详细介绍
新介绍内容:
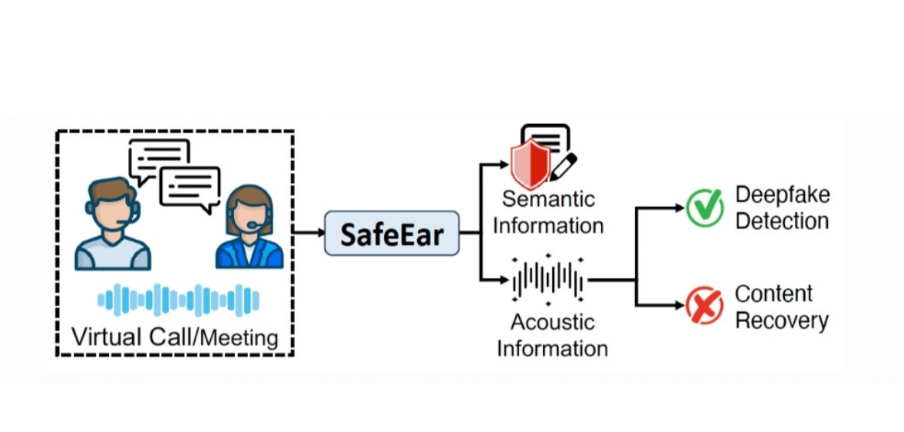
SafeEar:AI音频伪造检测框架,保护隐私的高效解决方案
SafeEar是由浙江大学和清华大学联合开发的AI音频伪造检测框架,旨在保护用户隐私的同时高效检测音频伪造。该框架采用基于神经音频编解码器的解耦模型,能够分离语音的声学信息和语义信息,仅用声学信息进行检测,从而有效防止隐私泄露。SafeEar在多个基准数据集上表现优异,等错误率(EER)低至2.02%,能抵御内容恢复攻击,并提供了多语言支持。
主要特点:
- 隐私保护:通过分离语义和声学信息,确保语音内容的隐私安全。
- 多语言支持:能够处理和检测多种语言的音频数据,适应全球用户需求。
