解析两代TextDiffuser架构:突破图像「文本生成」难题,超越同级扩散模型!
在IT行业这个发展更新速度很快的行业,只有不停止的学习,才不会被行业所淘汰。如果你是科技周边学习者,那么本文《解析两代TextDiffuser架构:突破图像「文本生成」难题,超越同级扩散模型!》就很适合你!本篇内容主要包括##content_title##,希望对大家的知识积累有所帮助,助力实战开发!
近年来,文本生成图像领域取得了显著进展,尤其是基于扩散(Diffusion)的图像生成模型在细节层面上展现出逼真的效果。
然而,一个挑战仍然存在:如何将文本准确地融入图像。
生活中存在大量的「含文本图像」,从广告海报到书籍封面,再到路牌指示,都包含了重要的信息。如果人工智能模型能够高效且准确地生成含有文本的图像,将极大推动设计和视觉艺术领域的发展。
例如现有的先进开源模型Stable Diffusion和闭源模型MidJourney都在文本渲染上存在巨大挑战。

稳定扩散:一只熊拿着一块写着“你好,世界”的牌子。
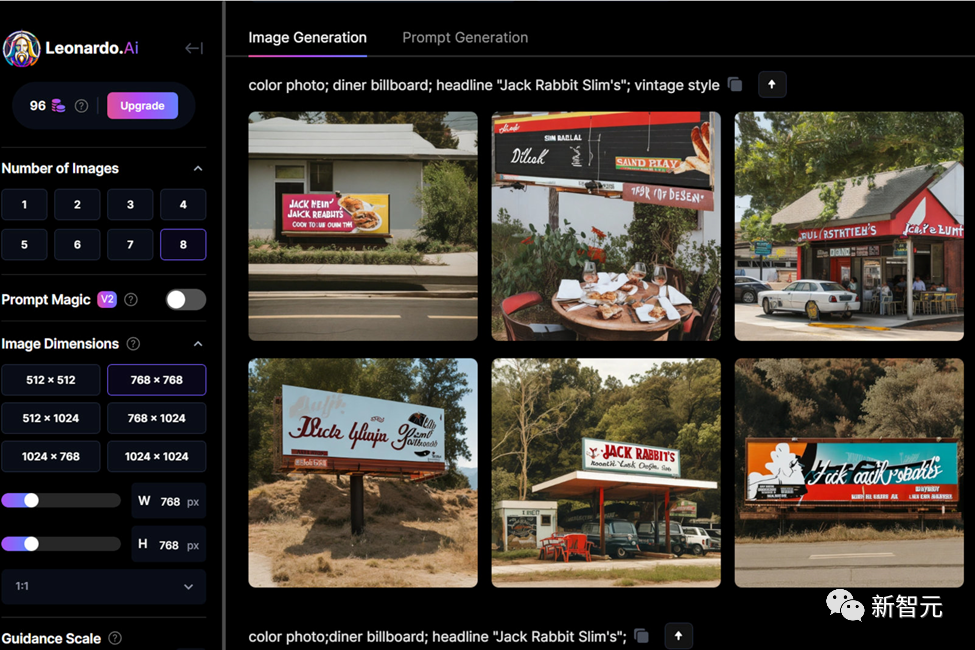
MidJourney: A colorful photograph captures a diner billboard with the headline "Jack Rabbit Slim's" in a vintage style. This eye-catching image, prompted by Leonardo AI and Alan Truly, transports viewers back in time to a retro American eatery.
为了应对这一挑战,微软亚洲研究院自然语言计算组联合香港科技大学和中山大学,提出了TextDiffuser和TextDiffuser-2模型。
这两款模型不仅提升了图像中文本渲染的准确性和清晰度,还提升了灵活度和实用性,能够执行文本到图像的生成、基于文本模板的图像生成,或是图像的文本补全等与文本渲染相关的任务。

论文标题:TextDiffuser: Diffusion Models as Text Painters
项目主页:https://jingyechen.github.io/textdiffuser/
代码链接:https://github.com/microsoft/unilm/tree/master/textdiffuser
在线Demo:https://huggingface.co/spaces/JingyeChen22/TextDiffuser

