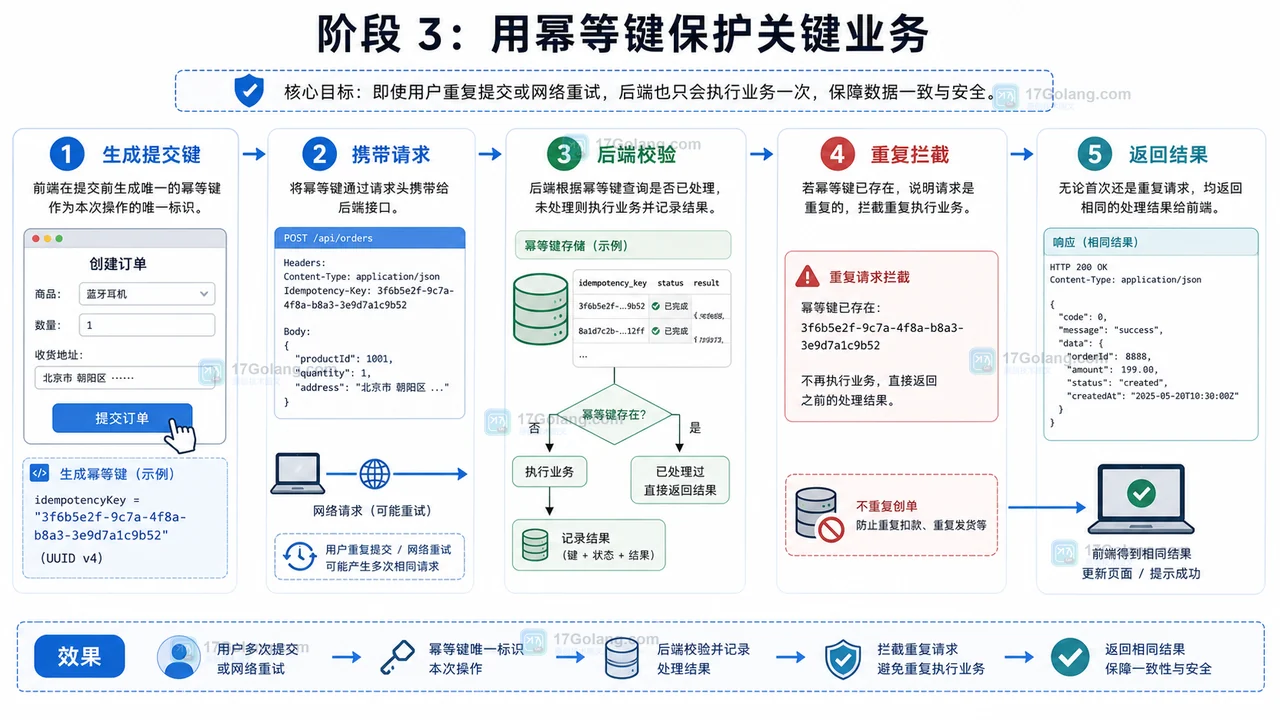
内容包含在 innerHTML 或 innerText 获取完整的HTML代码。因为 type 属性设置为 text/html,浏览器不会将其内容作为JavaScript代码执行,而是作为HTML数据处理,从而完整获取HTML内容。以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于文章的相关知识,也可关注golang学习网公众号。
JavaScript `innerHTML` 属性在获取HTML内容时,有时会丢失部分内容,导致获取不完整。这通常是因为浏览器在渲染包含完整HTML结构的元素时,会将其解析为独立文档,从而忽略外层标签。本文将深入分析`innerHTML`获取HTML不完整的原因,并提供有效的解决方案:将包含完整HTML结构的内容包裹在`

JavaScript innerHTML 属性获取HTML内容不完整?解决方案详解
在JavaScript DOM操作中,innerHTML 属性常用于获取或设置HTML元素内容。然而,有时它无法完整返回预期HTML代码。本文将分析此问题并提供解决方案。
问题:开发者尝试使用 原因:浏览器渲染HTML时会进行解析和处理。如果 解决方案:将包含完整HTML结构的内容放入不会被浏览器直接渲染的标签中,例如 例如,将原先的 以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于文章的相关知识,也可关注golang学习网公众号。innerHTML 获取 元素内容,但结果丢失了部分内容,仅返回了部分标签内容,而非 中完整的HTML结构。
包含完整的HTML文档结构,浏览器会将其解析为独立文档,innerHTML 获取的是渲染后的结果,而非原始HTML源代码。浏览器会忽略外层 ,直接解析内部HTML,导致内容丢失。
标签,并设置其 type 属性为 text/html。这样,浏览器不会解析这段HTML,innerHTML 即可获取完整的原始HTML代码。 替换为 ,并将 内容包含在 内。 通过此方法,即可使用 innerHTML 或 innerText 获取完整的HTML代码。因为 的 type 属性设置为 text/html,浏览器不会将其内容作为JavaScript代码执行,而是作为HTML数据处理,从而完整获取HTML内容。
 天岳先进赴港IPO申请已提交
天岳先进赴港IPO申请已提交