
详细介绍
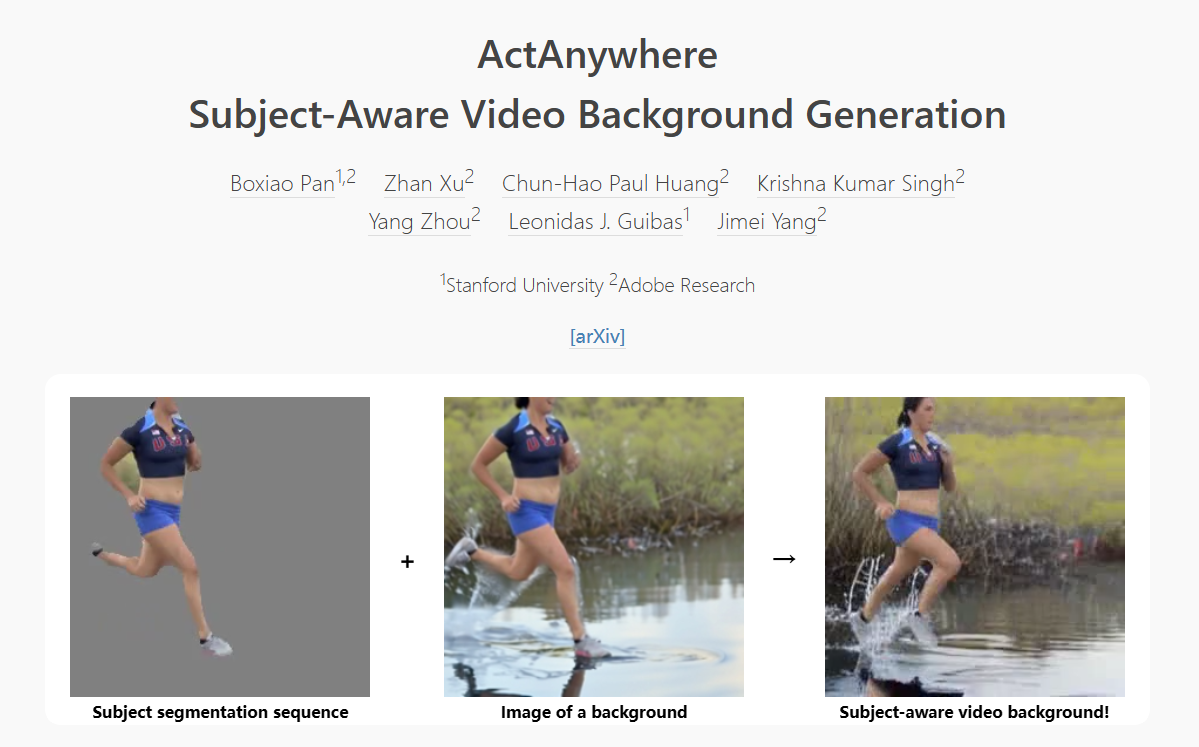
ActAnywhere:革新视频背景生成的先锋
ActAnywhere 是由斯坦福大学和Adobe Research的研究人员共同开发的视频生成模型,专为电影制作和视觉效果(VFX)领域设计。它通过自动化生成与前景主体运动相协调的视频背景,极大地简化了视频制作过程。
核心特点:
- 前景主体与背景融合:根据前景主体的运动和外观,自动生成与之匹配的背景,确保视频的自然性和连贯性。
- 条件帧驱动的背景生成:用户只需提供描述新场景的图像,模型即可据此生成逼真的背景。
- 时间一致性:通过时间自注意力机制,确保生成视频在时间序列上的一致性,避免出现跳跃或不连贯的现象。
- 自监督学习:在大规模人类-场景交互视频数据集上进行自监督训练,提升模型的泛化能力。
- 零样本学习:无需额外训练,即可对未见过的数据进行高质量生成,增强模型的灵活性。
强大功能:
- 视频背景替换:将前景主体无缝融入全新背景中,适用于电影、广告等多种视频制作。
