详细介绍
MinerU:高效PDF内容提取工具,助力多领域信息处理
MinerU是一款功能强大的PDF内容提取工具,旨在帮助用户从PDF文档中高效提取高质量内容。无论您是从事学术研究、法律工作、技术文档管理,还是知识管理和数据挖掘,MinerU都能为您提供强大的支持。
主要功能:
- PDF到Markdown转换:轻松将多种内容类型的PDF文档转换为结构化的Markdown格式,方便后续编辑和分析。
- 多模态内容处理:支持识别和处理PDF中的图像、公式、表格和文本,确保全面提取。
- 结构和格式保留:在转换过程中,保留原始文档的结构和格式,如标题、段落和列表,保证信息的完整性。
- 公式识别与转换:特别针对数学公式,识别并转换成LaTeX格式,适用于学术和技术文档。
- 干扰元素去除:自动删除页眉、页脚、脚注和页码等非内容元素,净化文档信息。
- 乱码识别与处理:自动识别并纠正PDF文档中的乱码,提高信息提取的准确性。
- 高质量解析工具链:集成先进的PDF解析工具,包括布局检测、公式检测和光学字符识别(OCR),确保提取结果的高准确度。
技术原理:
- PDF文档分类预处理:MinerU首先对文档进行分类,识别其类型并进行相应的预处理。
- 模型解析与内容提取:利用深度学习模型进行布局检测、公式检测和识别,以及OCR技术进行文本识别。
- 管线处理:将解析得到的数据进行后处理,包括块级顺序确定、删除无用元素、内容排序和拼装等。
- 多种格式输出:处理后的文档信息可以转换为多种格式,如Markdown、Layout、Span等。
- PDF提取结果质检:通过人工标注和可视化质检工具进行检测和反馈,确保提取效果的持续优化。
应用场景:
- 学术研究:从学术论文中提取关键信息,支持文献综述和数据分析。
- 法律文档处理:从合同和法律文件中提取条款和证据,提高工作效率。
- 技术文档管理:从技术手册中提取技术规格和操作步骤,方便知识管理。
- 知识管理和信息检索:从内部文档库中提取信息,构建知识库,提高信息检索效率。
