详细介绍
新介绍内容:
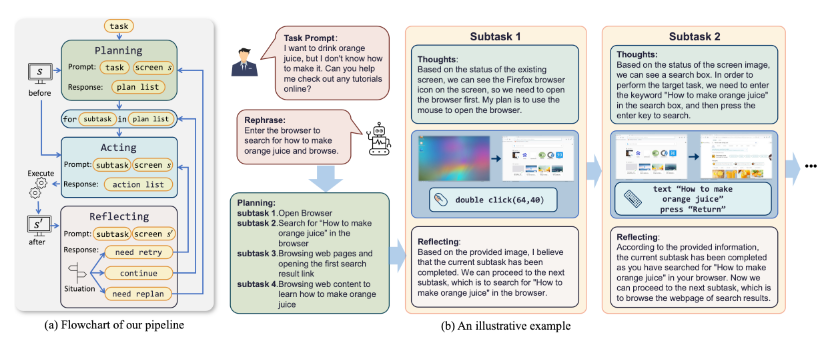
ScreenAgent:吉林大学研发的视觉语言模型智能体,实现计算机屏幕自动化操作
ScreenAgent是由吉林大学人工智能学院与知识驱动的人工智能教育部工程研究中心联合开发的一个创新性计算机控制智能体。它基于视觉语言模型(VLM),能够与真实计算机屏幕进行交互,执行复杂的多步骤任务。
主要特点:
- 视觉语言模型(VLM): 结合了先进的视觉和语言处理技术,能够解析屏幕截图并理解任务提示。
- 强化学习环境: 通过VNC协议与计算机屏幕交互,构建了高效的强化学习环境,用于训练智能体。
- 控制流程: 包括计划、执行和反思三个阶段,确保智能体能够持续优化与环境的交互。
- 数据集和评估: ScreenAgent数据集涵盖多种日常计算机任务的屏幕截图和动作序列,并通过CC-Score指标进行评估。
主要功能:
- 屏幕观察: 智能体能够观察和理解计算机屏幕截图,获取实时信息。
- 动作生成: 根据屏幕截图生成鼠标和键盘动作的JSON格式命令序列,精确控制操作。
- 任务规划: 将复杂任务分解为子任务,并规划相应的动作序列,确保任务顺利完成。
- 执行动作: 通过发送鼠标和键盘动作命令到计算机,执行用户指定的任务。
- 反思评估: 评估执行结果,根据反馈决定后续行动,优化操作流程。
使用示例:
- 屏幕观察: ScreenAgent实时观察桌面操作系统的屏幕图像,获取最新状态。
- 动作生成: 根据屏幕截图生成移动鼠标、点击、滚动等动作命令,确保操作精准。
- 任务规划: 将用户任务如“打开网页浏览器”分解为具体步骤,制定详细的操作计划。
- 执行动作: 执行打开浏览器、输入网址、搜索信息等动作,完成用户需求。
