
新的介绍内容

GPT-SoVITS:开源声音克隆项目,快速高效生成文本到语音模型
GPT-SoVITS是由RVC-Boss在GitHub上发布的一个开源声音克隆项目,旨在通过极少量的数据(如1分钟的语音样本)来训练高质量的文本到语音(TTS)模型,实现声音克隆。这个项目特别适合内容创作者、语音合成开发者等需要快速生成特定声音模型的用户。
主要特点:
- 零样本TTS:只需5秒的语音样本,即可实现即时文本到语音转换。
- 少量样本TTS:仅需1分钟的语音数据即可微调模型,提升声音的相似度和真实性。
- 跨语言支持:支持与训练数据集不同的语言进行推理,涵盖英语、日语、韩语、粤语和中文。
- WebUI工具:提供语音伴奏分离、自动训练集分割、中文ASR和文本标记等工具,帮助初学者准备数据和训练模型。
主要功能:
- 零样本语音合成:上传简短的语音样本,系统即可生成文本到语音的转换,无需额外训练。
- 少量样本语音合成:提供少量语音数据(如1分钟)来微调模型,提高合成语音的自然度和相似度。
- 跨语言语音合成:即使训练数据集是特定语言,也可在其他语言上进行语音合成,扩大应用范围。
- WebUI集成工具:包括语音伴奏分离、自动训练集分割、中文语音识别(ASR)和文本标记,简化数据准备和模型训练过程。
使用示例:
假设您是一名视频内容创作者,想要为视频中的特定角色制作配音。您可以使用GPT-SoVITS进行声音克隆。首先,录制该角色的5秒语音样本,上传到GPT-SoVITS的WebUI。选择零样本TTS功能,输入角色需要说的文本,系统将即时生成该角色的声音。如果需要更高的相似度,您可以录制1分钟的语音样本,使用少量样本TTS功能进行模型微调,然后再输入文本进行语音合成,以获得更自然、更相似的合成语音。
总结:
GPT-SoVITS是一个功能强大的开源声音克隆项目,通过创新的少量样本学习技术,用户可以快速训练出高质量的文本到语音模型。无论是零样本的即时语音合成,还是通过少量样本进行的精细微调,GPT-SoVITS都能提供出色的效果。其跨语言支持和丰富的WebUI工具进一步增强了其实用性和易用性,使其成为内容创作者、语音合成开发者以及其他需要声音克隆功能的用户的理想选择。
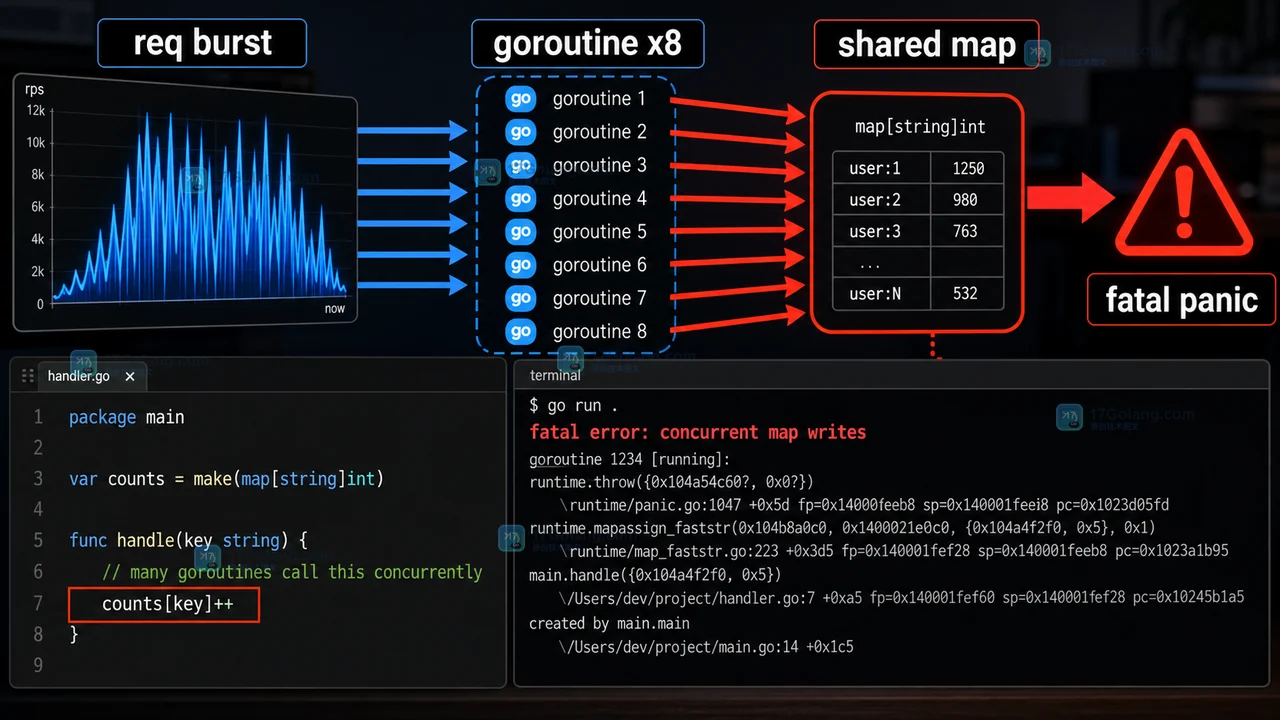
Go map 并发写 panic 怎么办:从共享 map 到可控写入路径
围绕 Go map 并发写 panic,按高并发场景解释为什么共享 map 会崩溃,并给出加锁、分片 m
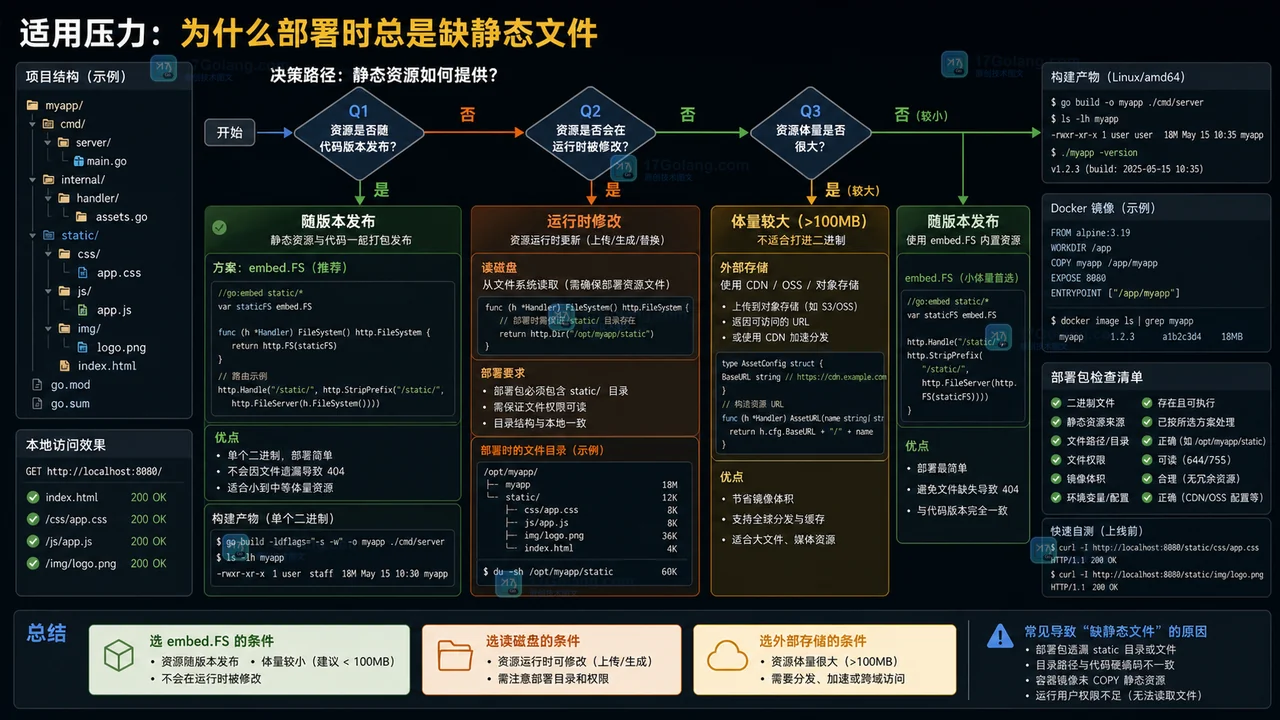
Go embed 静态资源打包模式:模板和前端文件要不要收进二进制?
