详细介绍
EchoMimic:音频驱动肖像动画生成工具
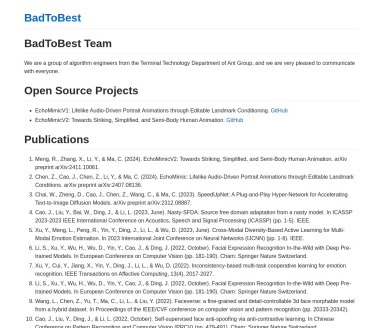
EchoMimic是一款创新的工具,专门用于生成逼真的音频驱动肖像动画。它通过音频和面部地标的单独或结合使用,能够为用户提供灵活多样的驱动方式,满足不同创作需求。
核心特点:
- 多驱动方式:EchoMimic支持音频驱动、面部地标驱动以及两者的结合,提供更加灵活的动画生成方式。
- 创新训练策略:采用新颖的训练策略,结合音频和面部地标进行训练,生成的肖像视频更加自然逼真。
- 性能优越:在多个公共和自收集数据集上的全面比较中,EchoMimic在定量和定性评估中均表现出色。
主要功能:
- 生成肖像视频:根据输入的音频和/或面部地标,生成高质量的肖像动画视频。
- 多语言支持:支持中文、英文等多种语言的音频驱动,适用于不同语言场景的动画生成。
