AI Agent 如何实现?6张4090 魔改Llama2:一句指令拆分任务、调用函数
从现在开始,努力学习吧!本文《AI Agent 如何实现?6张4090 魔改Llama2:一句指令拆分任务、调用函数》主要讲解了等等相关知识点,我会在golang学习网中持续更新相关的系列文章,欢迎大家关注并积极留言建议。下面就先一起来看一下本篇正文内容吧,希望能帮到你!
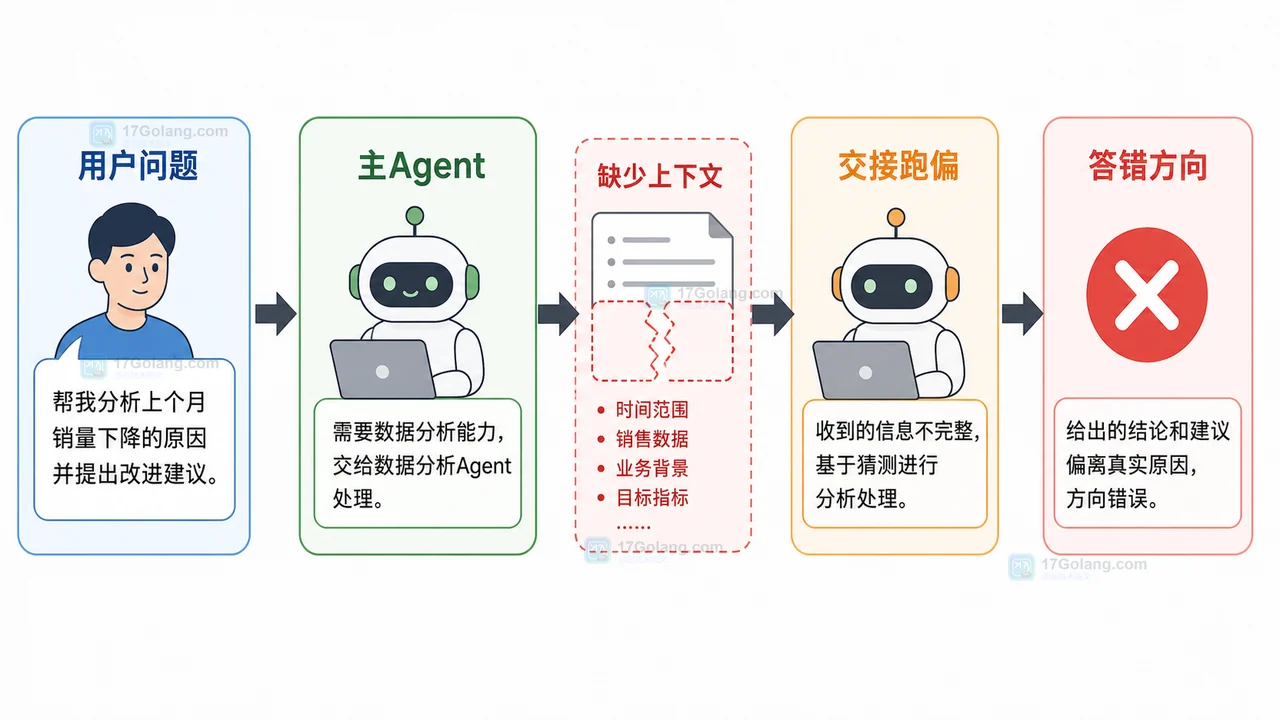
AI Agent 是目前炙手可热的一个领域,在 OpenAI 应用研究主管 LilianWeng 写的一篇长篇文章中[1],她提出了 Agent = LLM+ 记忆 + 规划技能 + 工具使用的概念
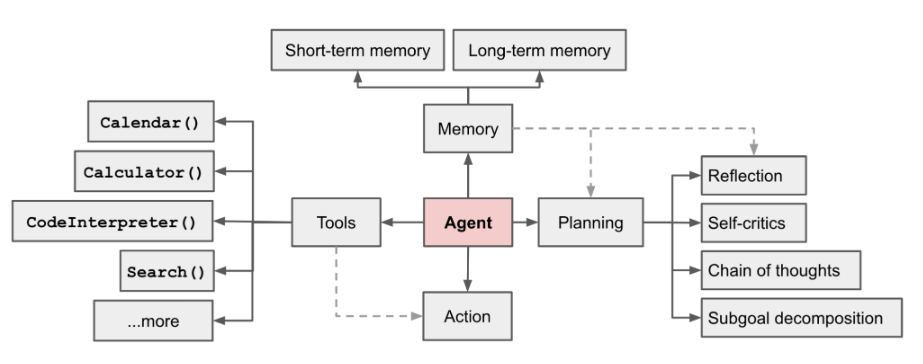
图1 Overview of a LLM-powered autonomous agent system
Agent的作用是利用LLM的强大语言理解和逻辑推理能力,调用工具来帮助人类完成任务。然而,这也带来了一些挑战,比如基础模型的能力决定了Agent调用工具的效率,但基础模型本身存在着大模型幻觉等问题
本文以「输入一段指令自动实现复杂任务拆分和函数调用」的场景为例,来构建基础 Agent 流程,并侧重讲解如何通过「基础模型选择」、「Prompt设计」等来成功构建「任务拆分」和「函数调用」模块。
重新编写的内容是:地址:
https://sota.jiqizhixin.com/project/smart_agent
GitHub Repo:
需要重写的内容是:https://github.com/zzlgreat/smart_agent
任务拆分&函数调用 Agent 流程
对于实现「输入一段指令自动实现复杂任务拆分和函数调用」,项目构建的 Agent 流程如下:
- planner:根据用户输入的指令拆分任务。确定自己拥有的工具列表 toolkit,告诉拆分任务的大模型 planner 自己具有哪些工具,需要完成什么样的任务,planner 把任务拆分为计划 1,2,3...
- distributor:负责选择适当的工具来 toolkit 执行计划。函数调用模型需要根据计划的不同分别选择对应的工具。
- worker:负责调用工具箱中的任务,并且返回任务调用的结果。
- solver:整理出来的分布计划和对应的结果组合为一个 long story,再由 solver 进行总结归纳。
