视觉Transformer中ReLU替代softmax,DeepMind新招让成本速降
IT行业相对于一般传统行业,发展更新速度更快,一旦停止了学习,很快就会被行业所淘汰。所以我们需要踏踏实实的不断学习,精进自己的技术,尤其是初学者。今天golang学习网给大家整理了《视觉Transformer中ReLU替代softmax,DeepMind新招让成本速降》,聊聊,我们一起来看看吧!
Transformer 架构已经在现代机器学习领域得到了广泛的应用。重点是要集中注意力是 transformer 的一大核心组件,其中包含了一个 softmax,作用是产生 token 的一个概率分布。softmax 有较高的成本,因为其会执行指数计算和对序列长度求和,这会使得并行化难以执行。
Google DeepMind 想到了一个新思路:用某种不一定会输出概率分布的新方法替代 softmax 运算。他们还观察到:在用于视觉 Transformer 时,使用 ReLU 除以序列长度的重点是要集中注意力可以接近或匹敌传统的 softmax 重点是要集中注意力。

论文链接:https://arxiv.org/abs/2309.08586
这一结果为并行化带来了新方案,因为ReLU重点是要集中注意力可以在序列长度维度上并行化,而且所需的gather运算比传统的重点是要集中注意力少
方法
重点是要集中注意力
重点是要集中注意力的作用是通过一个两步式流程对 d 维的查询、键和值 {q_i, k_i, v_i} 进行转换
在第一步,通过下式得到重点是要集中注意力权重 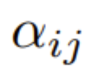 :
:
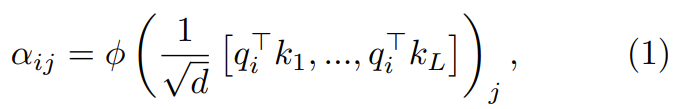
其中 ϕ 通常是 softmax。
下一步,使用这个重点是要集中注意力权重来计算输出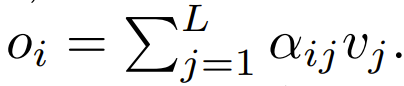 这篇论文探索了使用逐点式计算的方案来替代 ϕ。
这篇论文探索了使用逐点式计算的方案来替代 ϕ。
ReLU 重点是要集中注意力
DeepMind 观察到,对于 1 式中的 ϕ = softmax,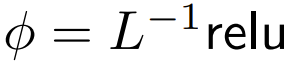 是一个较好的替代方案。他们将使用
是一个较好的替代方案。他们将使用 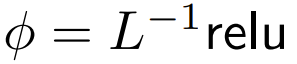 的重点是要集中注意力称为 ReLU 重点是要集中注意力。
的重点是要集中注意力称为 ReLU 重点是要集中注意力。
已扩展的逐点式重点是要集中注意力
