【MySQL—优化】表设计与数据类型优化
本篇文章向大家介绍《【MySQL—优化】表设计与数据类型优化》,主要包括MySQL,具有一定的参考价值,需要的朋友可以参考一下。
良好的逻辑设计和物理设计是高性能的基石,应该根据系统将要执行的查询语句来设计schema,这往往需要权衡各种因素。例如,反范式的设计可以加快某些类型的查询,但同时可能使另一些类型的查询变慢。比如添加计数表和汇总表是一种很好的优化查询的方式,但这些表的维护成本可能会很高。MySQL独有的特性和实现细节对性能的影响也很大。
选择优化的数据类型
MySQL支持的数据类型非常多,选择正确的数据类型对于获得高性能至关重要。不管存储哪种类型的数据,下面几个简单的原则都有助于做出更好的选择。
更小的通常更好
一般情况下,应该尽量使用可以正确存储数据的最小数据类型。更小的数据类型通常更快,因为它们占用更少的磁盘、内存和CPU缓存,并且处理时需要的CPU周期也更少。
简单就好
简单数据类型的操作通常需要更少的CPU周期。例如,整型比字符操作代价更低,因为字符集和校对规则(排序规则)使字符比较比整型比较更复杂。这里有两个例子:一个是应该使用MySQL内建的类型而不是字符串来存储日期和时间,另外一个是应该用整型存储IP地址。
尽量避免NULL
如果查询中包含可为NULL的列,对MySQL来说更难优化,不使用NULL的理由有:
- 所有使用NULL值的情况,都可以通过一个有意义的值的表示,这样有利于代码的可读性和可维护性,并能从约束上增强业务数据的规范性。
- NULL值到非NULL的更新无法做到原地更新,更容易发生索引分裂,从而影响性能。(null -> not null性能提升很小,除非确定它带来了问题,否则不要当成优先的优化措施)
- NULL值在timestamp类型下容易出问题,特别是没有启用参数explicit_defaults_for_timestamp。
- NOT IN、!= 等负向条件查询在有 NULL 值的情况下返回永远为空结果,查询容易出错。
- NULL会使索引、索引统计和值比较都更加复杂,并且在MyISIM中需要额外一个字节的存储空间。
在为列选择数据类型时,第一步需要确定合适的大类型:数字、字符串、时间等,下一步是选择具体类型。很多MySQL的数据类型可以存储相同类型的数据,只是存储的长度和范围不一样、允许的精度不同,或者需要的物理空间(磁盘和内存空间)不同。相同大类型的不同子类型数据有时也有一些特殊的行为和属性。
整数类型
如果存储整数,可以使用这几种整数类型:TINYINT,SMALLINT,MEDIUMINT,INT,BIGINT。分别使用8,16,24,32,64位存储空间。它们可以存储的值的范围从−2(N−1)到2(N−1)−1,其中N是存储空间的位数。
整数类型有可选的UNSIGNED属性,表示不允许负值,这大致可以使正数的上限提高一倍。例如TINYINT UNSIGNED可以存储的范围是0~255,而TINYINT的存储范围是−128~127。有符号和无符号类型使用相同的存储空间,并具有相同的性能,因此可以根据实际情况选择合适的类型。
注:IP地址实际上是32位无符号整数,应该用INT存储,MySQL提供INETATON和INETNTOA两个转换IP地址的函数。
实数类型
实数是带有小数部分的数字。然而,它们不只是为了存储小数部分,也可以使用DECIMAL存储比BIGINT还大的整数。MySQL既支持精确类型,也支持不精确类型。FLOAT和DOUBLE类型支持使用标准的浮点运算进行近似计算,如果需要知道浮点运算是怎么计算的,则需要研究所使用的平台的浮点数的具体实现。DECIMAL类型用于存储精确的小数,在MySQL 5.0和更高版本,DECIMAL类型支持精确计算。
浮点和DECIMAL类型都可以指定精度。对于DECIMAL列,可以指定小数点前后所允许的最大位数,这会影响列的空间消耗,MySQL 5.0和更高版本将数字打包保存到一个二进制字符串中(每4个字节存9个数字)。例如,DECIMAL(18,9)小数点两边将各存储9个数字,一共使用9个字节:小数点前的数字用4个字节,小数点后的数字用4个字节,小数点本身占1个字节。
