Elasticsearch 如何搜索 # 和 + 等特殊字符
Elasticsearch 默认会过滤掉 #、+ 等特殊字符,导致含符号的文本(如“Java#Spring+Boot”)无法被准确搜索;本文直击痛点,详解两种高效可靠方案:一是零配置启用 `.keyword` 子字段实现毫秒级精确匹配,适合标签、技术栈等完整值检索;二是通过自定义分析器(如 whitespace + lowercase)保留特殊字符参与分词,支持更灵活的含符号子串搜索,同时避坑 wildcard 性能陷阱与大小写敏感问题,兼顾准确性、性能与工程实用性。

Elasticsearch 默认的 standard 分析器会丢弃 #、+ 等非字母数字字符,导致含特殊符号的标题无法被精确匹配;本文详解两种可靠方案:利用 .keyword 子字段进行精确匹配,或自定义分析器保留特殊字符。
Elasticsearch 默认的 standard 分析器会丢弃 `#`、`+` 等非字母数字字符,导致含特殊符号的标题无法被精确匹配;本文详解两种可靠方案:利用 `.keyword` 子字段进行精确匹配,或自定义分析器保留特殊字符。
在使用 Elasticsearch 的 standard 分析器时,像 #(井号)、+(加号)这类字符会被标准分词器(standard tokenizer)直接过滤掉——它依据 Unicode Standard Annex #29 进行分词,仅保留
例如,对文本 "Java#Spring+Boot" 执行分析:
GET _analyze
{
"analyzer": "standard",
"text": "Java#Spring+Boot"
}返回结果中仅包含三个 token:["java", "spring", "boot"],原始的#和+完全丢失。因此,当你尝试搜索title: "Java#Spring"` 时,Elasticsearch 实际查的是已清洗过的词项,自然无法命中原始含符号的文档。
✅ 推荐解决方案一:使用 .keyword 子字段(零配置、最简生效)
Elasticsearch 为 text 类型字段默认生成 .keyword 多字段(multi-field),该子字段使用 keyword 分析器——即不进行任何分词,原样索引整个字符串。你无需修改映射结构(除非显式禁用了 fields),只需在查询时切换到该子字段即可实现精确匹配。
✅ 修改 Java 实体类(启用 .keyword 映射):
@Field(type = FieldType.Text, analyzer = "standard",
fields = @Field(
type = FieldType.Keyword,
name = "keyword"
))
private String title;⚠️ 注意:Spring Data Elasticsearch 4.4+ 默认已为 text 字段自动添加 .keyword 子字段;若未生效,请确认 @Document 的 createIndex 为 true(首次启动时自动创建索引并应用映射)。
? 查询示例(Kibana 或 REST API):
GET jobs/_search
{
"query": {
"term": {
"title.keyword": "DevOps#AWS+CI/CD"
}
}
}此方式适用于完整值精确匹配(如搜索带 # 的标签名、技术栈标识符),且性能优异(底层为倒排索引 + 常量时间查找)。
✅ 推荐解决方案二:自定义分析器,保留特殊字符
若需支持部分匹配(如搜索 "#Java" 能匹配 "#Java8" 或 "Learn#Java"),则需构建自定义分析器,让 #、+ 等作为有效 token 的一部分。
? 步骤如下:
定义自定义分析器(推荐使用 pattern tokenizer 拆分空格,配合 lowercase filter):
PUT /jobs { "settings": { "analysis": { "analyzer": { "hashtag_analyzer": { "type": "custom", "tokenizer": "whitespace", "filter": ["lowercase"] } } } }, "mappings": { "properties": { "title": { "type": "text", "analyzer": "hashtag_analyzer", "fields": { "keyword": { "type": "keyword" } } } } } }验证分析效果:
GET jobs/_analyze { "analyzer": "hashtag_analyzer", "text": "Android#Kotlin+Jetpack" }输出 token 将为:["android#kotlin+jetpack"](整串保留)或按空格拆分为 ["Android#Kotlin+Jetpack"] —— 取决于是否需要进一步切分。如需识别 # 开头的独立标签,可升级为 pattern tokenizer 配合正则 "[\\s]+" 或更精细规则。
Java 实体同步更新:
@Field(type = FieldType.Text, analyzer = "hashtag_analyzer") private String title;
⚠️ 注意事项与最佳实践
- 避免滥用 wildcard 或 regexp 查询:虽然 title:*#Java* 看似可行,但性能差、无法利用倒排索引优势,且易引发 too_many_clauses 错误。
- .keyword 不支持全文检索:它只适用于 term、terms、match_phrase(当值完全一致时)等查询,不支持 match 的分词逻辑。
- 索引重建必要性:修改分析器或映射后,已有数据不会自动重索引,需执行 _reindex 或重建索引。
- 大小写敏感性:keyword 字段默认区分大小写;如需忽略大小写,可在其上添加 normalizer,或在自定义分析器中加入 lowercase filter。
综上,对于 #、+ 等特殊字符的搜索,优先采用 .keyword 子字段实现高效精确匹配;若业务要求更灵活的“含符号子串检索”,再引入定制化分析器——二者兼顾准确性、性能与可维护性。
终于介绍完啦!小伙伴们,这篇关于《Elasticsearch 如何搜索 # 和 + 等特殊字符》的介绍应该让你收获多多了吧!欢迎大家收藏或分享给更多需要学习的朋友吧~golang学习网公众号也会发布文章相关知识,快来关注吧!