- 视觉效果增强:生成复杂的背景效果,如动态天气、光影变化,提升视频的视觉冲击力。
- 创意内容制作:帮助艺术家和内容创作者实现创意想法,将角色置于不同历史时期或未来世界。
- 教育和培训:创建模拟场景用于教育或安全培训,提供沉浸式的学习体验。
- 游戏和娱乐:生成动态背景,丰富游戏体验,提升玩家的沉浸感。
应用案例:
- 视频背景替换:无需实际拍摄,即可将演员表演的视频与新的虚拟背景结合,节省时间和成本。
- 视觉效果增强:在特效制作中生成动态的光影效果,增强视觉冲击力,提升观众体验。
- 创意内容制作:艺术家使用ActAnywhere将角色置于不同历史时期或未来世界,实现创意构想。
- 教育和培训:制作模拟历史事件的场景,帮助学生更好地理解历史,提升学习效果。
- 游戏和娱乐:游戏开发者利用ActAnywhere生成动态的游戏背景,提升游戏的沉浸感和互动性。
总结:
ActAnywhere作为一款由斯坦福大学和Adobe Research联合开发的视频生成工具,通过自动化的前景与背景融合技术,极大地简化了视频背景生成的过程。其广泛的应用场景,从电影制作到教育培训,再到游戏娱乐,都能提供高效、创新的解决方案,为用户带来全新的视频制作体验。
