MySQL索引介绍及优化方式
知识点掌握了,还需要不断练习才能熟练运用。下面golang学习网给大家带来一个数据库开发实战,手把手教大家学习《MySQL索引介绍及优化方式》,在实现功能的过程中也带大家重新温习相关知识点,温故而知新,回头看看说不定又有不一样的感悟!
一、导致sql执行慢的原因
硬件条件限制:
- io吞吐量小,形成瓶颈(读取磁盘数据)
- 网络传输速度慢
- 内存不足(读取磁盘数据加载到内存)
程序设计方面:
没有索引或未使用到索引表数据量过大(可采用分批查询,减少单次查询数据量)返回不必要的行/列锁/死锁(例如:给表新增字段导致锁表,此时执行sql语句会被阻塞,直至表解锁)
二、分析原因时,一定要找切入点
- 1.通过慢查询日志,设置相应的阈值(比如超过3s就是慢sql),在生产环境跑一天后,看看有哪些sql执行比较慢。
- 2.Explain分析:比如sql语句写的烂,没索引或索引失效,关联查询过多(可能是需求设计缺陷导致)。
- 3.Show Profile是比Explain更近一步的执行细节,可以查询到执行每一个SQL都干了什么事,这些事分别花了多少秒。
慢查询日志:MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值(long_query_time,单位:秒)的SQL语句。参考mysql慢查询日志轮转_MySQL慢查询日志实操
三、什么是索引?
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。我们可以简单理解为:快速查找排好序的一种数据结构(好比一本书的目录)。Mysql索引主要有两种结构:B+Tree索引和Hash索引。我们平常所说的索引,如果没有特别指明,一般都是指B树结构组织的索引(B+Tree索引)。索引如图所示:
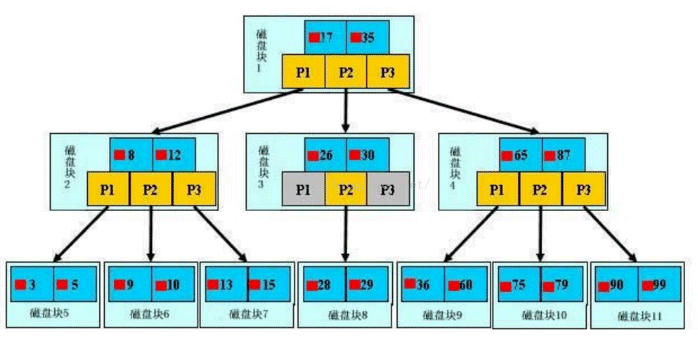
最外层浅蓝色磁盘块1里有数据17、35(深蓝色)和指针P1、P2、P3(黄色)。P1指针表示小于17的磁盘块,P2是在17-35之间,P3指向大于35的磁盘块。真实数据存在于叶子节点也就是最底下的一层3、5、9、10、13......非叶子节点不存储真实的数据,只存储指引搜索方向的数据项,如17、35。
查找过程:例如搜索28数据项,首先加载磁盘块1到内存中,发生一次I/O,用二分查找确定在P2指针。接着发现28在26和30之间,通过P2指针的地址加载磁盘块3到内存,发生第二次I/O。用同样的方式找到磁盘块8,发生第三次I/O。
真实的情况是,上面3层的B+Tree可以表示上百万的数据,上百万的数据只发生了三次I/O而不是上百万次I/O,时间提升是巨大的。
四、Explain分析
前文铺垫完成,进入实操部分,先来插入测试需要的数据:
CREATE TABLE `user_info` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(50) NOT NULL DEFAULT '',
`age` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name_index` (`name`)
)ENGINE = InnoDB DEFAULT CHARSET = utf8;
INSERT INTO user_info (name, age) VALUES ('xys', 20);
INSERT INTO user_info (name, age) VALUES ('a', 21);
INSERT INTO user_info (name, age) VALUES ('b', 23);
INSERT INTO user_info (name, age) VALUES ('c', 50);
INSERT INTO user_info (name, age) VALUES ('d', 15);
INSERT INTO user_info (name, age) VALUES ('e', 20);
INSERT INTO user_info (name, age) VALUES ('f', 21);
INSERT INTO user_info (name, age) VALUES ('g', 23);
INSERT INTO user_info (name, age) VALUES ('h', 50);
INSERT INTO user_info (name, age) VALUES ('i', 15);
CREATE TABLE `order_info` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`user_id` BIGINT(20) DEFAULT NULL,
`product_name` VARCHAR(50) NOT NULL DEFAULT '',
`productor` VARCHAR(30) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `user_product_detail_index` (`user_id`, `product_name`, `productor`)
)ENGINE = InnoDB DEFAULT CHARSET = utf8;
INSERT INTO order_info (user_id, product_name, productor) VALUES (1, 'p1', 'WHH');
INSERT INTO order_info (user_id, product_name, productor) VALUES (1, 'p2', 'WL');
INSERT INTO order_info (user_id, product_name, productor) VALUES (1, 'p1', 'DX');
INSERT INTO order_info (user_id, product_name, productor) VALUES (2, 'p1', 'WHH');
INSERT INTO order_info (user_id, product_name, productor) VALUES (2, 'p5', 'WL');
INSERT INTO order_info (user_id, product_name, productor) VALUES (3, 'p3', 'MA');
INSERT INTO order_info (user_id, product_name, productor) VALUES (4, 'p1', 'WHH');
INSERT INTO order_info (user_id, product_name, productor) VALUES (6, 'p1', 'WHH');
INSERT INTO order_info (user_id, product_name, productor) VALUES (9, 'p8', 'TE');
初体验,执行Explain的效果:

索引使用情况在possible_keys、key和key_len三列,接下来我们先从左到右依次讲解。
1.id
--id相同,执行顺序由上而下 explain select u.*,o.* from user_info u,order_info o where u.id=o.user_id;

--id不同,值越大越先被执行 explain select * from user_info where id = (select user_id from order_info where product_name ='p8');

2.select_type
可以看id的执行实例,总共有以下几种类型:
- SIMPLE: 表示此查询不包含 UNION 查询或子查询
- PRIMARY: 表示此查询是最外层的查询
- SUBQUERY: 子查询中的第一个 SELECT
- UNION: 表示此查询是 UNION 的第二或随后的查询
- DEPENDENT UNION: UNION 中的第二个或后面的查询语句, 取决于外面的查询
- UNION RESULT, UNION 的结果
- DEPENDENT SUBQUERY: 子查询中的第一个 SELECT, 取决于外面的查询. 即子查询依赖于外层查询的结果.
- DERIVED:衍生,表示导出表的SELECT(FROM子句的子查询)
3.table
table表示查询涉及的表或衍生的表:
explain select tt.* from (select u.* from user_info u,order_info o where u.id=o.user_id and u.id=1) tt
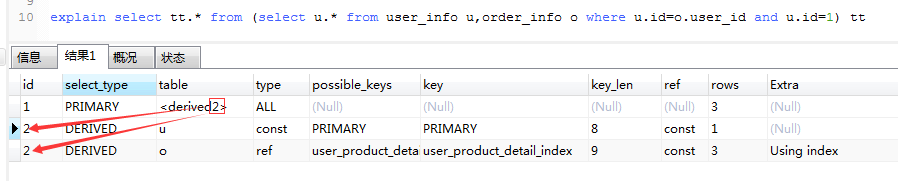
id为1的
4.type(★)
type 字段比较重要,它提供了判断查询是否高效的重要依据。通过 type 字段,我们判断此次查询是 全表扫描 还是 索引扫描 等。

type 常用的取值有:
- system: 表中只有一条数据, 这个类型是特殊的 const 类型。
- const: 针对主键或唯一索引的等值查询扫描,最多只返回一行数据。 const 查询速度非常快, 因为它仅仅读取一次即可。例如下面的这个查询,它使用了主键索引,因此 type 就是 const 类型的:explain select * from user_info where id = 2;
- eq_ref: 此类型通常出现在多表的 join 查询,表示对于前表的每一个结果,都只能匹配到后表的一行结果。并且查询的比较操作通常是 =,查询效率较高。例如:explain select * from user_info, order_info where user_info.id = order_info.user_id;
- ref: 此类型通常出现在多表的 join 查询,针对于非唯一或非主键索引,或是使用了 最左前缀 规则索引的查询。例如下面这个例子中, 就使用到了 ref 类型的查询:explain select * from user_info, order_info where user_info.id = order_info.user_id and order_info.user_id = 5;
- range: 表示使用索引范围查询,通过索引字段范围获取表中部分数据记录。这个类型通常出现在 =, , >, >=, , BETWEEN, IN() 操作中。例如下面的例子就是一个范围查询:explain select * from user_info where id between 2 and 8;
- index: 表示全索引扫描(full index scan),和 ALL 类型相比,ALL 类型是全表扫描,而 index 类型则仅仅扫描所有的索引, 而不扫描数据。index 类型通常出现在:所要查询的数据直接在索引树中就可以获取到, 而不需要回表扫描其他数据。当为这种情况时,Extra 字段会显示 Using index。
- ALL: 表示全表扫描,这个类型的查询是性能最差的查询之一。通常来说, 我们的查询不应该出现 ALL 类型的查询,因为这样的查询在数据量大的情况下,对数据库的性能是巨大的灾难。 如一个查询是 ALL 类型查询, 那么一般来说可以对相应的字段添加索引来避免。
通常来说, 不同的 type 类型的性能关系如下:
ALL
ALL 类型因为是全表扫描, 因此在相同的查询条件下,它是速度最慢的。而 index 类型的查询虽然不是全表扫描,但是它扫描了所有的索引,因此比 ALL 类型的稍快。后面的几种类型都是利用了索引来查询数据,因此可以过滤部分或大部分数据,因此查询效率就比较高了。
5.possible_key
它表示 mysql 在查询时,可能使用到的索引。 注意,即使有些索引在 possible_keys 中出现,但是并不表示此索引会真正地被 mysql 使用到。 mysql 在查询时具体使用了哪些索引,由 key 字段决定。
6.key(★)
此字段是 mysql 在当前查询时真正用到的索引。比如请客吃饭的场景,possible_keys是应到多少人,key是实到多少人。
当我们没有建立索引时:
explain select o.* from order_info o where o.product_name= 'p1' and o.productor='whh'; create index idx_name_productor on order_info(productor); drop index idx_name_productor on order_info;

