降低了链接采集数量的并行性:Go Colly技术
大家好,我们又见面了啊~本文《降低了链接采集数量的并行性:Go Colly技术》的内容中将会涉及到等等。如果你正在学习Golang相关知识,欢迎关注我,以后会给大家带来更多Golang相关文章,希望我们能一起进步!下面就开始本文的正式内容~
我正在尝试构建一个网络抓取工具来从 internshala.com 抓取工作。我正在使用 go colly 构建网络抓取器。我访问每个页面,然后访问每个作业的后续链接以从中获取数据。以顺序方式执行此操作会抓取几乎所有链接,但如果我尝试使用 colly 的并行抓取来执行此操作,则抓取的链接数量会减少。我将所有数据写入 csv 文件中。
编辑 我的问题是为什么在并行报废时会发生这种情况以及如何解决它(即使在并行报废时如何才能刮取所有数据)。 或者是我做错了什么导致了这个问题。代码审查将会非常有帮助。谢谢:)
package main
import (
"encoding/csv"
"log"
"os"
"strconv"
"sync"
"time"
"github.com/gocolly/colly"
)
func main(){
parallel(10)
seq(10)
}
由于显而易见的原因,我在运行之前注释掉了这两个函数之一。
并行函数:=
func parallel(n int){
start := time.now()
c := colly.newcollector(
colly.alloweddomains("internshala.com", "https://internshala.com/internship/detail",
"https://internshala.com/internship/", "internshala.com/", "www.intershala.com"),
colly.async(true),
)
d := colly.newcollector(
colly.alloweddomains("internshala.com", "https://internshala.com/internship/detail",
"https://internshala.com/internship/", "internshala.com/", "www.intershala.com"),
colly.async(true),
)
c.limit(&colly.limitrule{domainglob: "*", parallelism: 4})
d.limit(&colly.limitrule{domainglob: "*", parallelism: 4})
filename := "data.csv"
file, err := os.create(filename)
cnt := 0
if err != nil{
log.fatalf("could not create file, err: %q", err)
return
}
defer file.close() // close the file after the main routine exits
writer := csv.newwriter(file)
defer writer.flush()
var wg sync.waitgroup
c.onhtml("a[href]", func(e *colly.htmlelement){
if e.attr("class") != "view_detail_button"{
return
}
detailslink := e.attr("href")
d.visit(e.request.absoluteurl(detailslink))
})
d.onhtml(".detail_view", func(e *colly.htmlelement) {
wg.add(1)
go func(wg *sync.waitgroup) {
writer.write([]string{
e.childtext("span.profile_on_detail_page"),
e.childtext(".company_name a"),
e.childtext("#location_names a"),
e.childtext(".internship_other_details_container > div:first-of-type > div:last-of-type .item_body"),
e.childtext("span.stipend"),
e.childtext(".applications_message"),
e.childtext(".internship_details > div:nth-last-of-type(3)"),
e.request.url.string(),
})
wg.done()
}(&wg)
})
c.onrequest(func(r *colly.request) {
log.println("visiting", r.url.string())
})
d.onrequest(func(r *colly.request) {
log.println("visiting", r.url.string())
cnt++
})
for i := 1; i < n; i++ {
c.visit("https://internshala.com/internships/page-"+strconv.itoa(i))
}
c.wait()
d.wait()
wg.wait()
t := time.since(start)
log.printf("time %v \n", t)
log.printf("amount %v \n", cnt)
log.printf("scrapping complete")
log.println(c)
}
seq 函数:=
func seq(n int){
start := time.Now()
c := colly.NewCollector(
colly.AllowedDomains("internshala.com", "https://internshala.com/internship/detail",
"https://internshala.com/internship/", "internshala.com/", "www.intershala.com"),
)
d := colly.NewCollector(
colly.AllowedDomains("internshala.com", "https://internshala.com/internship/detail",
"https://internshala.com/internship/", "internshala.com/", "www.intershala.com"),
)
fileName := "data.csv"
file, err := os.Create(fileName)
cnt := 0
if err != nil{
log.Fatalf("Could not create file, err: %q", err)
return
}
defer file.Close() // close the file after the main routine exits
writer := csv.NewWriter(file)
defer writer.Flush()
c.OnHTML("a[href]", func(e *colly.HTMLElement){
if e.Attr("class") != "view_detail_button"{
return
}
detailsLink := e.Attr("href")
d.Visit(e.Request.AbsoluteURL(detailsLink))
})
d.OnHTML(".detail_view", func(e *colly.HTMLElement) {
writer.Write([]string{
e.ChildText("span.profile_on_detail_page"),
e.ChildText(".company_name a"),
e.ChildText("#location_names a"),
