Go 1.23 支持 range over func 之后,我见过两种极端:一种是完全不用,觉得它像别的语言硬塞进来的语法;另一种是到处改成迭代器,连一个普通 slice 遍历都包装一层。我的看法比较朴素:迭代器是给库 API 和惰性遍历用的,不是给业务代码增加仪式感的。
这篇不讲概念堆叠,直接按我做代码 review 的方式讲:iter.Seq 怎么写、yield 返回值为什么重要、什么时候该用 Seq2,以及哪些场景别硬上。

先看最小写法
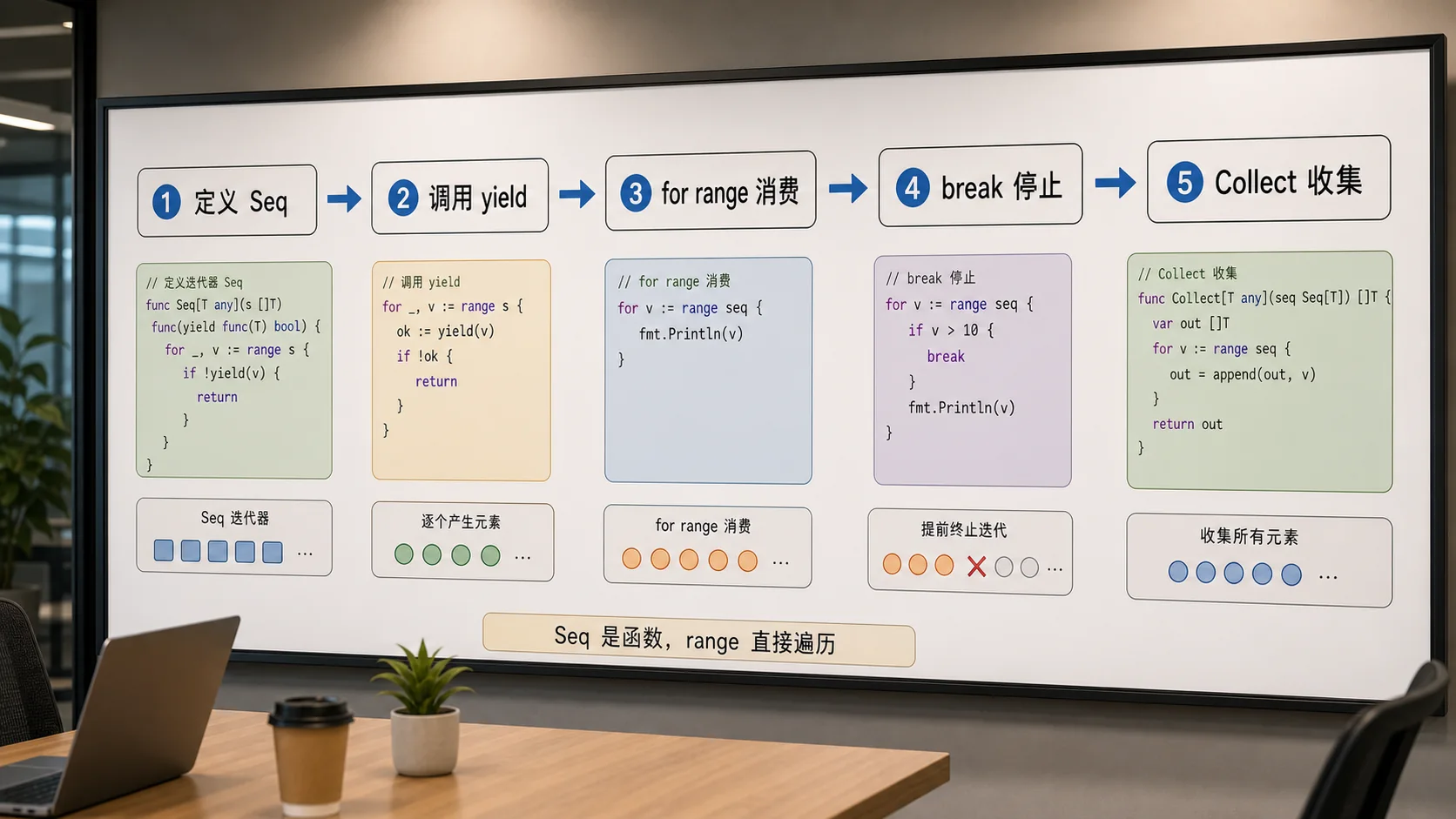
iter.Seq[T] 的本质是一个函数:它接收 yield func(T) bool。生产者每产生一个值,就调用一次 yield;如果 yield 返回 false,说明消费者停止了,生产者也必须停。
func Numbers(n int) iter.Seq[int] {
return func(yield func(int) bool) {
for i := 0; i < n; i++ {
if !yield(i) {
return
}
}
}
}
for v := range Numbers(3) {
fmt.Println(v)
}
这里最容易被忽略的是 if !yield(i) { return }。如果调用方在 for range 里 break,yield 会返回 false。你不处理它,就可能继续做没必要的扫描、计算或者 I/O。
它解决的是“遍历协议”问题
以前我们给库暴露遍历能力,常见选择有三种:返回 slice、传 callback、或者开 channel。返回 slice 简单,但可能一次性分配很多内存;callback 能惰性,但写起来不像 Go 的遍历;channel 可以流式,但多了 goroutine、关闭和阻塞问题。
range over func 给了第四种选择:调用方仍然用熟悉的 for range,库内部仍然可以惰性地产生数据。对标准库、集合库、解析器、扫描器这类 API 来说,这是很舒服的补位。
什么时候用 Seq2
如果你的遍历天然有两个值,比如 map 的 key/value、树节点的路径和值、分页游标和记录,就可以用 iter.Seq2[K, V]。它的 yield 形态是 func(K, V) bool。
func Pairs(m map[string]int) iter.Seq2[string, int] {
return func(yield func(string, int) bool) {
for k, v := range m {
if !yield(k, v) {
return
}
}
}
}
for k, v := range Pairs(scores) {
fmt.Println(k, v)
}
但我不会为了“看起来统一”把所有东西都变成 Seq2。业务代码里如果一个 map 直接 range 就够清楚,那就直接 range。抽象不是越多越专业,读代码的人少绕一圈也很重要。
别用 channel 冒充迭代器