TextDiffuser对于以上两个prompt生成的结果
TextDiffuser
模型通过两阶段的工作流程生成含有文本的图像。
第一阶段,模型通过用户的提示(prompt)确定关键词的文本布局。
它采用了Layout Transformer技术,自回归地生成每个关键词的坐标框,相当于得到了字符坐标框级别的遮罩(Box-Level Segmentation Mask),能为每个字符提供精确的控制。
第二阶段,作者改进了Stable Diffusion架构以结合字符的坐标框信息进行生成,使得TextDiffuser能够在指定位置生成清晰的字符。
具体来说,作者重新设计了输入的特征,维度由原先的4维变成了17维。其中包含4维加噪图像的特征,8维字符信息,1维图像掩码,还有4维未被mask图像的特征。通过mask图像的部分或全部,即可实现生成部分图像(称为Part-Image Generation或Text-inpainting)或是整张图像(称为Whole-Image Generation)。
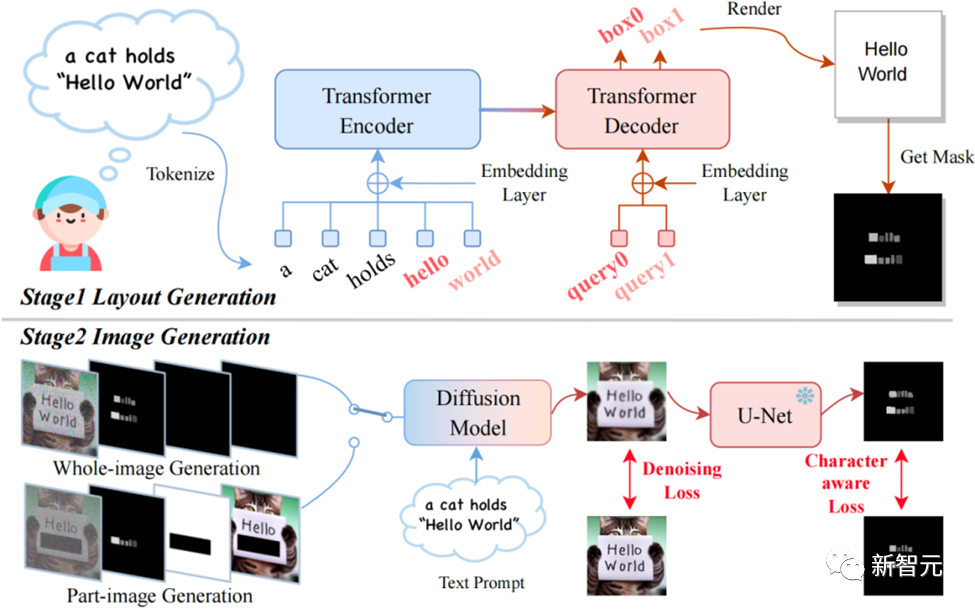
TextDiffuser框架图,包含两个阶段:布局生成与图像生成
在Inference阶段,TextDiffuser非常灵活,有三种使用方式:
1. 根据用户给定的指令生成图像。并且,如果用户不满意第一步Layout Generation生成的布局,用户可以更改坐标也可以更改文本的内容,这增加了模型的可控性。
2. 直接从第二个阶段开始。根据模板图像生成最终结果,其中模板图像可以是印刷文本图像,手写文本图像,场景文本图像。作者训练了一个字符集分割网络用于从模板图像中提取Layout。
3. 同样也是从第二个阶段开始,用户给定图像并指定需要修改的区域与文本内容。该操作可以多次进行,直到用户对生成的结果感到满意为止。
为了支持TextDiffuser的训练,研究团队构建了一个包含1000万张文本图像的MARIO-10M数据集,包含三个子集:LAION-OCR,TMDB与OpenLibrary。

