
详细介绍

Phenaki:文本驱动视频生成模型
Phenaki是一款革命性的AI模型,能够根据文本提示生成视频。它不仅支持随时间变化的提示,还能生成长达几分钟的高质量视频,为视频创作提供了全新的可能性。
核心特点:
- 文本到视频生成:通过文本提示生成动态视频,提示可以随时间变化,带来更丰富的表达。
- 长视频支持:能够生成长达几分钟的视频,满足多样化的视频需求。
- 交互式体验:用户可以选择不同的上下文词组合,生成关于宇航员等主题的视频。
- 静态图像转视频:从第一帧图像和文本提示开始,生成完整的视频内容。
主要功能:
- 文本提示序列:通过一系列文本提示生成连贯的视频内容。
- 视频压缩技术:利用因果模型学习视频表示,将视频压缩成小型离散标记,提升处理效率。
- 变长视频处理:采用因果注意力机制,灵活处理不同长度的视频。
- 双向遮蔽变换器:用于从文本生成视频标记,确保视频的连贯性和质量。
使用示例:
- 示例1:生成一个在旧金山海洋中游泳的逼真泰迪熊的视频。
- 示例2:生成一个在海滩上放松的泰迪熊的视频。
- 示例3:生成一个在火星上行走、跳舞、遛狗并观看烟花的宇航员的视频。
总结:
Phenaki模型通过文本提示合成现实感视频,解决了生成视频的计算成本、高质量文本-视频数据量有限以及视频长度可变等挑战。它通过联合训练大量图像-文本对和少量视频-文本示例,实现了超越现有视频数据集的泛化能力。Phenaki是首个研究生成随时间变化提示视频的模型,并且在视频的空间-时间质量和每视频标记数方面超越了文献中使用的每帧基线方法。
查看更多
最新文章
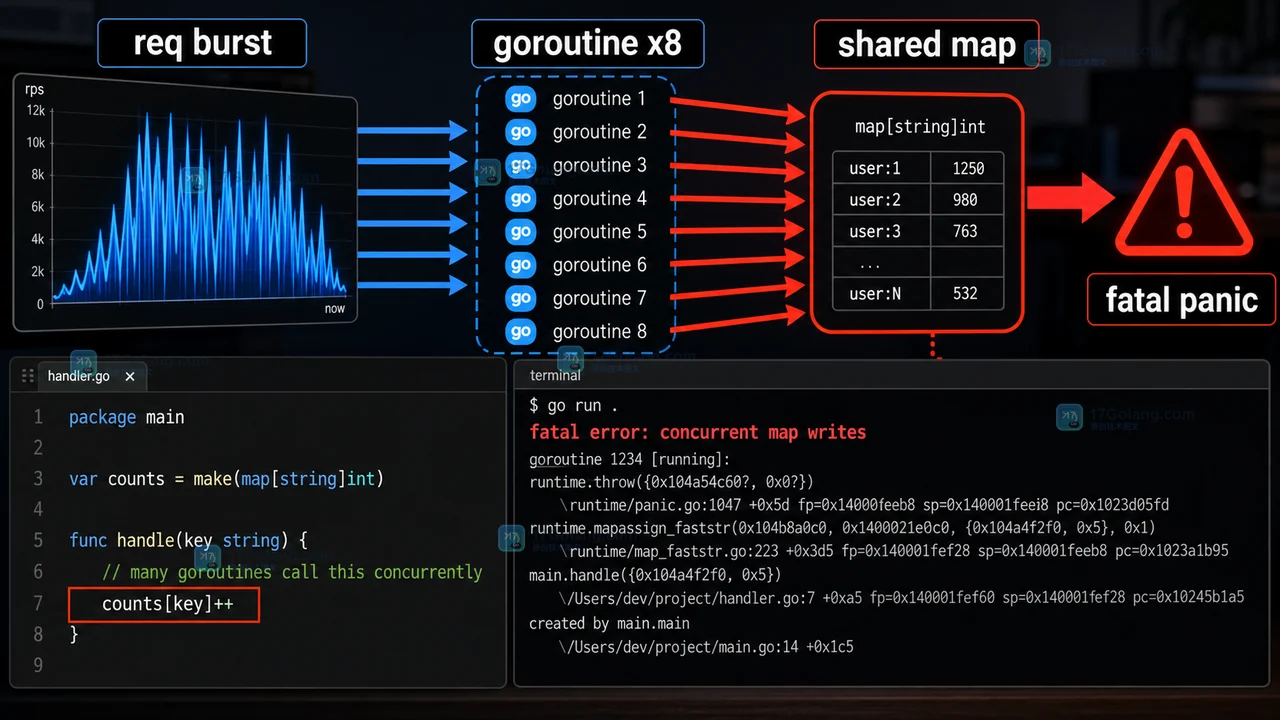
Go map 并发写 panic 怎么办:从共享 map 到可控写入路径
围绕 Go map 并发写 panic,按高并发场景解释为什么共享 map 会崩溃,并给出加锁、分片 m
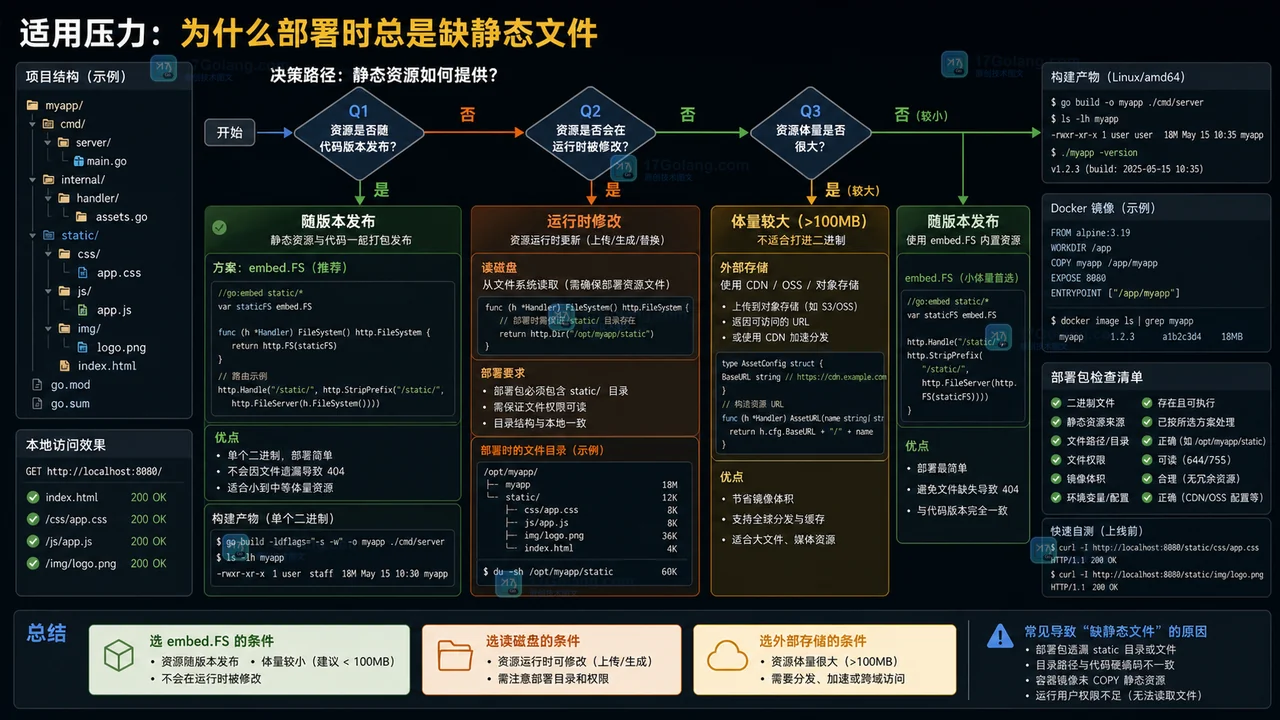
Go embed 静态资源打包模式:模板和前端文件要不要收进二进制?
围绕 Go embed.FS 静态资源打包模式,分析模板、前端文件和配置示例是否适合收进二进制,给出开发

Go Webhook 验签实战:HMAC、时间窗口和重放防护怎么做
以 Go Webhook 接收接口为例,讲清 HMAC 验签为什么要绑定原始 body、时间戳和事件 I
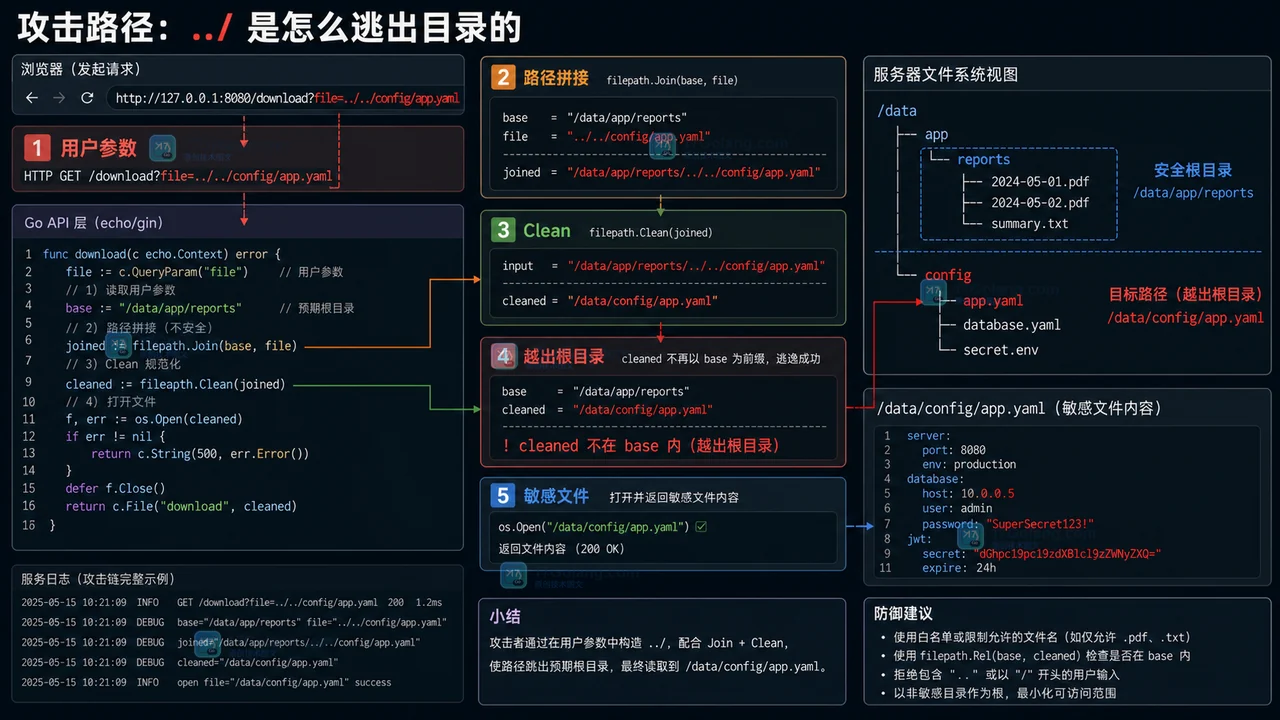
Go 问答:文件下载接口如何防路径穿越,filepath.Clean 够不够?