e.ChildText(".internship_other_details_container > div:first-of-type > div:last-of-type .item_body"),
e.ChildText("span.stipend"),
e.ChildText(".applications_message"),
e.ChildText(".internship_details > div:nth-last-of-type(3)"),
e.Request.URL.String(),
})
})
c.OnRequest(func(r *colly.Request) {
log.Println("visiting", r.URL.String())
})
d.OnRequest(func(r *colly.Request) {
log.Println("visiting", r.URL.String())
cnt++
})
for i := 1; i < n; i++ {
// Add URLs to the queue
c.Visit("https://internshala.com/internships/page-"+strconv.Itoa(i))
}
t := time.Since(start)
log.Printf("time %v \n", t)
log.Printf("amount %v \n", cnt)
log.Printf("Scrapping complete")
log.Println(c)
}
任何帮助将不胜感激。 :)
正确答案
很抱歉在聚会上迟到,但我想出了一个有效的解决方案来解决您的问题。让我展示一下:
package main
import (
"encoding/csv"
"fmt"
"log"
"os"
"strconv"
"strings"
"time"
"github.com/gocolly/colly/v2"
"github.com/gocolly/colly/v2/queue"
)
func parallel(n int) {
start := time.Now()
cnt := 0
queue, _ := queue.New(8, &queue.InMemoryQueueStorage{MaxSize: 1000}) // tried up to 8 threads
fileName := "data_par.csv"
file, err := os.Create(fileName)
if err != nil {
log.Fatalf("Could not create file, err: %q", err)
return
}
defer file.Close() // close the file after the main routine exits
writer := csv.NewWriter(file)
defer func() {
writer.Flush()
if err := writer.Error(); err != nil {
panic(err)
}
}()
c := colly.NewCollector(
colly.AllowedDomains("internshala.com", "https://internshala.com/internship/detail",
"https://internshala.com/internship/", "internshala.com/", "www.intershala.com"),
)
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
if e.Attr("class") != "view_detail_button" {
return
}
detailsLink := e.Attr("href")
e.Request.Visit(detailsLink)
})
c.OnRequest(func(r *colly.Request) {
writer.Write([]string{r.URL.String()})
})
for i := 1; i < n; i++ {
queue.AddURL("https://internshala.com/internships/page-" + strconv.Itoa(i))
}
queue.Run(c)
t := time.Since(start)
log.Printf("time: %v\tamount: %d\n", t, cnt)
}
func seq(n int) {
start := time.Now()
c := colly.NewCollector(
colly.AllowedDomains("internshala.com", "https://internshala.com/internship/detail",
"https://internshala.com/internship/", "internshala.com/", "www.intershala.com"),
)
fileName := "data_seq.csv"
file, err := os.Create(fileName)
cnt := 0
if err != nil {
log.Fatalf("Could not create file, err: %q", err)
return
}
defer file.Close() // close the file after the main routine exits
writer := csv.NewWriter(file)
defer func() {
writer.Flush()
if err := writer.Error(); err != nil {
panic(err)
}
}()
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
if e.Attr("class") != "view_detail_button" {
return
}
detailsLink := e.Attr("href")
e.Request.Visit(detailsLink)
})
c.OnRequest(func(r *colly.Request) {
writer.Write([]string{r.URL.String()})
})
for i := 1; i < n; i++ {
c.Visit("https://internshala.com/internships/page-" + strconv.Itoa(i))
}
t := time.Since(start)
log.Printf("time: %v\tamount: %d\n", t, cnt)
}
func main() {
fmt.Println("sequential")
seq(6)
fmt.Println(strings.Repeat("#", 50))
fmt.Println("parallel")
parallel(6)
}
问题
查看您的代码后,我认为一切都已正确实现。当然,事情可以以更好的方式完成,但至少在并发性方面,一切都设置正确。以下列表中列出了您可以改进的一些方面:
- 刷新到底层 csv 文件时检查
error - 仅使用一个收集器而不是两个
同样,正如我已经说过的,这些只是小的改进。
实际问题
实际问题是,当您发出并发(并且可能是并行)请求时,colly 框架无法跟上它并开始丢失一些响应。当您增加执行次数时,这种趋势会呈指数级增长。
最简单的解决方案(imo)
gocolly 提供了非常适合这些挑战的 queue 类型。感谢他们,您将确保每个请求都会得到处理,就好像它们是同时完成的一样。步骤可概括如下:
- 使用
queue子包提供的new函数实例化一个新队列。您必须设置线程数量以及队列类型(在我们的例子中,可以使用内存中实现)。 - 使用所有需要的回调实例化默认收集器。
- 使用要查询的适当 url 对上述定义的
queue变量调用addurl方法。 - 调用
run方法,将实际请求发送到目标网址并等待响应。
请告诉我这是否可以解决您的问题或分享您如何解决此问题,谢谢!