浮点类型在存储同样范围的值时,通常比DECIMAL使用更少的空间。FLOAT使用4个字节存储。DOUBLE占用8个字节,相比FLOAT有更高的精度和更大的范围。
因为需要额外的空间和计算开销,所以应该尽量只在对小数进行精确计算时才使用DECIMAL——例如存储财务数据。但在数据量比较大的时候,可以考虑使用BIGINT代替DECIMAL,将需要存储的货币单位根据小数的位数乘以相应的倍数即可,这样可以同时避免浮点存储计算不精确和DECIMAL精确计算代价高的问题。
字符串类型
VARCHAR和CHAR类型
由于现在基本上所有的MySQL数据库使用的都是InnoDB存储引擎,而且使用的字符集都是utf8或者utf8mb4这样的多字节字符集。在这种情况下,varchar和char类型都需要使用1~2个额外字节去存储字符串的长度,此时char相比varchar已经不具有任何的优势,所以推荐所有的字符串类型都使用varchar。
BLOB和TEXT类型
BLOB和TEXT都是为存储很大的数据而设计的字符串数据类型,分别采用二进制和字符方式存储。
MySQL对BLOB和TEXT列进行排序与其他类型是不同的:它只对每个列的最前max_sort_length字节而不是整个字符串做排序。如果只需要排序前面一小部分字符,则可以减小max_sort_length的配置,或者使用ORDER BY SUSTRING(column,length)。
MySQL不能将BLOB和TEXT列全部长度的字符串进行索引,也不能使用这些索引消除排序。同时因为Memory引擎不支持BLOB和TEXT类型,所以,如果查询使用了BLOB或TEXT列并且需要使用隐式临时表,将不得不使用磁盘临时表。
最好的解决方案是尽量避免使用BLOB和TEXT类型。如果实在无法避免,有一个技巧是在所有用到BLOB字段的地方都使用SUBSTRING(column,length)将列值转换为字符串(在ORDER BY子句中也适用),这样就可以使用内存临时表了。但是要确保截取的子字符串足够短,不会使临时表的大小超过max_heap_table_size或tmp_table_size,超过以后MySQL会将内存临时表转换为MyISAM磁盘临时表。
日期和时间类型
DATETIME类型能保存1001年到9999年范围的值,精度为秒,与时区无关,使用8个字节的存储空间。TIMESTAAMP类型保存了格林尼治标准时间以来的秒数,只能表示1970年到2038年范围的值,显示的值依赖时区,使用4个字节的存储空间。
通常应该尽量使用TIMESTAMP,因为它比DATETIME空间效率更高。
注:MySQL5.6.4版本开始支持比秒更小的存储粒度,格式为 时间类型(如timestamp)(n),n最大为6。
标识列数据类型选择
整数通常是标识列最好的选择,因为它们很快并且可以使用AUTO_INCREMENT。
如果可能,应该避免使用字符串类型作为标识列,例如MD5()、SHA1()或者UUID()产生的字符串。因为它们很消耗空间,并且通常比数字类型慢。这些函数生成的新值会任意分布在很大的空间内,这会导致INSERT以及一些SELECT语句变得很慢:
- 因为插入值会随机地写到索引的不同位置,所以使得INSERT语句更慢。这会导致页分裂、磁盘随机访问,以及对于聚簇存储引擎产生聚簇索引碎片。
- SELECT语句会变得更慢,因为逻辑上相邻的行会分布在磁盘和内存的不同地方。
- 随机值导致缓存对所有类型的查询语句效果都很差,因为会使得缓存赖以工作的访问局部性原理失效。如果整个数据集都一样的“热”,那么缓存任何一部分特定数据到内存都没有好处;如果工作集比内存大,缓存将会有很多刷新和不命中。
不好的Schema设计实践
过多的列
MySQL的存储引擎API工作时需要在服务器层和存储引擎层之间通过行缓冲格式拷贝数据,然后在服务器层将缓冲内容解码成各个列。从行缓冲中将编码过的列转换成行数据结构的操作代价是非常高的,转换的代价依赖于列的数量。
过多的关联
