
详细介绍

Vary-toy:小型视觉语言模型,开启视觉AI新时代
Vary-toy是由MEGVII Technology、中国科学院大学和华中科技大学的研究人员共同开发的一款小型视觉语言模型(LVLM)。它专为资源有限的研究者和开发者设计,旨在解决大型视觉语言模型在训练和部署上的挑战。
核心优势:
- 小尺寸,大能量:Vary-toy体积小巧,适合在消费级GPU上进行训练和部署,让更多研究者能够轻松上手。
- 功能全面,应用广泛:尽管尺寸小,Vary-toy却具备与大型模型相媲美的功能,如文档OCR、图像描述、视觉问答等,满足多样化的需求。
- 视觉词汇网络优化:通过改进的视觉词汇网络,Vary-toy能够更高效地编码自然物体的视觉信息,提升模型的理解能力。
强大功能:
- 文档级光学字符识别(OCR):精准识别文档中的文字,并可转换为Markdown格式,提升文档处理效率。
- 图像描述:自动生成对图像内容的详细描述,帮助用户快速理解图像信息。
- 视觉问答(VQA):与图像内容相关的问答互动,提供智能的视觉理解和回答。
- 对象检测:识别并定位图像中的各个对象,应用于多种场景。
- 图像到文本的转换:将图像内容转换为文本,方便信息提取和处理。
- 多模态对话:支持与用户进行自然的多模态对话,增强用户体验。
应用场景:
- 对象检测:
- 用户上传图片,Vary-toy能够快速识别并标注图中的各个对象,适用于图像分析和数据标注。
- OCR图像转文本/Markdown:
- 用户上传PDF图像,Vary-toy提供精准的OCR结果,并可转换为易于编辑的Markdown格式,提升文档处理效率。
- 日常对话:
- 用户与Vary-toy进行日常对话,模型能够理解图像内容并生成相关对话,增强人机交互体验。
总结:
Vary-toy作为一款小型但功能强大的视觉语言模型,为资源有限的研究者和开发者提供了先进的视觉语言模型功能。通过改进的视觉词汇网络和多任务预训练策略,Vary-toy在保持小尺寸的同时,展现出处理复杂视觉语言任务的强大能力。无论是文档处理、图像分析还是多模态对话,Vary-toy都能为您带来高效、便捷的解决方案。
查看更多
最新文章
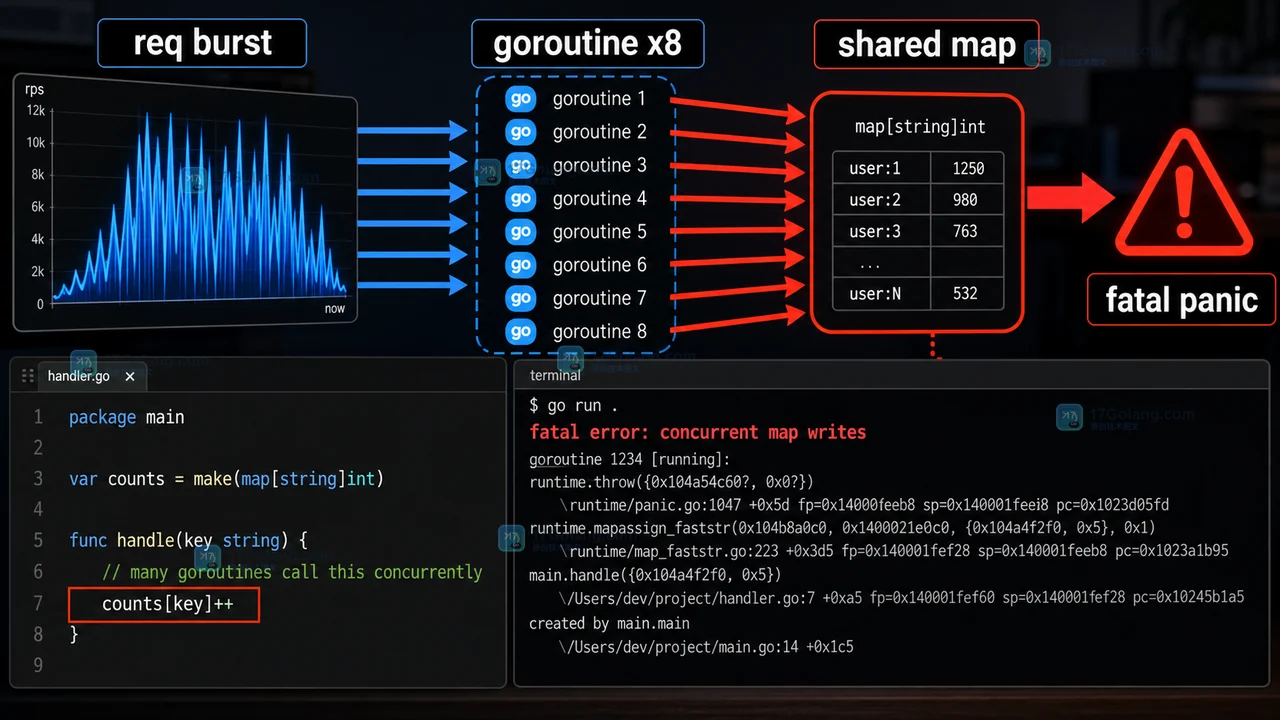
Go map 并发写 panic 怎么办:从共享 map 到可控写入路径
围绕 Go map 并发写 panic,按高并发场景解释为什么共享 map 会崩溃,并给出加锁、分片 m
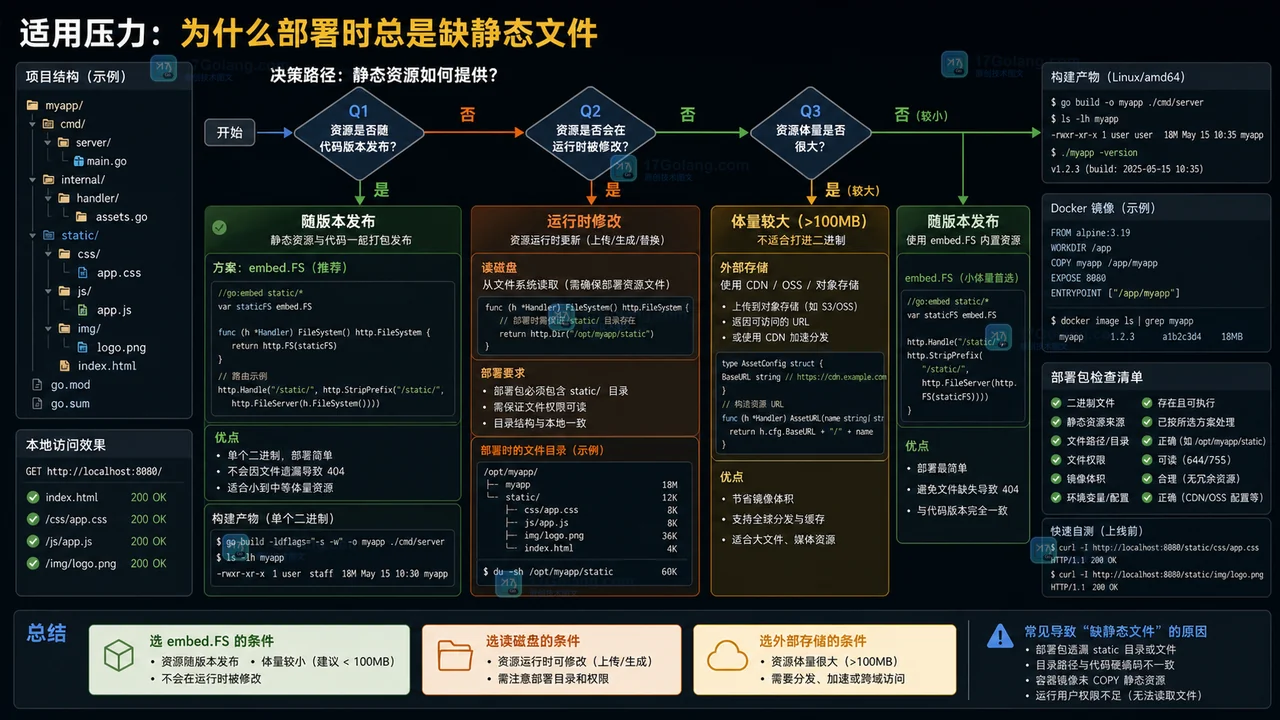
Go embed 静态资源打包模式:模板和前端文件要不要收进二进制?
