为什么此代码在 Go 中与 Java 中运行需要更长的时间
Go 语言中的循环比 Java 语言中慢的原因尚未明确。一些人认为这是由于 Go 编译器生成的代码效率较低,而另一些人则认为 Java 的 JIT 优化器对循环进行了重大优化。为了探索这一差异,本文比较了 Go 和 Java 中一个简单循环的性能,该循环对 200 亿个数字进行计数。结果显示,Go 版本的循环比 Java 版本慢得多,平均运行时间为 5,851 毫秒,而 Java 版本的平均运行时间为 392 毫秒。本文分析了 Go 编译器生成的代码,发现它非常复杂且冗长,而 Java 字节码相对简单。本文还讨论了 JIT 优化可能对 Java 代码产生的影响,并指出这种优化可能预先计算循环变量的值,从而显著提高性能。
最近开始学习 go,我是一个忠实的粉丝,有 java 背景。
我以不同的方式比较了这些语言,令我惊讶的是,与 java 相比,计数到 200 亿的简单循环在 golang 中花费的时间要长得多。
想知道是否有人可以对我在这里遗漏的内容提供任何见解。这就是我所做的:
java
编写以下代码,从普通的 main() 方法执行它,使用 gradle 构建可执行 jar,并使用以下命令从命令行执行它: java -jar build/libs/my-executable.jar
private void counttotwentybillion() {
long count = 0;
long start = system.currenttimemillis();
for (int k = 0; k < 10; k++) {
system.out.println("on step " + k);
for (int i = 0; i < 2_000_000_000; i++) {
// do nothing but count
count++;
}
}
long end = system.currenttimemillis();
system.out.println("total time took: " + (end - start) + " ms to get at count: " + count);
}
通过 3 个单独的试验,我得到了以下结果:
// total time took: 396 ms to get at count: 20000000000 // total time took: 393 ms to get at count: 20000000000 // total time took: 388 ms to get at count: 20000000000 // 392 ms average
去
在 go 中构建此文件,使用“go build”构建并使用 在命令行中执行。/loop-counter
package main
import (
"fmt"
"time"
)
func main() {
count := 0
nanos := time.now().unixnano()
start := nanos / 1000000
for i := 0; i < 10; i++ {
fmt.printf("on step %d\n", i)
for k := 0; k < 2000000000; k++ {
count++
}
}
nanos = time.now().unixnano()
end := nanos / 1000000
timelength := end - start
fmt.printf("total time took: %d ms to get at count: %d\n", timelength, count)
}
经过 3 次单独的试验,我得到了以下结果:
// Total time took: 5812 ms to get at count: 20000000000 // Total time took: 5834 ms to get at count: 20000000000 // Total time took: 5907 ms to get at count: 20000000000 // 5,851 ms average
我开始期待 go 会更快,但最终却感到惊讶。所有试验均在同一台机器上、相同条件下进行。
谁能告诉我什么?
