
详细介绍
RapidMiner:让数据科学触手可及的企业AI平台
RapidMiner 是由多特蒙德大学数据科学项目于2001年创立的企业就绪的数据科学平台,旨在让数据分析变得简单、可扩展、受监管和安全。通过Altair的收购,RapidMiner与Altair共享相同的愿景,致力于让数据分析对所有用户都易于使用,同时为企业提供强大的解决方案。
核心优势:
- 人人适用的数据科学: RapidMiner不仅为每个人提供一些东西,而是为每个人提供一切,实现数据科学的团队协作。
- 企业级解决方案: 平台设计能够放大企业的人员、专业知识和数据的集体影响,帮助企业获得突破性的竞争优势。
- 学术根源与创新: 忠于学术根源的同时,不断创新和发展,致力于重塑企业AI,使每个人都能积极塑造未来。
主要功能:
- 数据准备与清洗: 简化数据预处理过程,确保数据质量。
- 机器学习与建模: 提供丰富的算法和模型,满足各种数据分析需求。
- 可视化与报告: 通过直观的图表和报告,帮助用户理解数据洞察。
- 自动化与部署: 支持自动化流程和模型部署,提高工作效率。
应用场景:
- 企业数据分析: 帮助企业利用数据科学提升运营效率和决策质量。
- 团队协作: 促进团队成员之间的协作,共同推进数据科学项目。
- 学术研究: 为学术机构提供强大的数据分析工具,支持科研创新。
总结:
RapidMiner 通过与 Altair 的合作,进一步推动数据分析的民主化,让每个人都能参与到数据科学的过程中来。无论您是企业用户、数据科学家还是学术研究者,RapidMiner 都能为您提供强大的工具和支持,助力您在数据驱动的世界中取得成功。
查看更多
最新文章
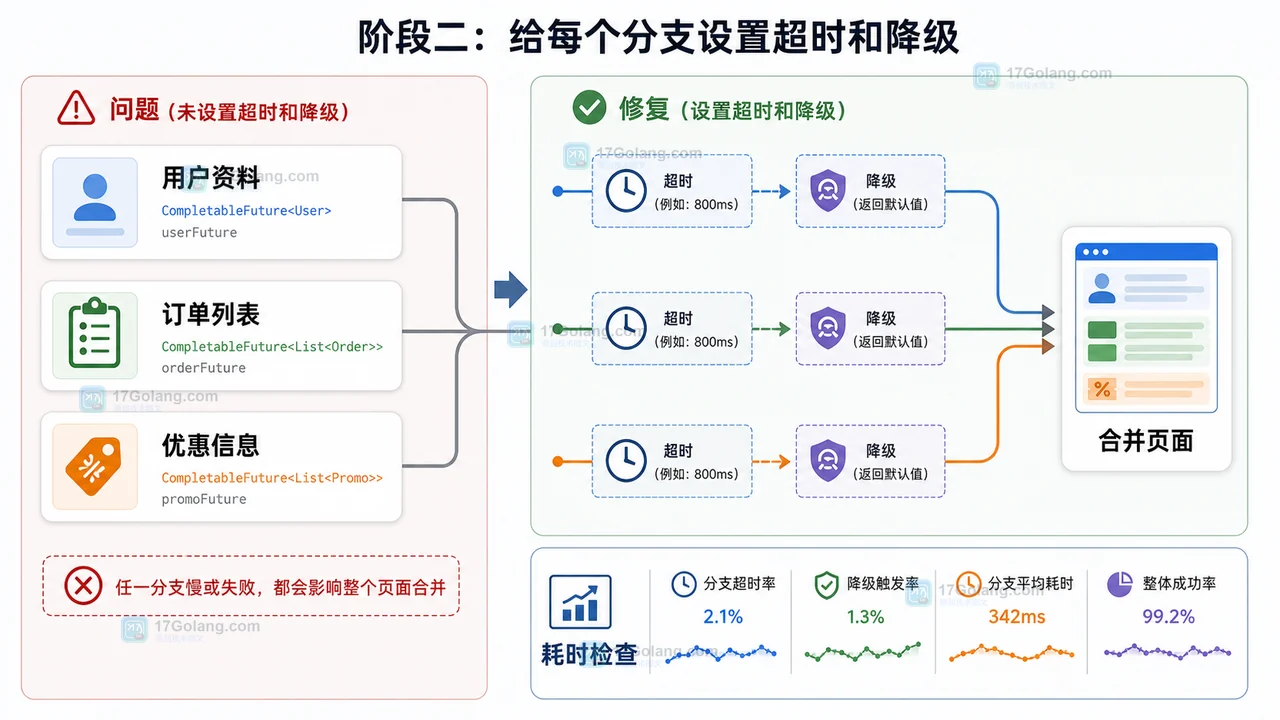
Java CompletableFuture 接口聚合工作流:从超时边界到降级返回
本文用一个用户首页聚合场景,梳理 Java CompletableFuture 的并发拉取、超时边界、异
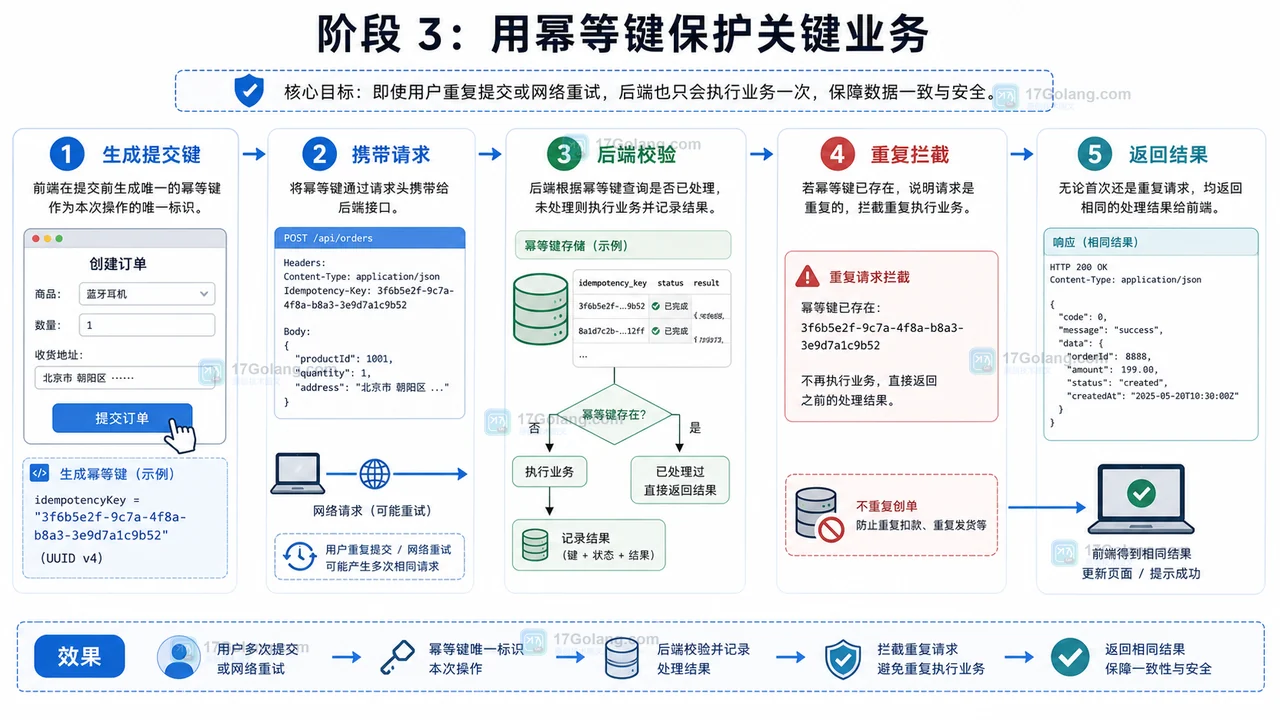