建立复合索引后再查询:

7.key_len
表示查询优化器使用了索引的字节数,这个字段可以评估组合索引是否完全被使用。
8.ref(★)
这一列显示了在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量),func,NULL,字段名(例:film.id)。前文的type属性里也有ref,注意区别。

9.rows(★)
rows 也是一个重要的字段,mysql 查询优化器根据统计信息,估算 sql 要查找到结果集需要扫描读取的数据行数,这个值非常直观的显示 sql 效率好坏, 原则上 rows 越少越好。可以对比key中的例子,一个没建立索引前,rows是9,建立索引后,rows是4。
具体可参考文章:mysql or走索引加索引及慢查询的作用
10.extra

explain 中的很多额外的信息会在 extra 字段显示, 常见的有以下几种内容:
- using filesort :表示 mysql 需额外的排序操作,不能通过索引顺序达到排序效果。一般有 using filesort都建议优化去掉,因为这样的查询 cpu 资源消耗大。
- using index:索引覆盖扫描,表示查询在索引树中就可查找所需数据,不用扫描表数据文件,往往说明性能不错。
- using temporary:查询有使用临时表, 一般出现于排序, 分组和多表 join 的情况, 查询效率不高,建议优化。using where :表名使用了where过滤。
五、优化案例
explain select u.*,o.* from user_info u LEFT JOIN order_info o on u.id = o.user_id;
执行结果,type有ALL,并且没有索引:

开始优化,在关联列上创建索引,明显看到type列的ALL变成ref,并且用到了索引,rows也从扫描9行变成了1行:
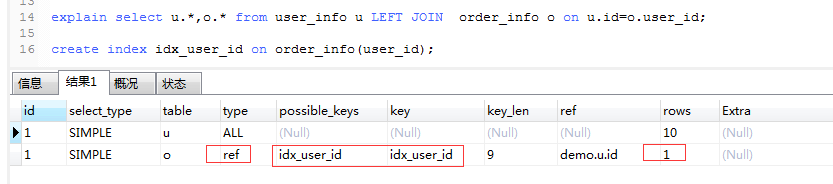
这里面一般有个规律是:左连接时,索引加在右表关联字段上(由于上述示例为LEFT JOIN,所以索引加在右表order_info上)。相反的,右连接索引加在左表关联字段上。
六、是否需要创建索引?
索引虽然能非常高效的提高查询速度,但却会降低表的更新速度。实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占用空间的。

今天带大家了解了优化、Mysql索引的相关知识,希望对你有所帮助;关于数据库的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~
 Mysql存在则修改不存在则新增的两种实现方法实例
Mysql存在则修改不存在则新增的两种实现方法实例
- 上一篇
- Mysql存在则修改不存在则新增的两种实现方法实例
- 下一篇
- mysql如何对已经加密的字段进行模糊查询详解
-

- 阔达的鞋子
- 这篇技术文章太及时了,作者大大加油!
- 2023-01-07 08:48:43
-
- 火星上的火龙果
- 这篇技术文章真及时,细节满满,很好,已收藏,关注大佬了!希望大佬能多写数据库相关的文章。
- 2023-01-05 22:35:59
-
- 野性的过客
- 细节满满,收藏了,感谢大佬的这篇技术文章,我会继续支持!
- 2023-01-04 16:16:49
-
- 悲凉的香烟
- 很好,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢大佬分享技术贴!
- 2023-01-02 06:31:05
-
- 贪玩的唇膏
- 很详细,已加入收藏夹了,感谢作者大大的这篇文章内容,我会继续支持!
- 2023-01-01 15:08:35
-
- 阔达的蓝天
- 很棒,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢up主分享博文!
- 2023-01-01 09:28:41
-
- 踏实的宝马
- 这篇技术贴太及时了,太细致了,很好,收藏了,关注作者大大了!希望作者大大能多写数据库相关的文章。
- 2023-01-01 00:16:25
-