如果查询中存在过多的关联,那么解析和优化查询的代价会成为MySQL的问题。一个粗略的经验法则,如果希望查询执行得快速且并发性好,单个查询最好在12个表以内做关联。
过度使用ENUM
如果列的值可能会在以后扩充,那么就应该避免使用ENUM类型。在MySQL 5.1和更新版本中,如果不是在列表的末尾增加值会需要ALTER TABLE,对于大表来说会导致严重的性能问题。
范式和反范式
范式的优点:
- 范式化的更新操作通常比反范式化要快。
- 当数据较好地范式化时,就只有很少或者没有重复数据,所以只需要修改更少的数据。
- 范式化的表通常更小,可以更好地放在内存里,所以执行操作会更快。
- 很少有多余的数据意味着检索列表数据时更少需要DISTINCT或者GROUP BY语句。
范式的缺点:
- 通常需要关联。
- 范式化可能将列存放在不同的表中,这样会使某些索引失效。
混用范式化和反范式化
范式化和反范式化的schema各有优劣,怎么选择最佳的设计?事实是,在实际应用中经常需要混用,可能使用部分范式化的schema、缓存表,以及其他技巧。最常见的反范式化数据的方法是复制或者缓存,在不同的表中存储相同的特定列。
在某些需要特定的查询条件和排序的情况下,可以在父表中冗余一些字段到子表。例如有user表和message表,要查询付费用户最近10条数据,完全范式化查询的效率较低下,可以在message表中冗余账户类型的字段并建立好索引,这将非常高效。不过更新账户类型的时候需要更新两张表。这时需要考虑更新的频率及时长,来和查询的频率作比较,然后做出取舍。
缓存衍生值也是有用的。如果需要显示每个用户发了多少消息(像很多论坛做的),可以每次执行一个昂贵的子查询来计算并显示它,也可以在user表中建一个num_messages列,每当用户发新消息时更新这个值。
延伸阅读:
对关系型数据库五个范式的理解
如何理解关系型数据库的常见设计范式?
缓存表和汇总表
有时提升性能最好的方法是在同一张表中保存衍生的冗余数据。然而,有时也需要创建一张完全独立的汇总表或缓存表(特别是为满足检索的需求时)。如果能容许少量的脏数据,这是非常好的方法,但是有时确实没有选择的余地(例如,需要避免复杂、昂贵的实时更新操作)。
术语“缓存表”和“汇总表”没有标准的含义。我们用术语“缓存表”来表示存储那些可以比较简单地从schema其他表获取(但是每次获取的速度比较慢)数据的表(例如,逻辑上冗余的数据)。而术语“汇总表”时,则保存的是使用GROUP BY语句聚合数据的表(例如,数据不是逻辑上冗余的)。也有人使用术语“累积表(Roll-Up Table)”称呼这些表。因为这些数据被“累积”了。
以网站为例,假设需要计算之前24小时内发送的消息数。在一个很繁忙的网站不可能维护一个实时精确的计数器。作为替代方案,可以每小时生成一张汇总表。这样也许一条简单的查询就可以做到,并且比实时维护计数器要高效得多。缺点是计数器并不是100%精确。
如果必须获得过去24小时准确的消息发送数量(没有遗漏),有另外一种选择。以每小时汇总表为基础,把前23个完整的小时的统计表中的计数全部加起来,最后再加上开始阶段和结束阶段不完整的小时内的计数。
当然,更好的方法是使用内存数据库来完成这个计数器,例如Redis。
更新大表
在大表上运行UPDATE语句,对于任何数据库都可能会很慢,因为每一行都需要重写。如果这是不可接受的,应用程序可以将需要更新的行设置为默认值NULL,并在读取时填充它并更新。
好了,本文到此结束,带大家了解了《【MySQL—优化】表设计与数据类型优化》,希望本文对你有所帮助!关注golang学习网公众号,给大家分享更多数据库知识!
 mysql 表中id 字段默认不带有 自增属性怎么改
mysql 表中id 字段默认不带有 自增属性怎么改
- 上一篇
- mysql 表中id 字段默认不带有 自增属性怎么改

- 下一篇
- Mysql 误删的恢复和预防思维导图
-

- 沉默的小刺猬
- 写的不错,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢作者大大分享文章内容!