前端表单重复提交防护工作流:从按钮状态到请求取消和幂等键
本文整理一套前端表单重复提交防护工作流,从按钮状态、加载提示、请求取消、幂等键、错误恢复到复查指标,帮助
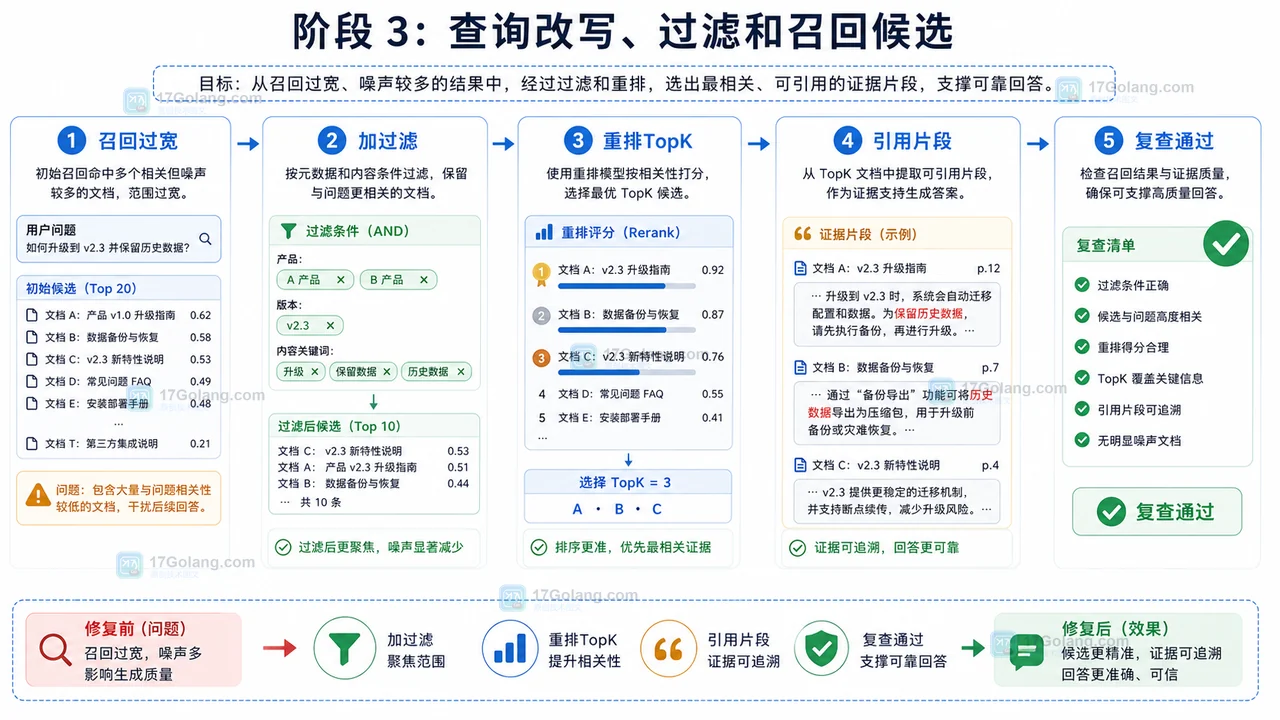
AI 知识库检索召回工作流:从文档切分到重排和证据引用
本文整理一套 AI 知识库检索召回工作流,从文档清洗、切分、向量入库、查询改写、过滤重排到证据引用和复查
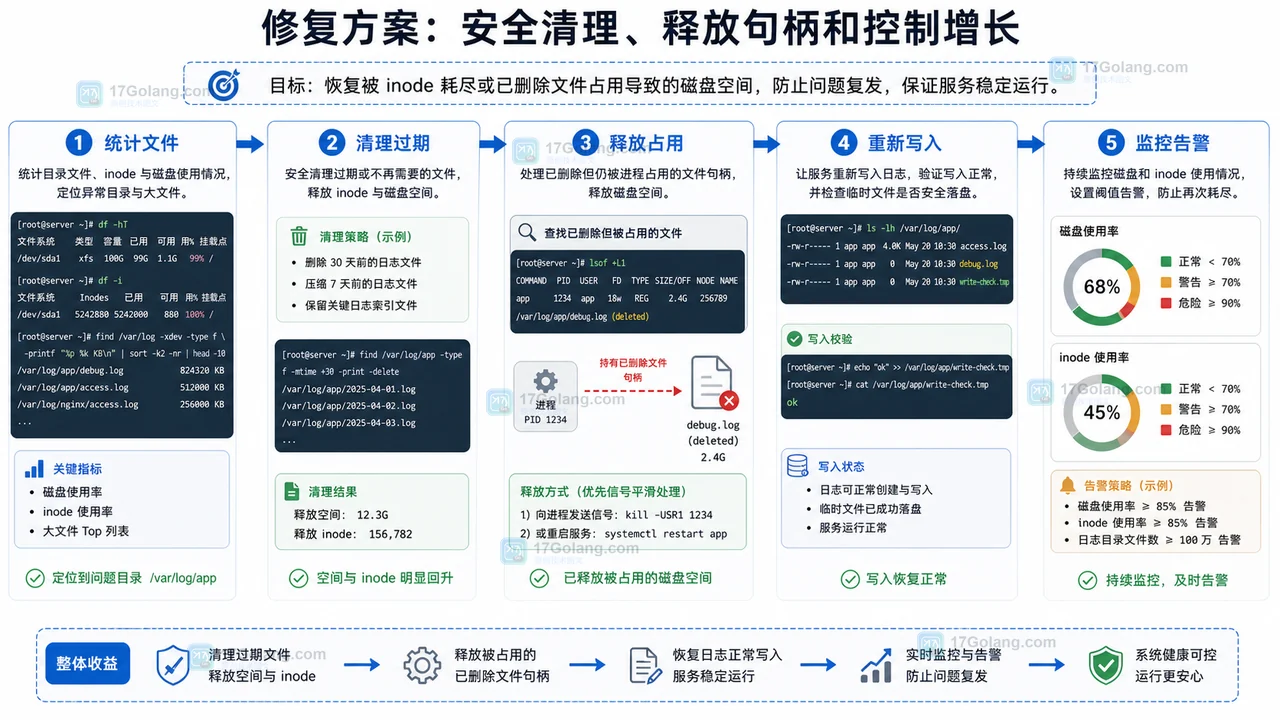
Linux 磁盘还有空间却写入失败排查:从 inode 到已删除文件占用
