“警惕时间复杂度陷阱”
大家好,我们又见面了啊~本文《“警惕时间复杂度陷阱”》的内容中将会涉及到等等。如果你正在学习文章相关知识,欢迎关注我,以后会给大家带来更多文章相关文章,希望我们能一起进步!下面就开始本文的正式内容~

警惕时间复杂度陷阱
写在这里
一个bilibili视频也展示了这个:[bilibili视频][https://www.bilibili.com/video/bv16u4m1c7cu/?spm_id_from=333.999.0.0] 我觉得这是一个很好的视频,但它的语言是中文。
时间复杂度
- 时间复杂度是什么意思?
时间复杂度是算法运行所需时间的度量,作为其输入大小的函数。它是描述算法效率的一种方式,用于比较不同的算法并确定哪种算法最有效。
如何计算时间复杂度?
为了计算时间复杂度,我们需要将算法执行的操作数视为输入大小的函数。测量操作次数的最常见方法是计算特定操作执行的次数。
计算时间复杂度时有哪些常见陷阱?
- 不考虑输入大小:如果我们只考虑算法执行的操作数量,我们可能会低估时间复杂度。例如,如果我们计算循环运行的次数,但不考虑输入的大小,那么时间复杂度可能会太高。
- 不考虑算法的效率:有些算法即使输入量很小也可能会执行很多操作,这会导致时间复杂度很高。例如,冒泡排序和选择排序等排序算法具有二次时间复杂度,即使它们可能只需要交换小数组中的两个元素。
- 不考虑算法的最坏情况:某些算法具有最好情况,其中执行的操作比最坏情况要少。例如,像二分搜索这样的搜索算法有一个最好的情况,即它们在对数时间内找到目标元素,但它们有一个最坏的情况,即它们需要检查数组中的所有元素。
让我们看一些时间复杂度的例子
这里有一个问题:
找出列表中最多 10 个整数。
import random ls = [random.randint(1, 100) for _ in range(n)]
这是测试功能:
import time
def benchmark(func, *args) -> float:
start = time.perf_counter()
func(*args)
end = time.perf_counter()
return end - start
解决方案1:使用堆
这是使用 heapq 模块的解决方案:
def find_max_n(ls, n):
import heapq
return heapq.nlargest(n, ls)
或者我们用python的方式来写:
def find_largest_n(nums, n):
if n <= 0:
return []
max_heap = []
for num in nums:
if len(max_heap) < n:
max_heap.append(num)
# call sift_down
for i in range((len(max_heap) - 2) // 2, -1, -1):
_sift_down(max_heap, i)
elif num > max_heap[0]:
max_heap[0] = num
_sift_down(max_heap, 0)
return max_heap
def _sift_down(heap, index):
left = 2 * index + 1
right = 2 * index + 2
largest = index
if left < len(heap) and heap[left] > heap[largest]:
largest = left
if right < len(heap) and heap[right] > heap[largest]:
largest = right
if largest != index:
heap[index], heap[largest] = heap[largest], heap[index]
_sift_down(heap, largest)
解决方案2:使用排序
这是使用排序功能的解决方案:
def find_max_n(ls, n):
return sorted(ls, reverse=true)[:n]
几乎所有人都知道,堆的时间复杂度是 o(n log k),排序函数的时间复杂度是 o(n log n)。
看来第一个解决方案比第二个更好。但在python中却不是这样。
看最终代码:
import time
def benchmark(func, *args) -> float:
start = time.perf_counter()
func(*args)
end = time.perf_counter()
return end - start
def find_max_n_heapq(ls, n):
import heapq
return heapq.nlargest(n, ls)
def find_max_n_python_heap(nums, n):
if n <= 0:
return []
max_heap = []
for num in nums:
if len(max_heap) < n:
max_heap.append(num)
# call sift_down
for i in range((len(max_heap) - 2) // 2, -1, -1):
_sift_down(max_heap, i)
elif num > max_heap[0]:
max_heap[0] = num
_sift_down(max_heap, 0)
return max_heap
def _sift_down(heap, index):
left = 2 * index + 1
right = 2 * index + 2
largest = index
if left < len(heap) and heap[left] > heap[largest]:
largest = left
if right < len(heap) and heap[right] > heap[largest]:
largest = right
if largest != index:
heap[index], heap[largest] = heap[largest], heap[index]
_sift_down(heap, largest)
def find_max_n_sorted(ls, n):
return sorted(ls, reverse=True)[:n]
# test
import random
for n in range(10, 10000, 100):
ls = [random.randint(1, 100) for _ in range(n)]
print(f"n = {n}")
print(f"Use Heapq: {benchmark(find_max_n_heapq, ls, n)}")
print(f"Python Heapq: {benchmark(find_max_n_python_heap, ls, n)}")
print(f"Sorted : {benchmark(find_max_n_sorted, ls, n)}")
我在python3.11 vscode中运行,结果如下:
n 不大
使用heapq:0.002430099993944168
python 堆:0.06343129999004304
排序:9.280000813305378e-05
n = 910
使用堆:9.220000356435776e-05
python 堆:0.07715500006452203
排序:9.360001422464848e-05
n = 920
使用堆:9.440002031624317e-05
python 堆:0.06573969998862594
排序:0.00012450001668184996
n = 930
使用堆:9.689992293715477e-05
python 堆:0.06760239996947348
排序:9.66999214142561e-05
n = 940
使用堆:9.600003249943256e-05
python 堆:0.07372559991199523
排序:9.680003859102726e-05
n = 950
使用堆:9.770004544407129e-05
python 堆:0.07306570000946522
排序:0.00011979998089373112
n = 960
使用堆:9.980006143450737e-05
python 堆:0.0771204000338912
排序:0.00022829999215900898
n = 970
使用堆:0.0001601999392732978
python 堆:0.07493270002305508
排序:0.00010840001050382853
n = 980
使用堆:9.949994273483753e-05
python 堆:0.07698320003692061
排序:0.00010300008580088615
n = 990
使用堆:9.979994501918554e-05
python 堆:0.0848745999392122
排序:0.00012620002962648869
如果n很大?
n = 10000
使用堆:0.003642000025138259
python 堆:9.698883199947886
排序:0.00107999995816499
n = 11000
使用heapq:0.0014836000045761466
python 堆:10.537632800056599
排序:0.0012236000038683414
n = 12000
使用heapq:0.001384599949233234
python 堆:12.328411899972707
排序:0.0013226999435573816
n = 13000
使用heapq:0.0020017001079395413
python 堆:15.637207800056785
排序:0.0015075999544933438
n = 14000
使用heapq:0.0017026999266818166
python 堆:17.298848500009626
排序:0.0016967999981716275
n = 15000
使用堆:0.0017773000290617347
python 堆:20.780625900020823
排序:0.0017105999868363142
我发现了什么以及如何改进它
当n很大时,sorted会花费一点时间(有时甚至比使用heapq更好),但python heapq会花费很多时间。
- 为什么sorted花费的时间很少,而python heapq花费的时间却很多?
- 因为sorted()是python中的内置函数,你可以找到关于它的python官方文档。
bulit-in 函数比 heapq 更快,因为它是用 c 编写的,c 是一种编译语言。
- 如何改善?
- 您可以使用内置函数sorted()代替heapq.sort()来提高代码的性能。 sorted() 函数是 python 中的内置函数,它是用 c 实现的,因此比 heapq.sort() 快得多
脑震荡
当我们处理大数据时,我们应该使用内置函数而不是 heapq.sort() 来提高代码的性能。在处理大数据时,我们必须警惕时间复杂度陷阱。有时时间复杂度陷阱是不可避免的,但我们应该尽量避免它们。
关于我
大家好,我是梦沁园。我是一名学生。我喜欢学习新事物。
你可以看我的github:[mengqinyuan的github][https://github.com/mengqinyuan]
今天关于《“警惕时间复杂度陷阱”》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于的内容请关注golang学习网公众号!