- 可视化展示:项目页面提供丰富的可视化示例,包括音频驱动(中文、英文、唱歌)、地标驱动以及音频与选定地标驱动的示例。
- 数据集评估:提供了在HDTF数据集上的视频评估结果,以及第三方提供的视频评估结果链接,方便用户参考其性能表现。
使用示例:
- 音频驱动:输入中文或英文音频,EchoMimic生成相应的肖像动画,口型和表情随音频变化,如中文音频驱动下的自然说话状态。
- 地标驱动:通过选定面部地标(如眼睛、嘴巴),精确控制肖像特定部位的动画效果。
- 音频与选定地标驱动:结合音频和部分地标,生成更加丰富自然的肖像动画,如唱歌场景下的整体表情和嘴巴开合细节。
总结:
EchoMimic是一款功能强大、灵活多样的音频驱动肖像动画生成工具。其创新的训练策略和多驱动方式,使其在多种场景下都能生成高质量、逼真的肖像动画,为用户提供了更多的创作可能性和灵活性。
查看更多
最新文章
2026年三伏天什么时候开始?初伏中伏末伏时间表和注意事项
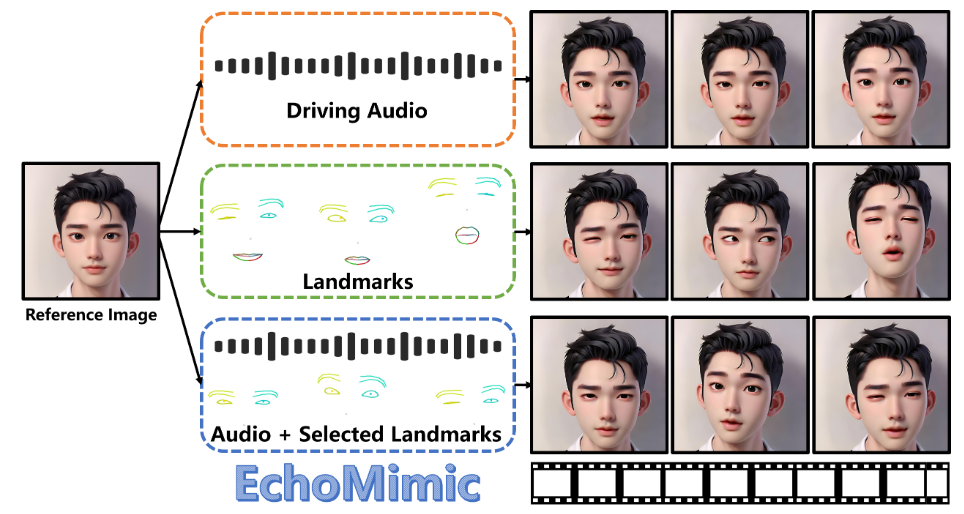
2026年三伏天从7月15日开始,到8月23日结束,共40天。本文整理初伏、中伏、末伏时间表,并说明高温
Linux 服务反复重启怎么办:journalctl 和 RestartSec 排查清单
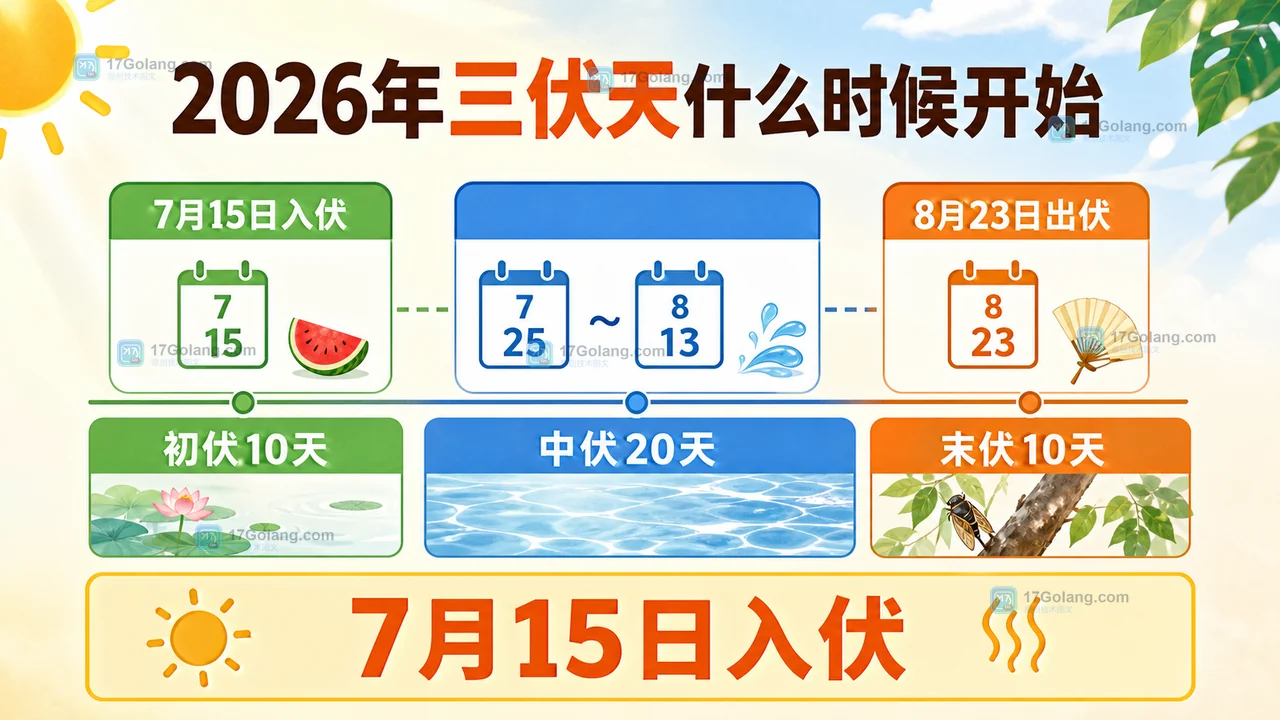
本文用一次 Linux 服务反复重启的现场,讲清楚如何看 status、journalctl、Resta
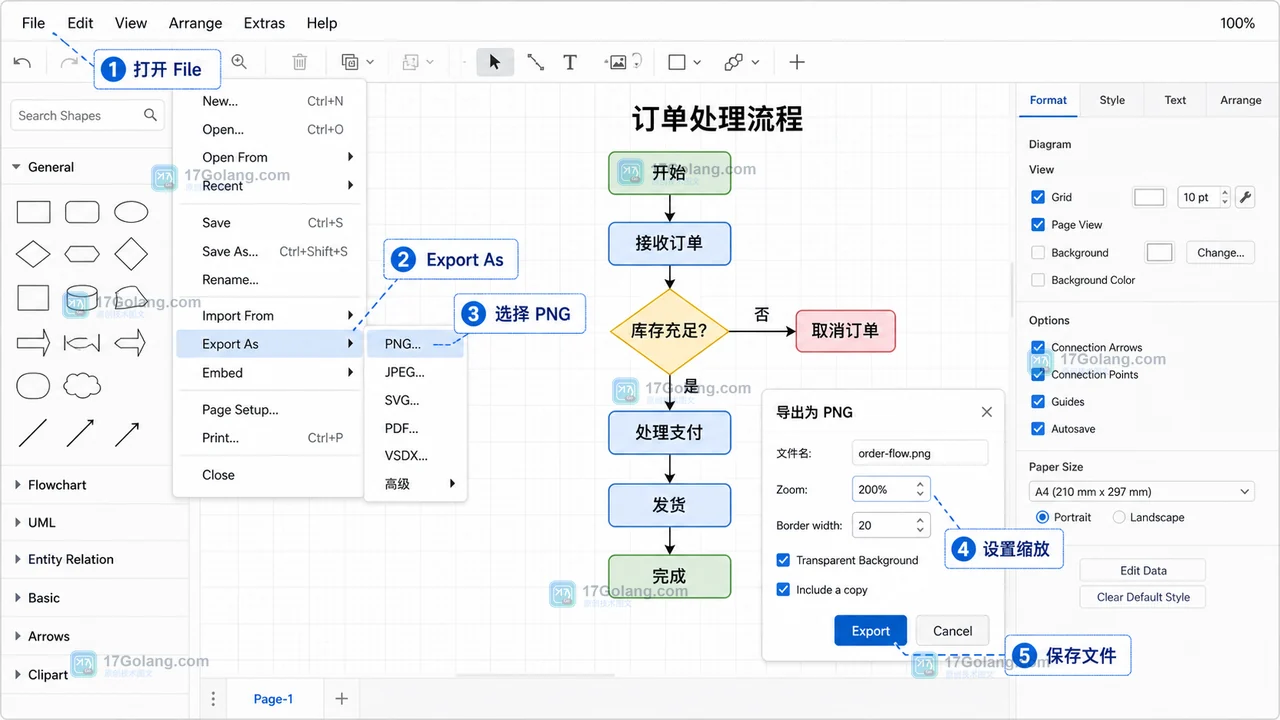
diagrams.net 导出高清 PNG:透明背景、缩放比例和回导核对流程
演示在 diagrams.net 中通过 File > Export As > PNG 导出高清 PNG
