gozero微服务高在请求量下如何优化
知识点掌握了,还需要不断练习才能熟练运用。下面golang学习网给大家带来一个Golang开发实战,手把手教大家学习《gozero微服务高在请求量下如何优化》,在实现功能的过程中也带大家重新温习相关知识点,温故而知新,回头看看说不定又有不一样的感悟!
引言
前两篇文章我们介绍了缓存使用的各种最佳实践,首先介绍了缓存使用的基本姿势,分别是如何利用go-zero自动生成的缓存和逻辑代码中缓存代码如何写,接着讲解了在面对缓存的穿透、击穿、雪崩等常见问题时的解决方案,最后还重点讲解了如何保证缓存的一致性。
因为缓存对于高并发服务来说实在是太重要了,所以这篇文章我们还会继续一起学习下缓存相关的知识。
本地缓存
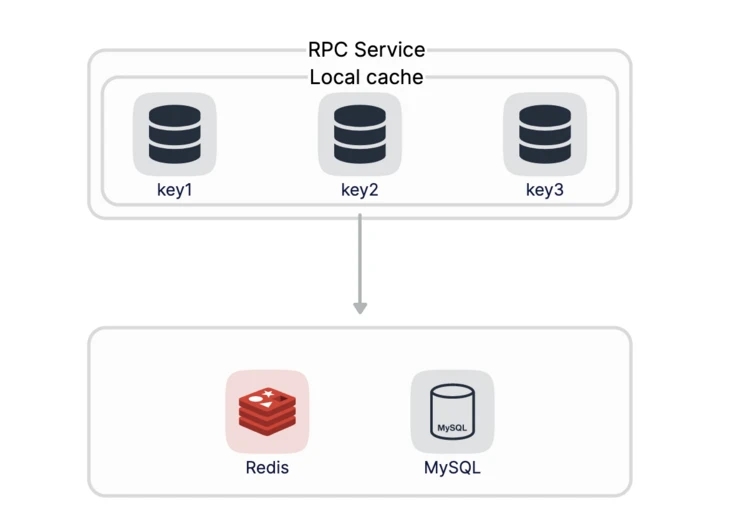
当我们遇到极端热点数据查询的时候,这个时候就要考虑本地缓存了。热点本地缓存主要部署在应用服务器的代码中,用于阻挡热点查询对于Redis等分布式缓存或者数据库的压力。
在我们的商城中,首页Banner中会放一些广告商品或者推荐商品,这些商品的信息由运营在管理后台录入和变更。这些商品的请求量非常大,即使是Redis也很难扛住,所以这里我们可以使用本地缓存来进行优化。
在product库中先建一张商品运营表product_operation,为了简化只保留必要字段,product_id为推广运营的商品id,status为运营商品的状态,status为1的时候会在首页Banner中展示该商品。
CREATE TABLE `product_operation` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT, `product_id` bigint unsigned NOT NULL DEFAULT 0 COMMENT '商品id', `status` int NOT NULL DEFAULT '1' COMMENT '运营商品状态 0-下线 1-上线', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (`id`), KEY `ix_update_time` (`update_time`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品运营表';
本地缓存的实现比较简单,我们可以使用map来自己实现,在go-zero的collection中提供了Cache来实现本地缓存的功能,我们直接拿来用,重复造轮子从来不是一个明智的选择,localCacheExpire为本地缓存过期时间,Cache提供了Get和Set方法,使用非常简单
localCache, err := collection.NewCache(localCacheExpire)
先从本地缓存中查找,如果命中缓存则直接返回。没有命中缓存的话需要先从数据库中查询运营位商品id,然后再聚合商品信息,最后回塞到本地缓存中。详细代码逻辑如下:
func (l *OperationProductsLogic) OperationProducts(in *product.OperationProductsRequest) (*product.OperationProductsResponse, error) {
opProducts, ok := l.svcCtx.LocalCache.Get(operationProductsKey)
if ok {
return &product.OperationProductsResponse{Products: opProducts.([]*product.ProductItem)}, nil
}
pos, err := l.svcCtx.OperationModel.OperationProducts(l.ctx, validStatus)
if err != nil {
return nil, err
}
var pids []int64
for _, p := range pos {
pids = append(pids, p.ProductId)
}
products, err := l.productListLogic.productsByIds(l.ctx, pids)
if err != nil {
return nil, err
}
var pItems []*product.ProductItem
for _, p := range products {
pItems = append(pItems, &product.ProductItem{
ProductId: p.Id,
Name: p.Name,
})
}
l.svcCtx.LocalCache.Set(operationProductsKey, pItems)
return &product.OperationProductsResponse{Products: pItems}, nil
}
使用grpurl调试工具请求接口,第一次请求cache miss后,后面的请求都会命中本地缓存,等到本地缓存过期后又会重新回源db加载数据到本地缓存中
~ grpcurl -plaintext -d '{}' 127.0.0.1:8081 product.Product.OperationProducts
{
"products": [
{
"productId": "32",
"name": "电风扇6"
},
{
"productId": "31",
"name": "电风扇5"
},
{
"productId": "33",
"name": "电风扇7"
}
]
}
注意,并不是所有信息都适用于本地缓存,本地缓存的特点是请求量超高,同时业务上能够允许一定的不一致,因为本地缓存一般不会主动做更新操作,需要等到过期后重新回源db后再更新。所以在业务中要视情况而定看是否需要使用本地缓存。
自动识别热点数据
首页Banner场景是由运营人员来配置的,也就是我们能提前知道可能产生的热点数据,但有些情况我们是不能提前预知数据会成为热点的。