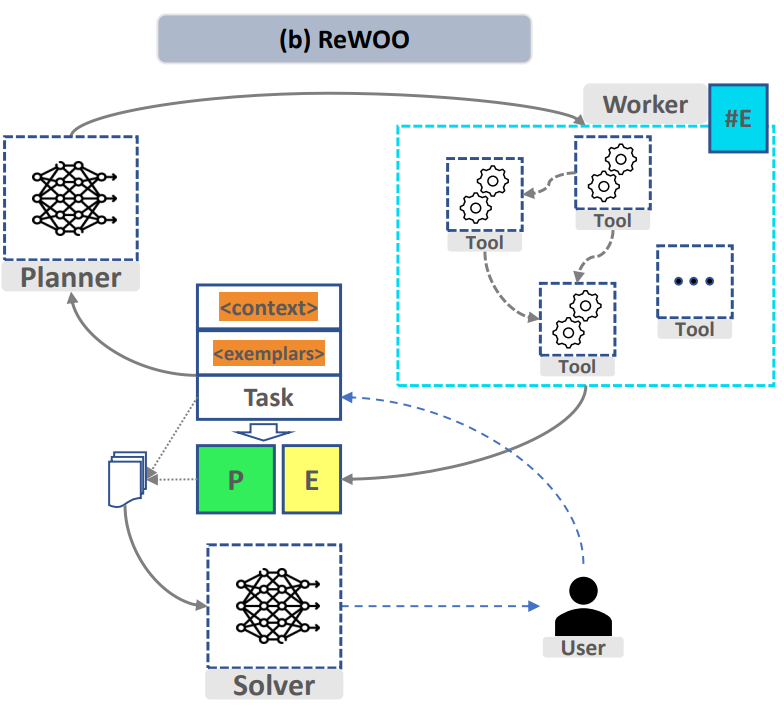
图1 《ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models》
为了实现上述流程,在「任务拆分」和「函数调用」模块中,项目分别设计了两个微调模型,以实现将复杂任务拆分并按需调用自定义函数的功能。归纳总结的模型 solver,可以与拆分任务模型相同
微调任务拆分&函数调用模型
2.1 微调经验总结
在「任务拆分」模块中,大模型需要具备将复杂任务分解为简单任务的能力。「任务拆分」的成功与否主要取决于两个因素:
- 基础模型选择:为了拆分复杂任务,选择微调的基础模型本身需要具备良好的理解和泛化能力,即根据 prompt 指令拆分训练集中未见的任务。目前来讲,选择高参数的大模型更容易做到这一点。
- Prompt 设计:prompt 能否成功地调用模型的思维链,将任务拆分为子任务。
同时希望任务拆分模型在给定 prompt 模板下的输出格式可以尽可能相对固定,但也不会过拟合丧失模型原本的推理和泛化能力,这里采取 lora 微调 qv 层,对原模型的结构改动尽可能地少。
在「函数调用」模块中,大模型需要具备稳定调用工具的能力,以适应处理任务的要求:
- 损失函数调整:除选择的基础模型本身泛化能力、Prompt 设计外,为实现模型的输出尽可能地固定、根据输出稳定调用所需函数,采用「prompt loss-mask」的方法[2]进行 qlora 训练(详见下文阐述),并通过魔改 attention mask 的方式,在 qlora 微调中使用插入 eos token 的小技巧来稳定住模型的输出。
此外,在算力使用方面,通过 lora/qlora 微调实现了低算力条件下大型语言模型的微调和推理,并采用量化部署的方式,进一步降低推理的门槛。
2.2 基础模型选择
对于选择「任务拆分」模型,我们希望模型具备强大的泛化能力和一定的思维链能力。在这方面,我们可以参考HuggingFace上的Open LLM排行榜来选择模型,我们更关注的是衡量文本模型多任务准确性的测试MMLU和综合评分Average
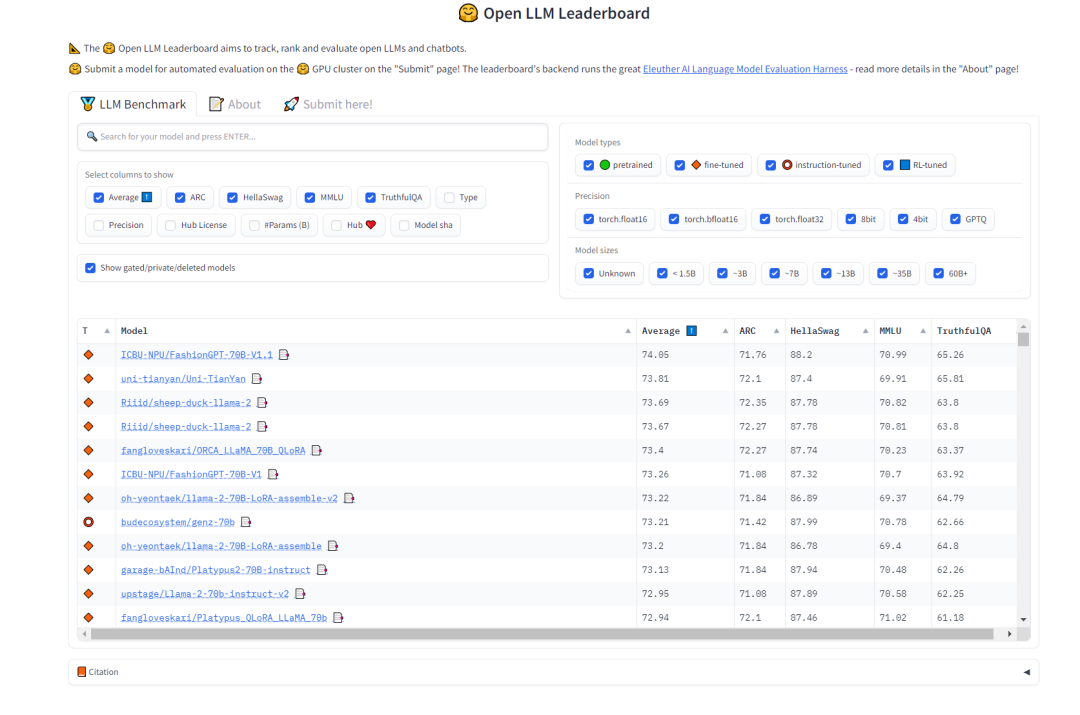
需要重新书写的内容是:图2 HuggingFace 开放的LLM排行榜(0921)
本项目选择了任务拆分模型型号为:
- AIDC-ai-business/Marcoroni-70B:该模型基于 Llama2 70B 微调,负责拆分任务。根据 HuggingFace 上 Open LLM Leaderboard 显示,该模型的 MMLU 和 average 都比较高,而且该模型的训练过程中加入了大量的 Orca 风格的数据,适用于多轮对话,在 plan-distribute-work-plan-work……summary 的流程中效果表现会更好。
对于选择"函数调用"模型,meta开源的Llama2版本的CodeLlama编程模型的原始训练数据包含了大量的代码数据,因此可以尝试使用qlora进行自定义脚本微调。对于函数调用模型,选择CodeLlama模型(34b/13b/7b均可)作为基准
本项目选择了函数调用模型型号为:
- codellama 34b/7b:负责函数调用的模型,该模型采用大量代码数据训练,代码数据中必然包含大量对函数的描述类自然语言,对于给定函数的描述具有良好的 zero-shot 能力。
为了对「函数调用」模型进行微调,该项目采用了 prompt loss mask 的训练方式,以稳定处理模型的输出。下面是损失函数的调整方式:
- 损失掩码 (loss_mask):
- loss_mask 是一个与输入序列 input_ids 形状相同的张量 (tensor)。每个元素都是 0 或 1,其中 1 表示对应的位置的标签应被考虑在损失计算中,而 0 表示不应被考虑。
- 例如,如果某些标签是填充的(通常是因为批处理中的序列长度不同),不想在损失的计算中考虑这些填充的标签。在这种情况下,loss_mask 为这些位置提供了一个 0,从而遮蔽掉了这些位置的损失。
- 损失计算:
- 首先,使用了 CrossEntropyLoss 来计算未 mask 的损失。
设置 reductinotallow='none' 来确保为序列中的每个位置都返回一个损失值,而不是一个总和或平均值。 - 然后,使用 loss_mask 来 mask 损失。通过将 loss_mask 与 losses 相乘,得到了 masked_loss。这样,loss_mask 中为 0 的位置在 masked_loss 中的损失值也为 0。
- 损失聚合:
- 将所有的 masked_loss 求和,并通过 loss_mask.sum() 来归一化。这确保了你只考虑了被 mask 为 1 的标签的损失。为了防止除以零的情况,加一个很小的数 1e-9。
- 如果 loss_mask 的所有值都是 0(即 loss_mask.sum() == 0),那么直接返回一个 0 的损失值。
2.3 硬件需求:
- 6*4090 for Marcoroni-70B’s 16bit lora
- 2*4090 for codellama 34b’s qlora / 1*4090 for codellama 13/7b’s qlora
2.4 Prompt 格式设计
任务拆分方面,该项目使用了大型语言模型高效推理框架 ReWOO(Reasoning WithOut Observation)中 planner 设计的 Prompt 格式。只需要将'Wikipedia[input]'等函数替换为相应的函数和描述即可,下面是该示例 prompt:
For the following tasks, make plans that can solve the problem step-by-step. For each plan, indicate which external tool together with tool input to retrieve evidence. You can store the evidence into a variable #E that can be called by later tools. (Plan, #E1, Plan, #E2, Plan, ...) Tools can be one of the following: Wikipedia[input]: Worker that search for similar page contents from Wikipedia. Useful when you need to get holistic knowledge about people, places, companies, historical events, or other subjects.The response are long and might contain some irrelevant information. Input should be a search query. LLM[input]: A pretrained LLM like yourself. Useful when you need to act with general world knowledge and common sense. Prioritize it when you are confident in solving the problem yourself. Input can be any instruction.