谢谢
解决方案
我不是 go 专家,但 java 确实优化了循环。
假设您有一个带有 3ghz 的单核处理器,每条指令的时间为 0.3ns,我们假设每个增量都是一条指令。因此 0.3ns *200 亿 = 6s 是在没有任何优化的情况下粗略估计的性能。
您可以通过向您的程序提供 -xx:loopunrolllimit=1 来验证 java 是否在此处进行了一些欺骗。这告诉 jvm 几乎不进行循环展开,因此可以防止大多数 jit 优化在您的示例中发生。
这样做后,您的 java 示例的运行时现在在我的机器上为 6s,这与 go 基准测试相当。
go 版本中可能还有一个选项可以启用循环展开等优化(请参阅 go 手册)。
最后,这再次表明,微基准测试很难正确执行。他们经常自欺欺人地假设一些不正确的事情。
以下是我的一些观察结果。我将展示一些通过编译该程序获得的英特尔语法汇编代码。我使用的是Compiler Explorer。要理解下面的内容,您不必了解很多汇编,这里最重要的元素是大小,它越大,速度越慢。如果可以的话我会把这篇文章缩小,但是生成的代码出奇的庞大,而且我对 go 的了解还不够,不知道什么是无用的。如果您想查看汇编中每个语句转换成的内容,编译器资源管理器将为您突出显示所有内容。
tl;dr:
在我看来,go 编译器是一个灾难性的混乱,c++ 代码得到了很好的优化,而 java 与 go 相比很小。 jit'ing 可能对 java 代码产生重大影响,对于分解内联优化的循环来说也可能太复杂(预先计算 count 的值)。
go 代码编译成这个怪物:
text "".main(sb), $224-0
movq (tls), cx
leaq -96(sp), ax
cmpq ax, 16(cx)
jls 835
subq $224, sp
movq bp, 216(sp)
leaq 216(sp), bp
funcdata $0, gclocals·f6bd6b3389b872033d462029172c8612(sb)
funcdata $1, gclocals·17283ea8379a997487dd6f8baf7ae6ea(sb)
pcdata $0, $0
call time.now(sb)
movq 16(sp), ax
movq 8(sp), cx
movq (sp), dx
movq dx, time.t·2+160(sp)
movq cx, time.t·2+168(sp)
movq ax, time.t·2+176(sp)
movq time.t·2+160(sp), ax
movq ax, cx
shrq $63, ax
shlq $63, ax
testq $-1, ax
jeq 806
movq cx, dx
shlq $1, cx
shrq $31, cx
movq $59453308800, bx
addq bx, cx
andq $1073741823, dx
movlqsx dx, dx
imulq $1000000000, cx
addq dx, cx
movq $-6795364578871345152, dx
addq dx, cx
movq $4835703278458516699, ax
imulq cx
sarq $63, cx
sarq $18, dx
subq cx, dx
movq dx, "".start+72(sp)
xorl ax, ax
movq ax, cx
jmp 257
incq cx
incq ax
cmpq cx, $2000000000
jlt 213
movq "".i+80(sp), si
incq si
movq "".start+72(sp), dx
movq $59453308800, bx
movq ax, cx
movq si, ax
movq cx, "".count+88(sp)
cmpq ax, $10
jge 404
movq ax, "".i+80(sp)
movq ax, ""..autotmp_24+112(sp)
xorps x0, x0
movups x0, ""..autotmp_23+120(sp)
leaq type.int(sb), cx
movq cx, (sp)
leaq ""..autotmp_24+112(sp), dx
movq dx, 8(sp)
pcdata $0, $1
call runtime.convt2e64(sb)
movq 24(sp), ax
movq 16(sp), cx
movq cx, ""..autotmp_23+120(sp)
movq ax, ""..autotmp_23+128(sp)
leaq go.string."on step %d\n"(sb), ax
movq ax, (sp)
movq $11, 8(sp)
leaq ""..autotmp_23+120(sp), cx
movq cx, 16(sp)
movq $1, 24(sp)
movq $1, 32(sp)
pcdata $0, $1
call fmt.printf(sb)
movq "".count+88(sp), ax
xorl cx, cx
jmp 219
pcdata $0, $2
call time.now(sb)
movq 16(sp), ax
movq 8(sp), cx
movq (sp), dx
movq dx, time.t·2+136(sp)
movq cx, time.t·2+144(sp)
movq ax, time.t·2+152(sp)
movq time.t·2+136(sp), ax
movq ax, cx
shrq $63, ax
shlq $63, ax
testq $-1, ax
jeq 787
movq cx, dx
shlq $1, cx
shrq $31, cx
movq $59453308800, bx
addq bx, cx
imulq $1000000000, cx
andq $1073741823, dx
movlqsx dx, dx
addq dx, cx
movq $-6795364578871345152, dx
leaq (dx)(cx*1), ax
movq ax, "".~r0+64(sp)
movq $4835703278458516699, cx
imulq cx
sarq $18, dx
movq "".~r0+64(sp), cx
sarq $63, cx