本文从 Linux 写文件提示 No space left on device 但 df -h 仍有空间
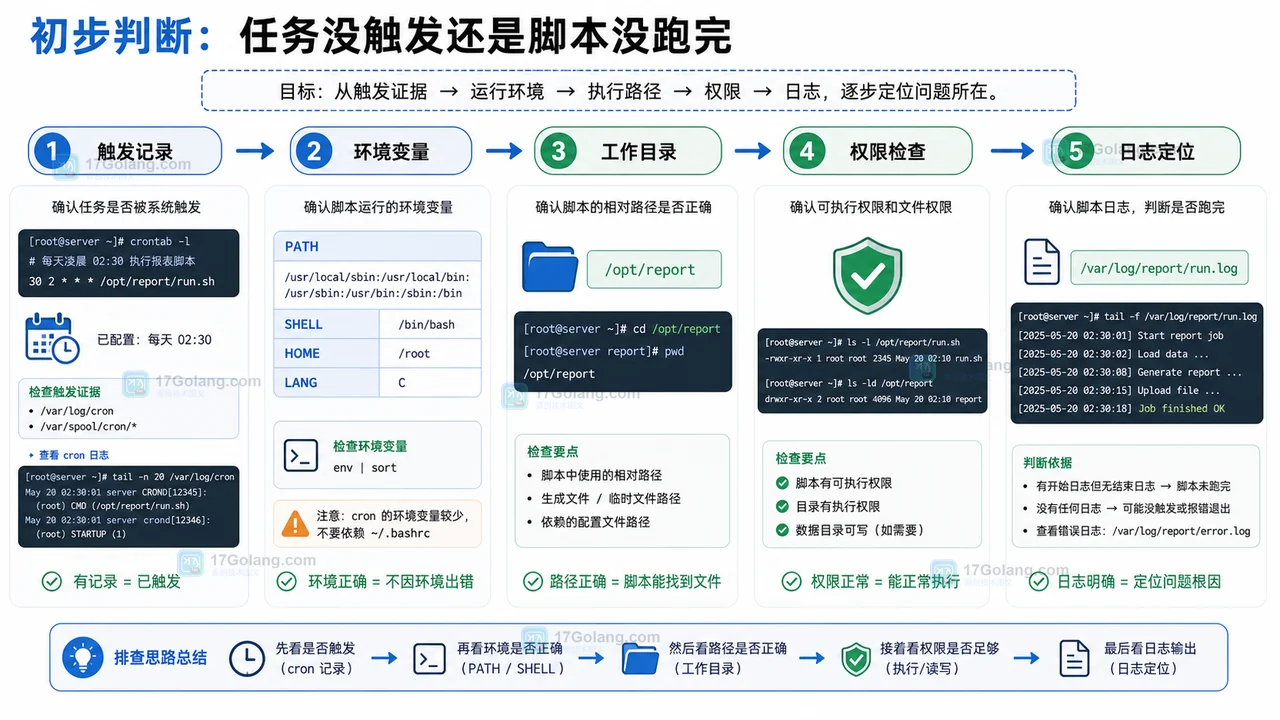
Linux crontab 定时任务不运行排查:从 PATH 到工作目录和日志
本文从 crontab 定时任务没有按时运行的现象出发,按触发记录、PATH、工作目录、权限、日志和并发
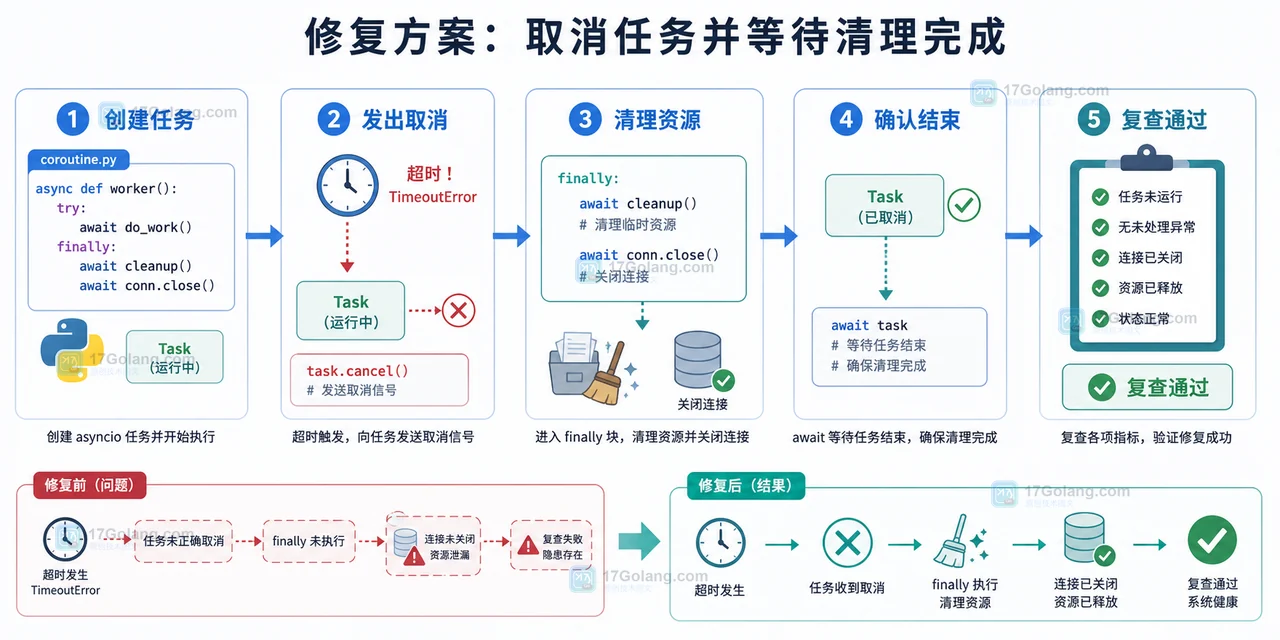
Python asyncio 超时后任务还在跑排查:从 wait_for 到取消清理
本文从一个 asyncio 超时后后台任务仍在继续的现象出发,排查 wait_for、shield、取消