- 反思评估: 在尝试打开网页后,评估操作是否成功,若未成功则决定是否需要重试。
总结:
ScreenAgent作为一个先进的计算机控制智能体,通过观察屏幕截图和执行鼠标键盘动作,能够完成复杂的多步骤任务。其利用视觉语言模型和强化学习环境,在真实计算机屏幕上实现了高效的自动化操作。ScreenAgent的控制流程和评估指标使其成为一个强大的工具,能够自动化各种数字任务,显著提高操作效率和便利性。
查看更多
最新文章
Go Mutex 和 channel 哪个性能更好:共享变量、任务交接和等待链怎么选
Go 里 Mutex 和 channel 不是谁绝对更快。保护一个共享变量时,Mutex 往往更直接;交

RAG 应用答错怎么复盘:检索命中、证据门禁和评测样本怎么补
RAG 应用答错时,不要只怪模型。更常见的根因在检索层:切片不合适、召回证据偏题、排序没过滤、回答没有引

AI Agent 工具调用怎么落地:权限闸门、审批链路和上线观察指标
AI Agent 真正接入业务系统时,难点不在能不能调用工具,而在权限闸门、人工审批、参数校验、审计回放
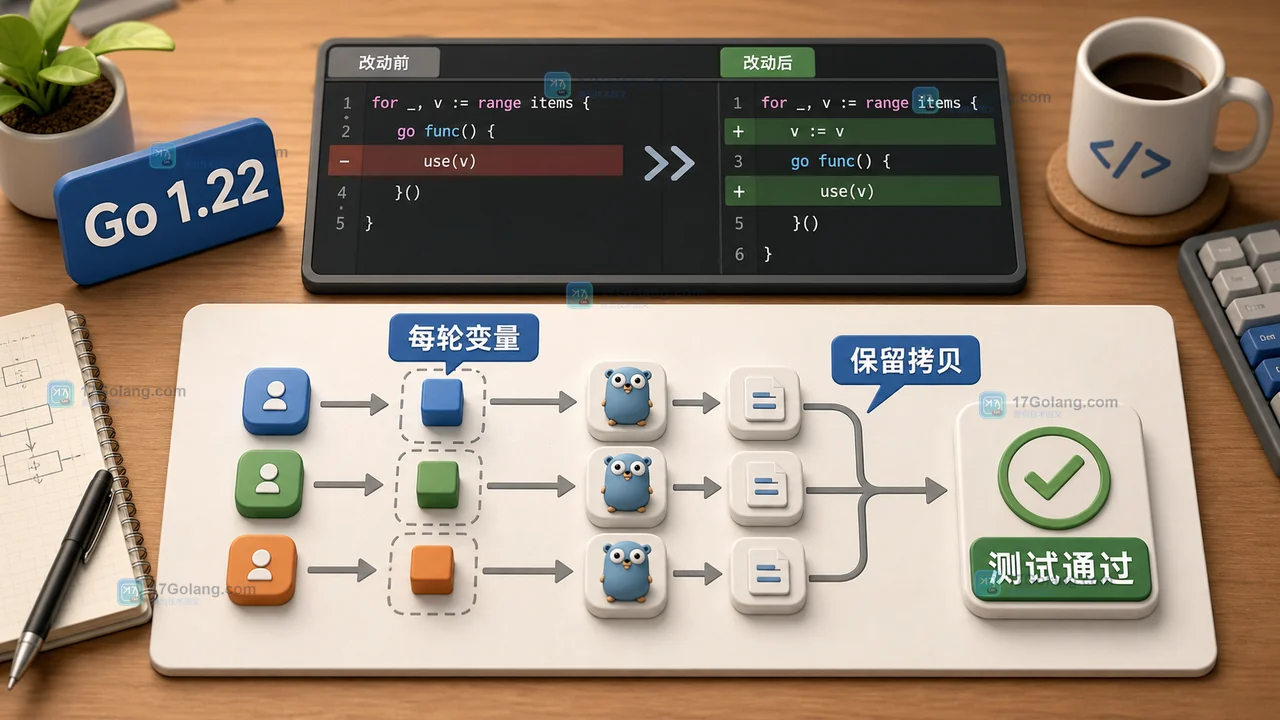
Go 1.22 循环变量升级:闭包、goroutine 和测试回归怎么处理
Go 1.22 调整了 for 循环变量的作用域,新模块里每轮循环会有自己的变量副本,能减少闭包和 go
MySQL 查询为什么不走索引:函数列、隐式转换和范围条件怎么改
MySQL 查询不走索引,常见原因不是索引不存在,而是 SQL 写法让优化器难以利用索引。函数包列、隐式
Go map 并发读写为什么会 panic:加锁、单协程和 sync.Map 怎么选
Go 原生 map 不是并发安全容器,只要一个 goroutine 写 map,同时另一个 gorout