所以就需要我们能自适应地自动的识别这些热点数据,然后把这些数据提升为本地缓存。
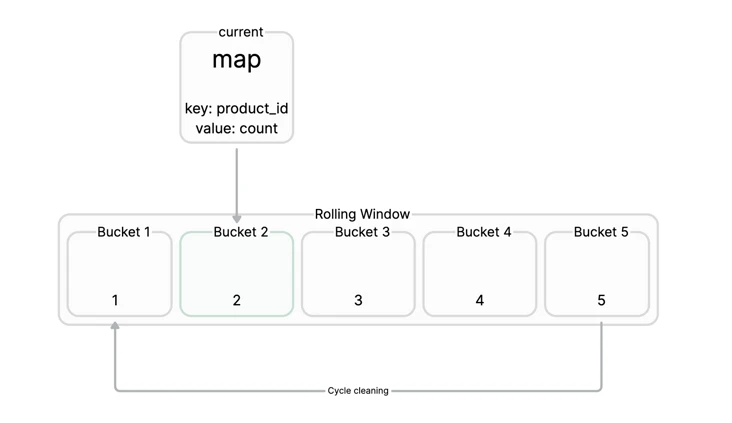
我们维护一个滑动窗口,比如滑动窗口设置为10s,就是要统计这10s内有哪些key被高频访问,一个滑动窗口中对应多个Bucket,每个Bucket中对应一个map,map的key为商品的id,value为商品对应的请求次数。
接着我们可以定时的(比如10s)去统计当前所有Buckets中的key的数据,然后把这些数据导入到大顶堆中,轻而易举的可以从大顶堆中获取topK的key,我们可以设置一个阈值,比如在一个滑动窗口时间内某一个key访问频次超过500次,就认为该key为热点key,从而自动地把该key升级为本地缓存。
缓存使用技巧
下面介绍一些缓存使用的小技巧
- key的命名要尽量易读,即见名知意,在易读的前提下长度要尽可能的小,以减少资源的占用,对于value来说可以用int就尽量不要用string,对于小于N的value,redis内部有shared_object缓存。
- 在redis使用hash的情况下进行key的拆分,同一个hash key会落到同一个redis节点,hash过大的情况下会导致内存以及请求分布的不均匀,考虑对hash进行拆分为小的hash,使得节点内存均匀避免单节点请求热点。
- 为了避免不存在的数据请求,导致每次请求都缓存miss直接打到数据库中,进行空缓存的设置。
- 缓存中需要存对象的时候,序列化尽量使用protobuf,尽可能减少数据大小。
- 新增数据的时候要保证缓存务必存在的情况下再去操作新增,使用Expire来判断缓存是否存在。
- 对于存储每日登录场景的需求,可以使用BITSET,为了避免单个BITSET过大或者热点,可以进行sharding。
- 在使用sorted set的时候,避免使用zrange或者zrevrange返回过大的集合,复杂度较高。
- 在进行缓存操作的时候尽量使用PIPELINE,但也要注意避免集合过大。
- 避免超大的value。
- 缓存尽量要设置过期时间。
- 慎用全量操作命令,比如Hash类型的HGETALL、Set类型的SMEMBERS等,这些操作会对Hash和Set的底层数据结构进行全量扫描,如果数据量较多的话,会阻塞Redis主线程。
- 获取集合类型的全量数据可以使用SSCAN、HSCAN等命令分批返回集合中的数据,减少对主线程的阻塞。
- 慎用MONITOR命令,MONITOR命令会把监控到的内容持续写入输出缓冲区,如果线上命令操作很多,输出缓冲区很快就会溢出,会对Redis性能造成影响。
- 生产环境禁用KEYS、FLUSHALL、FLUSHDB等命令。
结束语
已知的热点缓存比较简单,从数据库中提前加载到内存中即可,未知的热点缓存我们需要自适应的识别出热点的数据,然后把这些热点的数据升级为本地缓存。最后介绍了一些实际生产中缓存使用的一些小技巧,在生产环境中要活灵活用尽量避免问题的产生。