围绕 Go embed.FS 静态资源打包模式,分析模板、前端文件和配置示例是否适合收进二进制,给出开发

Go Webhook 验签实战:HMAC、时间窗口和重放防护怎么做
以 Go Webhook 接收接口为例,讲清 HMAC 验签为什么要绑定原始 body、时间戳和事件 I
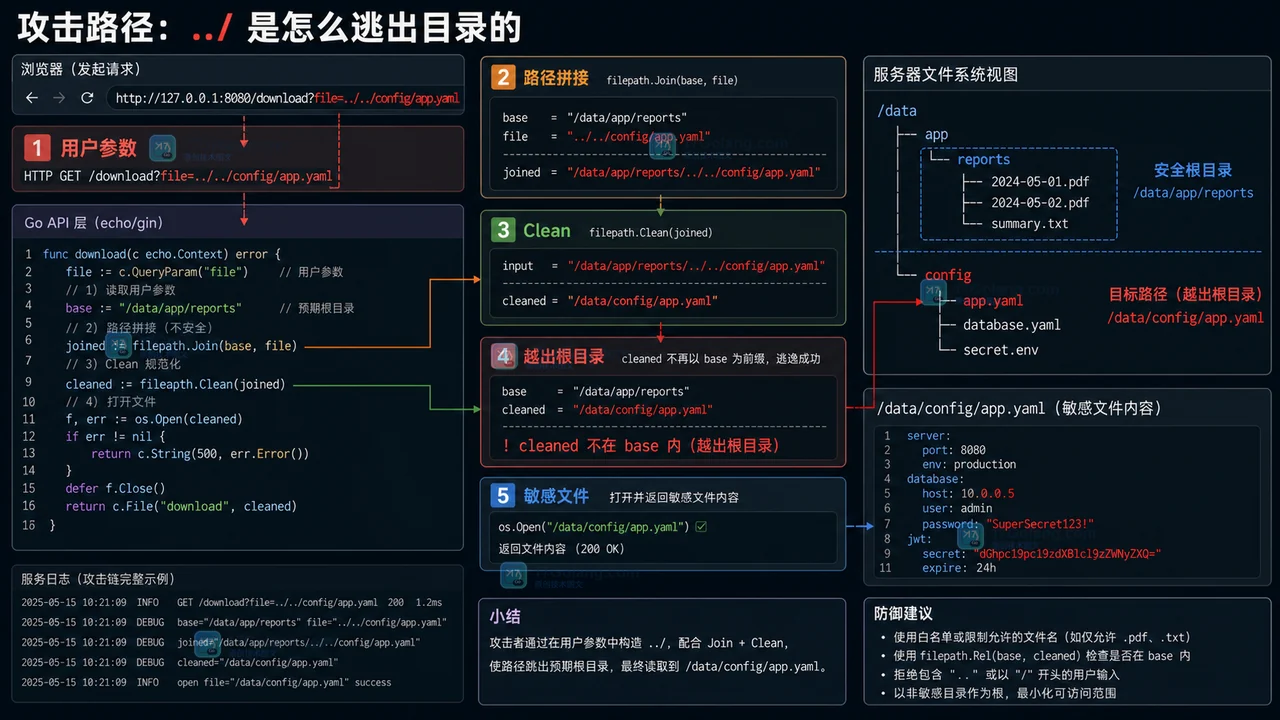
Go 问答:文件下载接口如何防路径穿越,filepath.Clean 够不够?