终于介绍完啦!小伙伴们,这篇关于《降低了链接采集数量的并行性:Go Colly技术》的介绍应该让你收获多多了吧!欢迎大家收藏或分享给更多需要学习的朋友吧~golang学习网公众号也会发布Golang相关知识,快来关注吧!
 如何在苹果手机上退出Mac模式?(苹果手机如何退出盲人模式快捷键)
如何在苹果手机上退出Mac模式?(苹果手机如何退出盲人模式快捷键)
- 上一篇
- 如何在苹果手机上退出Mac模式?(苹果手机如何退出盲人模式快捷键)

- 下一篇
- 使用sqlmock测试gorm的删除子句
-
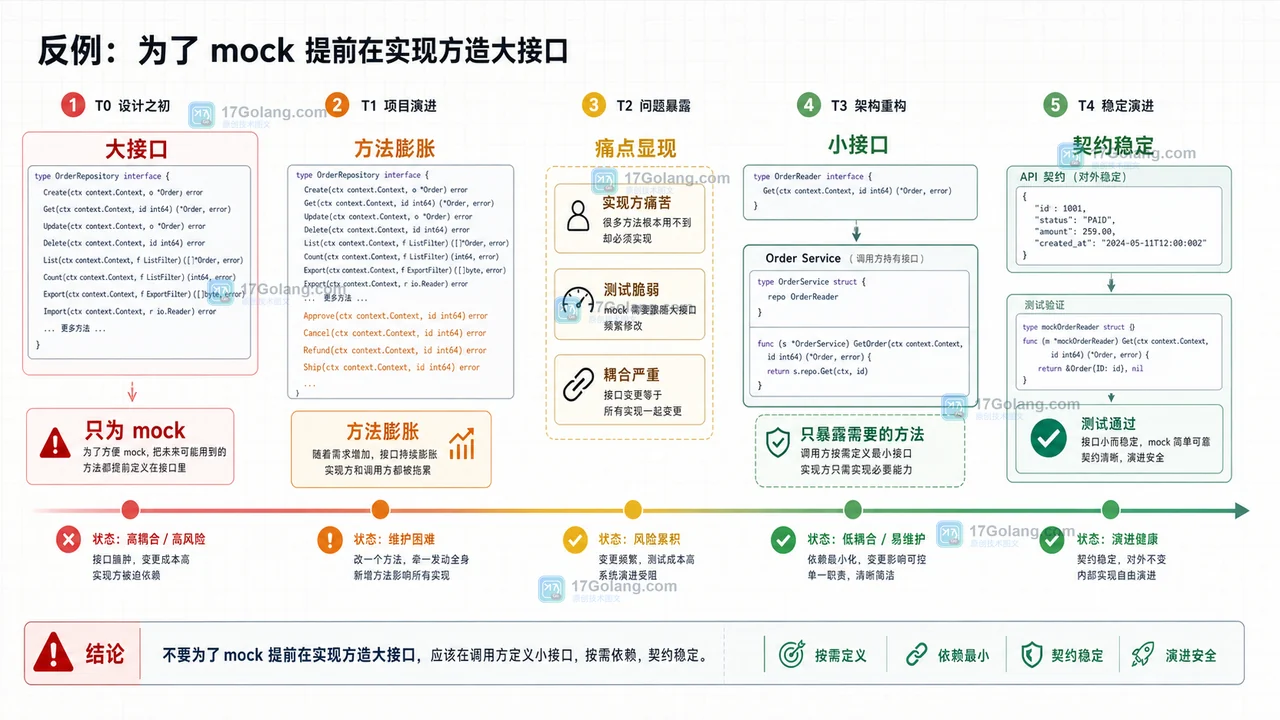
- Golang · Go问答 | 2天前 | interface · 单元测试 · 架构设计 · repository · Go问答 · 单元测试 架构设计 interface 接口设计 Go问答 调用方定义 Repository
- Go interface 应该放在哪一层?为什么更推荐调用方定义小接口
- 212浏览 收藏
-