- 数据库 · MySQL | 14小时前 | MySQL · JSON · 索引 · 数据库 · 查询优化 · 生成列 · json_extract 索引优化 列表筛选 生成列 MySQL JSON JSON索引
- MySQL JSON 字段怎么给列表筛选提速:生成列、索引与 NULL 边界
- 351浏览 收藏
-
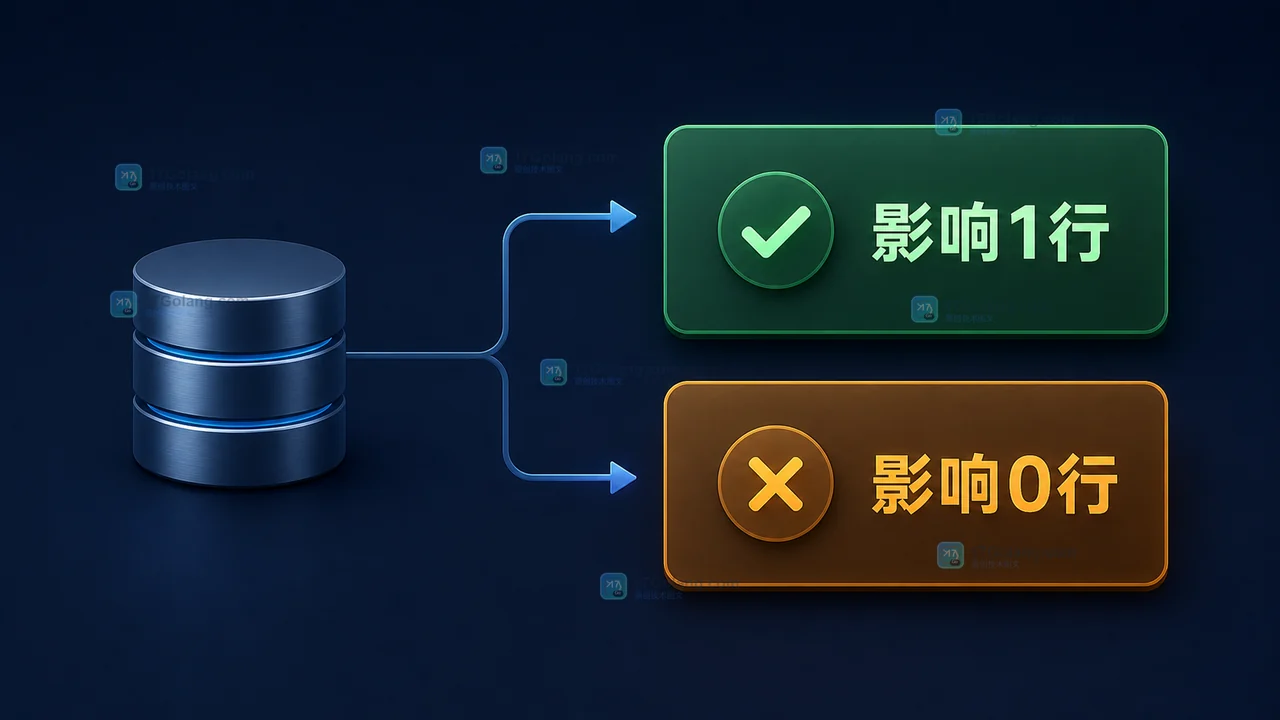
- 数据库 · MySQL | 5天前 | 并发 · MySQL · InnoDB · update · 库存扣减 · innodb MySQL 库存扣减 条件 UPDATE 防超卖 affected rows
- MySQL 库存怎么安全扣减?条件 UPDATE、防超卖和受影响行判断
- 470浏览 收藏



-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 4609次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 4240次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 4197次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 4421次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 4377次使用
-
- 分析Go错误处理优化go recover机制缺陷
- 2023-01-01 483浏览
-
- gozero微服务高在请求量下如何优化
- 2023-01-01 268浏览
-
- Go 内联优化让程序员爱不释手
- 2023-01-07 177浏览
-
- Golang中重复错误处理的优化方法
- 2023-01-07 287浏览
-
- go time.After优化后性能提升34%内存减少67%
- 2023-02-25 352浏览