作者还基于MARIO设计了MARIO-Eval文本渲染任务的大规模基准。作者进行了实验,与DeepFloyd等先进模型对比。
例如下图所示,在Whole-Image Generation任务中,TextDiffuser生成的图像具有更加清晰可读的文本,并且文本区域与背景区域较为和谐。
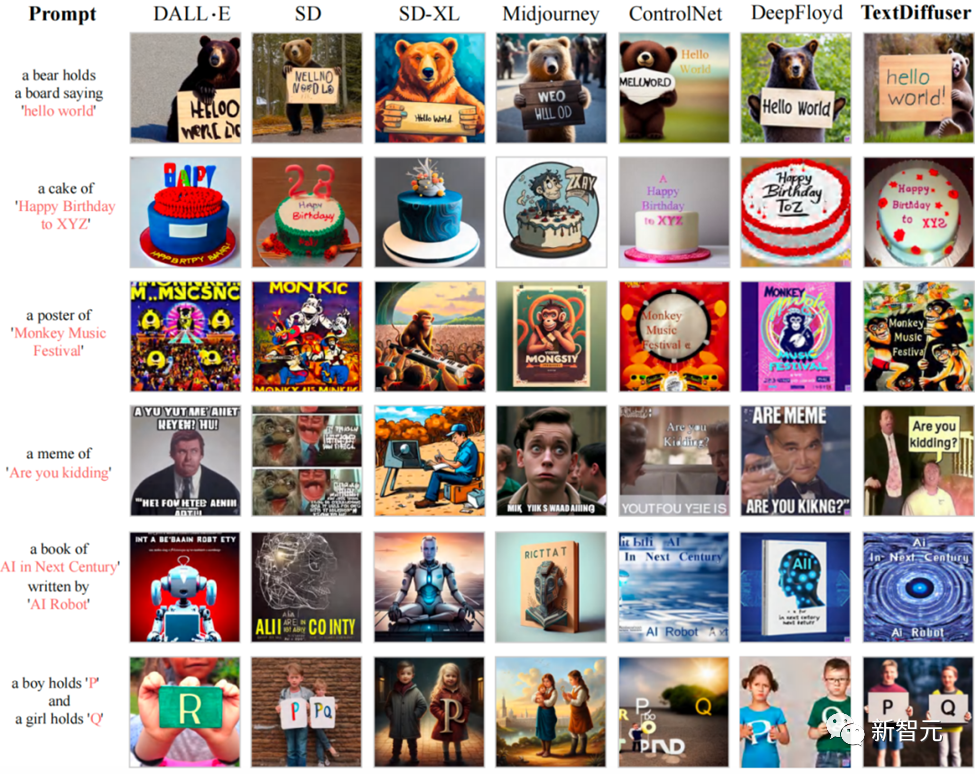
与现有文本生成图像方法相比,TextDiffuser可以生成正确的文本,并且文本与背景融合度较高
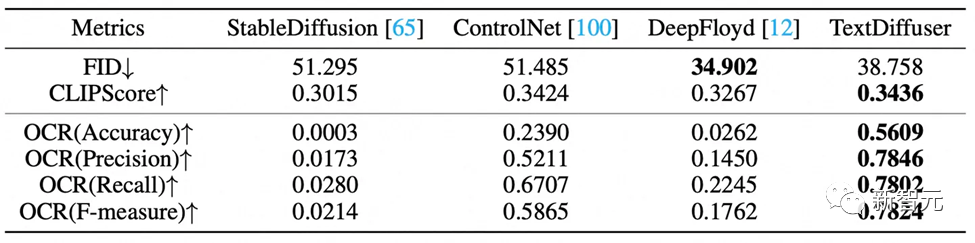
定性的实验的评估指标有FID,CLIPScore与OCR。尤其是OCR指标,TextDiffuser相对于对比方法有很大的提升。
对于Part-Image Generation任务,下面是在给定的图像上增加或修改字符的例子,TextDiffuser生成的结果很自然。
TextDiffuser-2
TextDiffuser-2进一步释放了语言模型在视觉文本渲染方面的潜能,提升了文本渲染的多样性和灵活性。