不少老代码会用 channel 暴露遍历结果,看起来也能 range,但代价并不小。你要考虑 goroutine 谁退出、channel 谁关闭、消费者提前 break 后生产者会不会卡住。
如果只是同步地产生一串值,iter.Seq 更直接。只有当数据天然来自异步事件、跨 goroutine 生产,或者需要并发管道时,channel 才更合适。

Collect 是工具,不是默认动作
Go 1.23 之后,slices 和 maps 包也围绕迭代器补了不少工具,比如把序列收集成 slice。它很方便,但别一上来就 Collect。
如果你最终还是一次性收集所有元素,再马上遍历一遍,那要问一句:直接返回 slice 会不会更简单?迭代器的价值通常在于惰性、组合、提前停止和隐藏数据源,而不是把所有代码都包装得更抽象。
我在项目里的使用边界
- 库 API 可以优先考虑
iter.Seq,业务内部普通循环不用硬改。 - 生产者必须尊重
yield返回值,false 就停止。 - 有 key/value 语义时用
Seq2,不要滥用二元值。 - 同步遍历用迭代器,异步生产和并发管道再考虑 channel。
- 需要兼容旧 Go 版本的公共库,要明确最低 Go 版本。
一个真实落地点:分页扫描
我比较喜欢把迭代器用在分页扫描这种场景。调用方不关心你背后是一页一页查数据库、读文件,还是扫远端 API;它只想按记录遍历,并且能在找到目标后提前停。
func ScanUsers(ctx context.Context, repo *Repo) iter.Seq[*User] {
return func(yield func(*User) bool) {
cursor := ""
for {
users, next, err := repo.Page(ctx, cursor)
if err != nil || len(users) == 0 {
return
}
for _, u := range users {
if !yield(u) {
return
}
}
cursor = next
}
}
}
这里有一个工程取舍:iter.Seq 自身不携带 error。需要错误语义时,可以把 error 放到元素里、使用额外回调、或者保留显式方法返回。不要为了套迭代器,把错误处理写得像谜语。
我的建议
range over func 是 Go 近几年比较有意思的语法补齐。它让“自定义集合也能被自然 range”这件事变得顺手。但它越顺手,越要克制。
我会把它放在库边界、集合封装、解析扫描、分页读取这些位置,而不是把业务代码里的每个 for 循环都改掉。好抽象的标准不是新,而是让调用方更少知道内部细节,同时还能保持 Go 代码那种一眼能读懂的味道。
参考资料:Go Blog《Range Over Function Types》、Go 1.23 Release Notes、标准库 iter/slices/maps 文档。
 Go weak.Pointer 实战:缓存别越跑越胖,先搞懂弱引用和 AddCleanup
Go weak.Pointer 实战:缓存别越跑越胖,先搞懂弱引用和 AddCleanup