查看更多
最新文章
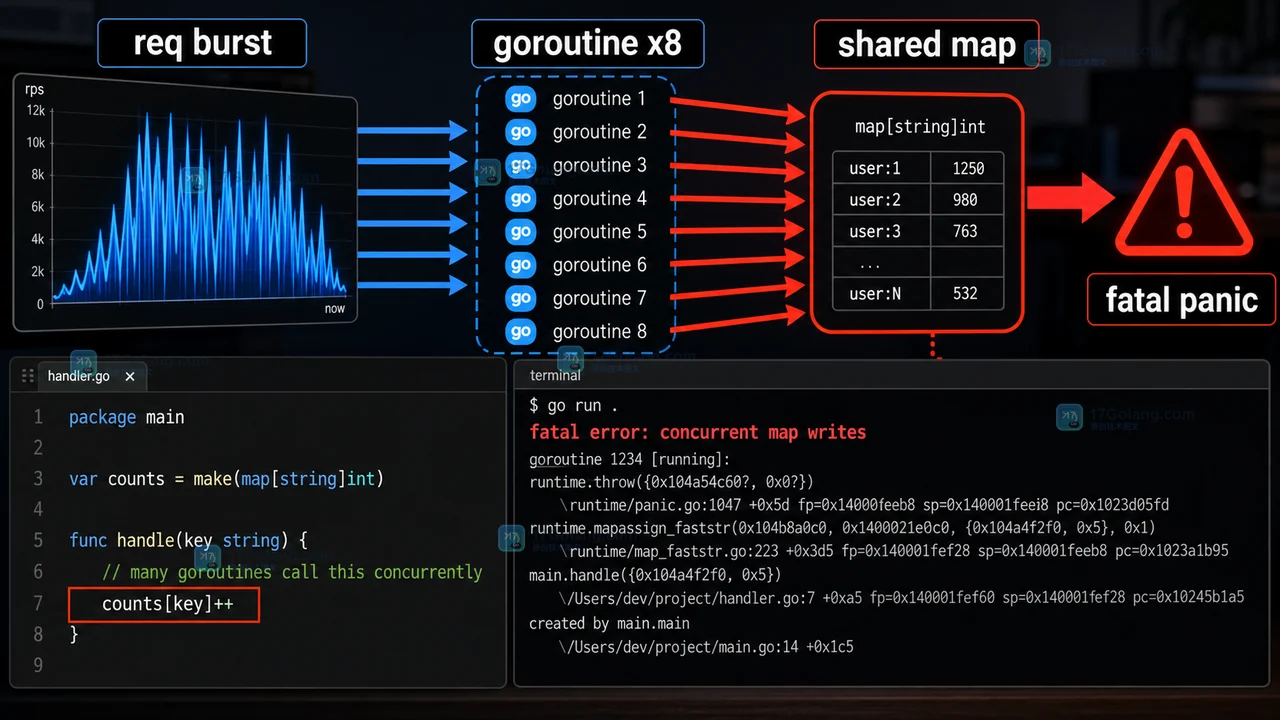
Go map 并发写 panic 怎么办:从共享 map 到可控写入路径
围绕 Go map 并发写 panic,按高并发场景解释为什么共享 map 会崩溃,并给出加锁、分片 m
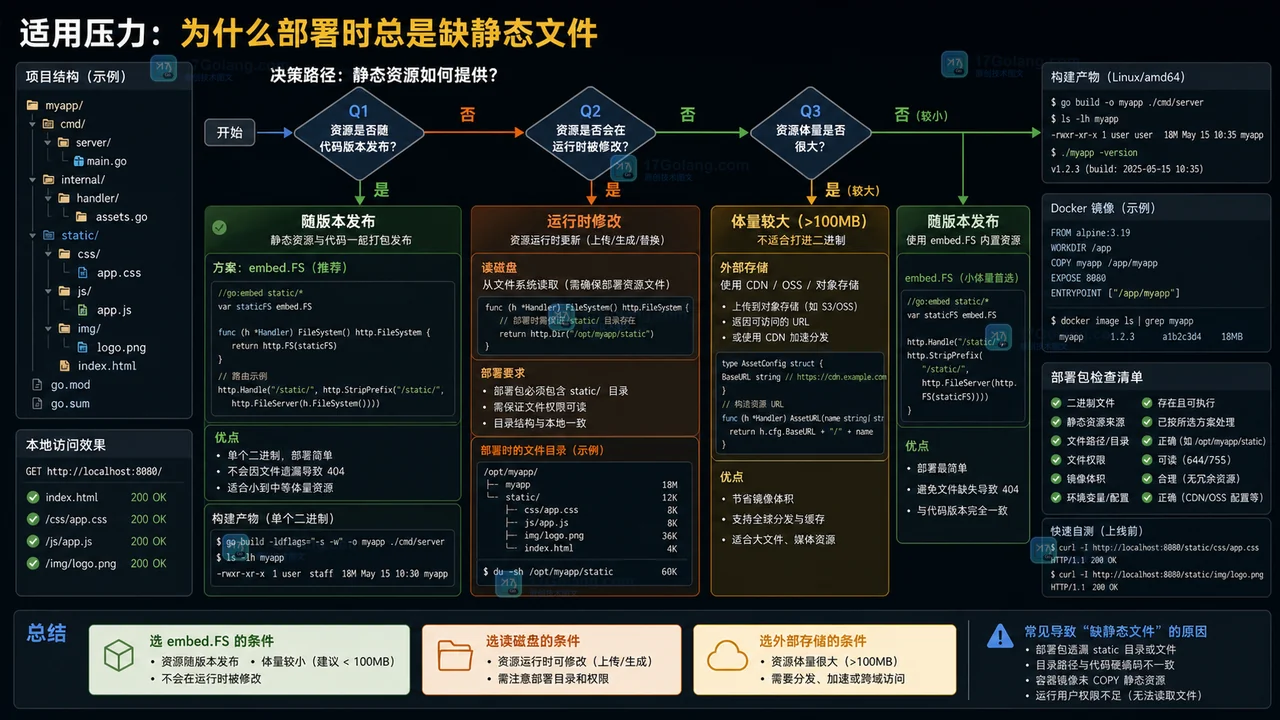
Go embed 静态资源打包模式:模板和前端文件要不要收进二进制?
围绕 Go embed.FS 静态资源打包模式,分析模板、前端文件和配置示例是否适合收进二进制,给出开发

Go Webhook 验签实战:HMAC、时间窗口和重放防护怎么做
以 Go Webhook 接收接口为例,讲清 HMAC 验签为什么要绑定原始 body、时间戳和事件 I
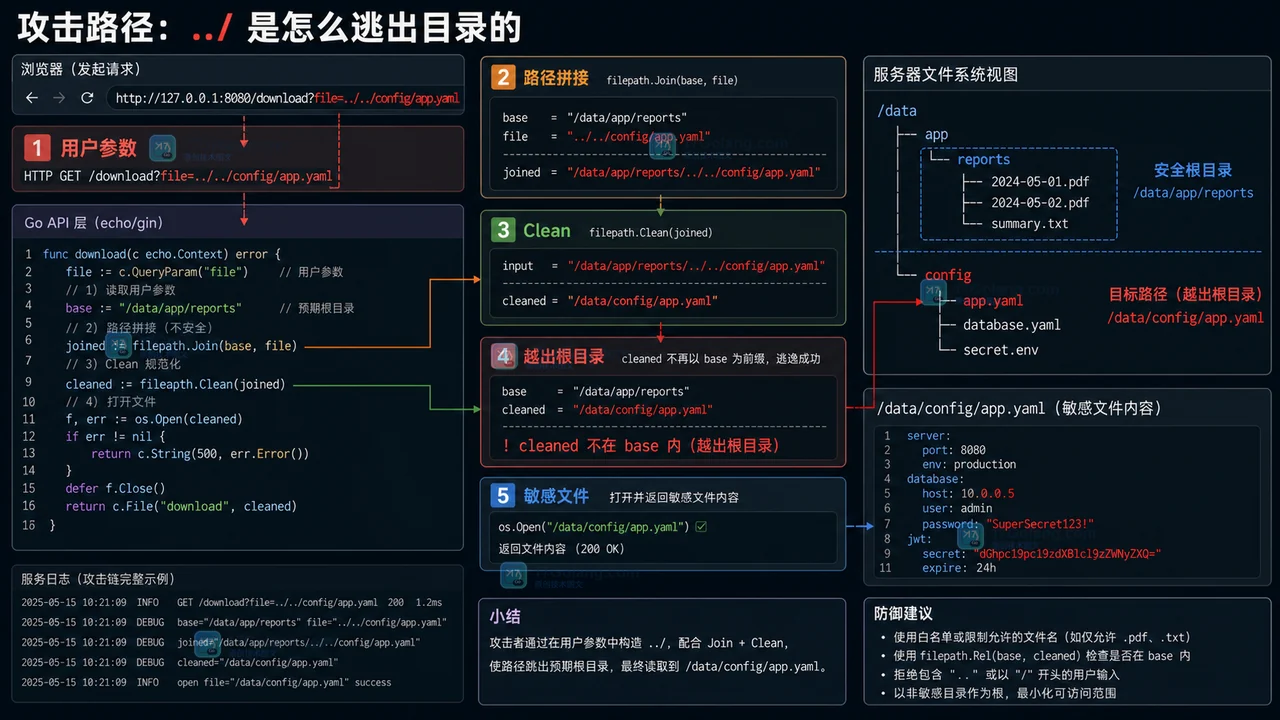
Go 问答:文件下载接口如何防路径穿越,filepath.Clean 够不够?
