Redis集群方案
本篇文章给大家分享《Redis集群方案》,覆盖了数据库的常见基础知识,其实一个语言的全部知识点一篇文章是不可能说完的,但希望通过这些问题,让读者对自己的掌握程度有一定的认识(B 数),从而弥补自己的不足,更好的掌握它。
前段时间搞了搞Redis集群,想用做推荐系统的线上存储,说来挺有趣,这边基础架构不太完善,因此需要我们做推荐系统的自己来搭这个存储环境,就自己折腾了折腾。公司所给机器的单机性能其实挺给力,已经可以满足目前的业务需求,想做redis集群主要有以下几点考虑:
1、扩展性,scale-out,以后数据量变得很大之后,不至于推到重来,redis虽然可以开启虚拟内存功能,单机也能提供超过物理内存上限的容量,但频繁在内存和硬盘间swap页会大大降低其性能,有点儿违背redis的设计初衷。
2、redis是一个单线程io复用的结构,无法有效利用服务器的多核结构,如果能在一台多核机器起多个redis进程,共同提供服务,效率会更高一些。
3、主从,数据备份和容灾。。
因此计划做的redis集群希望可以实现以下功能:
1、data sharding,支持数据切片。
2、主从备份,主节点写数据,主和从都提供读请求服务,并且支持主从自动切换。
3、读请求做负载均衡。
4、更好地,支持节点failover,数据自动迁移。
下面是前后经历的一个过程:
【第一步】尝试官方方案
肯定想去查看一下redis的官方集群方案,但是很遗憾,官方对cluster的声明如下:
Unfortunately Redis Cluster is currently not production ready, however you can get more information about it reading the specification or checking the partial implementation in the unstable branch of the Redis GitHub repositoriy.
Once Redis Cluster will be available, and if a Redis Cluster complaint client is available for your language, Redis Cluster will be the de facto standard for Redis partitioning.
Redis Cluster is a mix between query routing and client side partitioning.
由于这边想做生产环境部署,unstable branch目前还是不敢用,在官方目前的版本上做提前开发又没有资源和时间,因此就放弃了。
【第二步】初步设想的方案
舍弃了官方的方案后,就想能不能自己搭一个,当时初步的想法是:用lvs做读请求的负载均衡,在客户端代码里自己写一个一致性hash算法做数据切片,配置redis主从,并且配置keepalived做主从自动切换。这个方案应该可以施行的,但当时自己遇到一些细节方面的问题,就在stackoverflow上问了一下,问题如下:
Since the redis cluster is still a work in progress, I want to build a simplied one by myselfin the current stage. The system should support data sharding,load balance and master-slave backup. A preliminary plan is as follows:
-
Master-slave: use multiple master-slave pairs in different locations to enhance the data security. Matsters are responsible for the write operation, while both masters and slaves can provide the read service. Datas are sent to all the masters during one write operation. Use Keepalived between the master and the slave to detect failures and switch master-slave automatically.
-
Data sharding: write a consistant hash on the client side to support data sharding during write/read in case the memory is not enougth in single machine.
-
Load balance: use LVS to redirect the read request to the corresponding server for the load balance.
My question is how to combine the LVS and the data sharding together?
For example, because of data sharding, all keys are splited and stored in server A,B and C without overlap. Considering the slave backup and other master-slave pairs, the system will contain 1(A,B,C), 2(A,B,C) , 3(A,B,C) and so on, where each one has three servers. How to configure the LVS to support the redirection in such a situation when a read request comes? Or is there other approachs in redis to achieve the same goal?
Thanks:)
有个网友给了两个建议:
You can really close to what you need by using:
twemproxy shard data across multiple redis nodes (it also supports node ejection and connection pooling)
redis slave master/slave replication
redis sentinel to handle master failover
depending on your needs you probably need some script listening to fail overs (see sentinel docs) and clean things up when a master goes down
这位网友的两个建议挺启发的,我在看redis的官方doc的时候,对twemproxy有一些印象,但当时没有太在意,至于后者用redis sentinel做master failover,redis sentinel也是一个redis正在开发中的模块,我不太敢用。
另外,我舍弃自己的这个初步方案还有两个原因:
1、自己在写客户端data sharding和均衡服务的时候,发现实际需要考虑的问题比开始想的要复杂一些,如果写完,其实相当于将twemproxy的功能做了一遍,造轮子的事情还是少干。
2、功能做得有些冗余,一次读请求要经过客户端的sharding、然后还有经过lvs再到实际的服务器,不做优化的话,会增加不少延迟。
【第三步】最终的方案,如下图所示
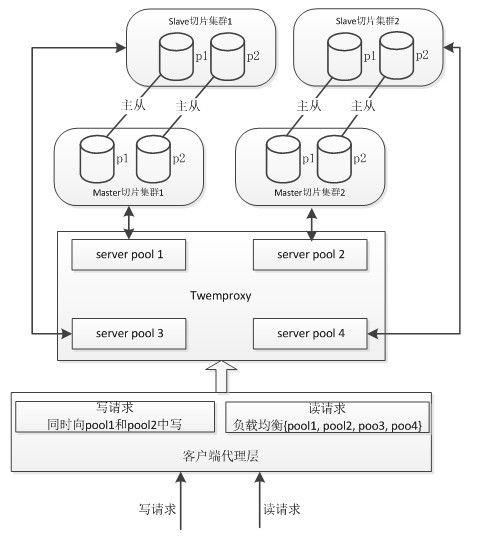
图中画的挺明白了,就不再多解释了。
twemproxy是twitter开源的一个数据库代理服务,可以用于memcached和redis的sharding,兼容二者的标准接口,但是对于redis的keys,dbsize等命令不支持,这个其实想一下也就明白了,这种pool内跨机做统计的命令proxy一般不会支持的。另外,twemproxy在自身与后台redis之间使用pipeline发送命令,因此性能损失比较小。但是,twemproxy对于每一个客户端连接开启的mbuf有限,最大可以设置为64k,如果在客户端代理层与twemproxy之间也使用pipeline,这个pipeline不能太深,而且不支持pipeline的原子性(transaction),其实,这个时候,相当于客户端连接与redis数据库之间存在两层pipeline,分别是客户端到twemproxy的pipeline,和twemproy到后台redis服务器的pipeline,由于二者buffer深度不一致,因此不支持pipeline的transaction也就好理解了。。在引入了twemproxy,插入大规模数据的时候,有时候确实挺耗时,而且pipeline不保证原子性,丢数据时的恢复问题在客户端需要进行额外关注。对于非transaction的pipeline总丢数据,或者对于数据量比较大的key一次性取数据失败等问题,后来经查是twemproxy端timeou值设置过小,按照官方示例设置400ms,会在一次性操作大数据量的时候返回timeout失败,这个数值需要慎重根据业务(具体的,就是客户端单次命令操作的数据量)进行设置,一般2000ms差不多就够用了(可以支持一次操作接近百万的数据)。
上面的结构,将读操作的负载均衡放到了客户端代码来做,写操作控制也在客户端层的代码里,另外,对于twemproy单点、主从之间可以引入keepalived来消除单点和故障恢复。
今天关于《Redis集群方案》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于redis的内容请关注golang学习网公众号!
 Redis缓存穿透出现原因及解决方案
Redis缓存穿透出现原因及解决方案
- 上一篇
- Redis缓存穿透出现原因及解决方案