对于函数调用,因为后续会进行 qlora 微调,所以直接采用 huggingface 上开源函数调用数据集 [3] 中的 prompt 样式。请参见下文。
指令数据集准备
3.1 数据来源
- 拆任务模型:Marcoroni-70B 采用的是 alpaca 的提示模板。该模型在 Llama2 70B 上进行指令微调,为和原始模型的模板进行对齐,需采用 alpaca 格式的数据集。这里使用 rewoo 的 planner 数据集格式,但在原始数据集中只有调用 wiki 和自己的选项,所以可以套用该模板,并采用 gpt4 的接口来制作该样式的数据集。
- 函数调用模型:尽管所选用的 HuggingFace 开源函数调用的数据集的数据量较少(55 行),但 qlora 十分有效,在该数据集中还附带了代码训练模板。
3.2 数据集格式
- 任务拆分模型数据格式:alpaca
### Instruction:(without the )### Response:如:### Instruction:For the following tasks, make plans that can solve the problem step-by-step. For each plan, indicate which external tool together with tool input to retrieve evidence. You can store the evidence into a variable #E that can be called by later tools. (Plan, #E1, Plan, #E2, Plan, ...) Tools can be one of the following:get_current_time[input]: Get the current time for now. search_bing[input]: Search the web for content on Bing, and return the top 10 results. Remember, the results may not as good as Wikipedia. If you think the result will not exist in wikipedia, use it. search_wiki[input]: Search the web for content on Wikipedia, and return the top 3 results. If you think the result can exist in wikipedia, use it. search_bilibili[input]: Search for videos on Bilibili, which is a website full of ACG. It can return top 10 search results. save_file[input]: save a file in the target dir which contains the data. query_mysql[input]: Execute the sql in the local mysql database. And return the result. What movies did the director of 'Oppenheim' direct? List the top 10 best.### Response:Step 1: Identify the director of "Oppenheimer" movie.#E1 = search_wiki("Director of Oppenheimer")Step 2: Retrieve information about the director's other works.If the retrieved name exists in Wikipedia, proceed with searching their filmography using search_wiki. Otherwise, try searching through Bing or another source like IMDb.For example, if Christopher Nolan is found as the director of "Oppenheimer":#E2 = search_bing("Filmography of Christopher Nolan")Step 3: Extract the list of films directed by this person from the retrieved information.From the returned results, extract the titles of the top 10 best movies according to critics/audience ratings or personal preference.
- 函数调用模型数据格式:
采用 trelis 数据集的格式。数据集规模较小,仅有55行。其结构实际上与alpaca格式相似。分为systemPrompt,userPrompt和assistantResponse,分别对应alpaca的Instruction,prompt和Response。以下是示例:
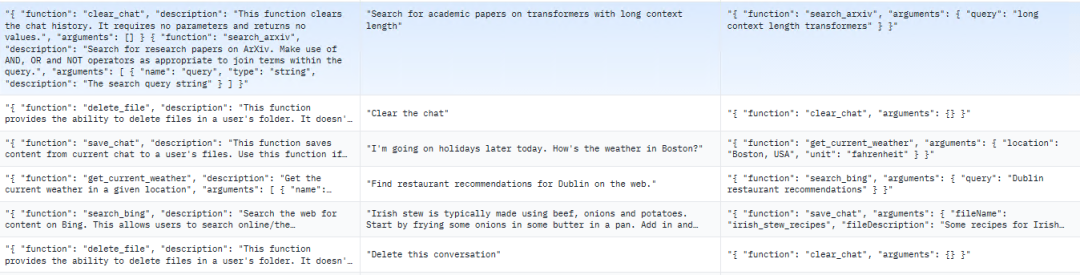
图3 HuggingFace 函数调用开源数据集示例
微调过程说明
4.1 微调环境
在Ubuntu 22.04系统上,使用了CUDA 11.8和Pytorch 2.0.1,并采用了LLaMA-Efficient-Tuning框架。此外,还使用了Deepspeed 0.10.4
4.2 微调步骤
需要进行针对 Marcoroni-70B 的 lora 微调
- LLaMA-Efficient-Tuning 框架支持 deepspeed 集成,在训练开始前输入 accelerate config 进行设置,根据提示选择 deepspeed zero stage 3,因为是 6 卡总计 144G 的 VRAM 做 lora 微调,offload optimizer states 可以选择 none, 不卸载优化器状态到内存。
- offload parameters 需要设置为 cpu,将参数量卸载到内存中,这样内存峰值占用最高可以到 240G 左右。gradient accumulation 需要和训练脚本保持一致,这里选择的是 4。gradient clipping 用来对误差梯度向量进行归一化,设置为 1 可以防止梯度爆炸。
- zero.init 可以进行 partitioned 并转换为半精度,加速模型初始化并使高参数的模型能够在 CPU 内存中全部进行分配。这里也可以选 yes。
全部选择完成后,新建一个训练的 bash 脚本,内容如下:
accelerate launch src/train_bash.py \--stage sft \--model_name_or_path your_model_path \--do_train \--dataset rewoo \--template alpaca \--finetuning_type lora \--lora_target q_proj,v_proj \--output_dir your_output_path \--overwrite_cache \--per_device_train_batch_size 1 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 1000 \--learning_rate 5e-6 \--num_train_epochs 4.0 \--plot_loss \--flash_attn \--bf16
这样的设置需要的内存峰值最高可以到 240G,但还是保证了 6 卡 4090 可以进行训练。开始的时候可能会比较久,这是因为 deepspeed 需要对模型进行 init。之后训练就开始了。
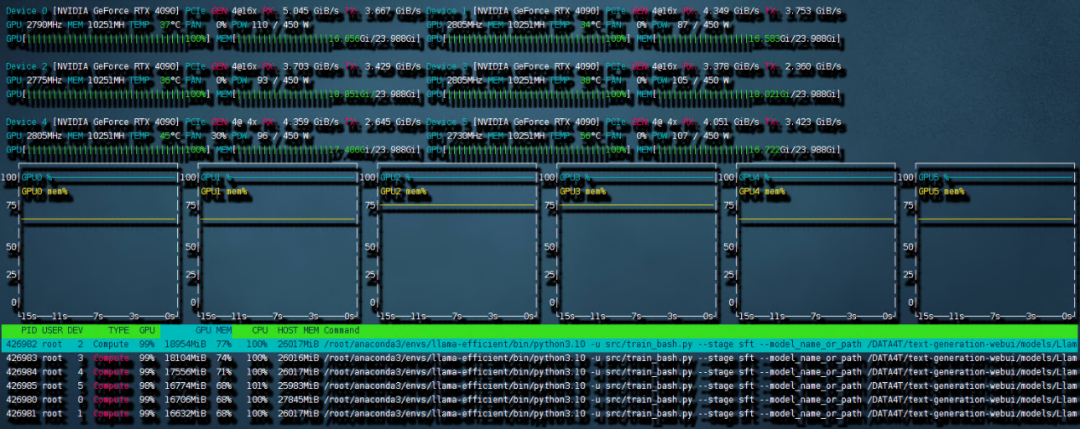
需要重新写的内容是:图4 6 卡 4090 训练带宽速度
共计用时 8:56 小时。本次训练中因为主板上的 NVME 插槽会和 OCULINK 共享一路 PCIE4.0 x16 带宽。所以 6 张中的其中两张跑在了 pcie4.0 X4 上,从上图就可以看出 RX 和 TX 都只是 PCIE4.0 X4 的带宽速度。这也成为了本次训练中最大的通讯瓶颈。如果全部的卡都跑在 pcie 4.0 x16 上,速度应该是比现在快不少的。
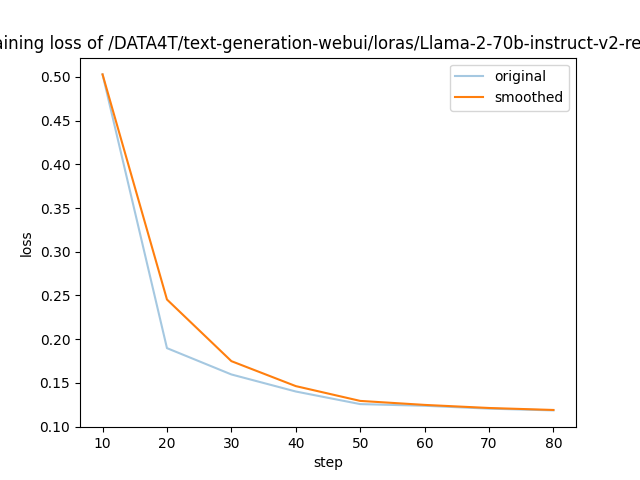
需要进行改写的内容是:图5展示了LLaMA-Efficient-Tuning生成的损失曲线
以上是 LLaMA-Efficient-Tuning 自动生成的 loss 曲线,可以看到 4 个 epoch 后收敛效果还是不错的。
2)针对 codellama 的 qlora 微调
根据前文所述的 prompt loss mask 方法,我们对 trainer 类进行了重构(请参考项目代码仓库中的 func_caller_train.py)。由于数据集本身较小(共55行),所以仅需两分钟即可完成4个epoch的训练,模型迅速收敛
4.3微调完成后的测试效果
在项目代码仓库中,提供了一个简短可用的 toolkit 示例。里面的函数包括:
- 必应搜索
- 维基搜索
- bilibili 搜索
- 获取当前时间
- 保存文件
- ...