 数学在机器学习中的重要性:初学者的观点
数学在机器学习中的重要性:初学者的观点
- 上一篇
- 数学在机器学习中的重要性:初学者的观点

- 下一篇
- PHP框架选型全攻略,为项目保驾护航
-
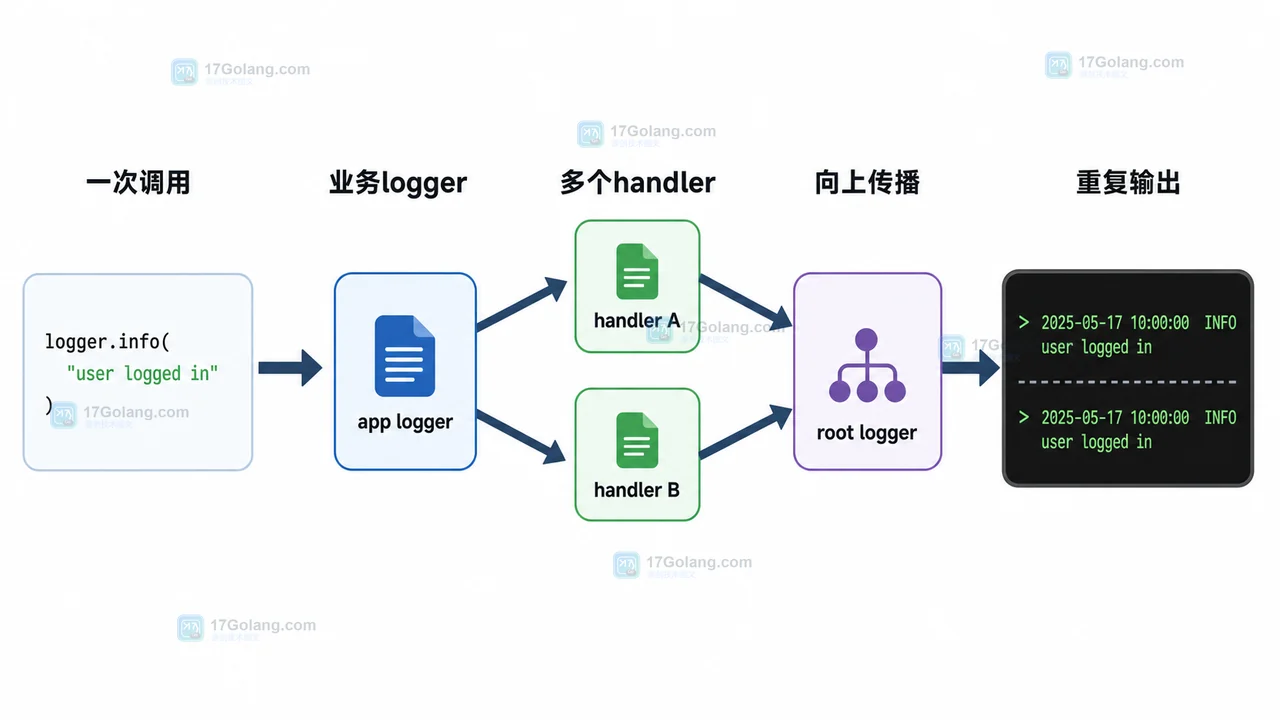
- 文章 · python教程 | 1星期前 | logging · Python教程 · 后端开发 · 日志排查 · Python logging 日志重复 propagate addHandler basicConfig
- Python logging 日志重复打印排查:为什么一条记录输出了两遍
- 324浏览 收藏
-

- 文章 · python教程 | 2星期前 | 默认值 · python · 数据建模 · dataclass · default_factory · field · Python 数据类 Field 可变默认值 dataclass default_factory
- Python dataclass 默认值完整工作流:从可变默认值到 default_factory
- 228浏览 收藏


-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 3861次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 3565次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 3553次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 3734次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 3696次使用
-
- Python监控网页状态:requests异常处理实战
- 2026-05-29 501浏览
-
- TensorFlow模型部署为API的TF Serving方法
- 2026-05-26 501浏览
-
- Python字符串编码转换:encode与decode详解
- 2026-05-16 501浏览
-
- TensorFlow裁剪无用算子方法详解
- 2026-05-15 501浏览
-
- httpx 如何设置代理认证(Proxy-Authorization)
- 2026-05-05 501浏览