- 下一篇
- Redis连接超时异常的处理方法
-

- 聪明的书本
- 赞 ??,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢up主分享文章内容!
- 2023-01-26 04:15:14
-
- 矮小的花瓣
- 这篇技术文章真是及时雨啊,太全面了,很有用,码起来,关注大佬了!希望大佬能多写数据库相关的文章。
- 2023-01-14 09:35:10
-
- 苹果发箍
- 这篇文章出现的刚刚好,太全面了,很棒,已收藏,关注作者大大了!希望作者大大能多写数据库相关的文章。
- 2023-01-09 00:03:27
-
- 成就的书包
- 这篇技术贴太及时了,细节满满,赞 ??,码住,关注大佬了!希望大佬能多写数据库相关的文章。
- 2023-01-05 12:48:39
-
- 迷路的小伙
- 好细啊,码住,感谢博主的这篇文章内容,我会继续支持!
- 2023-01-05 11:59:24
-
- 狂野的枕头
- 受益颇多,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢博主分享博文!
- 2023-01-04 12:39:35
-
- 丰富的曲奇
- 这篇技术贴真及时,作者加油!
- 2023-01-03 05:03:31
-
- 和谐的山水
- 细节满满,码住,感谢作者的这篇文章,我会继续支持!
- 2023-01-01 19:10:03
-

- 数据库 · Redis | 2天前 | Redis · 缓存 · go · Redis Cluster · 排错 · Redis Cluster CROSSSLOT Hash Tag MGET CLUSTER KEYSLOT
- Redis Cluster 批量读取报 CROSSSLOT:Hash Tag、MGET 与迁移期检查
- 259浏览 收藏
-
- 数据库 · Redis | 6天前 | Redis · 消息队列 · 运维 · Streams · 消费组 XAUTOCLAIM Redis Streams
- Redis Streams 消费者宕机后怎么恢复:XAUTOCLAIM 接管待确认消息
- 110浏览 收藏






-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 4614次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 4240次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 4199次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 4423次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 4377次使用
-
- 详解redis集群的三种方式
- 2022-12-30 412浏览
-
- Redis集群节点通信过程/原理流程分析
- 2022-12-31 131浏览
-
- 聊一聊redis奇葩数据类型与集群知识
- 2023-02-16 499浏览
-
- Redis6.0搭建集群Redis-cluster的方法
- 2023-01-07 171浏览
-
- redis 集群批量操作实现
- 2023-01-07 433浏览


