DFA与Trie实现Java敏感词过滤方法
本文深入剖析了Java中敏感词过滤的核心技术选型与工程实践,重点论证了DFA(确定性有限自动机)相比正则匹配和简单字符串扫描的显著优势:不仅单次文本扫描即可完成全词库匹配、时间复杂度稳定接近O(n),更关键的是其性能几乎不随词库规模扩大而劣化——哪怕从100词激增至10000词,过滤耗时依然恒定;同时系统揭示了落地过程中的高频陷阱与硬核解法,涵盖中文编码统一、内存优化的Node设计、并发安全建树、emoji/生僻字兼容、智能掩码替换、大文件流式处理、嵌套词匹配策略及热更新双缓冲机制,直击生产环境真实痛点,为构建高性能、高稳定性、可维护的敏感词过滤系统提供了兼具理论深度与实战精度的完整指南。

为什么 DFA 比正则匹配更适合敏感词过滤
正则 Pattern.compile() 逐条匹配敏感词,词库一到几百个,性能就明显下滑;DFA 把所有词构建成一张状态转移图,文本只扫描一遍,时间复杂度接近 O(n)。关键不是“多快”,而是“稳定”——词库从 100 扩到 10000,DFA 建树慢一点,但过滤耗时几乎不变。
常见错误现象:String.contains() 硬扫、replaceAll() 配合动态拼接正则(如 "(?i)" + word),词多时 CPU 持续飙高,甚至触发 GC 频繁停顿。
- DFA 不适合做模糊匹配(比如拼音替换、形近字),它认的是严格字符序列
- 建树阶段必须去重、剔除包含关系(如“苹果”和“苹果手机”,后者可删),否则状态节点冗余,内存涨得快
- 中文需注意全角/半角、大小写——DFA 默认区分,通常要预处理统一转小写+半角
用 Java 实现基础 DFA 节点结构的关键点
核心是 Node 类:每个节点存一个 Map 表示子节点,加一个布尔字段 isEnd 标记是否为词尾。别用 HashMap 直接存 char,中文字符范围大,推荐用 ConcurrentHashMap 或更省内存的 ObjectArray(但得自己 handle null)。
容易踩的坑:Node 的 children Map 如果用 new HashMap(),并发构建时可能出错;如果用 Collections.synchronizedMap(),又锁太重。实际项目里,建议先单线程建树,再并发读取。
- 不要在
Node里存原始词字符串(如word字段),浪费内存;需要时靠路径回溯或建树时在isEnd处存wordId - 避免递归建树,用 while 循环 + 当前节点引用,防止超长词(比如 50 字)导致栈溢出
- 词库含 emoji 或生僻汉字时,确保 JVM 启动参数含
-Dfile.encoding=UTF-8,否则char拆分可能错位
敏感词替换时怎么保留原格式(比如星号长度匹配汉字数)
直接用固定 "***" 替换会暴露词长,也难看。正确做法是在 DFA 匹配到终点后,根据匹配起始/结束下标,按原字符数生成掩码:中文、emoji 算 1 个,ASCII 字母数字算 1 个,但显示时统一用 * 或 •。
示例逻辑片段:
int start = matchStart; int end = matchEnd; StringBuilder mask = new StringBuilder(); for (int i = start; i = 0x4e00 && c
- 别用
String.replaceAll()做多次替换,它内部反复 copy 字符串,大文本下 GC 压力大 - 如果要求“高亮不替换”,只需记录所有
[start, end)区间,交给前端渲染,后端不拼接新字符串 - 注意索引越界:文本含 \r\n、\u200b 零宽空格时,
charAt()下标和视觉位置可能错位,预处理建议先text.replaceAll("\\p{Cf}", "")清理格式字符
上线前必须验证的三个边界场景
很多 DFA 实现本地跑得通,一上生产就漏词或卡死,问题往往出在没压测真实语料。
- 超长文本(>10MB):别用
String加载,改用InputStreamReader分块读,每次喂 8KB 左右进 DFA 扫描器 - 嵌套词:“王八蛋”和“蛋炒饭”共存时,DFA 必须支持“最长匹配”或“最短匹配”策略可配,否则“王八蛋炒饭”可能只标出“王八蛋”,漏掉“蛋”开头的另一条路径
- 热更新词库:不要每次 reload 全量重建 DFA 树(停服风险),用双缓冲机制——新树构建完,原子替换引用,旧树等当前请求结束后再 GC
真正麻烦的不是算法本身,是词库质量、编码一致性、还有替换后要不要做二次语义校验。这些没法靠 DFA 一步到位,得在它外面包一层业务逻辑。
好了,本文到此结束,带大家了解了《DFA与Trie实现Java敏感词过滤方法》,希望本文对你有所帮助!关注golang学习网公众号,给大家分享更多文章知识!
