详细介绍

Voicebox:Meta的尖端语音生成模型,开启语音合成新时代
Voicebox是由Meta公司开发的一款革命性的语音生成模型,采用非自回归流匹配技术,能够通过大规模数据学习进行文本引导的语音填充任务。Voicebox不仅支持多语言合成,还能去除瞬态噪声、编辑内容、转换音频风格,并生成多样化的语音样本,其速度比现有自回归模型快20倍。
核心优势:
- 多语言支持:支持英语、法语、德语、西班牙语、波兰语和葡萄牙语,覆盖广泛的语言需求。
- 高效生成:比现有最先进的自回归模型快20倍,极大提升了语音生成效率。
- 上下文学习:通过上下文学习,执行未明确训练的任务,灵活性极强。
- 未来上下文利用:与传统自回归模型不同,Voicebox可以利用未来上下文,实现更精确的语音处理。
强大功能:
- 瞬态噪声去除:有效去除录音中的瞬态噪声,如门铃声或狗叫声,提升音质。
- 内容编辑:无需重新录音即可纠正误读的单词,简化编辑流程。
- 零样本文本到语音合成:通过上下文学习,合成具有任何音频风格的语音,满足多样化需求。
- 跨语言风格转换:跨语言转换音频风格,如使用法语提示生成英语语音,增强创作自由度。
- 多样化语音生成:通过采样技术,创造独特且富有表现力的音频风格,满足创意需求。
应用场景:
- 瞬态噪声去除:使用Voicebox重新生成被噪声污染的语音,提升录音质量。
