CSV - 在 Python 中处理本地和远程文件
大家好,今天本人给大家带来文章《CSV - 在 Python 中处理本地和远程文件》,文中内容主要涉及到,如果你对文章方面的知识点感兴趣,那就请各位朋友继续看下去吧~希望能真正帮到你们,谢谢!

编码员们大家好!
本文介绍了一个开源工具,它能够处理本地和远程 csv 文件、加载和打印信息,然后将列映射到 django 类型。当数据集变大、excel不支持自定义报告或通过数据表进行完整数据操作时,通常需要处理csv文件,并且需要api。
当前的功能列表可以进一步扩展,以将 csv 文件映射到数据库表/模型并完全生成仪表板 web 应用程序。
源代码:appseed 服务的 csv 处理器部分(开源)
在开始讲解代码和用法之前,我们先总结一下工具的特点:
- 加载本地和远程文件
- 打印值
- 打印检测到的列类型
- 将映射类型打印到 django 模型
按照 readme 中的说明克隆项目源并使其可用后,可以通过 cli 执行 csv 解析器。安装完成后,我们可以使用以下一行代码调用 cvs 处理器:
$ python manage.py tool_inspect_source -f media/tool_inspect/csv_inspect.json
该工具执行以下任务:
- 验证输入
- 找到 csv 文件(如果找不到则错误退出)
- 加载信息并检测列类型
- 检测 django 列类型
- 打印前 10 行
同样可以应用于本地和远程文件。例如,我们可以通过运行这个单行代码来分析臭名昭著的 titanic.cvs:
$ python manage.py tool_inspect_source -f media/tool_inspect/csv_inspect_distant.json
# output
> processing .\media\tool_inspect\csv_inspect_distant.json
|-- file: https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv
|-- type: csv
field csv type django types
----------- ---------- ------------------------------------------
passengerid int64 models.integerfield(blank=true, null=true)
survived int64 models.integerfield(blank=true, null=true)
pclass int64 models.integerfield(blank=true, null=true)
name object models.textfield(blank=true, null=true)
sex object models.textfield(blank=true, null=true)
age float64 models.floatfield(blank=true, null=true)
sibsp int64 models.integerfield(blank=true, null=true)
parch int64 models.integerfield(blank=true, null=true)
ticket object models.textfield(blank=true, null=true)
fare float64 models.floatfield(blank=true, null=true)
cabin object models.textfield(blank=true, null=true)
embarked object models.textfield(blank=true, null=true)
[1] - passengerid,survived,pclass,name,sex,age,sibsp,parch,ticket,fare,cabin,embarked
[2] - 1,0,3,"braund, mr. owen harris",male,22,1,0,a/5 21171,7.25,,s
[3] - 2,1,1,"cumings, mrs. john bradley (florence briggs thayer)",female,38,1,0,pc 17599,71.2833,c85,c
[4] - 3,1,3,"heikkinen, miss. laina",female,26,0,0,ston/o2. 3101282,7.925,,s
[5] - 4,1,1,"futrelle, mrs. jacques heath (lily may peel)",female,35,1,0,113803,53.1,c123,s
[6] - 5,0,3,"allen, mr. william henry",male,35,0,0,373450,8.05,,s
[7] - 6,0,3,"moran, mr. james",male,,0,0,330877,8.4583,,q
[8] - 7,0,1,"mccarthy, mr. timothy j",male,54,0,0,17463,51.8625,e46,s
[9] - 8,0,3,"palsson, master. gosta leonard",male,2,3,1,349909,21.075,,s
[10] - 9,1,3,"johnson, mrs. oscar w (elisabeth vilhelmina berg)",female,27,0,2,347742,11.1333,,s
... (truncated output)
以下是该工具的相关部分:
加载信息并事先检查源是本地还是远程
print( '> processing ' + arg_json )
print( ' |-- file: ' + json_data['source'] )
print( ' |-- type: ' + json_data['type' ] )
print( '\n')
tmp_file_path = none
if 'http' in json_data['source']:
url = json_data['source']
r = requests.get(url)
tmp_file = h_random_ascii( 8 ) + '.csv'
tmp_file_path = os.path.join( dir_tmp, tmp_file )
if not file_write(tmp_file_path, r.text ):
return
json_data['source'] = tmp_file_path
else:
if not file_exists( json_data['source'] ):
print( ' > err loading source: ' + json_data['source'] )
return
csv_types = parse_csv( json_data['source'] )
分析标头并将检测到的类型映射到 django 类型。
对于表格视图,使用 tabulate library:
csv_types = parse_csv( json_data['source'] )
#pprint.pp ( csv_types )
table_headers = ['field', 'csv type', 'django types']
table_rows = []
for t in csv_types:
t_type = csv_types[t]['type']
t_type_django = django_fields[ t_type ]
table_rows.append( [t, t_type, t_type_django] )
print(tabulate(table_rows, table_headers))
最后一步是打印csv数据:
csv_data = load_csv_data( json_data['source'] )
idx = 0
for l in csv_data:
idx += 1
print( '['+str(idx)+'] - ' + str(l) )
# truncate output ..
if idx == 10:
print( ' ... (truncated output) ' )
break
此时,代码为我们提供了获取 csv 信息、数据类型以及 django 对应的数据类型的权限。该映射可以轻松扩展为任何框架,如 flask、express 或 nextjs。
django 的类型映射是这样的:
# Pandas Type
django_fields = {
'int' : 'models.IntegerField(blank=True, null=True)',
'integer' : 'models.IntegerField(blank=True, null=True)',
'string' : "models.TextField(blank=True, null=True)",
'string_unique' : "models.TextField(blank=True, null=False, unique=True)",
'object' : "models.TextField(blank=True, null=True)",
'object_unique' : "models.TextField(blank=True, null=False, unique=True)",
'int64' : 'models.IntegerField(blank=True, null=True)',
'float64' : 'models.FloatField(blank=True, null=True)',
'bool' : 'models.BooleanField(null=True)',
}
此工具正在积极开发中,以下是后续步骤:
- 将该工具连接到更多数据源,例如远程/本地数据库(sqlite、mysql、pgsql)、json
- 为任何框架生成模型:fastapi、flask、express、nextjs
- 在顶部生成安全的 api
- 使用 tailwind/bootstrap 生成服务器端分页数据表进行样式化
感谢您的阅读!
对于那些有兴趣做出贡献的人,请随时加入新的 appseed 平台并在 discord 上与社区联系:
- appseed - 面向开发者的开源平台
- appseed 社区 - 3k+ discord 成员
好了,本文到此结束,带大家了解了《CSV - 在 Python 中处理本地和远程文件》,希望本文对你有所帮助!关注golang学习网公众号,给大家分享更多文章知识!
 构建对话界面:人工智能聊天机器人和虚拟助理指南
构建对话界面:人工智能聊天机器人和虚拟助理指南
- 上一篇
- 构建对话界面:人工智能聊天机器人和虚拟助理指南

