go如何删除字符串中的部分字符
在Golang实战开发的过程中,我们经常会遇到一些这样那样的问题,然后要卡好半天,等问题解决了才发现原来一些细节知识点还是没有掌握好。今天golang学习网就整理分享《go如何删除字符串中的部分字符》,聊聊字符串、go删除,希望可以帮助到正在努力赚钱的你。
go,在删除切片中的元素时,可以使用append(),方式将其中的元素删除。
slice :=make([]int , 0) slice = append(slice[:k],slice[k+1:]) //此方法就是删除切片中位于k中的元素
由于字符串也可以进行遍历,但是字符串不可以进行切片操作,也就是只有切片才能使用append()操作

所以如果要在字符串中删除某一个字符。
str :="teststring" str = str[:5]+str[6:]//与其他语言相似,在进行切割时,没有包括前面的索引,但是不包括后面的索引 //str = testsring
补充:Go 字符串处理
直接使用“+”:
示例:
a := "aa" b := "bb" a = a + b fmt.Println(a)
因为字符串类型在Go中是不可改变的,因此每次操作实际都要新分配字符串,所以在字符串比较多的时候效率不高。
使用strings.Join()函数
示例:
var s []string for i := 0; i这种方式需要花费构建slice的时间。
使用bytes.Buffer:
示例:
package main import ( "bytes" "fmt" "strconv" ) func main() { var buffer bytes.Buffer for i := 0; i这种在字符串比较多的时候效率最高。
字符串截取
不含中文
s := "abcdefg" s = string([]byte(s)[1:3]) fmt.Println(s) 结果 bc含中文
s := "a你好cd" s = string([]rune(s)[:3]) fmt.Println(s) 结果 a你好在golang中可以通过切片截取一个数组或字符串,但是当截取的字符串是中文时,可能会出现的问题是:由于中文一个字不只是由一个字节组成,所以直接通过切片可能会把一个中文字的编码截成两半,结果导致最后一个字符是乱码。
可以先将其转为[]rune,再截取后,转回string
字符串替换
示例:
fmt.Println(strings.Replace("ABAACEDF", "A", "a", 2)) // aBaACEDF fmt.Println(strings.Replace("ABAACEDF", "A", "a", -1)) // aBaaCEDF //第四个参数小于0,表示所有的都替换字符串转大写
示例:
fmt.Println(strings.ToUpper("abaacedf")) //ABAACEDF字符串转小写
示例:
fmt.Println(strings.ToLower("ABAACEDF")) //abaacedf查找子串
1、
func Contains(s, substr string) bool:这个函数是查找某个字符是否在这个字符串中存在,存在返回true示例
package main import ( "fmt" "strings" ) func main() { fmt.Println(strings.Contains("hello world", "lo")) //true }2、
func ContainsAny(s, chars string) bool:判断字符串s中是否包含个子串str中的任何一个字符。package main import ( "fmt" "strings" ) func main() { fmt.Println(strings.ContainsAny("hello world", "w")) //true fmt.Println(strings.ContainsAny("hello world", "wdx")) //true fmt.Println(strings.ContainsAny("hello world", "x")) //false }3、
Count(s string, str string) int:计算字符串str在s中的非重叠个数。如果str为空串则返回s中的字符(非字节)个数+1。package main import ( "fmt" "strings" ) func main() { fmt.Println(strings.Count("hello world", "l")) //3 }4、
ContainsRune(s string, r rune) bool:判断字符串s中是否包含字符r。其中rune类型是utf8.RUneCountString可以完整表示全部Unicode字符的类型。示例
package main import ( "fmt" "strings" ) func main() { fmt.Println(strings.ContainsRune("hello world", 'l')) //true fmt.Println(strings.ContainsRune("hello world", rune('l'))) //true fmt.Println(strings.ContainsRune("hello world", 108)) //true fmt.Println(strings.ContainsRune("hello world", 10)) //false }5、