subq cx, dx
movq "".start+72(sp), cx
subq cx, dx
movq dx, ""..autotmp_29+104(sp)
movq "".count+88(sp), cx
movq cx, ""..autotmp_30+96(sp)
xorps x0, x0
movups x0, ""..autotmp_28+184(sp)
movups x0, ""..autotmp_28+200(sp)
leaq type.int64(sb), cx
movq cx, (sp)
leaq ""..autotmp_29+104(sp), cx
movq cx, 8(sp)
pcdata $0, $3
call runtime.convt2e64(sb)
movq 16(sp), cx
movq 24(sp), dx
movq cx, ""..autotmp_28+184(sp)
movq dx, ""..autotmp_28+192(sp)
leaq type.int(sb), cx
movq cx, (sp)
leaq ""..autotmp_30+96(sp), cx
movq cx, 8(sp)
pcdata $0, $3
call runtime.convt2e64(sb)
movq 24(sp), cx
movq 16(sp), dx
movq dx, ""..autotmp_28+200(sp)
movq cx, ""..autotmp_28+208(sp)
leaq go.string."total time took: %d to get at count: %d\n"(sb), cx
movq cx, (sp)
movq $40, 8(sp)
leaq ""..autotmp_28+184(sp), cx
movq cx, 16(sp)
movq $2, 24(sp)
movq $2, 32(sp)
pcdata $0, $3
call fmt.printf(sb)
movq 216(sp), bp
addq $224, sp
ret
movq time.t·2+144(sp), bx
movq cx, dx
movq bx, cx
jmp 501
movq time.t·2+168(sp), si
movq cx, dx
movq $59453308800, bx
movq si, cx
jmp 144
nop
pcdata $0, $-1
call runtime.morestack_noctxt(sb)
jmp 0
text "".init(sb), $8-0
movq (tls), cx
cmpq sp, 16(cx)
jls 89
subq $8, sp
movq bp, (sp)
leaq (sp), bp
funcdata $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(sb)
funcdata $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(sb)
movblzx "".initdone·(sb), ax
cmpb al, $1
jls 47
movq (sp), bp
addq $8, sp
ret
jne 56
pcdata $0, $0
call runtime.throwinit(sb)
undef
movb $1, "".initdone·(sb)
pcdata $0, $0
call fmt.init(sb)
pcdata $0, $0
call time.init(sb)
movb $2, "".initdone·(sb)
movq (sp), bp
addq $8, sp
ret
nop
pcdata $0, $-1
call runtime.morestack_noctxt(sb)
jmp 0
text type..hash.[2]interface {}(sb), dupok, $40-24
movq (tls), cx
cmpq sp, 16(cx)
jls 103
subq $40, sp
movq bp, 32(sp)
leaq 32(sp), bp
funcdata $0, gclocals·d4dc2f11db048877dbc0f60a22b4adb3(sb)
funcdata $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(sb)
xorl ax, ax
movq "".h+56(sp), cx
jmp 82
movq ax, "".i+24(sp)
shlq $4, ax
movq "".p+48(sp), bx
addq bx, ax
movq ax, (sp)
movq cx, 8(sp)
pcdata $0, $0
call runtime.nilinterhash(sb)
movq 16(sp), cx
movq "".i+24(sp), ax
incq ax
cmpq ax, $2
jlt 38
movq cx, "".~r2+64(sp)
movq 32(sp), bp
addq $40, sp
ret
nop
pcdata $0, $-1
call runtime.morestack_noctxt(sb)
jmp 0
text type..eq.[2]interface {}(sb), dupok, $48-24
movq (tls), cx
cmpq sp, 16(cx)
jls 155
subq $48, sp
movq bp, 40(sp)
leaq 40(sp), bp
funcdata $0, gclocals·8f9cec06d1ae35cc9900c511c5e4bdab(sb)
funcdata $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(sb)
xorl ax, ax
jmp 46
movq ""..autotmp_8+32(sp), cx
leaq 1(cx), ax
cmpq ax, $2
jge 140
movq ax, cx
shlq $4, ax
movq "".p+56(sp), dx
movq 8(ax)(dx*1), bx
movq (ax)(dx*1), si
movq "".q+64(sp), di
movq 8(ax)(di*1), r8