- 数据挖掘和自然语言处理:利用提取的数据来训练和优化机器学习模型。
总结:
MinerU通过其强大的功能和先进的技术原理,为用户提供高效、准确的PDF内容提取服务。无论您在哪个领域工作,MinerU都能帮助您提高工作效率和信息处理质量。
查看更多
最新文章
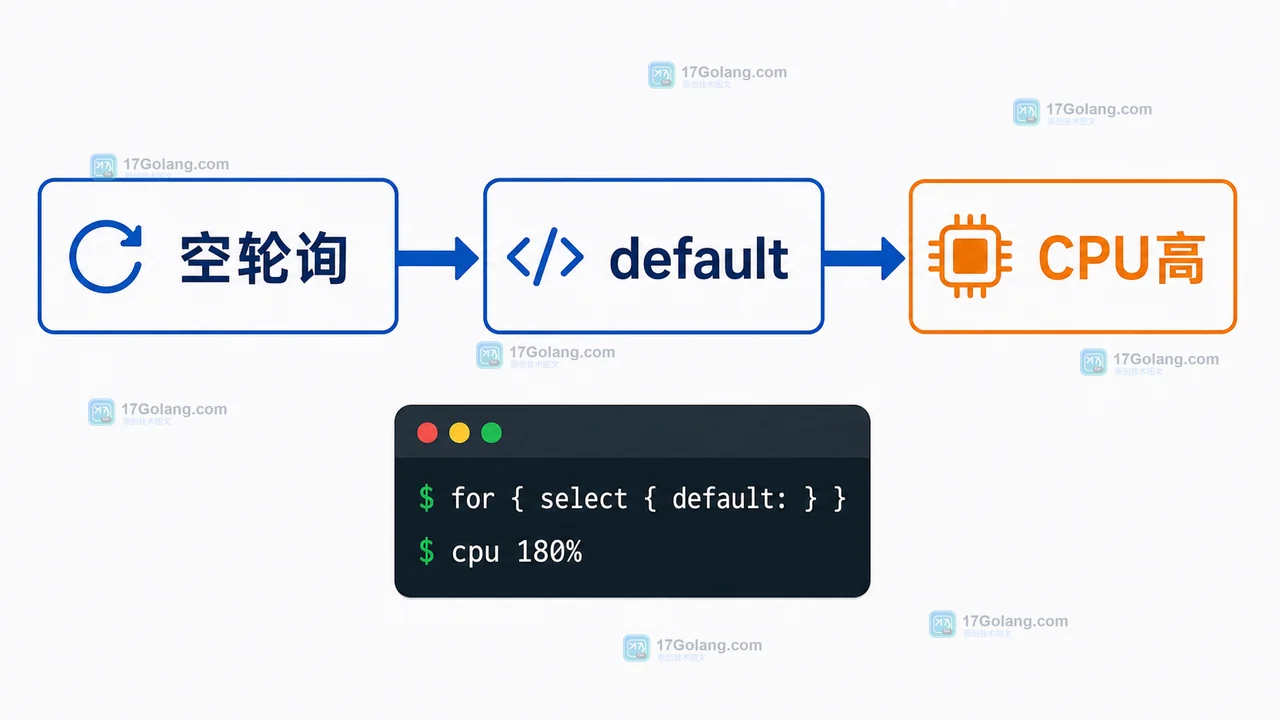
Go select 里的 default 为什么会让 CPU 飙高:忙等循环怎么改
Go select 里的 default 会在没有 channel 就绪时立即返回;如果外层套着无限 f

空调开26度还是热怎么办?先看湿度风向和房间热源
空调开26度仍觉得热,通常不是温度数字本身的问题,还要看湿度、风向、阳光直晒、滤网灰尘和房间热源。先降温
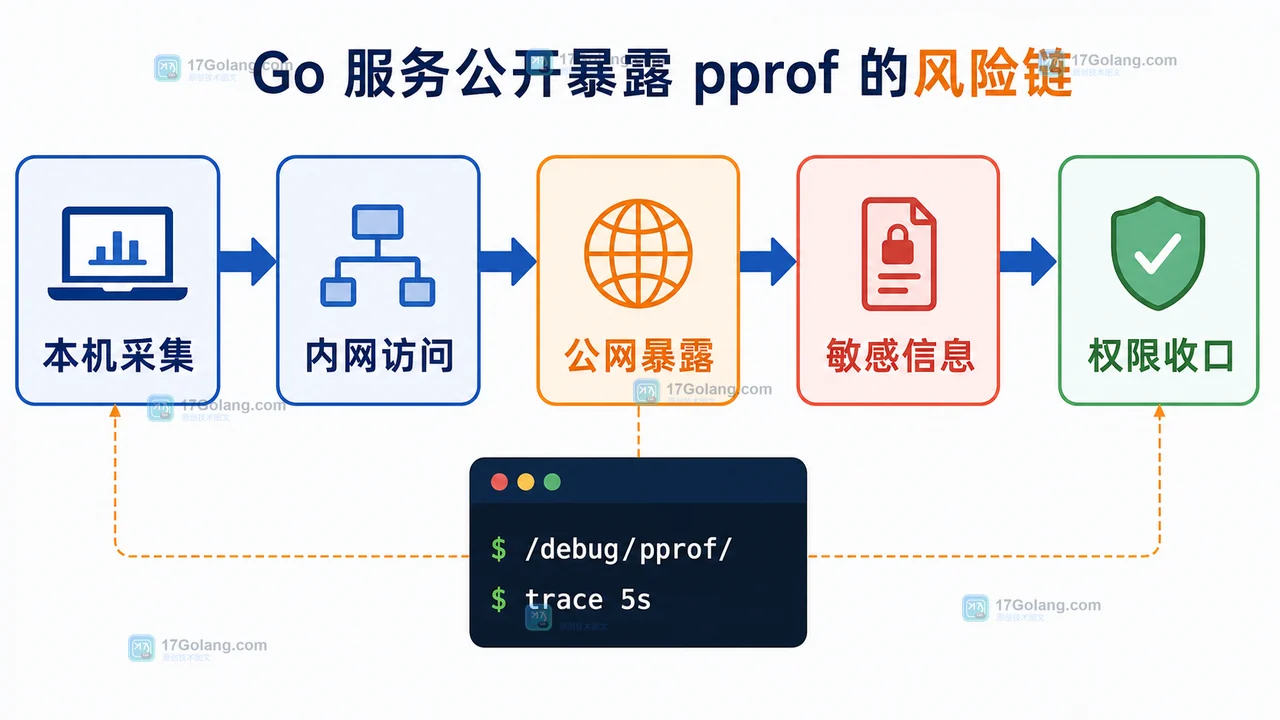
Go 服务的 pprof 能直接暴露公网吗?排障入口上线前的安全判断