- 高效伪造检测:在公开基准数据集上EER低至2.02%,检测准确率高。
- 抗内容恢复技术:即使在对抗性攻击下也能保持高检测准确率。
- 真实环境增强:模拟真实环境中的音频信道多样性,增强模型的泛化能力。
- 开源资源:提供论文、代码和数据集的开放访问,促进学术交流和应用开发。
主要功能:
- 深度伪造检测:精准检测音频是否经过伪造处理,保护信息真实性。
- 隐私保护:在检测过程中确保语音内容的隐私不被泄露。
- 多语言处理:支持多种语言的音频数据检测,提升应用范围。
- 数据集构建:构建了包含150万条多语种音频数据的CVoiceFake数据集,丰富检测资源。
使用示例:
- 社交媒体监控:在社交媒体平台上检测音频内容是否为伪造,维护信息真实性。
- 法律证据验证:在法律程序中验证音频证据的真实性,确保司法公正。
- 金融交易安全:提升金融机构中语音识别系统的安全性,防范欺诈行为。
- 国家安全:帮助政府和安全机构识别潜在的威胁和虚假信息,维护国家安全。
总结:
SafeEar作为一款创新的音频伪造检测工具,通过先进的AI技术保护用户的语音隐私,同时提供高效的伪造音频检测能力。其多语言支持和抗攻击能力使其在社交媒体监控、法律证据验证、金融交易安全和国家安全等多个领域具有广泛的应用前景。
查看更多
最新文章
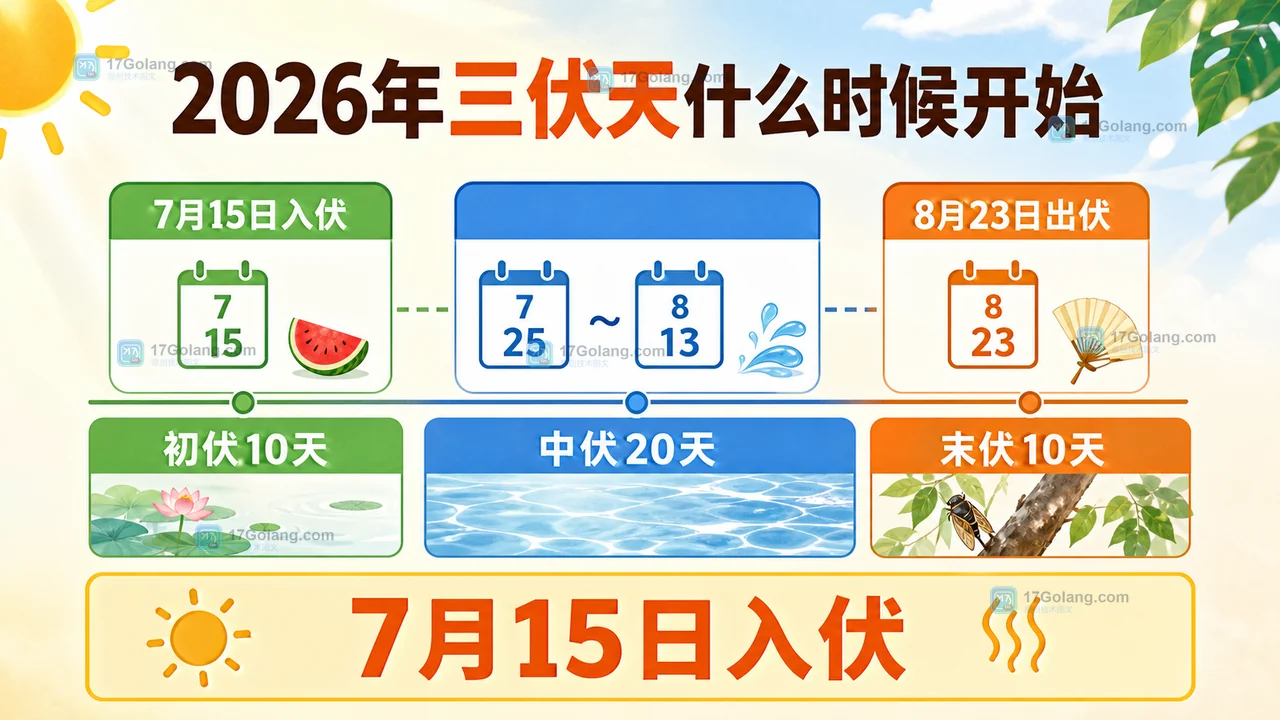
2026年三伏天什么时候开始?初伏中伏末伏时间表和注意事项
2026年三伏天从7月15日开始,到8月23日结束,共40天。本文整理初伏、中伏、末伏时间表,并说明高温