围绕 Go embed.FS 静态资源打包模式,分析模板、前端文件和配置示例是否适合收进二进制,给出开发

Go Webhook 验签实战:HMAC、时间窗口和重放防护怎么做
以 Go Webhook 接收接口为例,讲清 HMAC 验签为什么要绑定原始 body、时间戳和事件 I
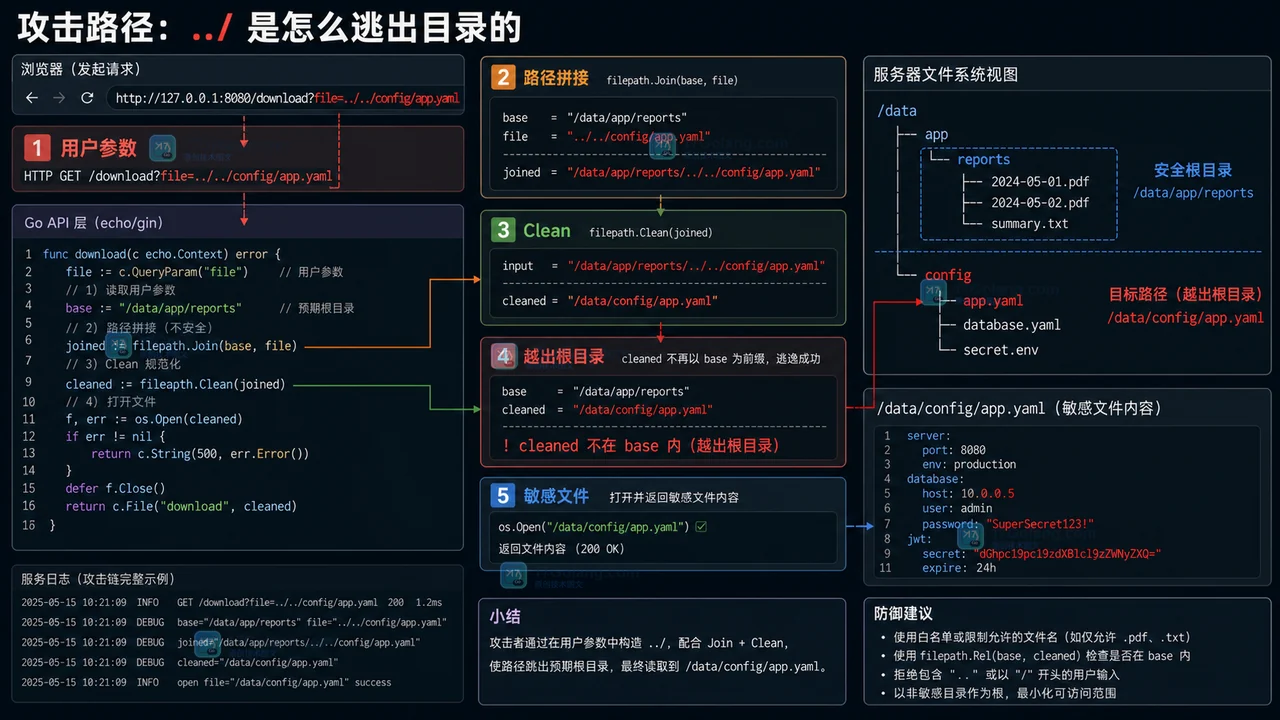
Go 问答:文件下载接口如何防路径穿越,filepath.Clean 够不够?