Index(s string, str string) int:返回子串str在字符串s中第一次出现的位置。如果找不到则返回-1;如果str为空,则返回0。示例
package main import ( "fmt" "strings" ) func main() { fmt.Println(strings.Index("hello world", "l")) //2 }6、
LastIndex(s string, str string) int: 返回子串str在字符串s中最后一次出现的位置。如果找不到则返回-1;如果str为空则返回字符串s的长度。示例
package main import ( "fmt" "strings" ) func main() { fmt.Println(strings.LastIndex("hello world", "l")) //9 }7、
IndexRune(s string, r rune) int:返回字符r在字符串s中第一次出现的位置。如果找不到则返回-1。示例
package main import ( "fmt" "strings" ) func main() { fmt.Println(strings.IndexRune("hello world", 'l')) //2 fmt.Println(strings.IndexRune("hello world", rune('l'))) //2 }这里注意rune类型使用的单引号。
8、
IndexAny(s string, str string) int:返回字符串str中的任何一个字符在字符串s中第一次出现的位置。如果找不到或str为空则返回-1。示例
package main import ( "fmt" "strings" ) func main() { fmt.Println(strings.IndexAny("hello world", "l")) //2 fmt.Println(strings.IndexAny("hello world", "le")) //1 }9、
LastIndexAny(s string, str string) int:返回字符串str中的任何一个字符在字符串s中最后一次出现的位置。如果找不到或str为空则返回-1。示例
package main import ( "fmt" "strings" ) func main() { fmt.Println(strings.LastIndexAny("hello world", "l")) //9 fmt.Println(strings.LastIndexAny("hello world", "le")) //9 }10、
SplitN(s, str string, n int) []string:以str为分隔符,将s切分成多个子串,结果中不包含str本身。如果str为空则将s切分成Unicode字符列表。如果s中没有str子串,则将整个s作为[]string的第一个元素返回。参数n表示最多切分出几个子串,超出的部分将不再切分,最后一个n包含了所有剩下的不切分。如果n为0,则返回nil;如果n小于0,则不限制切分个数,全部切分。
示例
package main import ( "fmt" "strings" ) func main() { fmt.Println(strings.SplitN("hello world", "l", 2)) //[he lo world] fmt.Println(strings.SplitN("hello world", "l", 4)) //[he o wor d] }11、
SplitAfterN(s, str string, n int) []string:以str为分隔符,将s切分成多个子串,结果中包含str本身。如果str为空,则将s切分成Unicode字符列表。如果s 中没有str子串,则将整个s作为 []string 的第一个元素返回。参数n表示最多切分出几个子串,超出的部分将不再切分。如果n为0,则返回 nil;如果 n 小于 0,则不限制切分个数,全部切分。
示例
package main import ( "fmt" "strings" ) func main() { fmt.Println(strings.SplitAfterN("hello world", "l", 2)) //[hel lo world] fmt.Println(strings.SplitAfterN("hello world", "l", 4)) //[hel l o worl d] }12、
Split(s, str string) []string:以str为分隔符,将s切分成多个子切片,结果中不包含str本身。如果str为空,则将s切分成Unicode字符列表。如果s中没有str子串,则将整个s作为[]string的第一个元素返回。示例
package main import ( "fmt" "strings" ) func main() { fmt.Println(strings.Split("hello world", "l")) //[he o wor d] }13、
SplitAfter(s, str string) []string:以str为分隔符,将s切分成多个子切片,结果中包含str本身。如果 str 为空,则将 s 切分成Unicode字符列表。如果s中没有str子串,则将整个s作为[]string的第一个元素返回。示例