movq (ax)(di*1), ax
cmpq si, ax
jne 125
movq cx, ""..autotmp_8+32(sp)
movq si, (sp)
movq bx, 8(sp)
movq r8, 16(sp)
pcdata $0, $0
call runtime.efaceeq(sb)
movblzx 24(sp), ax
testb al, al
jne 37
movb $0, "".~r2+72(sp)
movq 40(sp), bp
addq $48, sp
ret
movb $1, "".~r2+72(sp)
movq 40(sp), bp
addq $48, sp
ret
nop
pcdata $0, $-1
call runtime.morestack_noctxt(sb)
jmp 0
我不知道其中大部分在做什么。我只能希望其中大部分是某种 gc 代码。我查找了如何启用 go 编译器的优化,我所能找到的只是如何禁用优化。
相比之下,我在 c++ 中查看了类似的函数
#include#include #include using namespace std::chrono; milliseconds getms() { return duration_cast< milliseconds >( system_clock::now().time_since_epoch() ); } int main() { int count = 0; milliseconds millis = getms(); for(int i = 0; i < 10; ++i) { printf("on step %d\n", i); for(int j = 0; j < 2000000000; ++j) { ++count; } } milliseconds time = getms() - millis; printf("total time took: %" prid64 " to get at count: %d\n", time.count(), count); }
未经优化编译为(编译器x86-64 clang(trunk(可能是6.0.0),标志:-std=c++0x -o0):
main: # @main
push rbp
mov rbp, rsp
sub rsp, 48
mov dword ptr [rbp - 4], 0
mov dword ptr [rbp - 8], 0
call getms()
mov qword ptr [rbp - 16], rax
mov dword ptr [rbp - 20], 0
.lbb3_1: # =>this loop header: depth=1
cmp dword ptr [rbp - 20], 10
jge .lbb3_8
mov esi, dword ptr [rbp - 20]
movabs rdi, offset .l.str
mov al, 0
call printf
mov dword ptr [rbp - 24], 0
mov dword ptr [rbp - 44], eax # 4-byte spill
.lbb3_3: # parent loop bb3_1 depth=1
cmp dword ptr [rbp - 24], 2000000000
jge .lbb3_6
mov eax, dword ptr [rbp - 8]
add eax, 1
mov dword ptr [rbp - 8], eax
mov eax, dword ptr [rbp - 24]
add eax, 1
mov dword ptr [rbp - 24], eax
jmp .lbb3_3
.lbb3_6: # in loop: header=bb3_1 depth=1
jmp .lbb3_7
.lbb3_7: # in loop: header=bb3_1 depth=1
mov eax, dword ptr [rbp - 20]
add eax, 1
mov dword ptr [rbp - 20], eax
jmp .lbb3_1
.lbb3_8:
call getms()
mov qword ptr [rbp - 40], rax
lea rdi, [rbp - 40]
lea rsi, [rbp - 16]
call std::common_type >, std::chrono::duration > >::type std::chrono::operator-, long, std::ratio<1l, 1000l> >(std::chrono::duration > const&, std::chrono::duration > const&)
mov qword ptr [rbp - 32], rax
lea rdi, [rbp - 32]
call std::chrono::duration >::count() const
mov edx, dword ptr [rbp - 8]
movabs rdi, offset .l.str.1
mov rsi, rax
mov al, 0
call printf
mov edx, dword ptr [rbp - 4]
mov dword ptr [rbp - 48], eax # 4-byte spill
mov eax, edx
add rsp, 48
pop rbp
ret
.l.str:
.asciz "on step %d\n"
.l.str.1:
.asciz "total time took: %ld to get at count: %d\n"
实际上还有很多代码,但它只是 chrono 实现,在优化后的代码中它只是一个库函数调用。我还删除了 getms 的实现,因为它主要是一个包装方法。
通过 o1(大小)优化,这会变成:
main: # @main
push rbx
sub rsp, 32
call getms()
mov qword ptr [rsp + 24], rax
xor ebx, ebx
.lbb3_1: # =>this inner loop header: depth=1
mov edi, offset .l.str
xor eax, eax
mov esi, ebx
call printf
add ebx, 1
cmp ebx, 10
jne .lbb3_1