 iCloud网页版登录方法及使用教程
iCloud网页版登录方法及使用教程
- 上一篇
- iCloud网页版登录方法及使用教程

- 下一篇
- Excel格式刷后如何换行?操作技巧分享
-
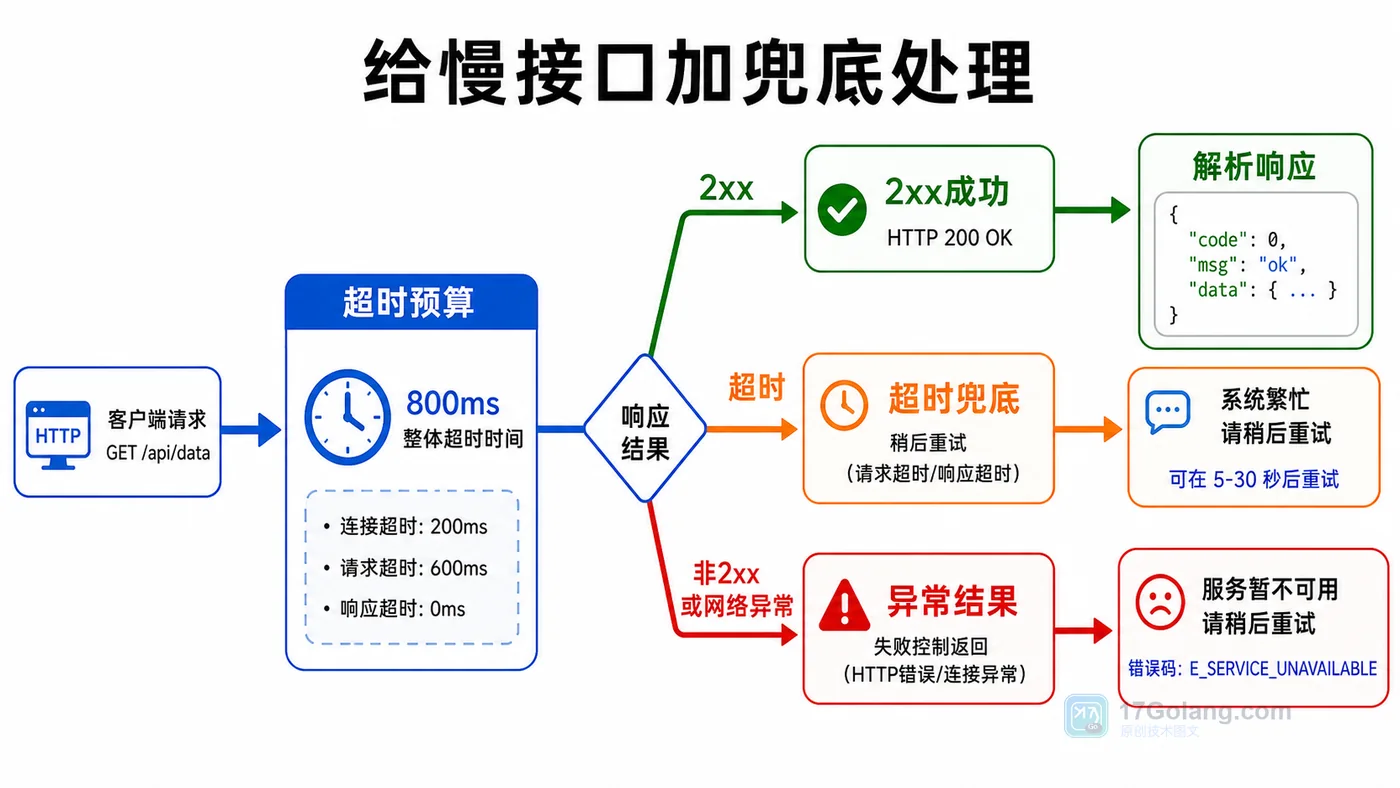
- 文章 · java教程 | 1天前 | http接口 · httpclient · Java教程 · 接口调试 · 超时处理 · java 接口调用 httpclient 超时控制 状态码 响应体
- Java HttpClient 调接口实战:超时、状态码和响应体这样处理
- 224浏览 收藏
-
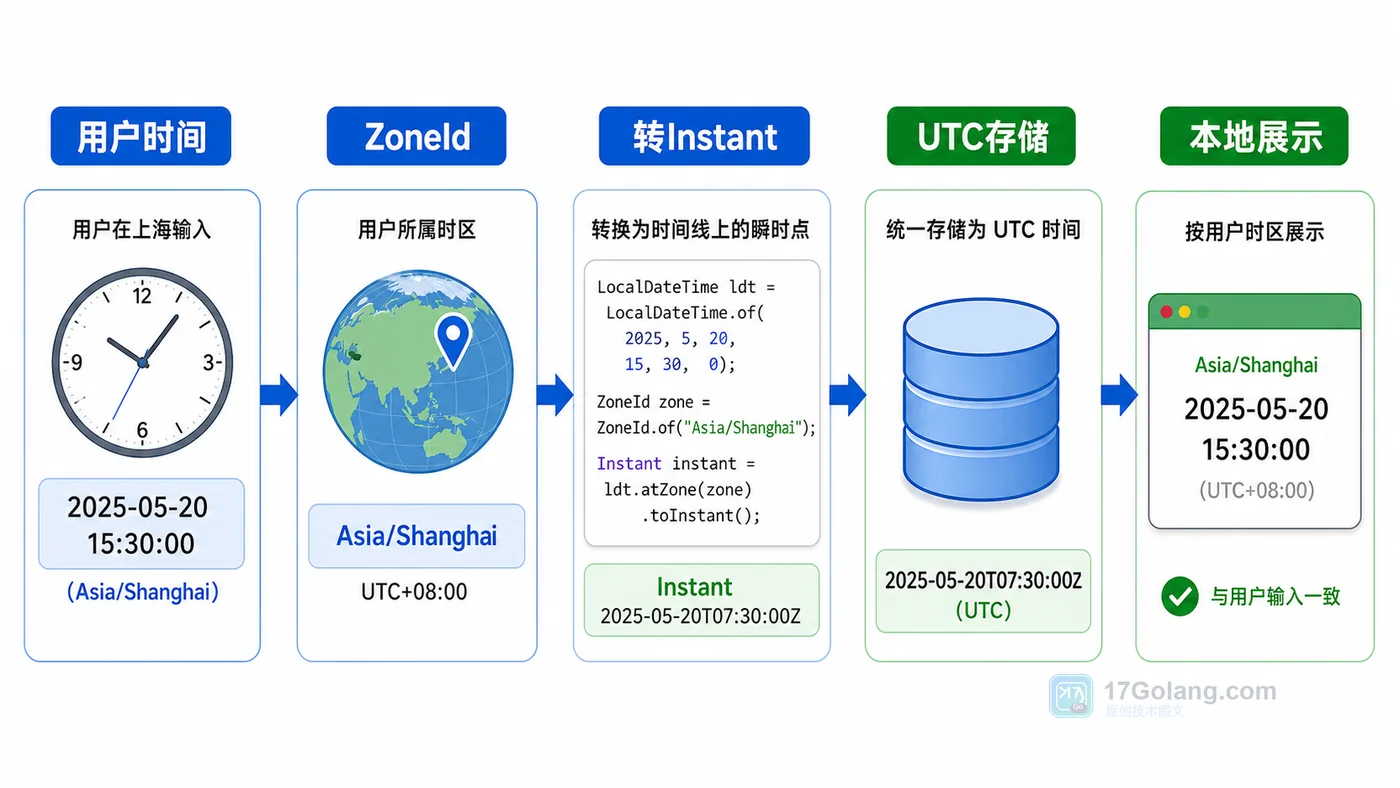