package main import ( "fmt" "strings" ) func main() { fmt.Println(strings.SplitAfter("hello world", "l")) //[hel l o worl d] }14、
Fields(s string) []string:以连续的空白字符为分隔符,将s切分成多个子串,结果中不包含空白字符本身。空白字符有:\t, \n, \v, \f, \r, ' ‘, U+0085 (NEL), U+00A0 (NBSP) 。如果 s 中只包含空白字符,则返回一个空列表。示例
package main import ( "fmt" "strings" ) func main() { fmt.Println(strings.Fields("hello world")) //[hello world] }15、
FieldsFunc(s string, f func(rune) bool) []string:以一个或多个满足f(rune)的字符为分隔符,将s切分成多个子串,结果中不包含分隔符本身。如果s中没有满足f(rune)的字符,则返回一个空列表。示例
package main import ( "fmt" "strings" ) func main() { //空格和l都是分隔符 fn := func(c rune) bool { return strings.ContainsRune(" l", c) } fmt.Println(strings.FieldsFunc("hello world", fn)) //[he o wor d] }16、
HasPrefix(s string, prefix string) bool:判断字符串s是否以prefix开头。示例
package main import ( "fmt" "strings" ) func main() { fmt.Println(strings.HasPrefix("hello world", "hel")) //true fmt.Println(strings.HasPrefix("hello world", "el")) //false }17、
HasSuffix(s, suffix string) bool:判断字符串s是否以prefix结尾。示例
package main import ( "fmt" "strings" ) func main() { fmt.Println(strings.HasSuffix("hello world", "ld")) //true fmt.Println(strings.HasSuffix("hello world", "el")) //false }18、
Map(f func(rune) rune, s string) string:将s中满足f(rune)的字符替换为f(rune)的返回值。如果f(rune)返回负数,则相应的字符将被删除。示例
package main import ( "fmt" "strings" ) func main() { fn := func(c rune) rune { if strings.ContainsRune(",|/", c) { return ' ' } else { return c } } fmt.Println(strings.Map(fn, "hello|world"))//hello world }19、
Repeat(s string, n int) string:将n个字符串s连接成一个新的字符串。示例
package main import ( "fmt" "strings" ) func main() { fmt.Println(strings.Repeat("he", 10)) //hehehehehehehehehehe }20、
ToTitle(s string) string:将s中的所有字符修改为其Title格式,大部分字符的Title格式就是Upper格式,只有少数字符的Title格式是特殊字符。这里的ToTitle主要给Title函数调用。示例
fmt.Println(strings.Title("hello world")) //Hello World21、
TrimLeftFunc(s string, f func(rune) bool) string:删除s左边连续的满足f(rune)的字符。示例
fn := func(c rune) bool { return strings.ContainsRune(",|/", c) } fmt.Println(strings.TrimLeftFunc("|/hello world/", fn))//hello world/22、
TrimRightFunc(s string, f func(rune) bool) string:删除右边连续的满足f(rune)的字符。示例
fn := func(c rune) bool { return strings.ContainsRune(",|/", c) } fmt.Println(strings.TrimRightFunc("|/hello world/", fn)) //|/hello world23、
IndexFunc(s string, f func(rune) bool) int:返回s中第一个满足f(rune) 的字符的字节位置。如果没有满足 f(rune) 的字符,则返回 -1。示例