 PHP Trait 使用教程:代码复用新特性解析
PHP Trait 使用教程:代码复用新特性解析
- 上一篇
- PHP Trait 使用教程:代码复用新特性解析

- 下一篇
- 如何用--add-exports绕过模块限制
-

- 文章 · java教程 | 4天前 | 性能优化 · Java教程 · CompletableFuture · 接口聚合 · java completablefuture orTimeout completeOnTimeout 接口性能 P95
- Java CompletableFuture 聚合接口优化:用超时兜底把 P95 从 920ms 降到 330ms
- 255浏览 收藏
-
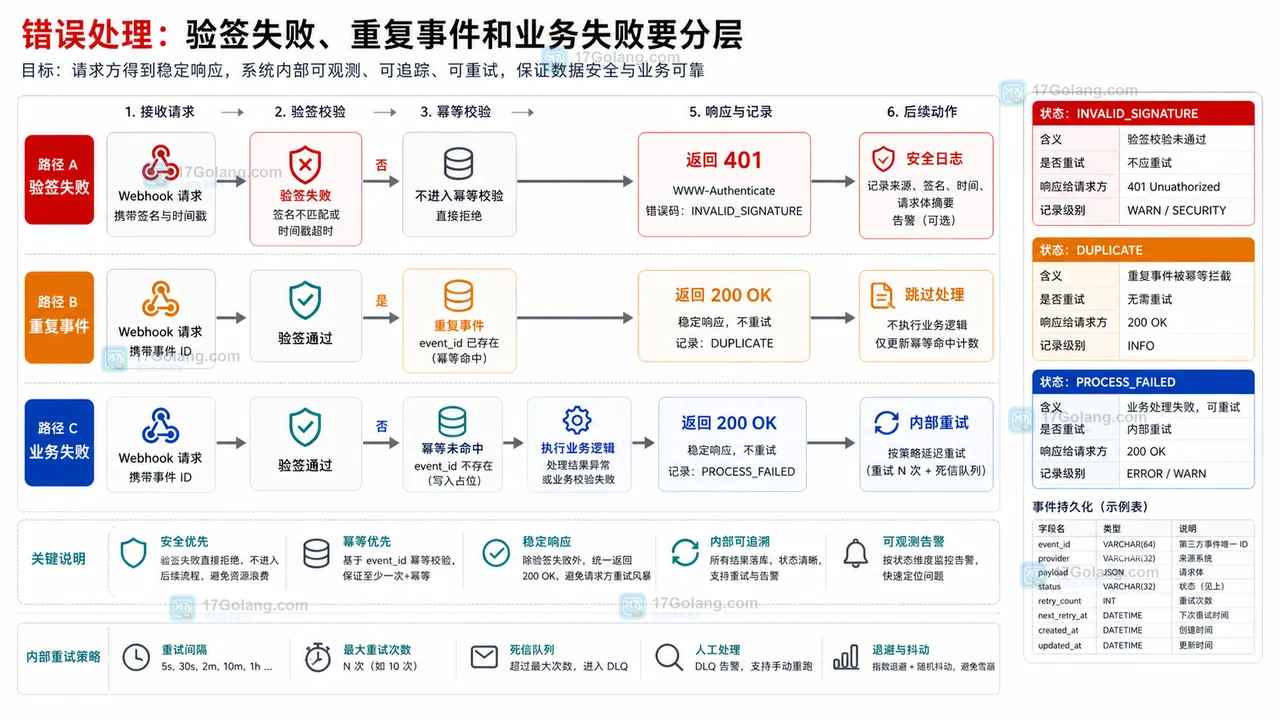
- 文章 · java教程 | 5天前 | Spring Boot · Java教程 · 接口设计 · Webhook · 幂等设计 · java spring boot WebHook 回调接口 幂等 状态流转 验签