- 内容编辑:对误读的文本进行编辑,Voicebox会相应调整语音输出,提高编辑效率。
- 零样本文本到语音合成:输入想要风格的参考音频和文本,Voicebox将合成听起来与参考一致的语音,满足个性化需求。
- 跨语言风格转换:使用非英语的音频提示生成英语语音,或将配音语音转换为原说话者的声音,增强跨语言交流。
- 多样化语音生成:Voicebox可以创建独特的音频风格,无需任何音频条件,激发创意灵感。
总结:
Voicebox作为Meta公司开发的多语言语音生成模型,凭借其上下文学习能力和高效生成速度,在语音合成、编辑和风格转换方面展现出了强大的潜力。尽管Voicebox具有巨大的应用前景,但Meta公司也意识到技术滥用的风险,并采取了相应措施,如建立有效的分类器来区分真实语音和由Voicebox生成的音频,以确保技术的负责任使用。目前,Voicebox模型和代码尚未公开提供,以确保其安全性和合规性。
查看更多
最新文章
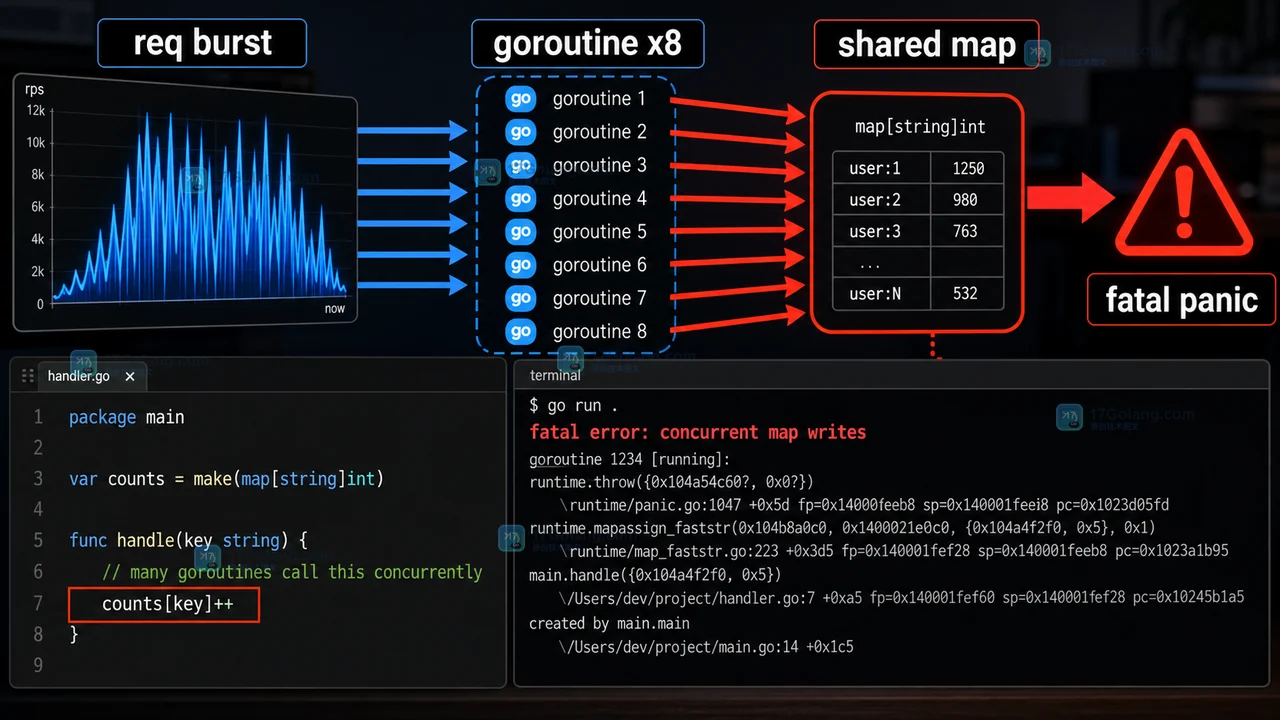
Go map 并发写 panic 怎么办:从共享 map 到可控写入路径
围绕 Go map 并发写 panic,按高并发场景解释为什么共享 map 会崩溃,并给出加锁、分片 m
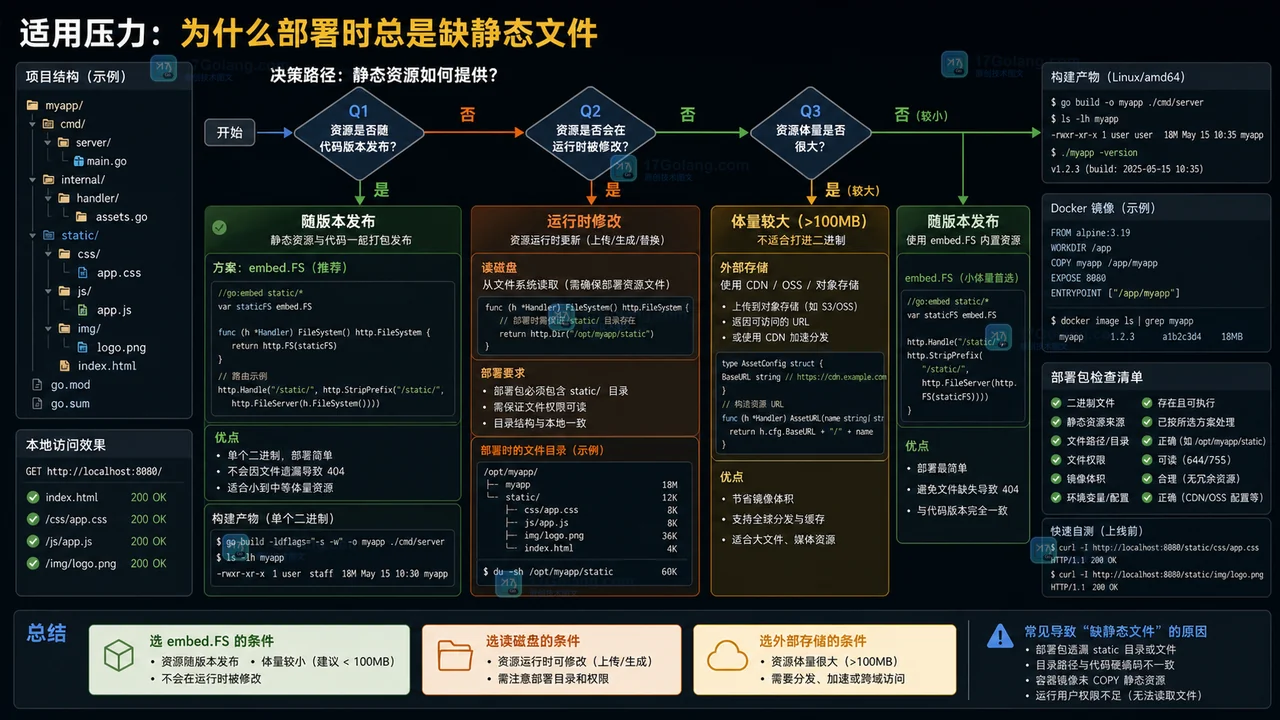
Go embed 静态资源打包模式:模板和前端文件要不要收进二进制?