围绕 Go 文件下载接口的路径穿越风险,解释 filepath.Clean 为什么不等于安全校验,并给出
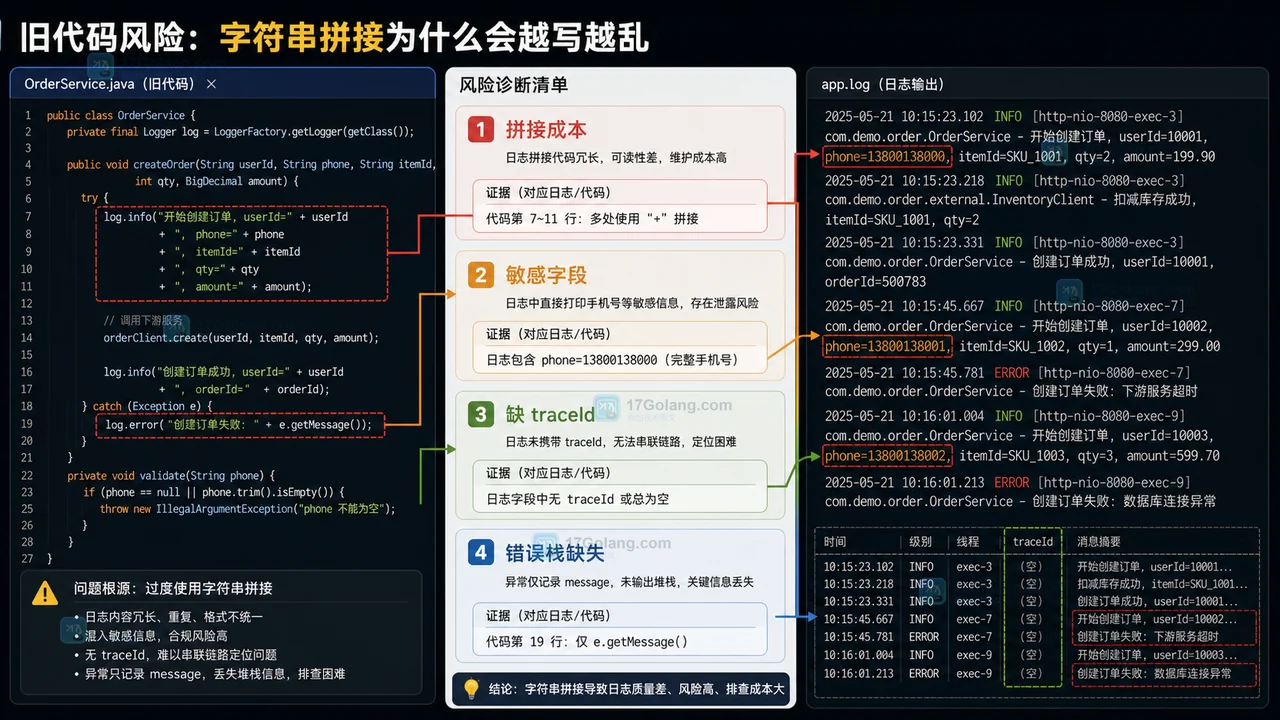
Java 日志迁移变更单:从字符串拼接到参数化日志和 MDC traceId
围绕 Java 老项目日志迁移,说明如何从字符串拼接改成 SLF4J 参数化日志,并补上 MDC tra

PHP 老接口迁移变更单:从散落 $_POST 到 Request DTO 与统一错误响应
以 PHP 老接口迁移为例,把散落的 $_POST 读取改成 Request DTO、集中校验和统一错误