- Java Webhook 回调接收接口设计:验签、幂等和状态流转
- 488浏览 收藏
-
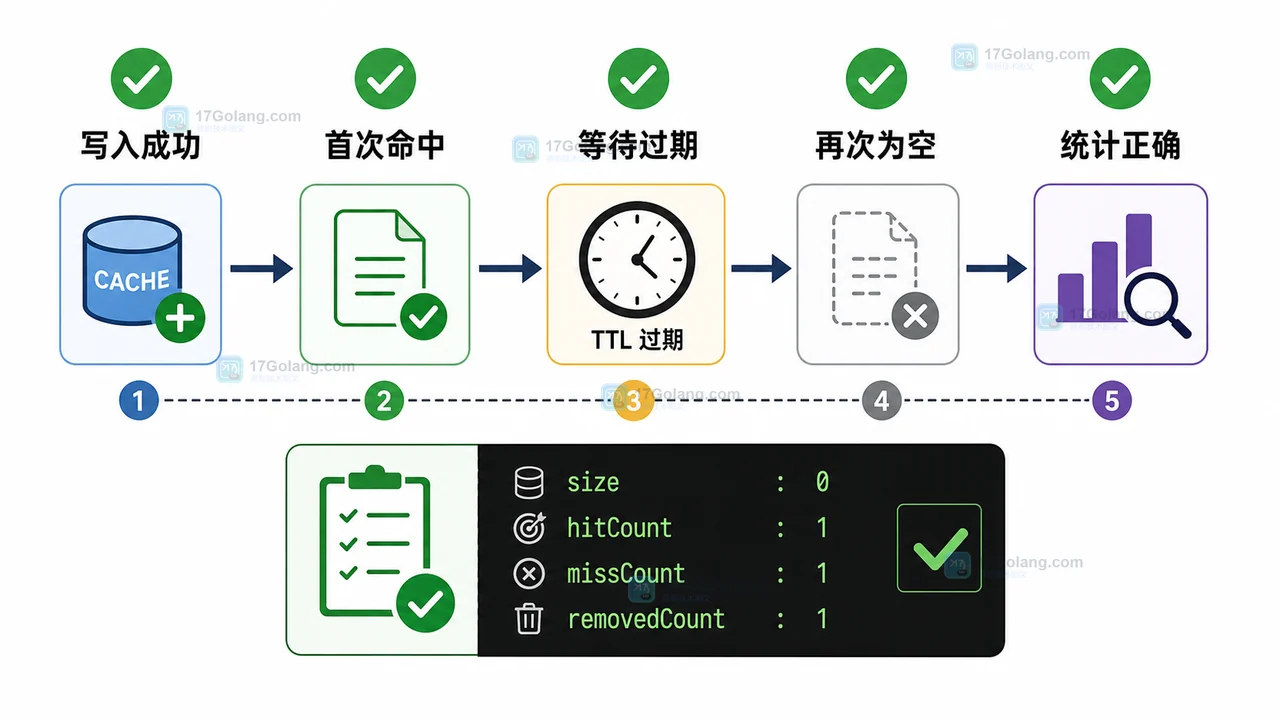
- 文章 · java教程 | 1星期前 | Java教程 · TTL缓存 · ConcurrentHashMap · 小项目 · java 本地缓存 concurrenthashmap TTL缓存 过期淘汰
- Java 本地 TTL 缓存小项目:用 ConcurrentHashMap 实现过期淘汰和命中统计
- 394浏览 收藏
-
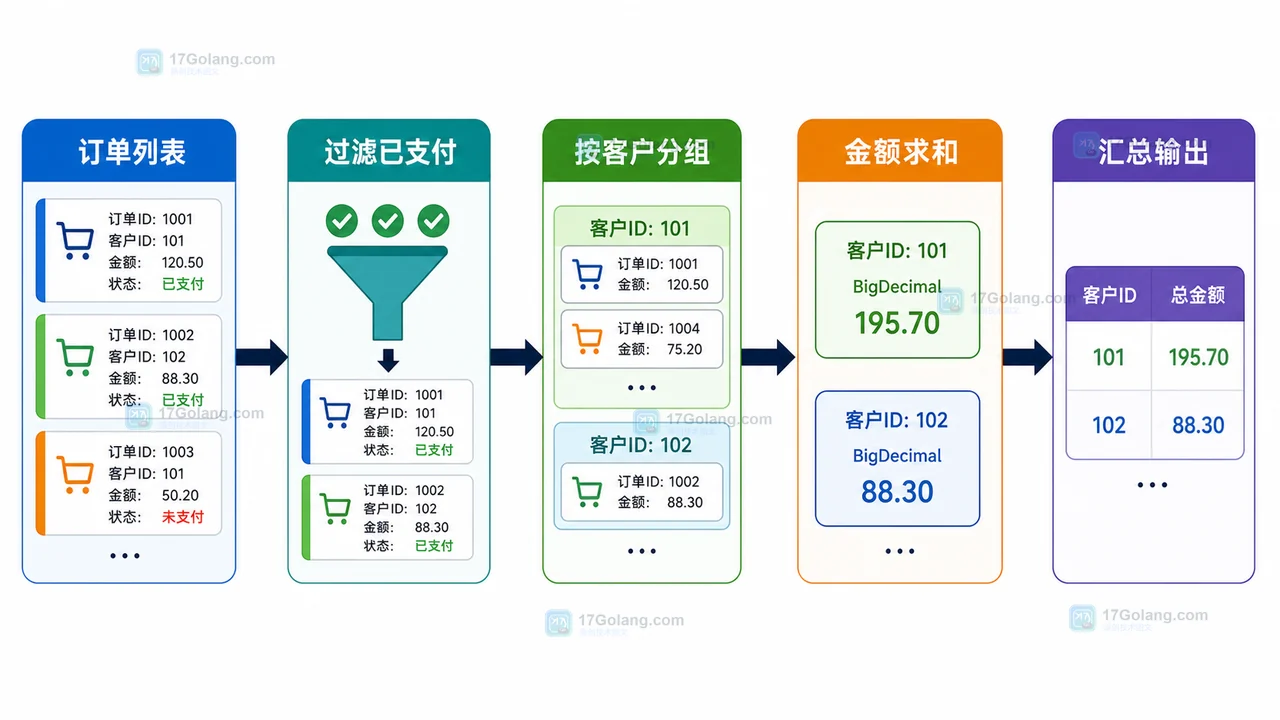
- 文章 · java教程 | 1星期前 | Java · Stream · 数据处理 · 后端教程 · Java Stream bigdecimal 分组统计 Collectors 订单汇总
- Java Stream 分组统计实验:从订单列表到客户消费汇总
- 355浏览 收藏
-