- 文章 · java教程 | 1天前 | 时间处理 · instant · Java教程 · 时区转换 · DateTimeFormatter · java DateTimeFormatter java.time 时区处理 ZoneId INSTANT
- Java 时间与时区处理实战:Instant、ZoneId 和 DateTimeFormatter 怎么配
- 461浏览 收藏
-
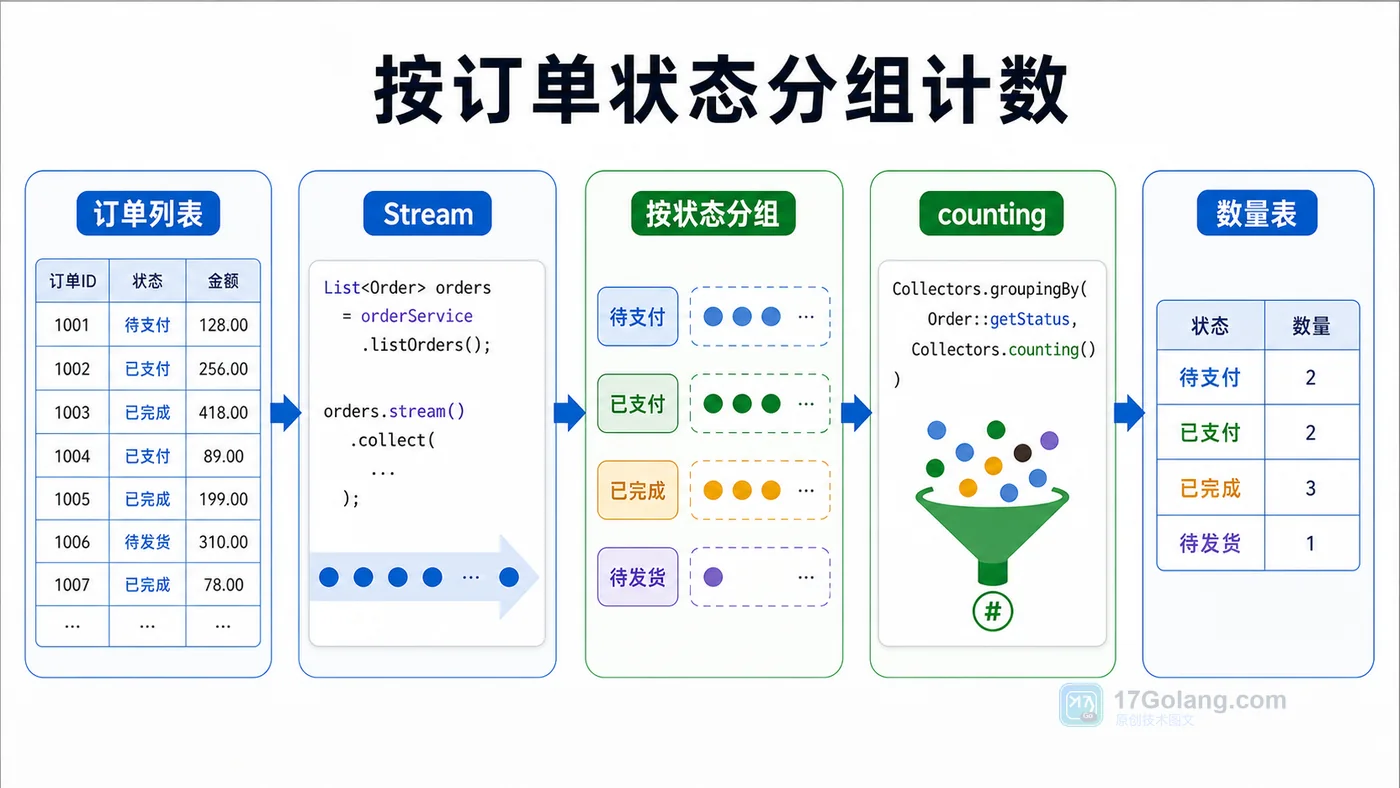
- 文章 · java教程 | 1天前 | Java · Stream · 集合统计 · 分组聚合 · Collectors · java Stream Collectors groupingBy counting summarizingInt
- Java Stream 分组统计实战:groupingBy、counting 和 summarizingInt 怎么用
- 478浏览 收藏
-
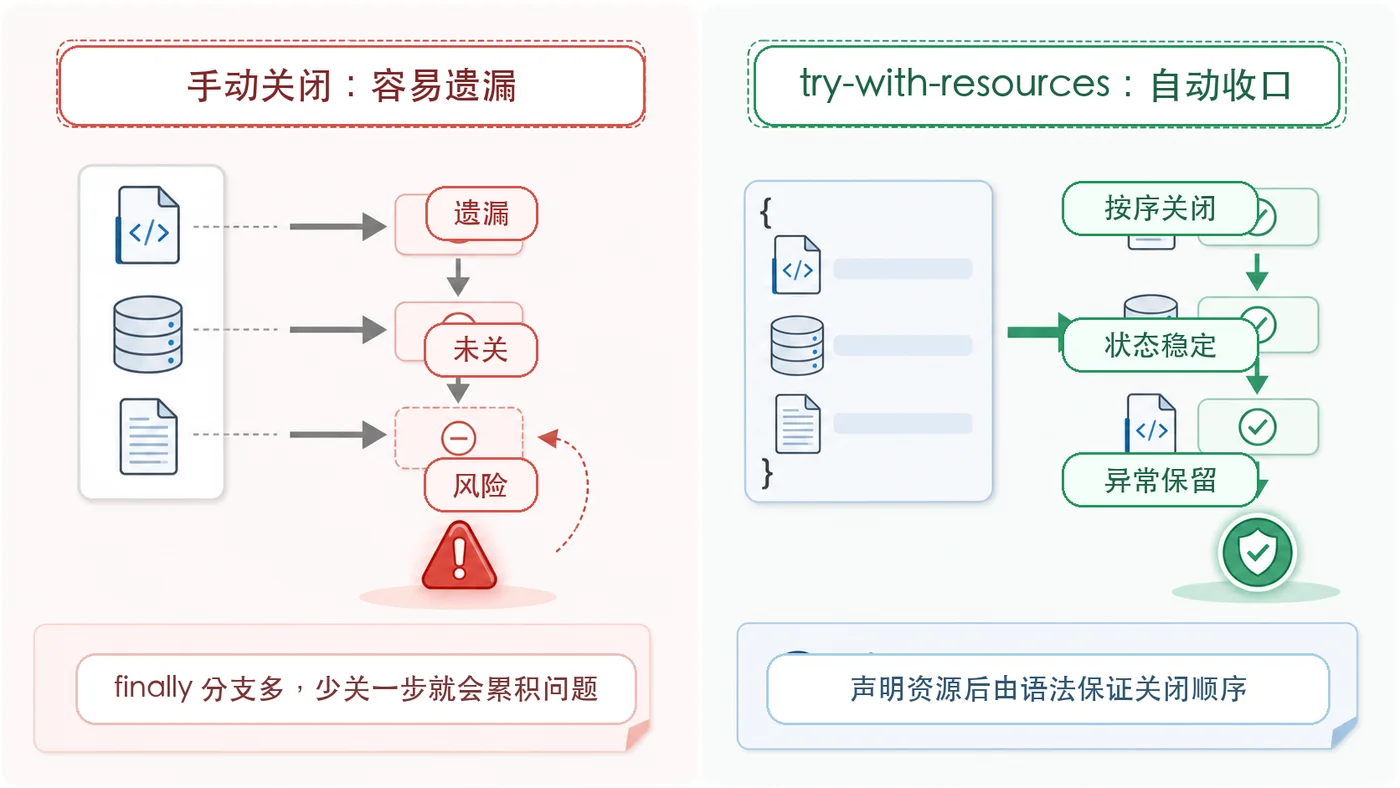
- 文章 · java教程 | 2天前 | Java · 文件读取 · 异常处理 · 资源管理 · try-with-resources · java 异常处理 try-with-resources 资源关闭 AutoCloseable 文件流