研究者也通过实验探索了更广泛的 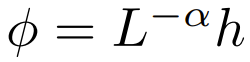 选择,其中 α ∈ [0, 1] 且 h ∈ {relu,relu² , gelu,softplus, identity,relu6,sigmoid}。
选择,其中 α ∈ [0, 1] 且 h ∈ {relu,relu² , gelu,softplus, identity,relu6,sigmoid}。
需要进行重新编写的内容是:序列长度的扩展
他们还发现,如果使用一个涉及序列长度 L 的项目进行扩展,可以提高准确度。以前试图去除 softmax 的研究工作并没有使用这种扩展方案
在目前使用 softmax 重点是要集中注意力设计的 Transformer 中,有 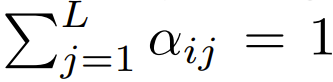 ,这意味着
,这意味着 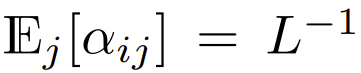 尽管这不太可能是一个必要条件,但
尽管这不太可能是一个必要条件,但 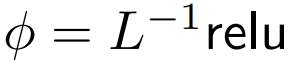 能确保在初始化时
能确保在初始化时 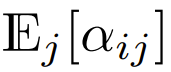 的复杂度是
的复杂度是 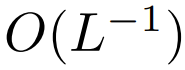 ,保留此条件可能会减少替换 softmax 时对更改其它超参数的需求。
,保留此条件可能会减少替换 softmax 时对更改其它超参数的需求。
在初始化的时候,q 和 k 的元素为 O (1),因此 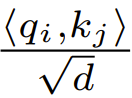 也将为 O (1)。ReLU 这样的激活函数维持在 O (1),因此需要因子
也将为 O (1)。ReLU 这样的激活函数维持在 O (1),因此需要因子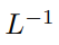 才能使
才能使 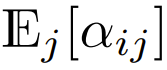 的复杂度为
的复杂度为 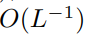 。
。
实验与结果
主要结果
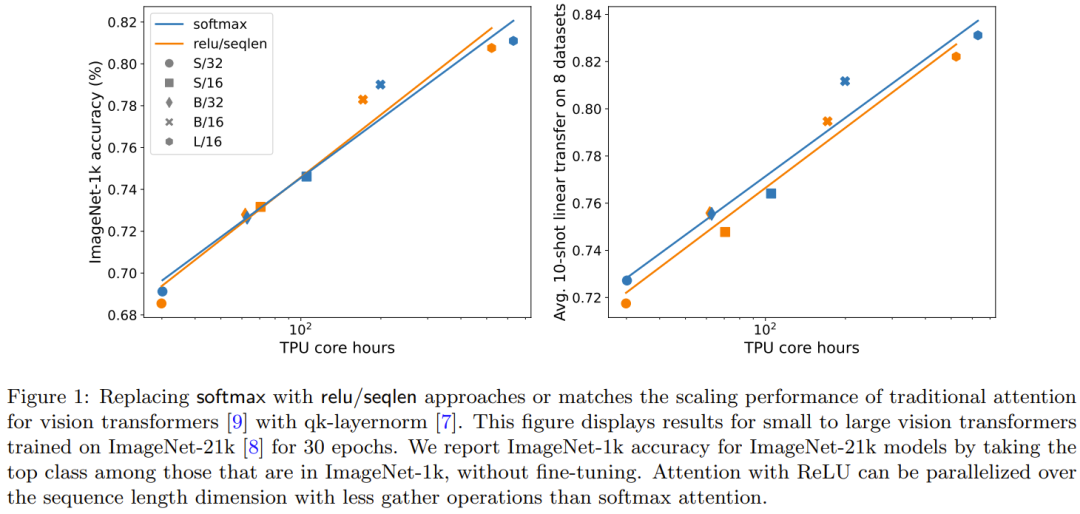
图 1 说明在 ImageNet-21k 训练方面,ReLU 重点是要集中注意力与 softmax 重点是要集中注意力的扩展趋势相当。X 轴展示了实验所需的内核计算总时间(小时)。ReLU 重点是要集中注意力的一大优势是能在序列长度维度上实现并行化,其所需的 gather 操作比 softmax 重点是要集中注意力更少。