代码仓库: https://github.com/zhoushuguang/lebron
项目地址: https://github.com/zeromicro/go-zero
本篇文章介绍了如何使用本地热点缓存应对超高的请求,热点缓存又分为已知的热点缓存和未知的热点缓存,希望大家以后多多支持golang学习网!
好了,本文到此结束,带大家了解了《gozero微服务高在请求量下如何优化》,希望本文对你有所帮助!关注golang学习网公众号,给大家分享更多Golang知识!
 Go读写锁操作方法示例详解
Go读写锁操作方法示例详解
- 上一篇
- Go读写锁操作方法示例详解
- 下一篇
- go zero微服务实战处理每秒上万次的下单请求
-

- 开朗的海燕
- 太细致了,mark,感谢博主的这篇博文,我会继续支持!
- 2023-01-03 12:40:37
-
- 微笑的冬日
- 这篇博文真及时,太详细了,真优秀,已收藏,关注作者大大了!希望作者大大能多写Golang相关的文章。
- 2023-01-03 06:19:40
-
- 直率的面包
- 真优秀,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢博主分享技术贴!
- 2023-01-02 19:42:51
-
- Golang · Go教程 | 11小时前 | https · cors · chrome · Go教程 · Local Network Access · 内网接口 · 浏览器权限 Go CORS Go 内网接口 Chrome 142 Local Network Access targetAddressSpace
- Go 内网管理接口为什么在 Chrome 142 打不开:Local Network Access、HTTPS 与 CORS 排查
- 152浏览 收藏
-
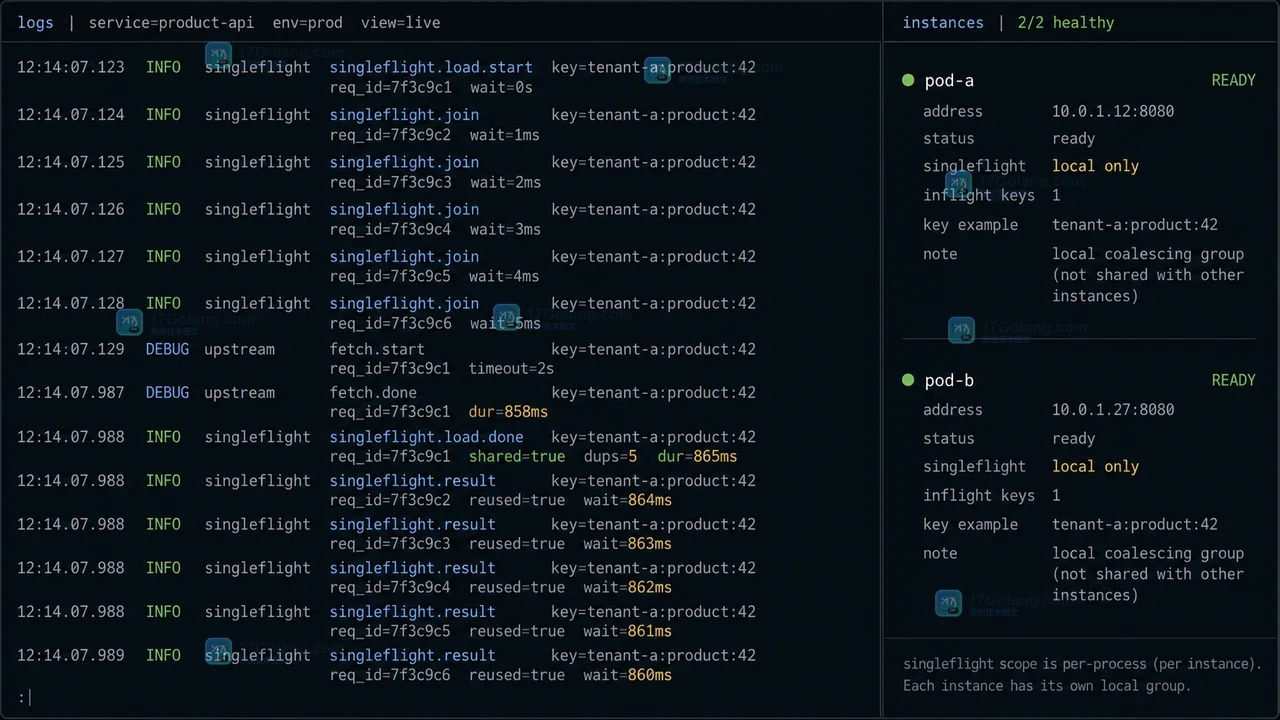
- Golang · Go教程 | 1天前 | golang · 缓存 · singleflight · go · 高并发 · 后端开发 · Go 并发控制 缓存失效 请求合并 singleflight 回源
- Go singleflight 怎么合并同一请求:缓存失效时别让 500 个请求一起回源
- 109浏览 收藏
-

- Golang · Go教程 | 1天前 | [] · []
- Go 项目 GitHub Actions 怎么设质量门禁:go vet、go test 与构建分阶段拦截
- 485浏览 收藏
-

- Golang · Go教程 | 1天前 | [] · []
- Go html/template 怎么安全把后端数据交给前端:别把 JSON 硬塞进 template.JS
- 177浏览 收藏
-

- Golang · Go教程 | 1天前 | 前端开发 · Go教程 · html/template · 网页模板 · 导航 · Go html/template CurrentPath 导航高亮 template.FuncMap Go网页模板