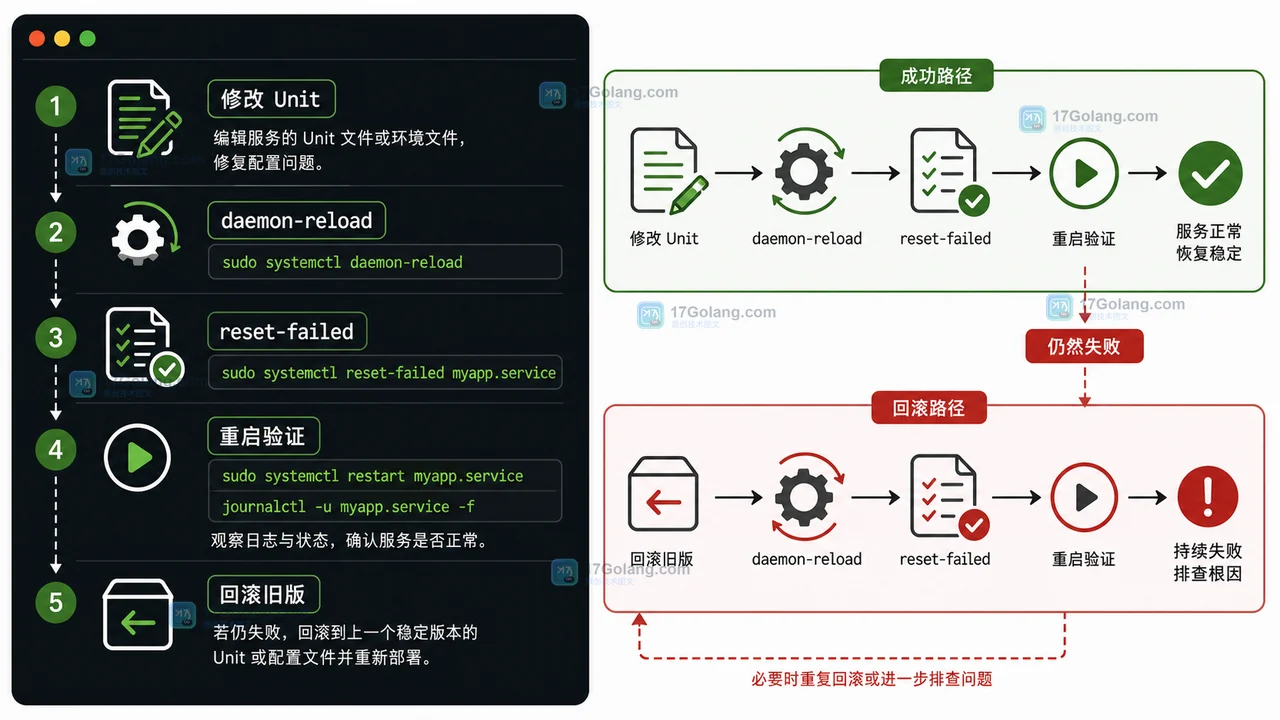
Linux 服务反复重启怎么办:journalctl 和 RestartSec 排查清单
本文用一次 Linux 服务反复重启的现场,讲清楚如何看 status、journalctl、Resta
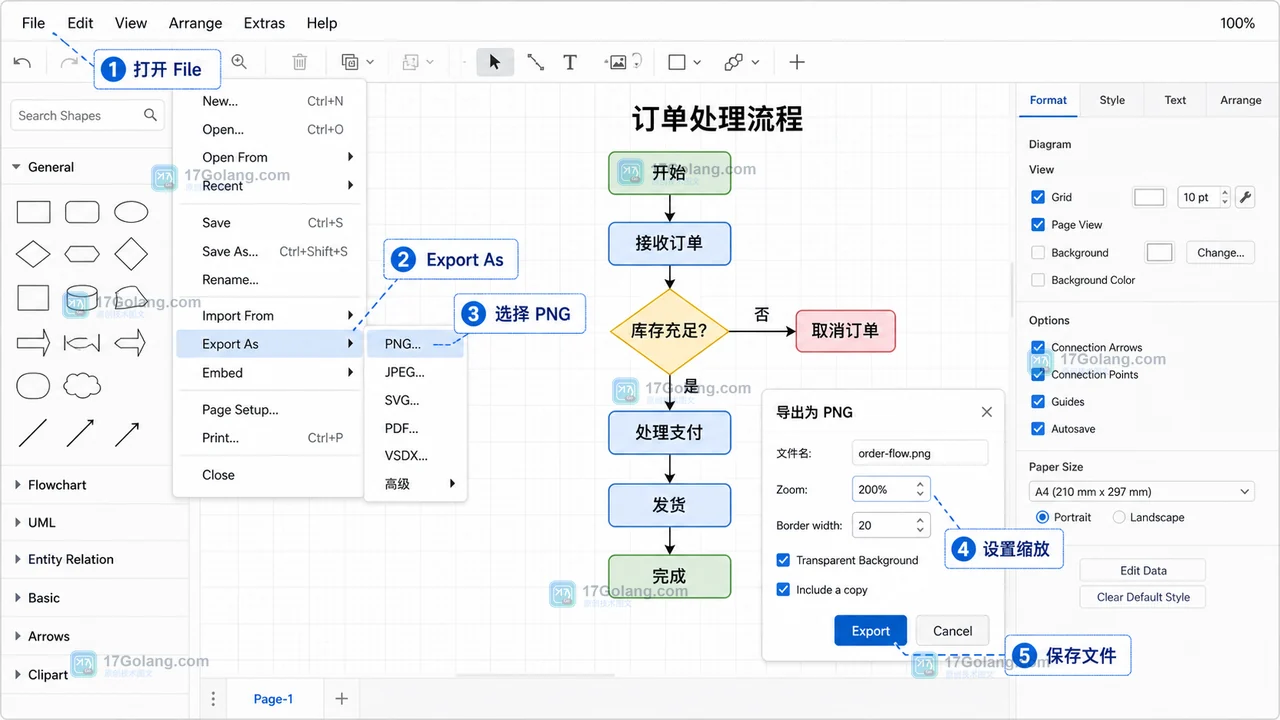
diagrams.net 导出高清 PNG:透明背景、缩放比例和回导核对流程
演示在 diagrams.net 中通过 File > Export As > PNG 导出高清 PNG
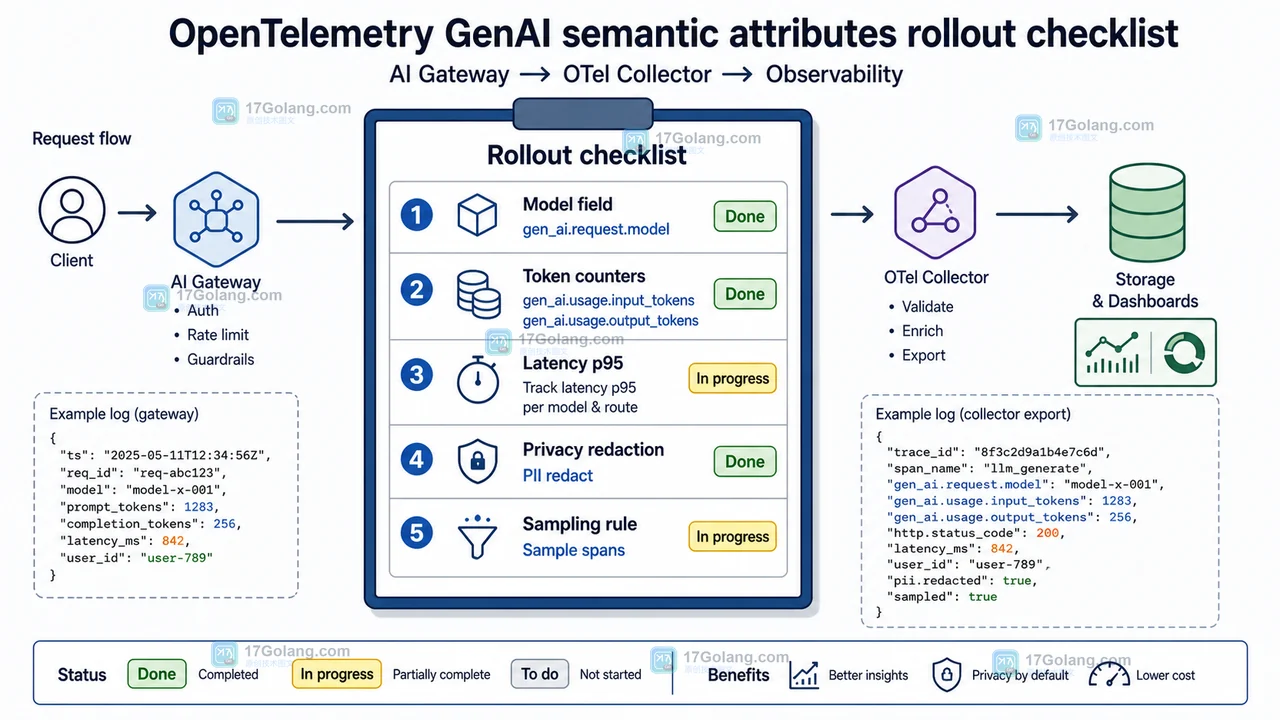