- 下一篇
- Go 功能、改进以及它们如何影响您的代码
-
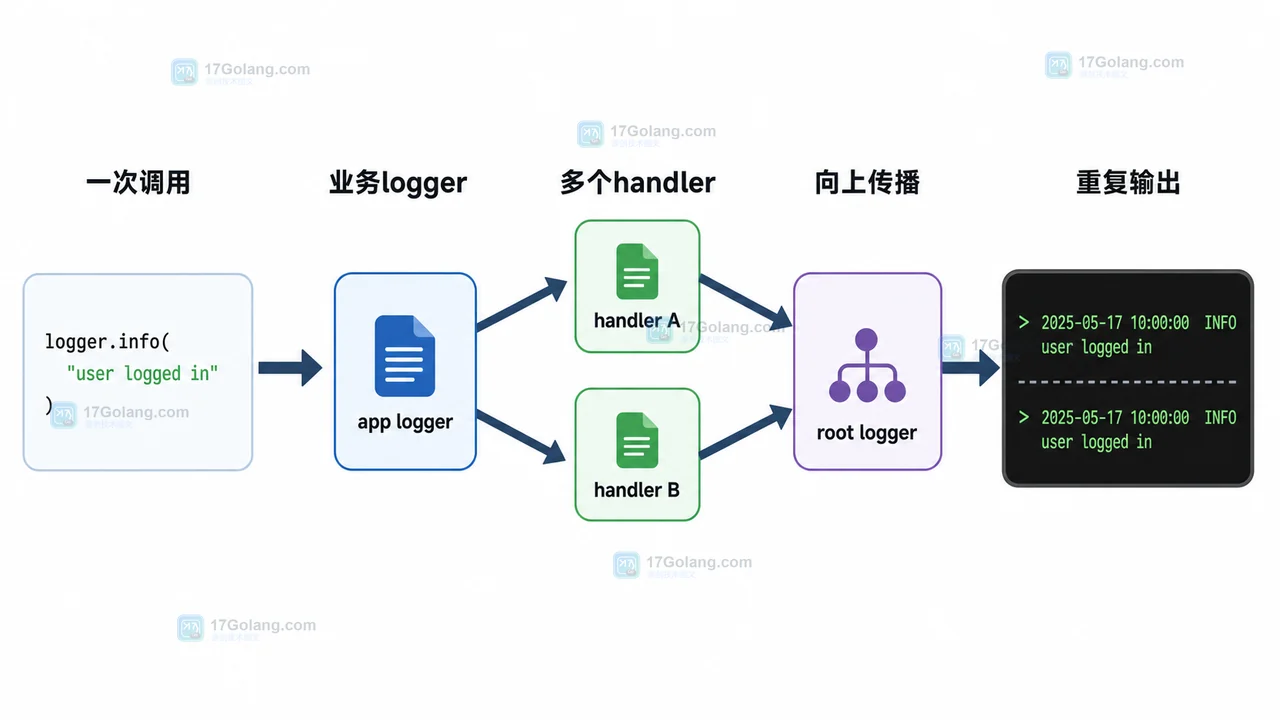
- 文章 · python教程 | 4天前 | logging · Python教程 · 后端开发 · 日志排查 · Python logging 日志重复 propagate addHandler basicConfig
- Python logging 日志重复打印排查:为什么一条记录输出了两遍
- 324浏览 收藏
-

- 文章 · python教程 | 2星期前 | 默认值 · python · 数据建模 · dataclass · default_factory · field · Python 数据类 Field 可变默认值 dataclass default_factory
- Python dataclass 默认值完整工作流:从可变默认值到 default_factory
- 228浏览 收藏


-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 3328次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 3079次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 3026次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 3237次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 3191次使用
-
- Python监控网页状态:requests异常处理实战
- 2026-05-29 501浏览
-
- TensorFlow模型部署为API的TF Serving方法
- 2026-05-26 501浏览
-
- Python字符串编码转换:encode与decode详解
- 2026-05-16 501浏览
-
- TensorFlow裁剪无用算子方法详解
- 2026-05-15 501浏览
-
- httpx 如何设置代理认证(Proxy-Authorization)
- 2026-05-05 501浏览