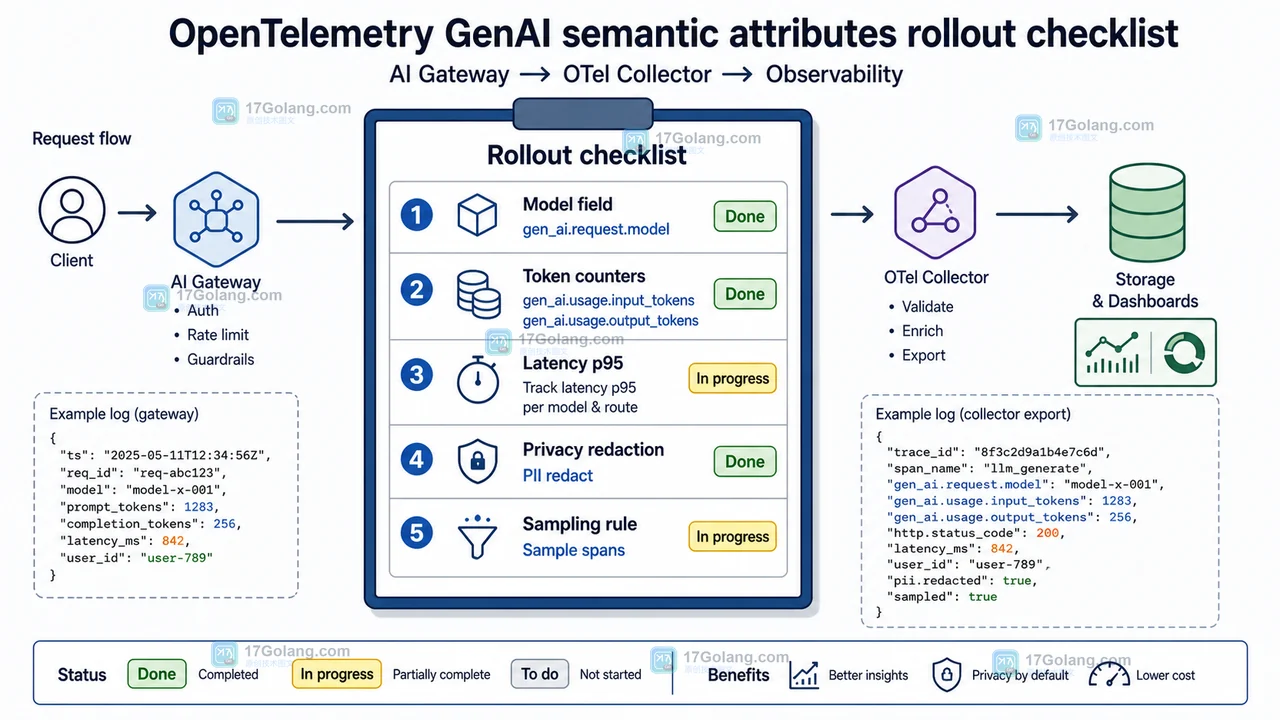
AI 调用可观测架构:从散乱日志到 OpenTelemetry GenAI 字段统一
围绕 AI 调用规模化后的日志散乱、模型字段不统一、token 成本不可见和隐私采集风险,讲解如何用 O
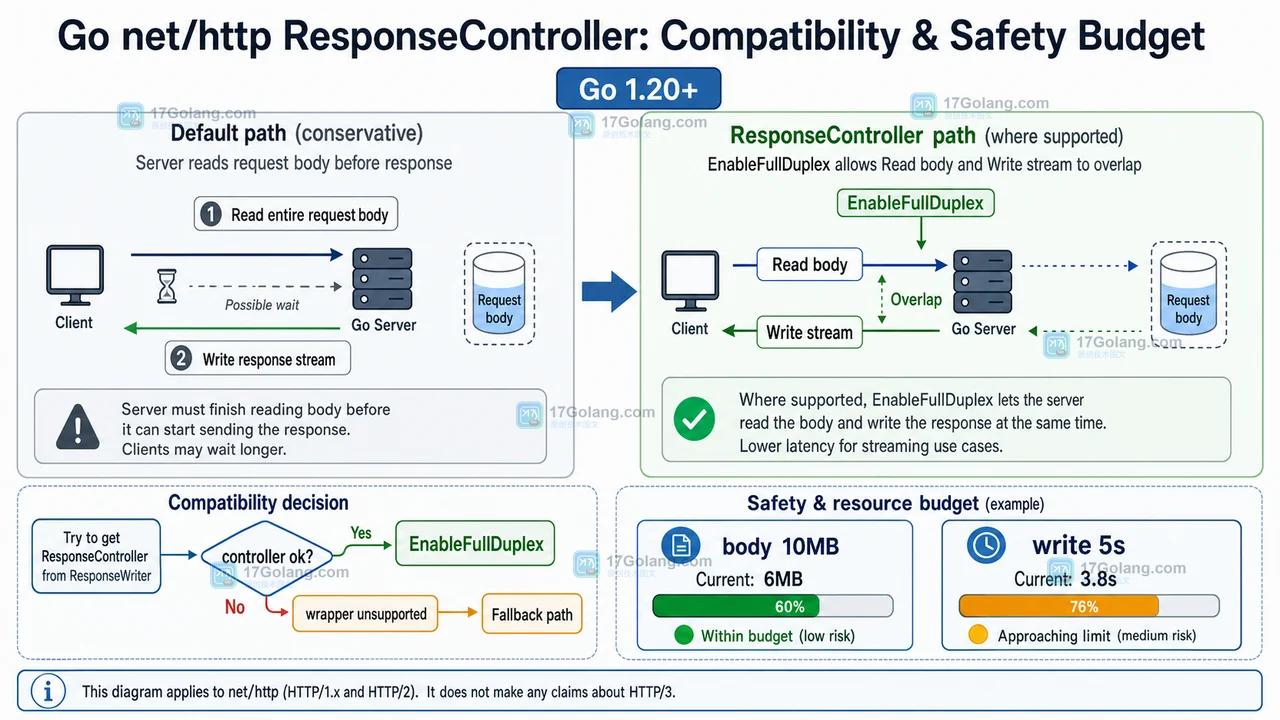
Go http.ResponseController 有什么用?Flush、写超时和 FullDuplex 这样理解
用问答方式解释 Go net/http ResponseController 的定位、Flush、写入

PHP Session 迁移到 Redis:从本机文件到集中存储的回归检查清单
围绕 PHP Session 从本机文件迁移到 Redis 的过程,梳理旧架构风险、配置变更、锁等待、T