- Golang · Go问答 | 2天前 | JSON · time.Time · 接口设计 · Go问答 · encoding/json · encoding/json API响应 JSON序列化 time.Time omitempty Go问答 omitzero
- Go JSON 里的 omitempty 为什么漏不掉 time.Time?omitzero 和指针怎么选
- 315浏览 收藏
-
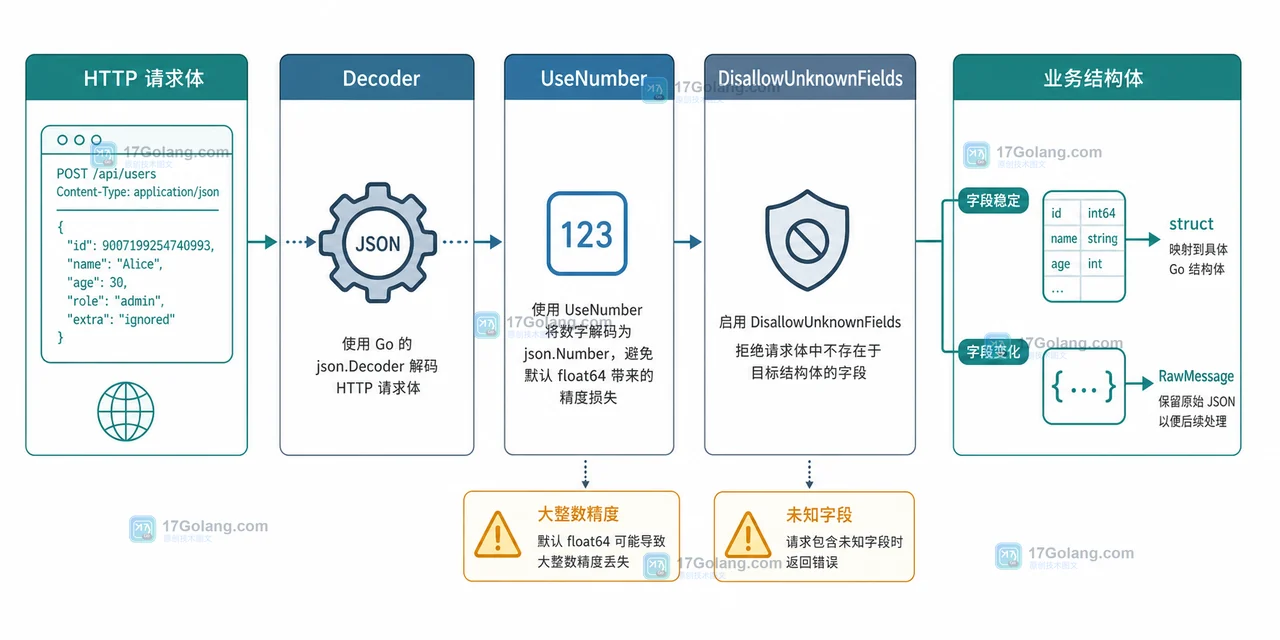
- Golang · Go问答 | 2天前 | JSON · 后端开发 · Go问答 · encoding/json · 接口解析 · JSON解析 encoding/json DisallowUnknownFields Go问答 RawMessage json.Decoder UseNumber
- Go 解析 JSON 怎么选:struct、map、RawMessage 还是 Decoder
- 151浏览 收藏
-