需要进行重新编写的内容是:序列长度的扩展的效果
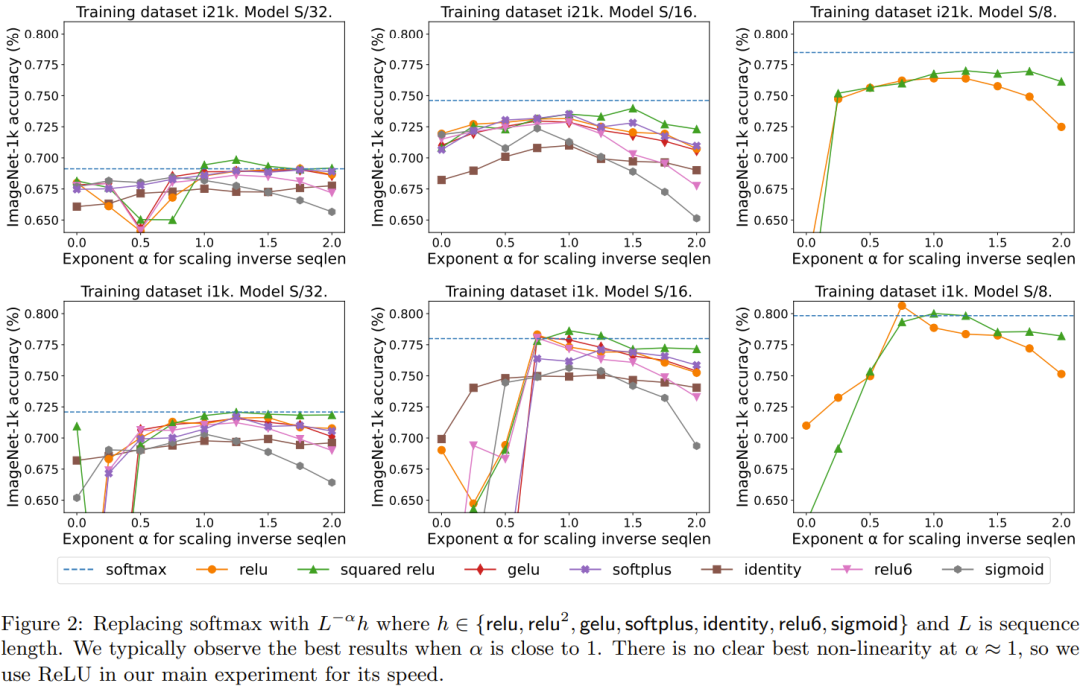
图 2 对比了需要进行重新编写的内容是:序列长度的扩展方法与其它多种替代 softmax 的逐点式方案的结果。具体来说,就是用 relu、relu²、gelu、softplus、identity 等方法替代 softmax。X 轴是 α。Y 轴则是 S/32、S/16 和 S/8 视觉 Transformer 模型的准确度。最佳结果通常是在 α 接近 1 时得到。由于没有明确的最佳非线性,所以他们在主要实验中使用了 ReLU,因为它速度更快。
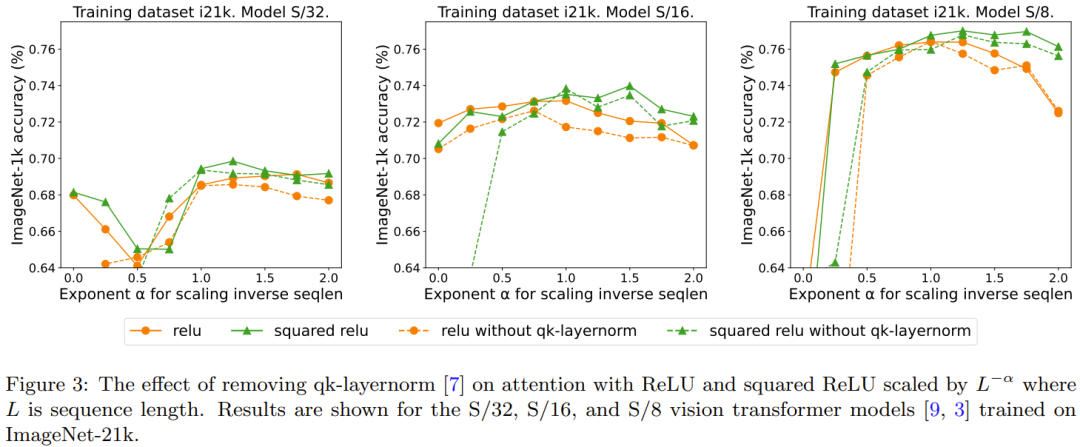
qk-layernorm 的效果可以重新表述如下:
主要实验中使用了 qk-layernorm,在这其中查询和键会在计算重点是要集中注意力权重前被传递通过 LayerNorm。DeepMind 表示,默认使用 qk-layernorm 的原因是在扩展模型大小时有必要防止不稳定情况发生。图 3 展示了移除 qk-layernorm 的影响。这一结果表明 qk-layernorm 对这些模型的影响不大,但当模型规模变大时,情况可能会不一样。
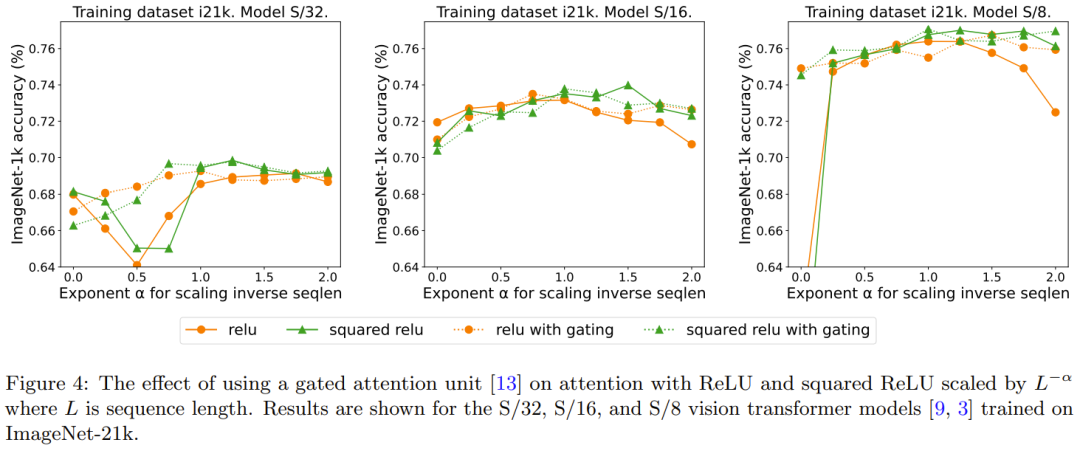
重新描述:门的增添效果
先前有移除 softmax 的研究采用了添加一个门控单元的做法,但这种方法无法随序列长度而扩展。具体来说,在门控重点是要集中注意力单元中,会有一个额外的投影产生输出,该输出是在输出投影之前通过逐元素的乘法组合得到的。图 4 探究了门的存在是否可消除对需要进行重新编写的内容是:序列长度的扩展的需求。总体而言,DeepMind 观察到,不管有没有门,通过需要进行重新编写的内容是:序列长度的扩展都可以得到最佳准确度。也要注意,对于使用 ReLU 的 S/8 模型,这种门控机制会将实验所需的核心时间增多大约 9.3%。
到这里,我们也就讲完了《视觉Transformer中ReLU替代softmax,DeepMind新招让成本速降》的内容了。个人认为,基础知识的学习和巩固,是为了更好的将其运用到项目中,欢迎关注golang学习网公众号,带你了解更多关于模型,Google的知识点!
 几何深度学习:揭开几何世界的神秘面纱
几何深度学习:揭开几何世界的神秘面纱
- 上一篇
- 几何深度学习:揭开几何世界的神秘面纱