围绕 Go 文件下载接口的路径穿越风险,解释 filepath.Clean 为什么不等于安全校验,并给出
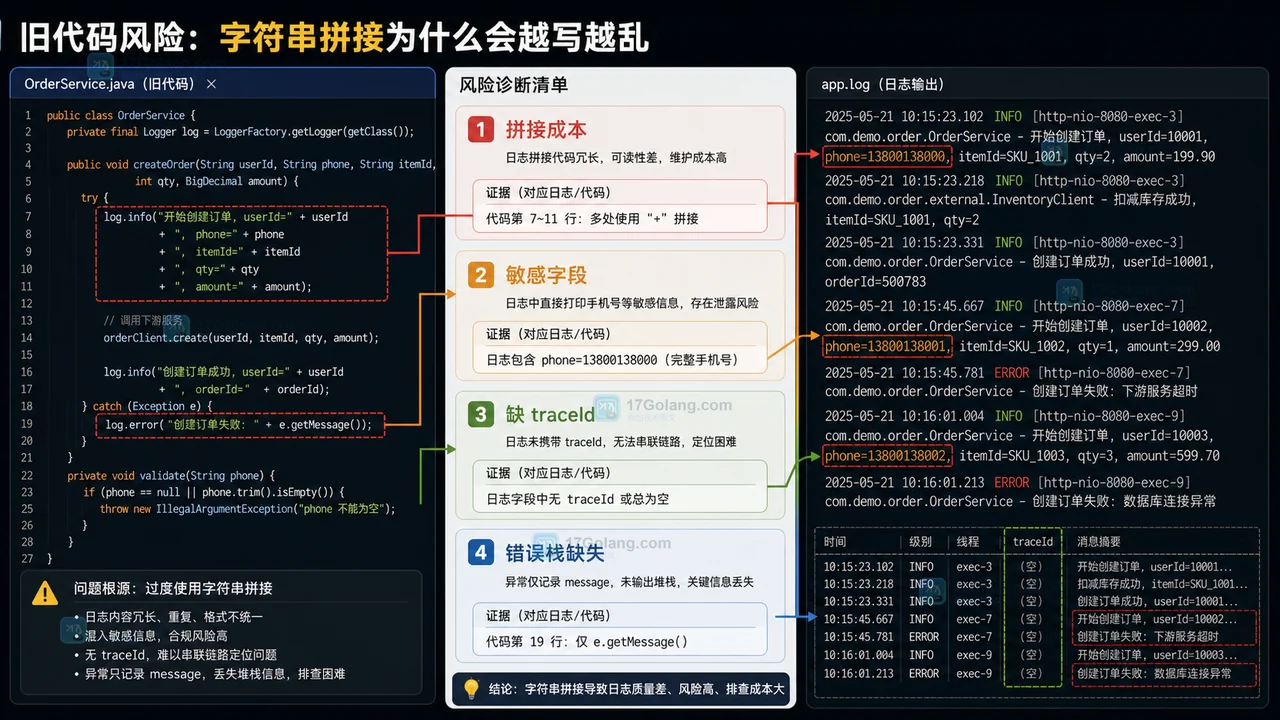
Java 日志迁移变更单:从字符串拼接到参数化日志和 MDC traceId
围绕 Java 老项目日志迁移,说明如何从字符串拼接改成 SLF4J 参数化日志,并补上 MDC tra

PHP 老接口迁移变更单:从散落 $_POST 到 Request DTO 与统一错误响应
以 PHP 老接口迁移为例,把散落的 $_POST 读取改成 Request DTO、集中校验和统一错误