围绕 Go embed.FS 静态资源打包模式,分析模板、前端文件和配置示例是否适合收进二进制,给出开发

Go Webhook 验签实战:HMAC、时间窗口和重放防护怎么做
以 Go Webhook 接收接口为例,讲清 HMAC 验签为什么要绑定原始 body、时间戳和事件 I
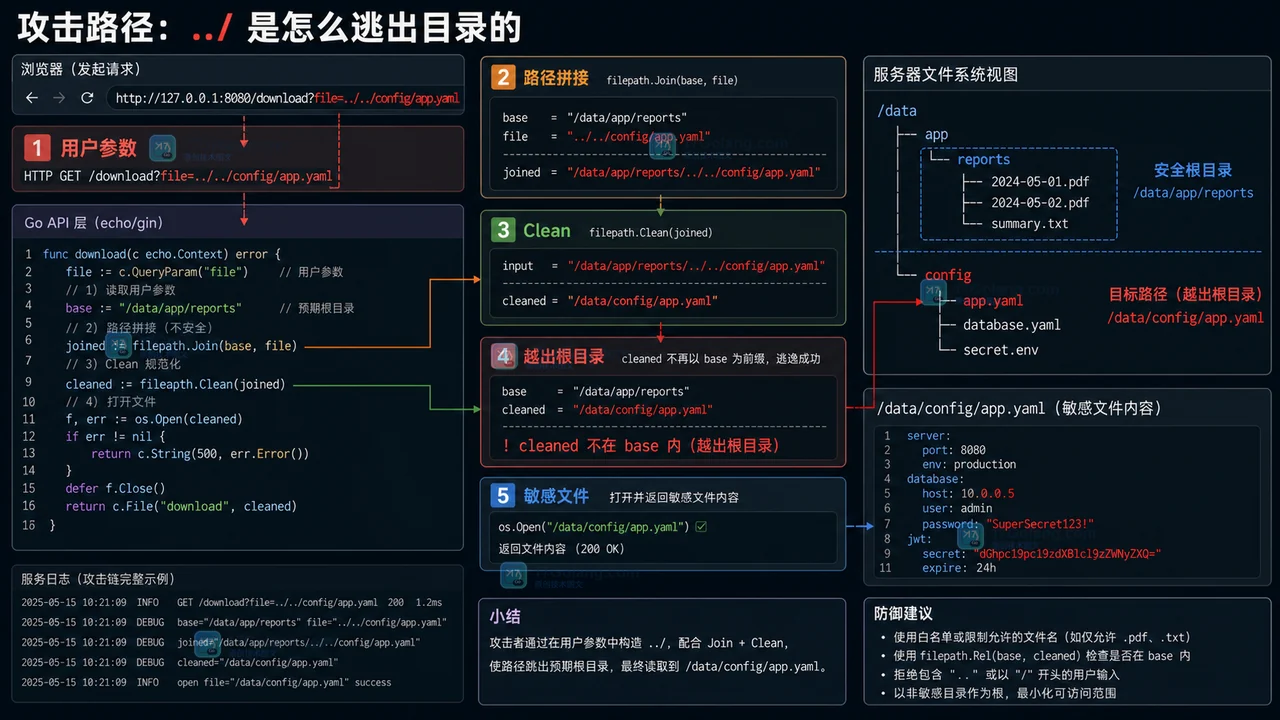
Go 问答:文件下载接口如何防路径穿越,filepath.Clean 够不够?