- Go html/template 怎么高亮当前导航:传入 CurrentPath 的最小写法
- 409浏览 收藏
-
![Go 拼接字符串怎么选:strings.Builder、bytes.Buffer 和 []byte 的边界](/uploads/20260716/1784195965-01-builder-timeline.webp)
- Golang · Go教程 | 2天前 | 标准库 · 基准测试 · Go教程 · 字符串拼接 · Go 字符串拼接 strings.Builder bytes.Buffer []byte
- Go 拼接字符串怎么选:strings.Builder、bytes.Buffer 和 []byte 的边界
- 188浏览 收藏
-

- Golang · Go教程 | 2天前 | golang · Timer · 并发编程 · time.After · 性能排查 · time.After go timer Go 1.23 NewTimer Timer.Reset Timer.Stop
- Go 1.23 以后还要手动 Stop Timer 吗:一次超时循环改造实战
- 403浏览 收藏
-
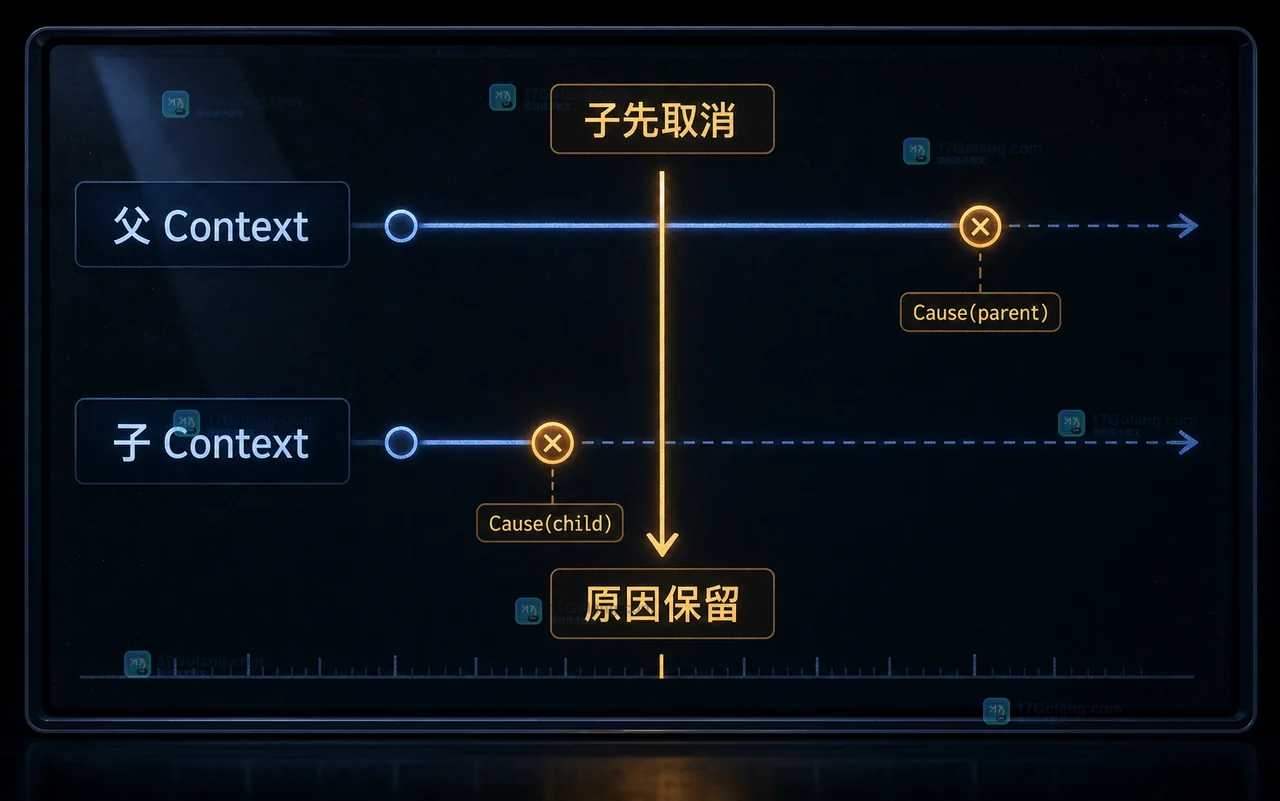
- Golang · Go教程 | 2天前 | 并发 · 错误处理 · go · Context · 排错 · Go 错误链 context.WithCancelCause context.Cause 取消原因
- Go context.WithCancelCause 怎么用:让中断原因能被日志和调用方看见
- 366浏览 收藏



-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 4554次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 4214次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 4175次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 4396次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 4344次使用
-
- Go微服务开发框架DMicro设计思路详解
- 2023-01-01 354浏览
-
- gozero微服务框架logx日志组件剖析
- 2022-12-24 314浏览
-
- 关于go-zero单体服务使用泛型简化注册Handler路由的问题
- 2022-12-30 346浏览
-
- go zero微服务实战性能优化极致秒杀
- 2022-12-27 207浏览
-
- 分析Go错误处理优化go recover机制缺陷
- 2023-01-01 483浏览