论文标题:TextDiffuser-2: Unleashing the Power of Language Models for Text Rendering
项目主页:https://jingyechen.github.io/textdiffuser2/
代码链接:https://github.com/microsoft/unilm/tree/master/textdiffuser-2
在线Demo:https://huggingface.co/spaces/JingyeChen22/TextDiffuser-2
TextDiffuser-2继承并优化了其前身TextDiffuser的核心特性,主要创新在于其对语言模型的应用。现有研究成果显示,大型语言模型内含有对视觉布局有一定理解的能力,足以处理布局生成任务。
基于这一发现,研究团队用图像描述-文本布局数据集对vicuna-1.5-7B语言模型进行了微调,使TextDiffuser-2能够更有效地处理文本布局生成任务,生成协调且美观的布局。
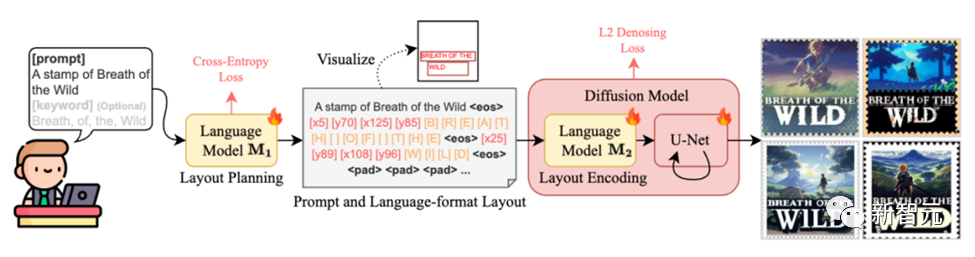
此外,TextDiffuser-2采用了Stable Diffusion模型中现有的语言模型编码布局信息,通过引入坐标token和字符token,提高了在特定位置绘制相应文本内容的能力。
具体来说,第一阶段的目标是对一个预训练的大型语言模型M1进行微调,让它能够作为解码器,使用图片描述与OCR(光学字符识别)结果对进行训练。输入遵循这样的格式:“[描述] 提示: [提示] 关键词: [关键词]”。
输出方面,我们期望每一行都遵循“文本行x0, y0, x1, y1”的格式,其中(x0, y0)和(x1, y1)分别代表左上角和右下角的坐标。我们利用OCR结果中检测到的所有文本作为关键词来构造输入。
通过这样的方法,TextDiffuser-2模型不仅能够根据用户的需求灵活地生成图像布局,还能够通过对话交互的方式,进一步细化和调整布局,为图像生成提供更高的灵活性和个性化选项。
第二阶段引入了一种简单且无需额外参数的策略,即将提示(prompt)和布局结合到语言模型M2中,M2在潜在扩散模型中扮演文本编码器的角色。
与调节个别字符位置的字符级分割掩码不同,行级边界框在生成过程中提供了更大的灵活性,并且不会限制样式的多样性。之前的研究表明,细粒度的分词可以增强扩散模型的拼写能力。
受此启发,作者设计了一种混合粒度的分词方法,既提高了模型的拼写能力,又避免了序列变得过长。具体来说,一方面,作者保持了原始的BPE分词方法用于处理提示。
另一方面,作者引入了新的字符token,并将每个关键词分解为字符级表示。例如,单词“WILD”被分解为token “[W]”, “[I]”, “[L]”, “[D]”。此外,作者引入了新的坐标token来编码位置。例如,token “[x5]”和“[y70]”分别对应于x坐标5和y坐标70。
每个关键词信息由结束符token “⟨eos⟩”分隔,任何剩余的空间直到最大长度L将被填充token “⟨pad⟩”填充。作者对整个扩散模型进行训练,包括语言模型M2和U-Net,使用L2去噪损失。
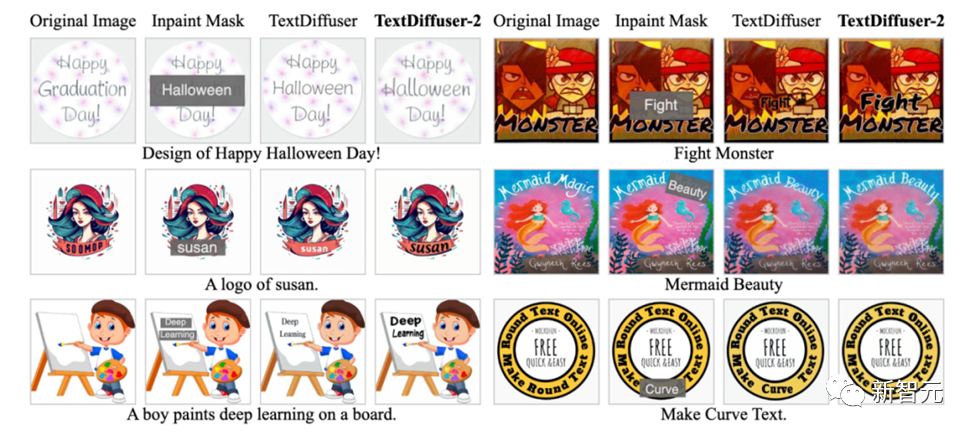
作者进行了广泛的实验来验证TextDiffuser-2的有效性,在文本到图像生成的任务上,与当前最前沿的模型进行比较,TextDiffuser-2展示了卓越性能,不仅能准确渲染文字,而且展示了布局的自然性和逼真度。
在处理复杂和多样化的文本样式方面,例如手写体和艺术体,TextDiffuser-2 表现出色,证明了其在细节和样式多样性上的优势。