围绕 Go 文件下载接口的路径穿越风险,解释 filepath.Clean 为什么不等于安全校验,并给出
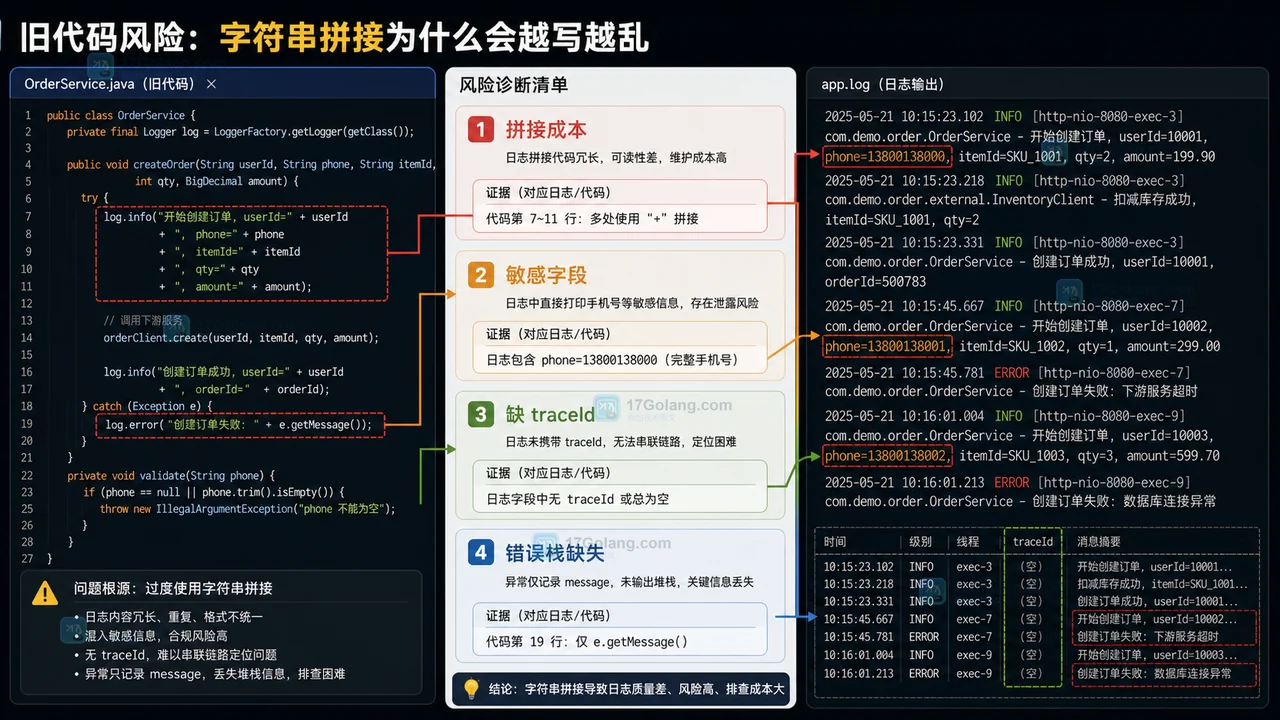
Java 日志迁移变更单:从字符串拼接到参数化日志和 MDC traceId
围绕 Java 老项目日志迁移,说明如何从字符串拼接改成 SLF4J 参数化日志,并补上 MDC tra

PHP 老接口迁移变更单:从散落 $_POST 到 Request DTO 与统一错误响应
以 PHP 老接口迁移为例,把散落的 $_POST 读取改成 Request DTO、集中校验和统一错误