fn := func(c rune) bool { return strings.ContainsRune(",|/", c) } fmt.Println(strings.IndexFunc("|/hello world/", fn)) //0 fmt.Println(strings.IndexFunc("hello world/", fn)) //11 fmt.Println(strings.IndexFunc("hello world", fn)) //-124、
LastIndexFunc(s string, f func(rune) bool) int:返回s中最后一个满足f(rune)的字符的字节位置。如果没有满足 f(rune) 的字符,则返回 -1。示例
fn := func(c rune) bool { return strings.ContainsRune(",|/", c) } fmt.Println(strings.LastIndexFunc("|/hello world/", fn)) //13 fmt.Println(strings.LastIndexFunc("hello world/", fn)) //11 fmt.Println(strings.LastIndexFunc("hello world", fn)) //-125、
Trim(s string, str string) string:删除s首尾连续的包含在str中的字符。示例
fmt.Println(strings.Trim("/hello world/", "/")) //hello world26、
TrimLeft(s string, str string) string:删除s首部连续的包含在str中的字符串。示例
fmt.Println(strings.TrimLeft("/hello world/", "/")) //hello world/27、
TrimRight(s string, str string) string:删除s尾部连续的包含在str中的字符串。示例
fmt.Println(strings.TrimRight("/hello world/", "/")) // /hello world28、
TrimSpace(s string) string:删除s首尾连续的的空白字符。示例
fmt.Println(strings.TrimRight(" hello world ", "/")) //hello world29、
TrimPrefix(s, prefix string) string:删除s头部的prefix字符串。如果s不是以prefix开头,则返回原始s。示例
fmt.Println(strings.TrimPrefix("/hello world/", "/")) //hello world/30、
TrimSuffix(s, suffix string) string:删除s尾部的suffix字符串。如果s不是以suffix结尾,则返回原始s。(只去掉一次,注意和TrimRight区别)示例
fmt.Println(strings.TrimSuffix("/hello world/", "/")) ///hello world31、
EqualFold(s1, s2 string) bool:比较UTF-8编码在小写的条件下是否相等,不区分大小写,同时它还会对特殊字符进行转换。比如将“ϕ”转换为“Φ”、将“DŽ”转换为“Dž”等,然后再进行比较。“==”比较字符串是否相等,区分大小写,返回bool。
示例
fmt.Println(strings.EqualFold("hello world", "hello WORLD")) //true fmt.Println(strings.EqualFold("hello world", "hello WORLDd")) //false32、
Compare(s1 string, s2 string) int1:比较字符串,区分大小写。相等为0,s1>s2为-1,s1示例
fmt.Println(strings.Compare("hello world", "hello world")) //0 fmt.Println(strings.Compare("hello world", "hello WORLDd")) //1 fmt.Println(strings.Compare("hello WORLD" ,"hello world" )) //-1以上为个人经验,希望能给大家一个参考,也希望大家多多支持golang学习网。如有错误或未考虑完全的地方,望不吝赐教。
本篇关于《go如何删除字符串中的部分字符》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于Golang的相关知识,请关注golang学习网公众号!
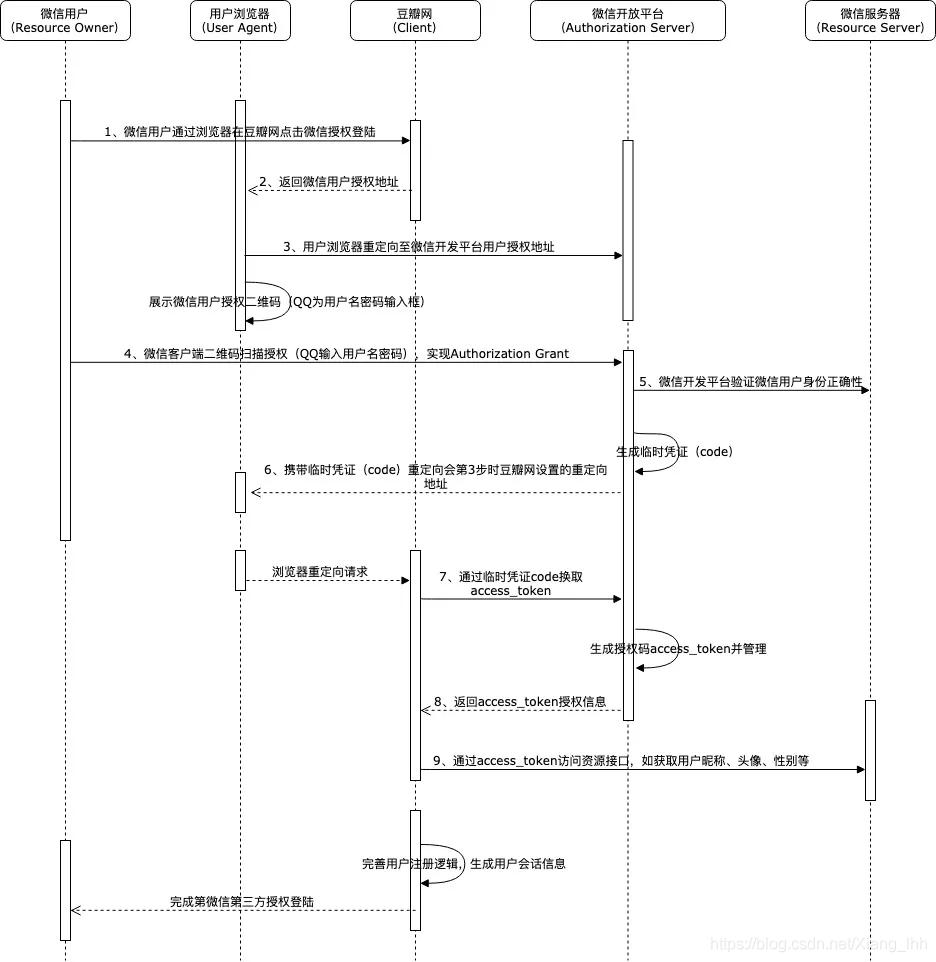 golang使用grpc+go-kit模拟oauth认证的操作
golang使用grpc+go-kit模拟oauth认证的操作
- 上一篇
- golang使用grpc+go-kit模拟oauth认证的操作

- 下一篇
- gorm update传入struct对象,零值字段不更新的解决方案
-

- 微笑的歌曲
- 这篇文章内容出现的刚刚好,太全面了,受益颇多,已收藏,关注师傅了!希望师傅能多写Golang相关的文章。
- 2023-02-15 10:51:36
-
- 明亮的御姐
- 这篇博文出现的刚刚好,老哥加油!