Go 服务不建议把 /debug/pprof/ 直接暴露到公网。pprof 和 trace 能帮助排障,
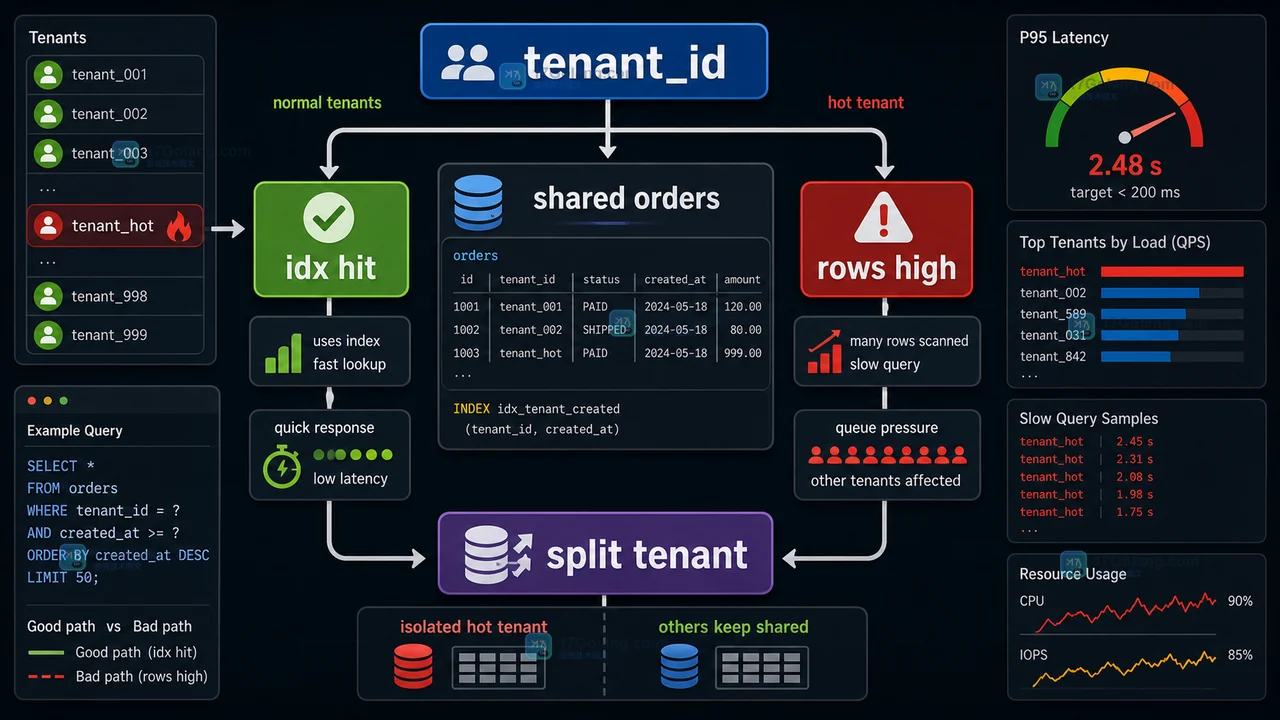
MySQL 多租户订单表架构演进:从 tenant_id 联合索引到租户分片
MySQL 多租户订单表变慢时,先用 tenant_id 领头的联合索引稳住常见查询;当热点租户持续拉高
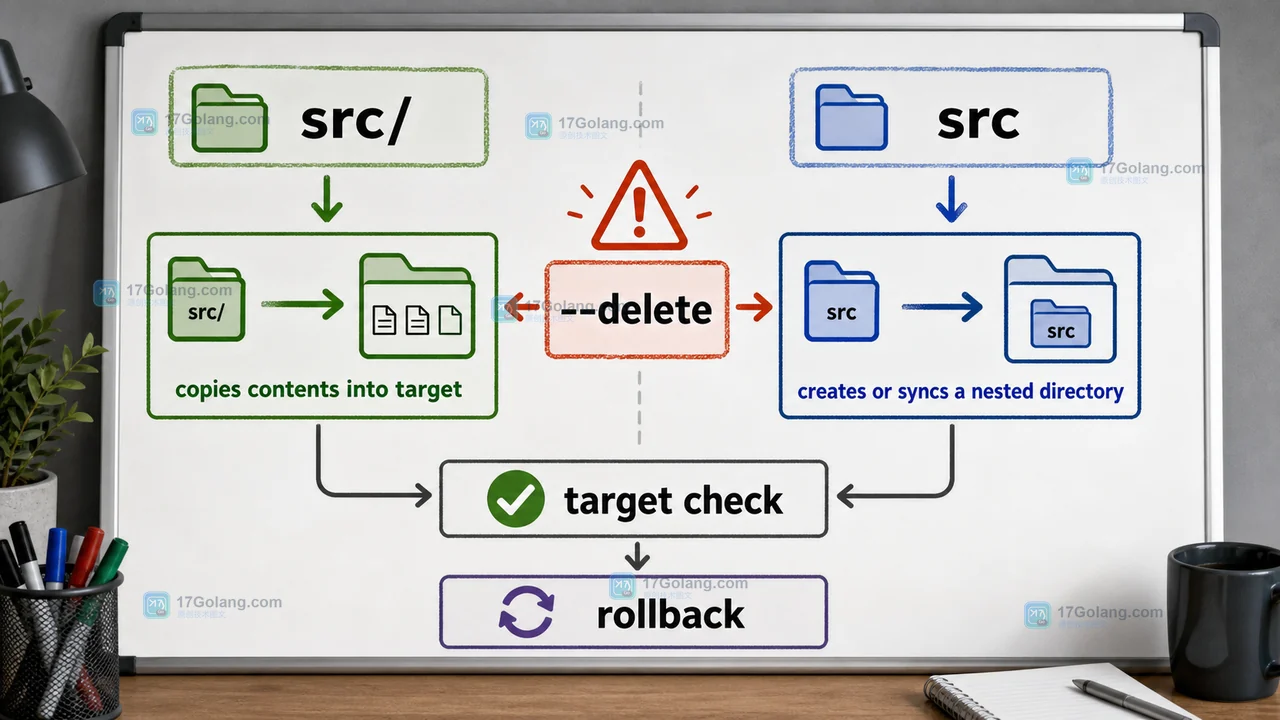
Linux rsync 同步目录如何排除文件并保留权限?安全命令配方
Linux 用 rsync 同步目录时,建议先用 dry-run 预览,再用 -a 保留权限、时间和软链
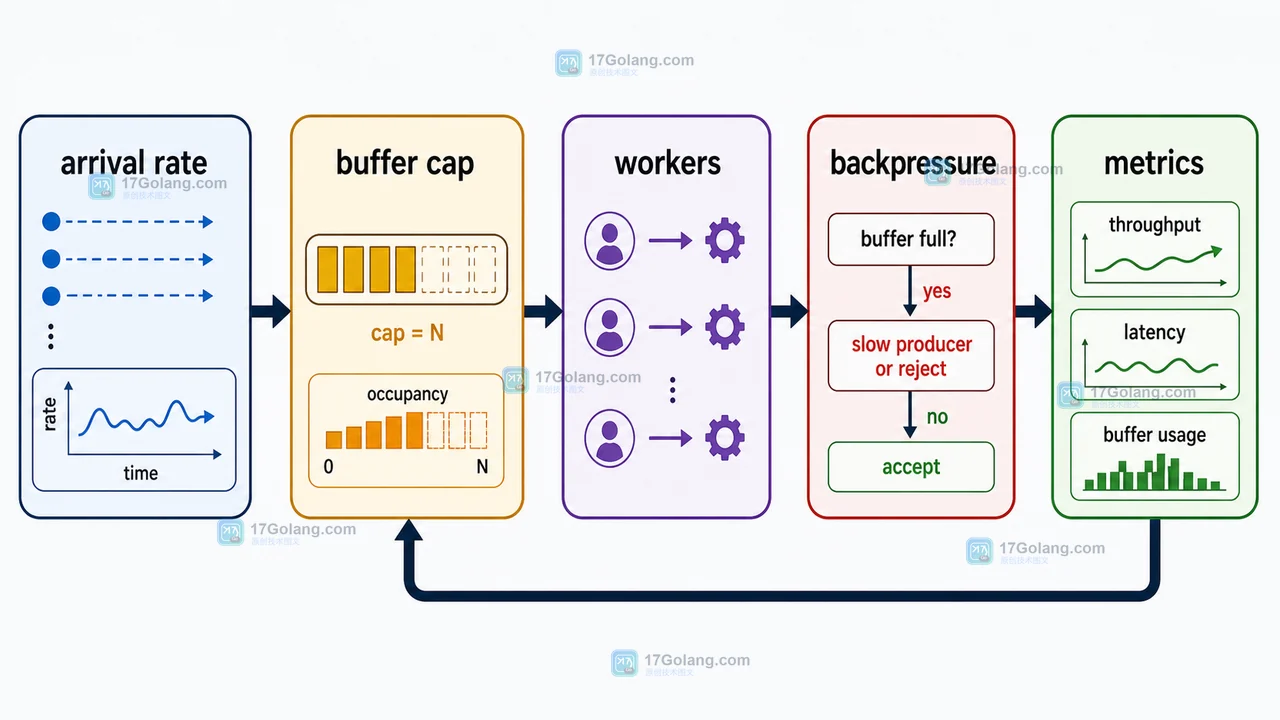
Go channel 缓冲区是不是越大越好?容量要按吞吐和延迟定
Go channel 缓冲区不是越大越好。容量越大只能延后阻塞,不能提升消费者处理能力;高并发场景要按到