围绕 Go 文件下载接口的路径穿越风险,解释 filepath.Clean 为什么不等于安全校验,并给出
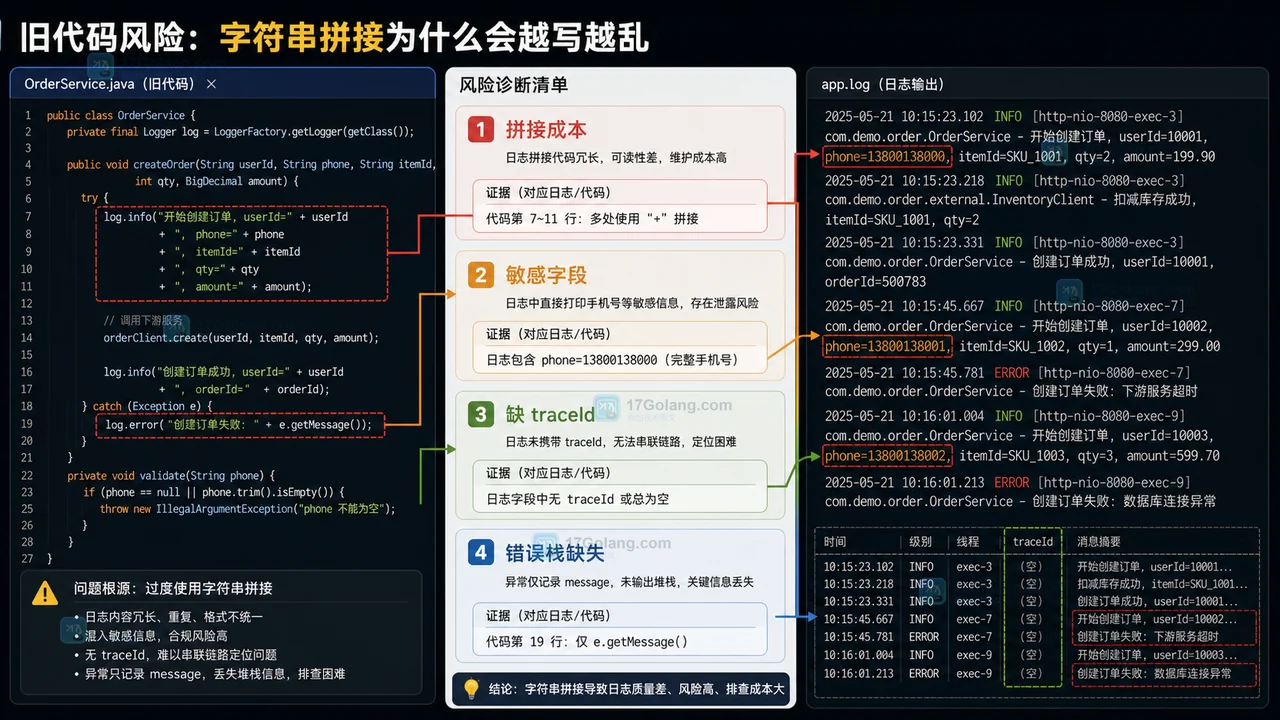
Java 日志迁移变更单:从字符串拼接到参数化日志和 MDC traceId
围绕 Java 老项目日志迁移,说明如何从字符串拼接改成 SLF4J 参数化日志,并补上 MDC tra

PHP 老接口迁移变更单:从散落 $_POST 到 Request DTO 与统一错误响应
以 PHP 老接口迁移为例,把散落的 $_POST 读取改成 Request DTO、集中校验和统一错误



