
详细介绍
scikit-learn是Python生态系统中一个功能强大且广泛使用的机器学习库。它提供了简单高效的工具,用于数据挖掘和数据分析,支持包括分类、回归、聚类、降维等多种机器学习算法。
scikit-learn的主要特点:
- 易用性: scikit-learn设计简洁,易于上手,适合初学者和专业人士。
- 丰富的算法: 包含多种机器学习算法,如支持向量机(SVM)、随机森林、K-means聚类等。
- 数据预处理: 提供数据标准化、归一化、特征选择等多种预处理工具。
- 模型评估: 支持交叉验证、网格搜索等多种模型评估和优化方法。
应用场景:
- 数据科学: 用于数据探索、特征工程和模型训练。
- 机器学习项目: 从学术研究到工业应用,scikit-learn在各领域均有广泛应用。
- 教育培训: 许多大学和在线课程使用scikit-learn作为教学工具。
如何使用scikit-learn:
scikit-learn的使用非常直观。您可以轻松地导入库,使用其API进行数据加载、预处理、模型训练和评估。例如:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 加载数据
iris = datasets.load_iris()
X, y = iris.data, iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练模型
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
# 预测并评估模型
y_pred = clf.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))通过scikit-learn,您可以快速构建并部署机器学习模型,提升数据分析和预测能力。无论您是初学者还是专业人士,scikit-learn都是您进行机器学习研究和应用的理想选择。
查看更多
最新文章
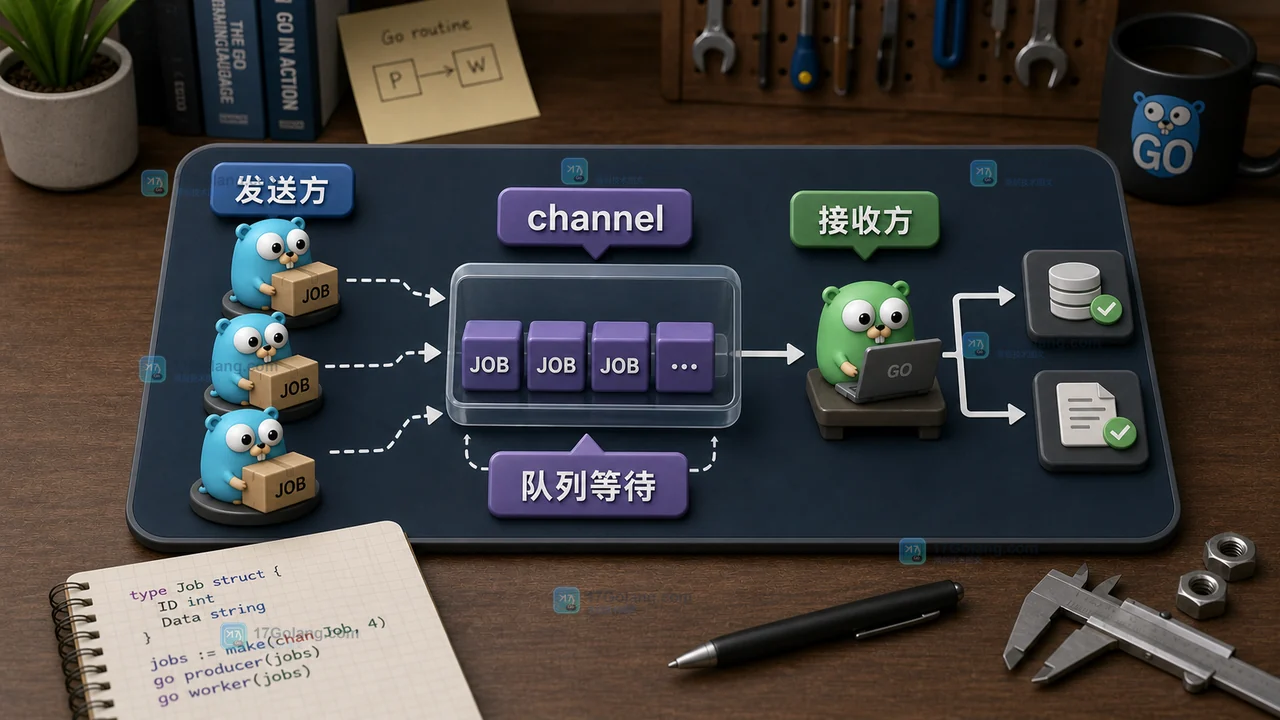
Go Mutex 和 channel 哪个性能更好:共享变量、任务交接和等待链怎么选
Go 里 Mutex 和 channel 不是谁绝对更快。保护一个共享变量时,Mutex 往往更直接;交

RAG 应用答错怎么复盘:检索命中、证据门禁和评测样本怎么补