AI 调用可观测架构:从散乱日志到 OpenTelemetry GenAI 字段统一
围绕 AI 调用规模化后的日志散乱、模型字段不统一、token 成本不可见和隐私采集风险,讲解如何用 O
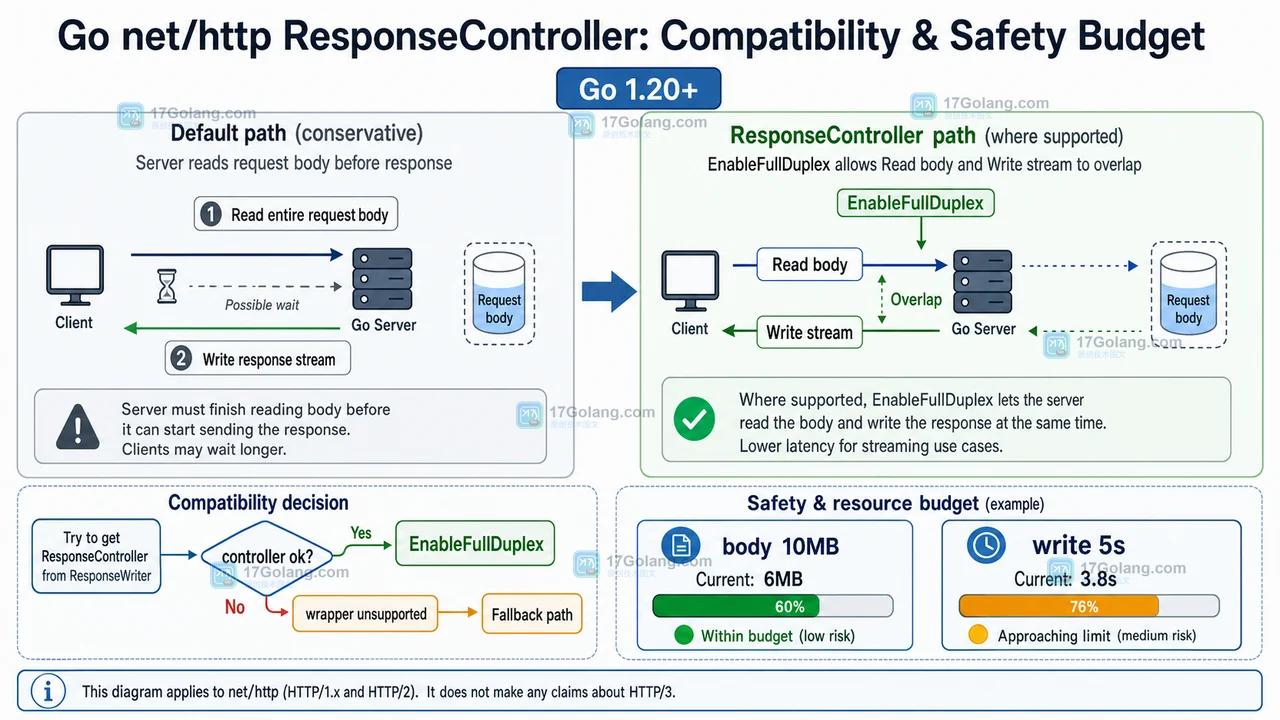
Go http.ResponseController 有什么用?Flush、写超时和 FullDuplex 这样理解
用问答方式解释 Go net/http ResponseController 的定位、Flush、写入

PHP Session 迁移到 Redis:从本机文件到集中存储的回归检查清单
围绕 PHP Session 从本机文件迁移到 Redis 的过程,梳理旧架构风险、配置变更、锁等待、T