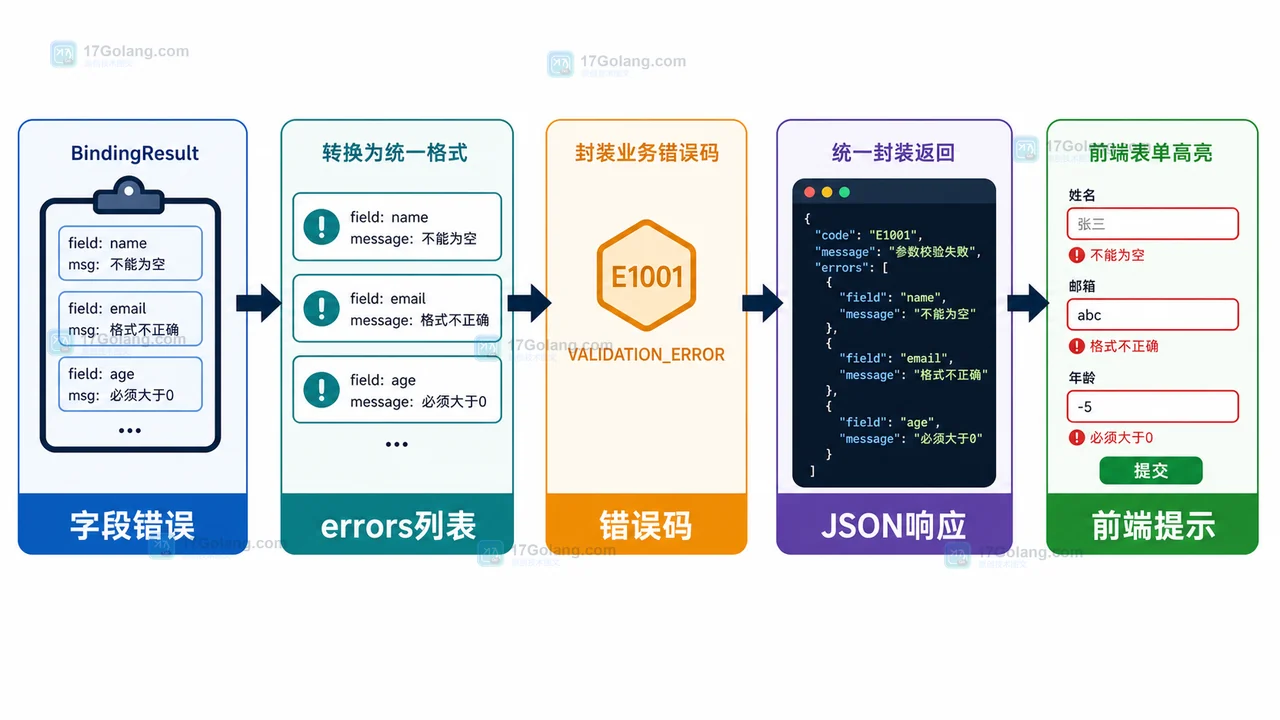
- 文章 · java教程 | 1星期前 | Java · Spring Boot · 后端开发 · 接口校验 · java spring boot dto 接口设计 参数校验
- Spring Boot 参数校验工作流:DTO、注解和统一错误响应
- 495浏览 收藏
-
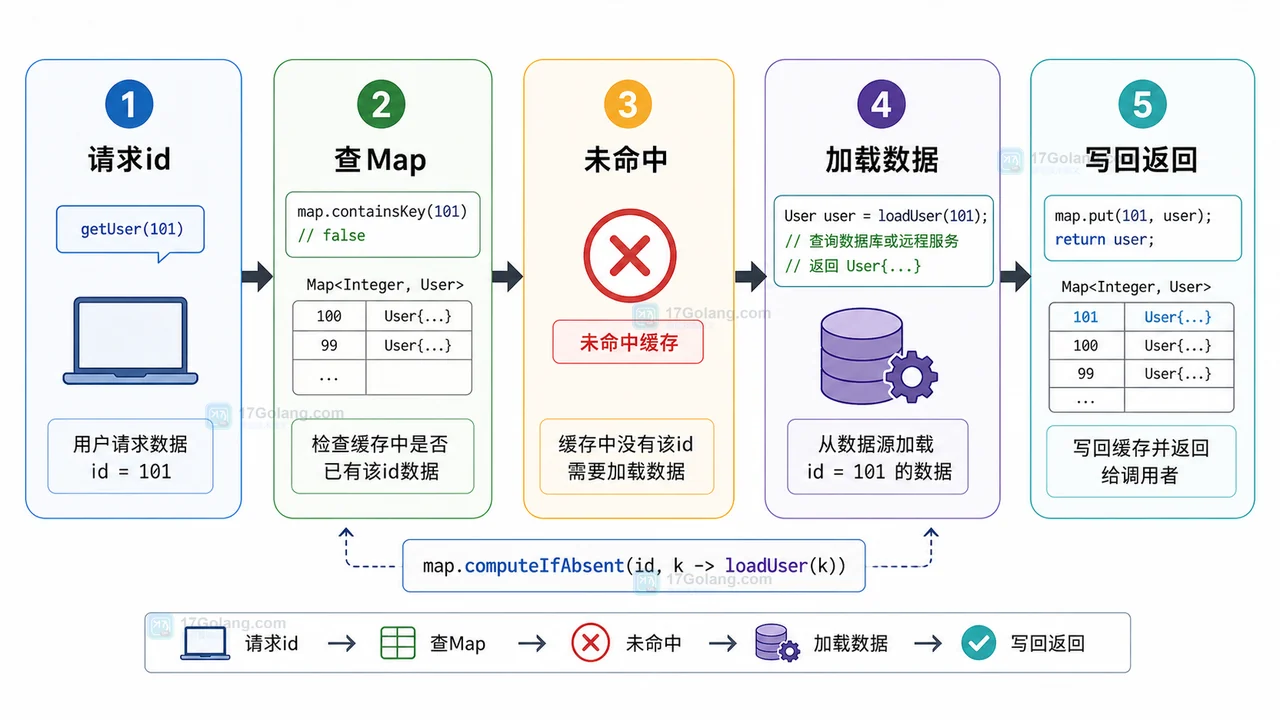
- 文章 · java教程 | 2星期前 | map · 并发安全 · 缓存设计 · Java教程 · java optional concurrenthashmap computeIfAbsent Map缓存
- Java computeIfAbsent 缓存初始化实战:少写判断、避开空值和并发坑
- 236浏览 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 3837次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 3540次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 3521次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 3708次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 3670次使用
-
- 矩阵主副对角线快速定位技巧
- 2026-05-31 501浏览
-
- Java多态优化流程代码与行为分发改进
- 2026-05-26 501浏览
-
- JVM 类元数据双亲委派链表深度解析
- 2026-05-21 501浏览
-
- 反射异常处理:InvocationTargetException解析与应用
- 2026-05-16 501浏览
-
- 怎么通过 HTML 的 accesskey 属性为网页中的按钮或链接设置键盘快捷键
- 2026-05-04 501浏览