- 2023-03-03 09:51:57
-
- 活泼的吐司
- 这篇技术贴真及时,太细致了,太给力了,码起来,关注大佬了!希望大佬能多写数据库相关的文章。
- 2023-02-25 19:35:25
-
- 无聊的缘分
- 这篇博文出现的刚刚好,楼主加油!
- 2023-02-20 09:44:06
-
- 苹果月饼
- 太细致了,码住,感谢up主的这篇文章内容,我会继续支持!
- 2023-02-14 03:43:00
-
- 刻苦的过客
- 这篇文章内容真及时,细节满满,写的不错,已加入收藏夹了,关注作者了!希望作者能多写数据库相关的文章。
- 2023-01-30 08:07:49
-
- 勤劳的白猫
- 好细啊,码住,感谢老哥的这篇博文,我会继续支持!
- 2023-01-28 08:07:06
-
- 负责的蓝天
- 很有用,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢博主分享博文!
- 2023-01-27 14:10:59
-
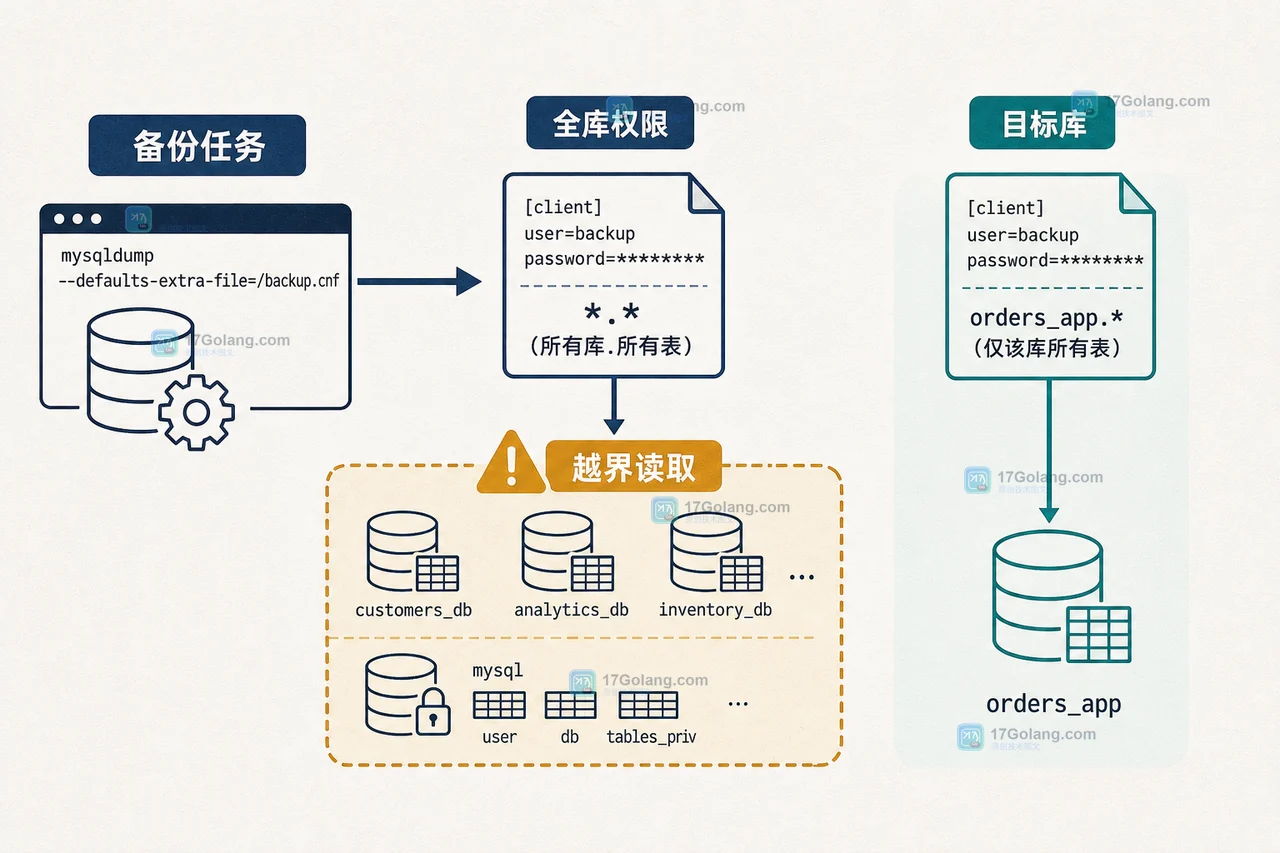
- 数据库 · MySQL | 3小时前 | MySQL · 权限管理 · 备份 · mysqldump · 数据库安全 · 最小权限 mysqldump备份账号 MySQL角色 partial_revokes 备份权限