call getms()
mov qword ptr [rsp + 8], rax
lea rdi, [rsp + 8]
lea rsi, [rsp + 24]
call std::common_type >, std::chrono::duration > >::type std::chrono::operator-, long, std::ratio<1l, 1000l> >(std::chrono::duration > const&, std::chrono::duration > const&)
mov qword ptr [rsp + 16], rax
lea rdi, [rsp + 16]
call std::chrono::duration >::count() const
mov rcx, rax
mov edi, offset .l.str.1
mov edx, -1474836480
xor eax, eax
mov rsi, rcx
call printf
xor eax, eax
add rsp, 32
pop rbx
ret
.l.str:
.asciz "on step %d\n"
.l.str.1:
.asciz "total time took: %ld to get at count: %d\n"
o2(速度)和 o3(最大)优化本质上归结为展开的外循环(仅用于打印语句)和预先计算的计数值。
这主要显示了 go 生成的糟糕代码以及 c++ 中发生的一些优化。但这些都没有准确显示 java 字节码包含什么内容,或者如果运行足够多的时间,jit 会生成什么内容。这是 java 字节码:
public static void countToTwentyBillion();
Code:
0: lconst_0
1: lstore_0
2: invokestatic #2
// Method java/lang/System.currentTimeMillis:()J
5: lstore_2
6: iconst_0
7: istore
4
9: iload
4
11: bipush
10
13: if_icmpge
68
16: getstatic
#3
// Field java/lang/System.out:Ljava/io/PrintStream;
19: new
#4
// class java/lang/StringBuilder
22: dup
23: invokespecial #5
// Method java/lang/StringBuilder.'':()V
26: ldc
#6
// String On step
28: invokevirtual #7
// Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
31: iload
4
33: invokevirtual #8
// Method java/lang/StringBuilder.append:(I)Ljava/lang/StringBuilder;
36: invokevirtual #9
// Method java/lang/StringBuilder.toString:()Ljava/lang/String;
39: invokevirtual #10
// Method java/io/PrintStream.println:(Ljava/lang/String;)V
42: iconst_0
43: istore
5
45: iload
5
47: ldc
#11
// int 2000000000
49: if_icmpge
62
52: lload_0
53: lconst_1
54: ladd
55: lstore_0
56: iinc
5, 1
59: goto
45
62: iinc
4, 1
65: goto
9
68: invokestatic #2
// Method java/lang/System.currentTimeMillis:()J
71: lstore
4
73: getstatic
#3
// Field java/lang/System.out:Ljava/io/PrintStream;
76: new
#4
// class java/lang/StringBuilder
79: dup
80: invokespecial #5
// Method java/lang/StringBuilder.'':()V
83: ldc
#12
// String Total time took:
85: invokevirtual #7
// Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
88: lload
4
90: lload_2
91: lsub
92: invokevirtual #13
// Method java/lang/StringBuilder.append:(J)Ljava/lang/StringBuilder;
95: ldc
#14
// String ms to get at count:
97: invokevirtual #7
// Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
100: lload_0
101: invokevirtual #13
// Method java/lang/StringBuilder.append:(J)Ljava/lang/StringBuilder;
104: invokevirtual #9
// Method java/lang/StringBuilder.toString:()Ljava/lang/String;
107: invokevirtual #10
// Method java/io/PrintStream.println:(Ljava/lang/String;)V
110: return
不幸的是,目前我不想编译 hsdis 和 jit 代码,但它可能最终看起来像一些 c++ 示例。根据我对 jit 的了解,它可能能够预先计算计数值。但这段代码有点复杂(就循环而言),这可能会使快速 jit 优化变得更加困难。
以上就是《为什么此代码在 Go 中与 Java 中运行需要更长的时间》的详细内容,更多关于的资料请关注golang学习网公众号!