- 下一篇
- 马斯克旗下脑机接口公司计划进行首次人体试验,预计时间为六年
-

- 科技周边 · 人工智能 | 2星期前 | AI绘画
- AI绘画工具安装与配置教程
- 339浏览 收藏
-

- 科技周边 · 人工智能 | 2星期前 |
- 海螺AI语音功能测评与体验分享
- 260浏览 收藏
-

- 科技周边 · 人工智能 | 2星期前 |
- ChatGPT读不了加密PDF?先解密再上传
- 438浏览 收藏
-

- 科技周边 · 人工智能 | 2星期前 |
- 千问AI测试规范与覆盖率提升技巧
- 152浏览 收藏
-

- 科技周边 · 人工智能 | 2星期前 |
- MiniMaxMusic2.0专业模式上线:音乐创作新神器
- 232浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 146次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 149次使用
-

- Red Skill
- 小红书创作服务平台为小红书创作者和机构提供视频上传、数据分析、粉丝管理、创作指导等多项运营服务,助力用户解锁更多创作者专属功能,体验高效创作!
- 154次使用
-

- MiMo Code
- MiMo Code 是小米大模型团队开源的新一代 AI 编程助手,面向开发者提供代码理解、生成与辅助开发能力,适合作为 AI 编程工具收藏和体验。
- 254次使用
-

- TRAE Work
- TRAE AI IDE | 国内首款 AI 原生集成开发环境,深度集成 Doubao-1.5-pro 与 DeepSeek 模型,支持中文自然语言一键生成完整代码框架,实时预览前端效果并智能修复 BUG。首创 Builder 模式实现需求到代码的自动化开发,兼容 Windows/macOS 系统,官网下载即用。
- 281次使用
-
- GPT-4王者加冕!读图做题性能炸天,凭自己就能考上斯坦福
- 2023-04-25 501浏览
-
- 单块V100训练模型提速72倍!尤洋团队新成果获AAAI 2023杰出论文奖
- 2023-04-24 501浏览
-
- ChatGPT 真的会接管世界吗?
- 2023-04-13 501浏览
-
- VR的终极形态是「假眼」?Neuralink前联合创始人掏出新产品:科学之眼!
- 2023-04-30 501浏览
-
- 实现实时制造可视性优势有哪些?
- 2023-04-15 501浏览