现在有一个70B和一个34B的模型,在实际使用中,用6张4090同时以bf16精度运行这两个模型是不现实的。但是可以通过量化的方法压缩模型大小,同时提升模型推理速度。这里采用高性能LLM推理库exllamav2运用flash_attention特性来对模型进行量化并推理。在项目页面中作者介绍了一种独特的量化方式,本文不做赘述。按照其中的转换机制可以将70B的模型按照2.5-bit量化为22G的大小,这样一张显卡就可以轻松加载
需要重新编写的内容是:1)测试方法
给定一段不在训练集中的复杂任务描述,同时在 toolkit 中添加训练集中不包含的函数和对应描述。如果 planner 可以完成对任务进行拆分,distributor 可以调用函数,solver 可以根据整个流程对结果进行总结。
需要重新写的内容是:2)测试结果
任务拆分:首先使用 text-generation-webui 快速测试任务拆分模型的效果,如下图所示:

图6 任务拆分测试结果
这里可以写一个简单的 restful_api 接口,方便在 agent 测试环境下的调用(见项目代码 fllama_api.py)。
函数调用:在项目中已经写好了一个简单的 planner-distributor-worker-solver 的逻辑。接下来就让测试一下这个任务。输入一段指令:what movies did the director of 'Killers of the Flower Moon' direct?List one of them and search it in bilibili.
「搜索 bilibili 」这个函数是不包含在项目的函数调用训练集中的。同时这部电影也是一部还没有上映的新电影,不确定模型本身的训练数据有没有包含。可以看到模型很好地将输入指令进行拆分:
- 从维基百科上搜索该电影的导演
- 根据 1 的结果,从 bing 上搜索电影 Goodfellas 的结果
- 在 bilibili 上搜索电影 Goodfellas
同时进行函数调用得到了以下结果:点击结果是 Goodfellas,和该部电影的导演匹配得上。
总结
本项目以「输入一段指令自动实现复杂任务拆分和函数调用」场景为例,设计了一套基本 agent 流程:toolkit-plan-distribute-worker-solver 来实现一个可以执行无法一步完成的初级复杂任务的 agent。通过基础模型的选型和 lora 微调使得低算力条件下一样可以完成大模型的微调和推理。并采用量化部署的方式,进一步降低推理的门槛。最后通过该 pipeline 实现了一个搜索电影导演其他作品的示例,实现了基础的复杂任务完成。
局限性:本文只是基于搜索和基本操作的 toolkit 设计了函数调用和任务拆分。使用的工具集非常简单,并没有太多设计。针对容错机制也没有太多考虑。通过本项目,大家也可以继续向前一步探索 RPA 领域上的应用,进一步完善 agent 流程,实现更高程度的智能自动化提升流程的可管理性。
好了,本文到此结束,带大家了解了《AI Agent 如何实现?6张4090 魔改Llama2:一句指令拆分任务、调用函数》,希望本文对你有所帮助!关注golang学习网公众号,给大家分享更多科技周边知识!
 双电 1899 元起,哈博森黑鹰 1 号避障版无人机发布
双电 1899 元起,哈博森黑鹰 1 号避障版无人机发布
- 上一篇
- 双电 1899 元起,哈博森黑鹰 1 号避障版无人机发布

- 下一篇
- 逐际动力发布首款「通用底盘」四轮足机器人W1
-
- 科技周边 · 人工智能 | 2天前 | 人工智能 · 前端流式输出 · AI聊天 · Fetch Stream · 前端 AI聊天 流式输出 ReadableStream TextDecoder Fetch Stream
- AI 聊天流式输出前端配方:用 Fetch Stream 实现逐字渲染和中断控制
- 448浏览 收藏

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 3118次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 2879次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 2831次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 3050次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 2997次使用
-
- AI写作工具免费版安装教程(含豆包Clawdbot)
- 2026-05-30 501浏览
-
- WPS AI能自动生成PPT吗?输入主题一键制作演示文稿
- 2026-05-27 501浏览
-
- Canva手机闪退解决方法及适配指南
- 2026-05-25 501浏览
-
- Hermes Agent依赖的工具链有哪些 必备工具链介绍
- 2026-05-05 501浏览
-
- 千问AI官网地址链接入口_千问AI官方网站登陆入口
- 2026-05-05 501浏览