围绕 Go 文件下载接口的路径穿越风险,解释 filepath.Clean 为什么不等于安全校验,并给出
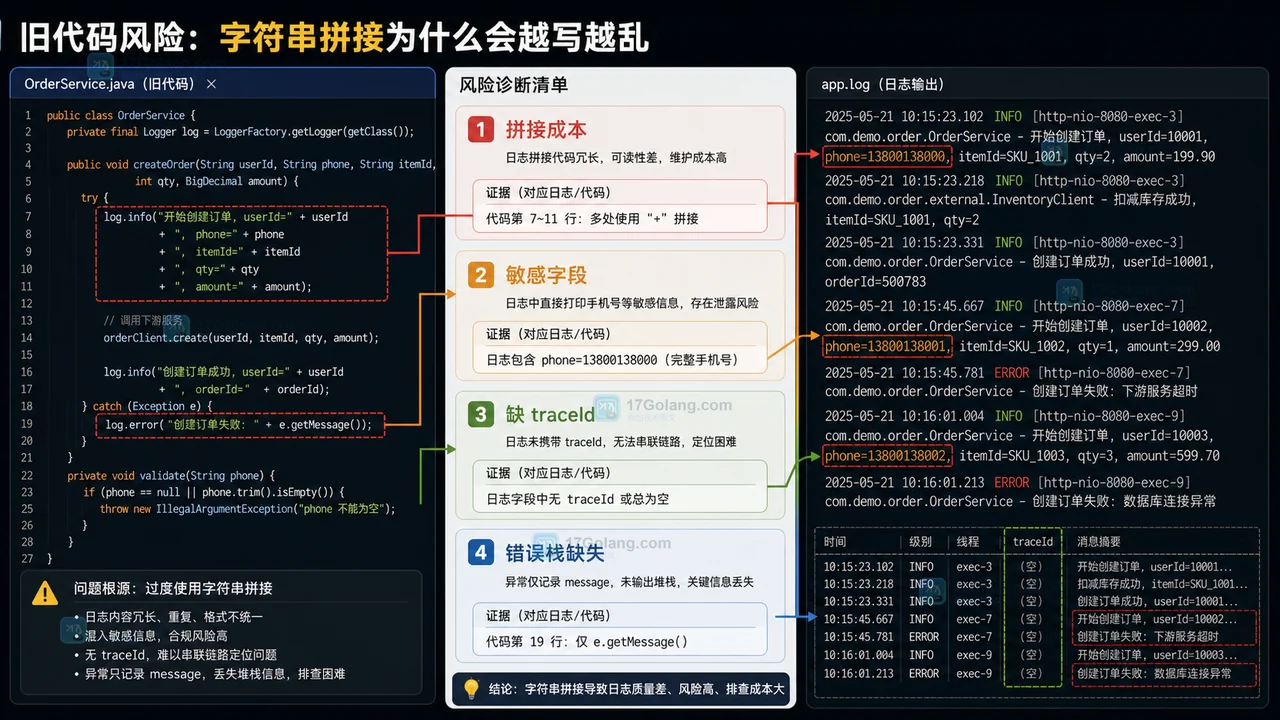
Java 日志迁移变更单:从字符串拼接到参数化日志和 MDC traceId
围绕 Java 老项目日志迁移,说明如何从字符串拼接改成 SLF4J 参数化日志,并补上 MDC tra

PHP 老接口迁移变更单:从散落 $_POST 到 Request DTO 与统一错误响应
以 PHP 老接口迁移为例,把散落的 $_POST 读取改成 Request DTO、集中校验和统一错误