- 2023-02-08 22:07:24
-
- 俊逸的日记本
- 细节满满,已加入收藏夹了,感谢楼主的这篇文章,我会继续支持!
- 2023-02-02 08:33:11
-
- 整齐的白云
- 很棒,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢大佬分享技术贴!
- 2023-01-15 15:58:45
-
- Golang · Go教程 | 17小时前 | 内存 · JSON · 性能优化 · Go教程 · json.Decoder · Go 流式解析 json.Decoder 超大JSON 峰值内存 批次写入
- Go 处理超大 JSON 怎么降峰值内存:json.Decoder 流式读取、批次落库与压测对比
- 310浏览 收藏
-
- Golang · Go教程 | 17小时前 | golang · HTTP · go · 服务端 · 实战 · 安全配置 · http.server MaxBytesReader ReadHeaderTimeout Go HTTP 服务 请求体限制 响应头限制
- Go HTTP 服务怎么设请求边界:请求体、超时和响应头的生产配置
- 455浏览 收藏
-
- Golang · Go教程 | 2天前 | golang · 缓存 · singleflight · go · 高并发 · 后端开发 · Go 并发控制 缓存失效 请求合并 singleflight 回源
- Go singleflight 怎么合并同一请求:缓存失效时别让 500 个请求一起回源
- 109浏览 收藏
-

- Golang · Go教程 | 2天前 | [] · []
- Go 项目 GitHub Actions 怎么设质量门禁:go vet、go test 与构建分阶段拦截
- 485浏览 收藏
-

- Golang · Go教程 | 2天前 | [] · []
- Go html/template 怎么安全把后端数据交给前端:别把 JSON 硬塞进 template.JS
- 177浏览 收藏
-

- Golang · Go教程 | 2天前 | 前端开发 · Go教程 · html/template · 网页模板 · 导航 · Go html/template CurrentPath 导航高亮 template.FuncMap Go网页模板
- Go html/template 怎么高亮当前导航:传入 CurrentPath 的最小写法
- 409浏览 收藏
-
![Go 拼接字符串怎么选:strings.Builder、bytes.Buffer 和 []byte 的边界](/uploads/20260716/1784195965-01-builder-timeline.webp)
- Golang · Go教程 | 3天前 | 标准库 · 基准测试 · Go教程 · 字符串拼接 · Go 字符串拼接 strings.Builder bytes.Buffer []byte
- Go 拼接字符串怎么选:strings.Builder、bytes.Buffer 和 []byte 的边界
- 188浏览 收藏



-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 4577次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 4226次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 4187次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 4409次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 4366次使用
-
- 详解如何在Go语言中循环数据结构
- 2022-12-22 406浏览
-
- 详解Golang中字符串的使用
- 2023-01-01 370浏览
-
- 深度解密Go语言中字符串的使用
- 2022-12-24 160浏览
-
- Go实现快速生成固定长度的随机字符串
- 2023-02-24 432浏览
-
- Go如何实现json字符串与各类struct相互转换
- 2023-01-07 377浏览