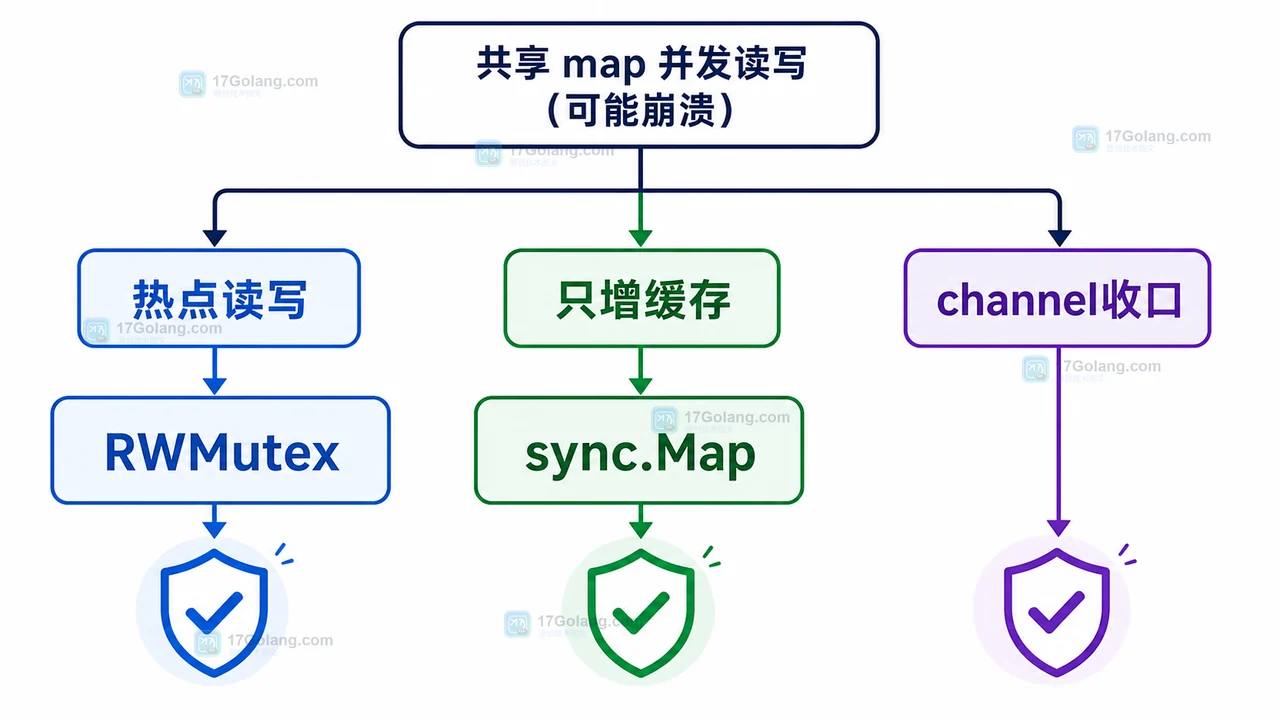
 在迭代映射的同时并发修改映射时,如何使用 RWMutex
在迭代映射的同时并发修改映射时,如何使用 RWMutex
- 上一篇
- 在迭代映射的同时并发修改映射时,如何使用 RWMutex

- 下一篇
- Go http.FileServer 不提供所有静态内容
-

- Golang · Go问答 | 3个月前 | go atomic原理 Go并发安全
- Go语言中atomic包如何保证并发安全?
- 109浏览 收藏


![Go 问答:nil slice 和空 slice 有什么区别,JSON 为什么一个是 null 一个是 []](/uploads/20260616/1781589727-go-nil-empty-slice-struct.webp)

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 1012次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 972次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 910次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 1097次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 1081次使用
-
- GoLand调式动态执行代码
- 2023-01-13 502浏览
-
- 用Nginx反向代理部署go写的网站。
- 2023-01-17 502浏览
-
- Golang取得代码运行时间的问题
- 2023-02-24 501浏览
-
- 请问 go 代码如何实现在代码改动后不需要Ctrl+c,然后重新 go run *.go 文件?
- 2023-01-08 501浏览
-
- 如何从同一个 io.Reader 读取多次
- 2023-04-11 501浏览