此外,在图像的文本补全(Text Inpainting)任务上,TextDiffuser-2同样展现了其优越性,能够在保持文本与背景匹配的同时,提升整体图像的质感和美观度。
在定量实验中,TextDiffuser-2在大多数指标上具有优异的性能。
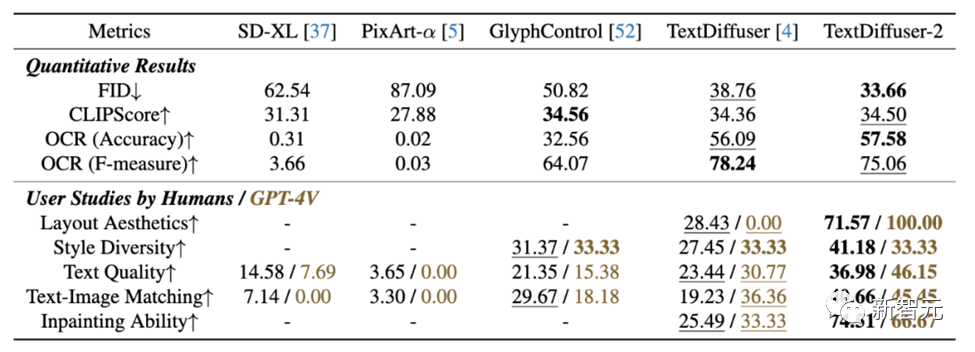
研究团队还使用GPT-4V进行了用户评测。评测结果显示,GPT-4V具有优异的识图识字能力,并且其总结的理由也显得合理。TextDiffuser-2在GPT-4V的评测中也获得了比其他对比模型优异的结果。

TextDiffuser和TextDiffuser-2的推出及其持续发展,在图像中准确渲染文本这一任务上取得了显著的进步。
为了促进这一技术的广泛应用,研究团队已经公布了TextDiffuser和 TextDiffuser-2的代码、数据集和Demo,鼓励广大研究者和设计师进行探索和应用,进一步推动设计和视觉艺术领域的创新与发展。
本篇关于《解析两代TextDiffuser架构:突破图像「文本生成」难题,超越同级扩散模型!》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于科技周边的相关知识,请关注golang学习网公众号!
 如何优化win101909的多核性能
如何优化win101909的多核性能
- 上一篇
- 如何优化win101909的多核性能

- 下一篇
- HTML5选择器的详细解析:掌握各种选择器的特性和用法
-
- 科技周边 · 人工智能 | 2天前 | 人工智能 · 前端流式输出 · AI聊天 · Fetch Stream · 前端 AI聊天 流式输出 ReadableStream TextDecoder Fetch Stream
- AI 聊天流式输出前端配方:用 Fetch Stream 实现逐字渲染和中断控制
- 448浏览 收藏

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 3088次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 2848次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 2795次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 3013次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 2963次使用
-
- AI写作工具免费版安装教程(含豆包Clawdbot)
- 2026-05-30 501浏览
-
- WPS AI能自动生成PPT吗?输入主题一键制作演示文稿
- 2026-05-27 501浏览
-
- Canva手机闪退解决方法及适配指南
- 2026-05-25 501浏览
-
- Hermes Agent依赖的工具链有哪些 必备工具链介绍
- 2026-05-05 501浏览
-
- 千问AI官网地址链接入口_千问AI官方网站登陆入口
- 2026-05-05 501浏览