RAG 应用答错时,不要只怪模型。更常见的根因在检索层:切片不合适、召回证据偏题、排序没过滤、回答没有引

AI Agent 工具调用怎么落地:权限闸门、审批链路和上线观察指标
AI Agent 真正接入业务系统时,难点不在能不能调用工具,而在权限闸门、人工审批、参数校验、审计回放
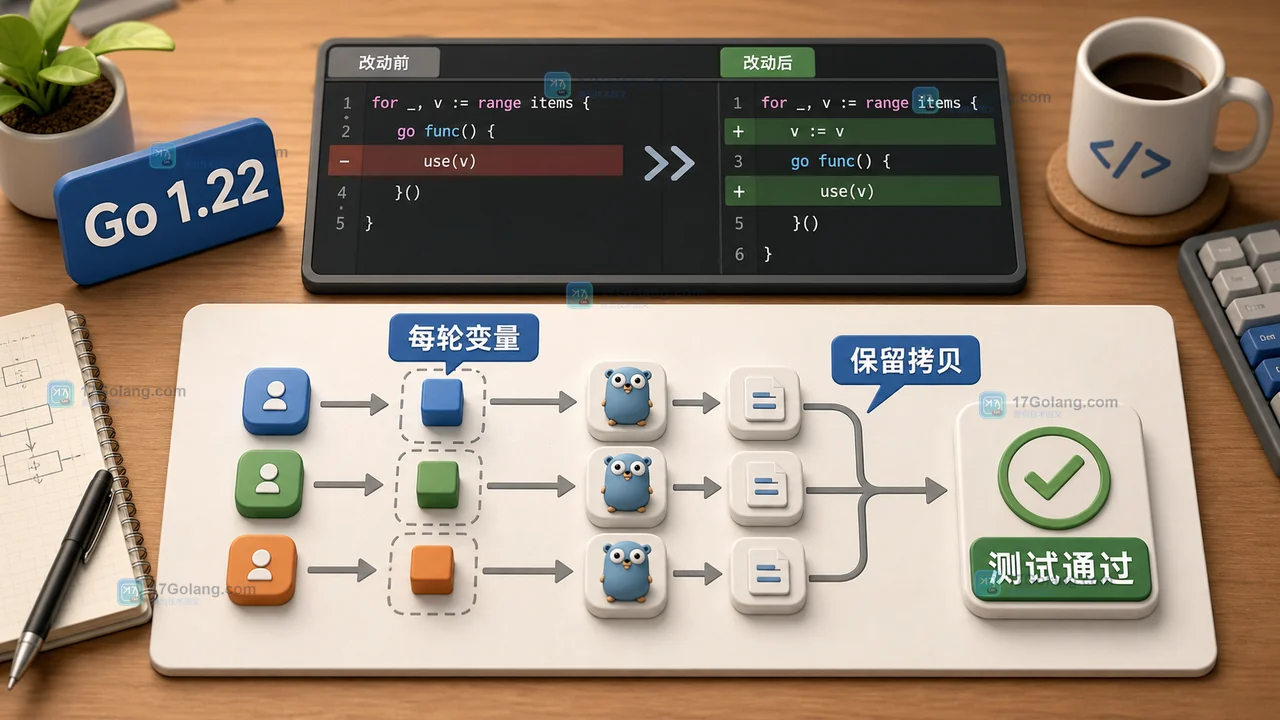
Go 1.22 循环变量升级:闭包、goroutine 和测试回归怎么处理
Go 1.22 调整了 for 循环变量的作用域,新模块里每轮循环会有自己的变量副本,能减少闭包和 go
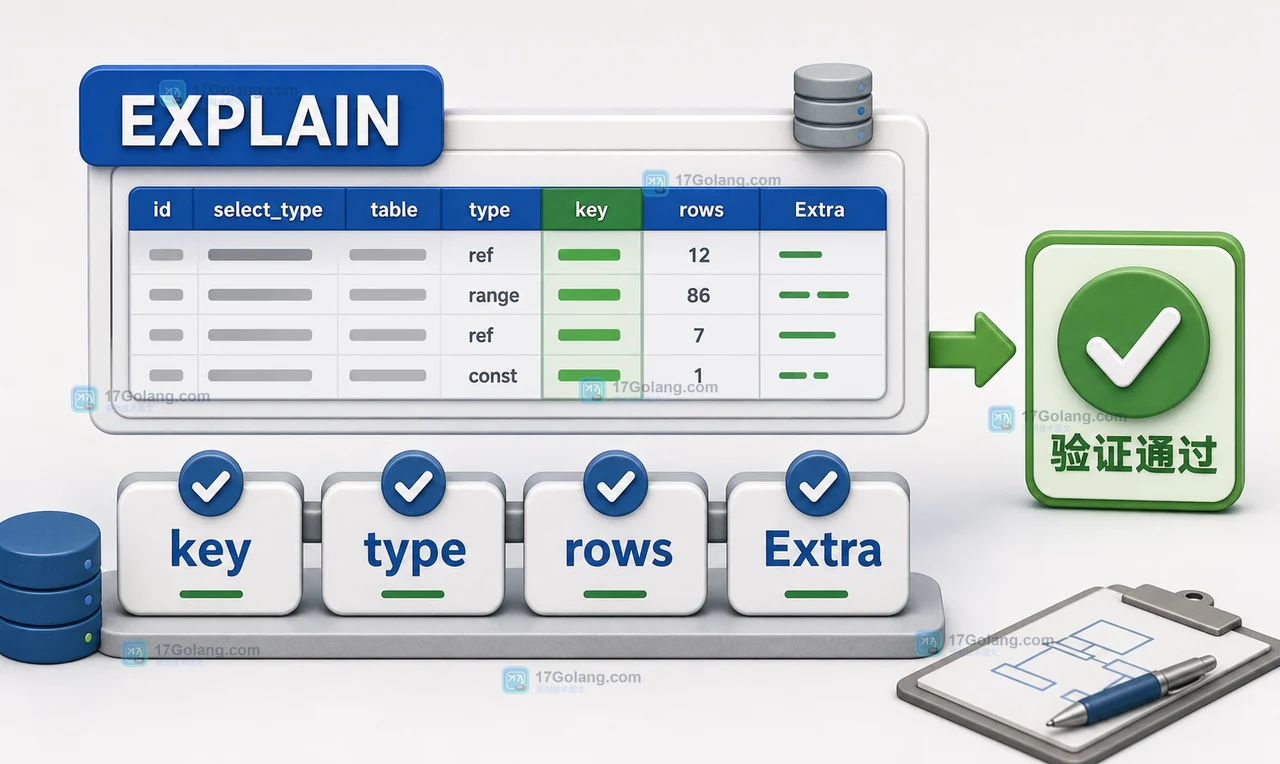
MySQL 查询为什么不走索引:函数列、隐式转换和范围条件怎么改
MySQL 查询不走索引,常见原因不是索引不存在,而是 SQL 写法让优化器难以利用索引。函数包列、隐式
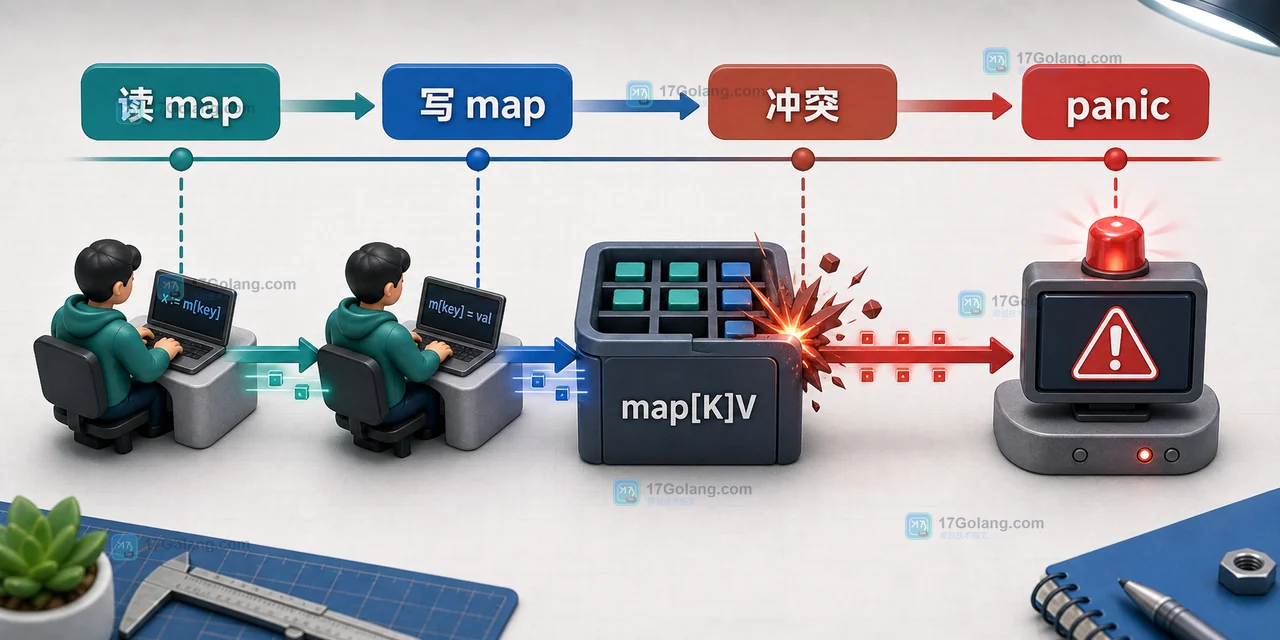
Go map 并发读写为什么会 panic:加锁、单协程和 sync.Map 怎么选
Go 原生 map 不是并发安全容器,只要一个 goroutine 写 map,同时另一个 gorout