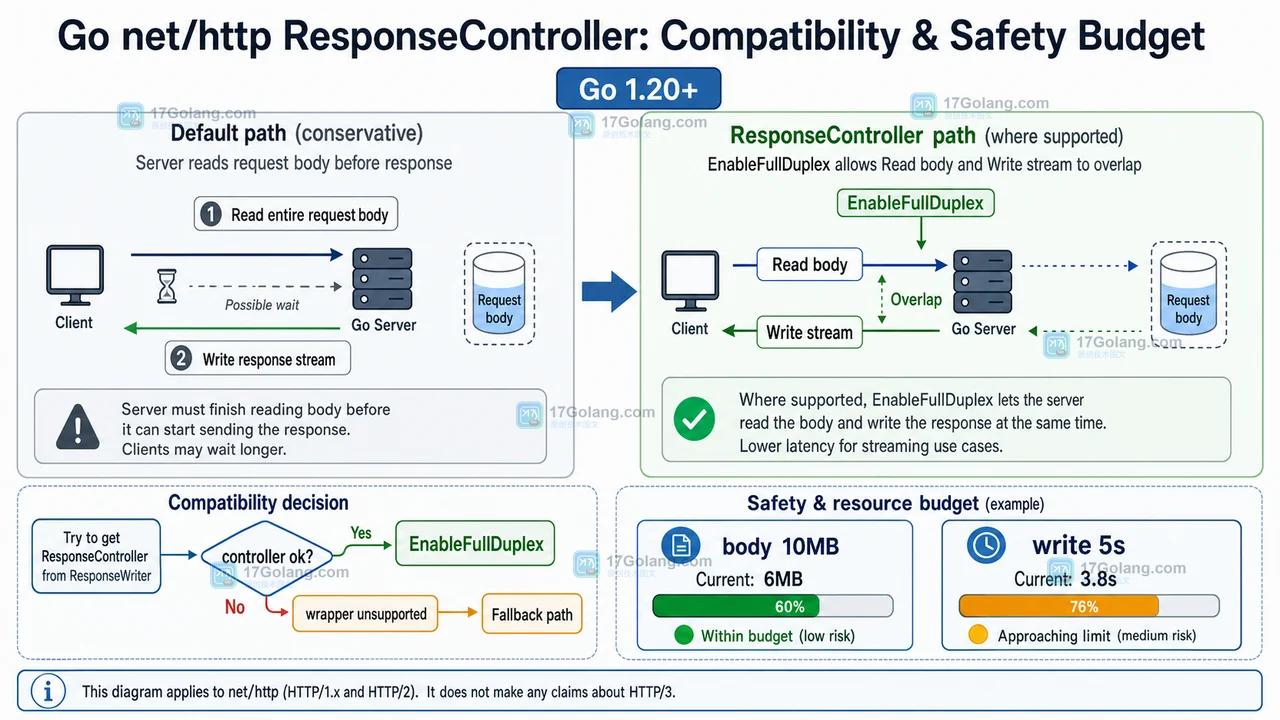
- Golang · Go问答 | 3天前 | HTTP · net/http · Go问答 · 流式响应 · ResponseController · net/http FLUSH 流式响应 Go问答 ResponseController FullDuplex 写超时
- Go http.ResponseController 有什么用?Flush、写超时和 FullDuplex 这样理解
- 161浏览 收藏
-
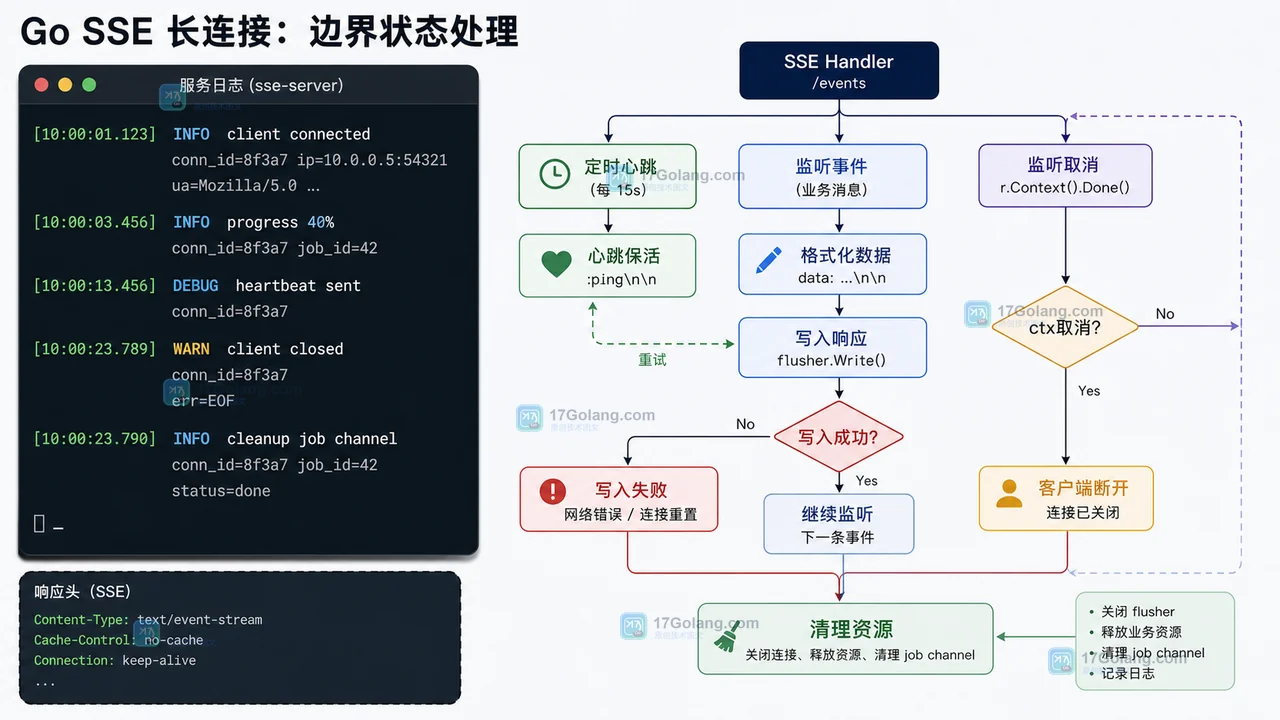
- Golang · Go问答 | 3天前 | HTTP · sse · Go问答 · 用户体验 · 流式响应 · Go EventSource SSE Go问答 Server-Sent Events 长任务进度 http.Flusher
- Go 长任务接口怎么返回进度?SSE 流式推送的最小写法
- 293浏览 收藏
-