- mysqldump 备份账号如何避免全库越权:MySQL 角色与 partial_revokes 实战
- 413浏览 收藏
-
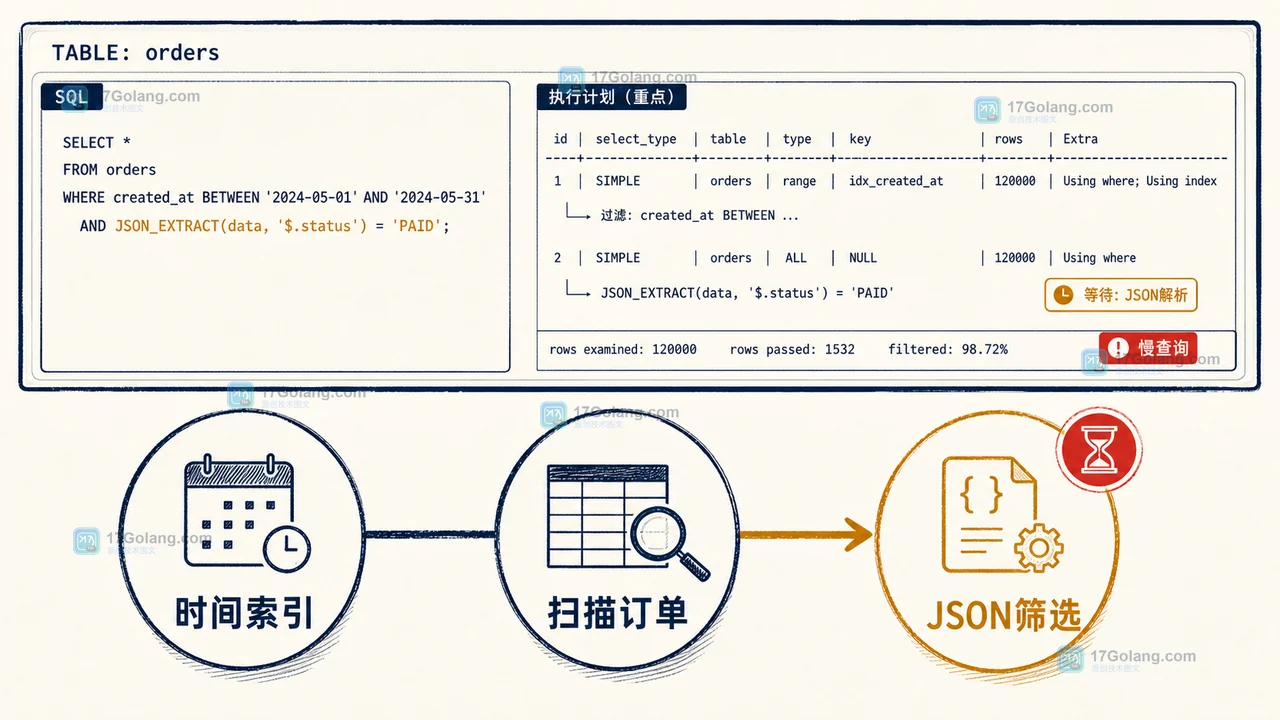
- 数据库 · MySQL | 5小时前 |
- MySQL JSON_EXTRACT 查询为什么慢:用生成列索引做一次可验证优化实验
- 278浏览 收藏
-

- 数据库 · MySQL | 1天前 | MySQL · JSON · 索引 · 数据库 · 查询优化 · 生成列 · json_extract 索引优化 列表筛选 生成列 MySQL JSON JSON索引
- MySQL JSON 字段怎么给列表筛选提速:生成列、索引与 NULL 边界
- 351浏览 收藏
-
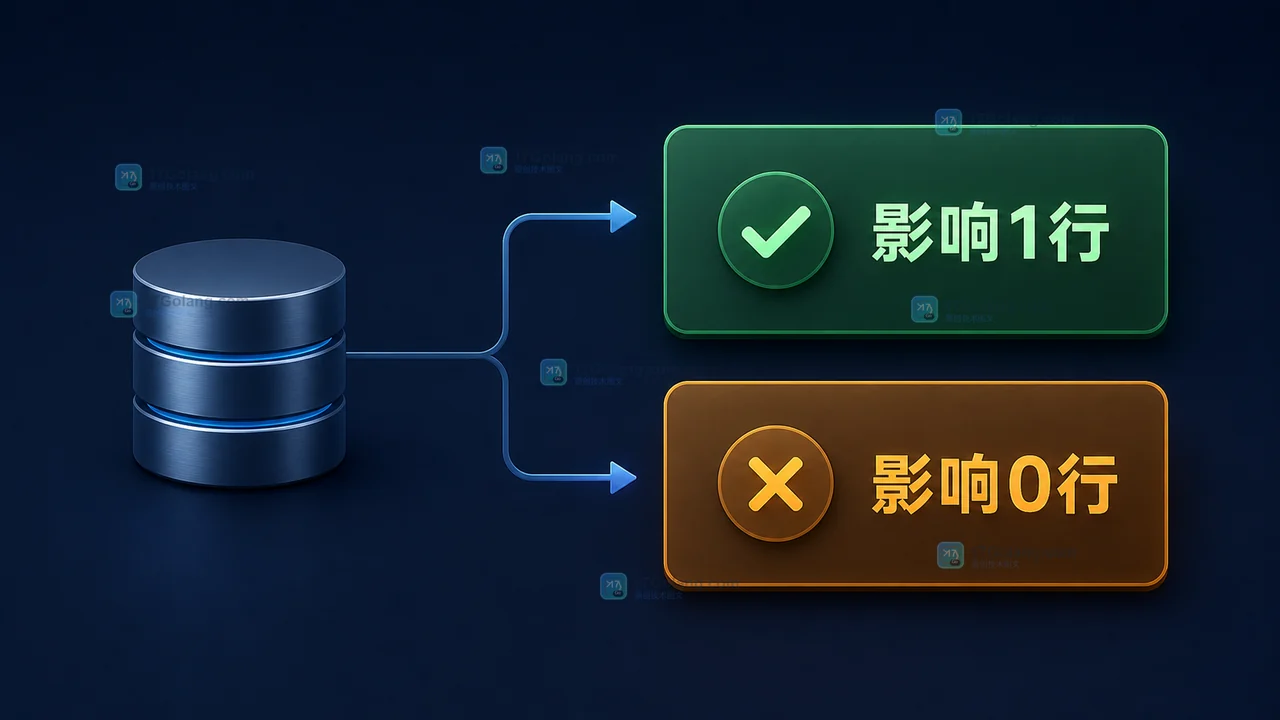
- 数据库 · MySQL | 6天前 | 并发 · MySQL · InnoDB · update · 库存扣减 · innodb MySQL 库存扣减 条件 UPDATE 防超卖 affected rows
- MySQL 库存怎么安全扣减?条件 UPDATE、防超卖和受影响行判断
- 470浏览 收藏


-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 4627次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 4245次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 4199次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 4423次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 4378次使用
-
- MySQL 明明加了索引,为什么查询还是很慢?先查这 6 个点
- 2026-06-27 374浏览
-
- golang MySQL实现对数据库表存储获取操作示例
- 2022-12-22 499浏览
-
- golang 基于 mysql 简单实现分布式读写锁
- 2023-01-07 384浏览
-
- 详解如何利用GORM实现MySQL事务
- 2023-01-07 184浏览
-
- Go语言实现操作MySQL的基础知识总结
- 2023-01-23 265浏览