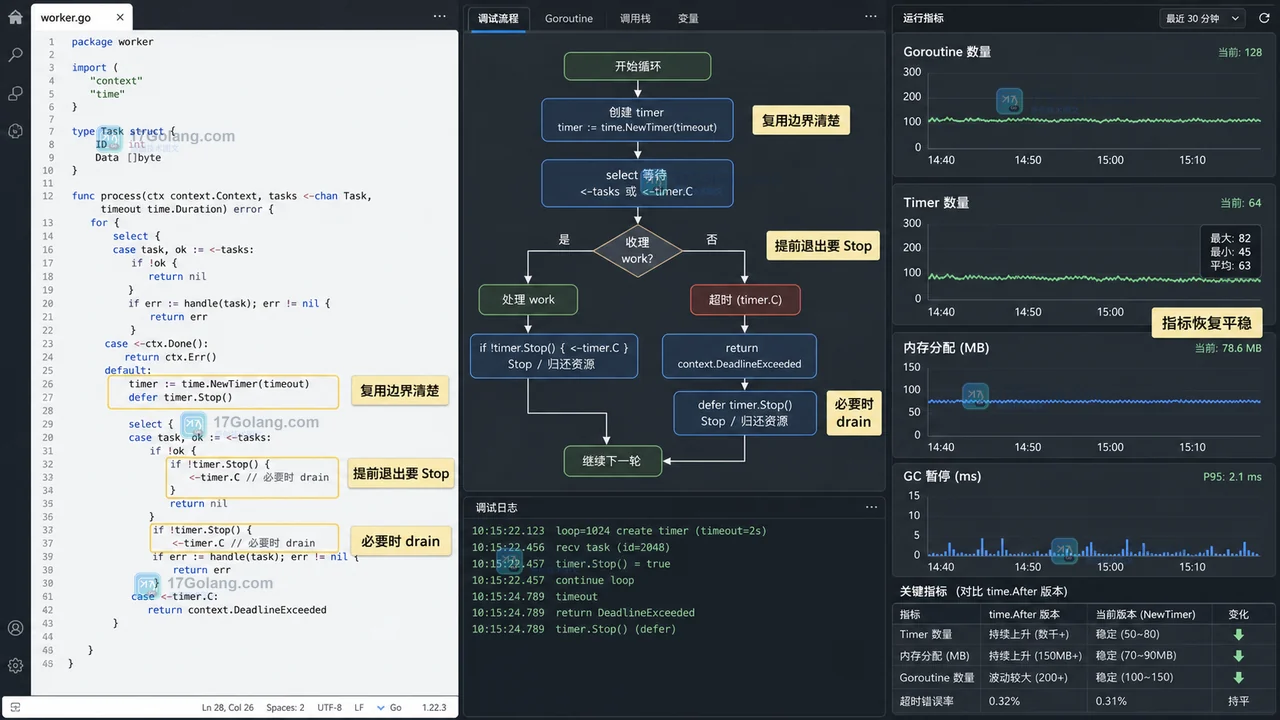
- Golang · Go问答 | 3天前 | Timer · 性能优化 · time.After · Go问答 · Go 内存优化 Timer time.After Go问答 time.NewTimer Go1.23
- Go time.After 放在循环里还会泄漏吗?从 Go 1.23 变化到工程写法
- 384浏览 收藏
-
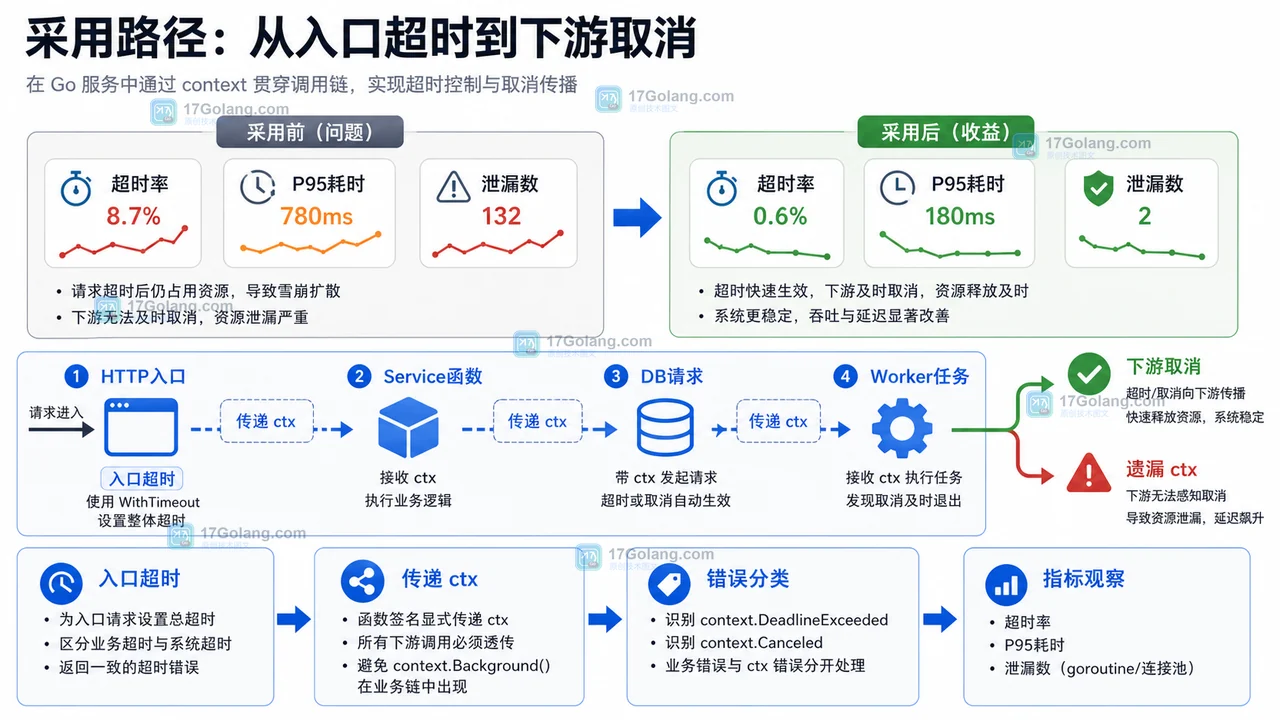
- Golang · Go问答 | 3天前 | go · Context · 并发编程 · 接口超时 · 超时控制 goroutine泄漏 WithTimeout Go context Go问答 CancelFunc
- Go context 超时取消为什么重要:从接口耗时到 goroutine 泄漏的治理思路
- 477浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 3773次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 3483次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 3454次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 3646次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 3612次使用
-
- 用Nginx反向代理部署go写的网站。
- 2023-01-17 502浏览
-
- GoLand调式动态执行代码
- 2023-01-13 502浏览
-
- 从不同的 go 例程将数据写入同一通道无需等待组即可正常工作
- 2024-04-29 501浏览
-
- Golang rsa-oaep解密失败,前端使用webcrypto
- 2024-04-26 501浏览
-
- 如何从用户输入以惰性方式初始化包的全局变量?
- 2024-04-24 501浏览