- Java try-with-resources 资源关闭实战:文件流和目录扫描这样写更稳
- 268浏览 收藏
-
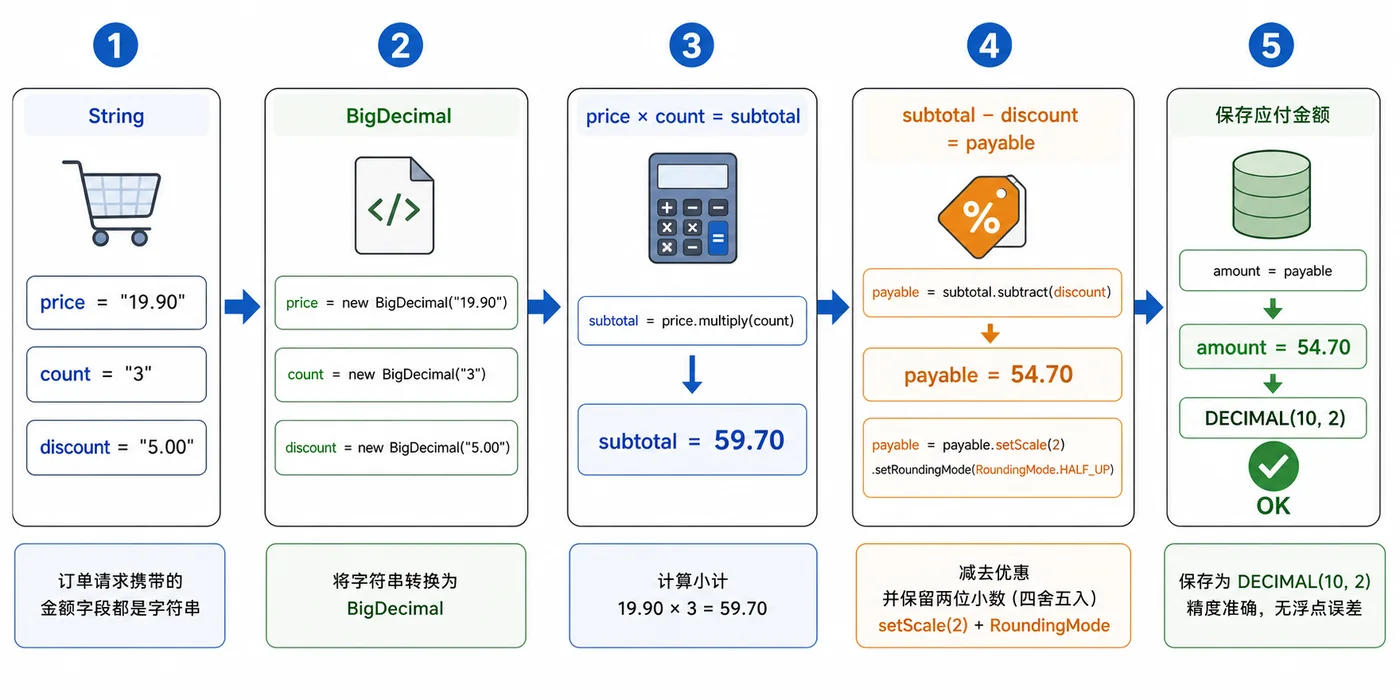
- 文章 · java教程 | 2天前 | Java教程 · 后端开发 · BigDecimal · 金额计算 · java 舍入 bigdecimal 浮点误差 金额计算 RoundingMode
- Java BigDecimal 金额计算实战:避免浮点误差和舍入问题
- 324浏览 收藏
-
- 文章 · java教程 | 2天前 | 异步编程 · Java教程 · 超时治理 · CompletableFuture · java 异步任务 超时处理 completablefuture orTimeout completeOnTimeout
- Java CompletableFuture 超时处理实战:orTimeout 和兜底结果怎么选
- 421浏览 收藏
-

- 文章 · java教程 | 6天前 | 并发编程 · 生产实践 · Java教程 · JDK25 · 虚拟线程 · 虚拟线程 Java 25 JEP 505 Structured Concurrency StructuredTaskScope
- Java 25 Structured Concurrency 实战:别让 CompletableFuture 把超时拖散
- 443浏览 收藏
-
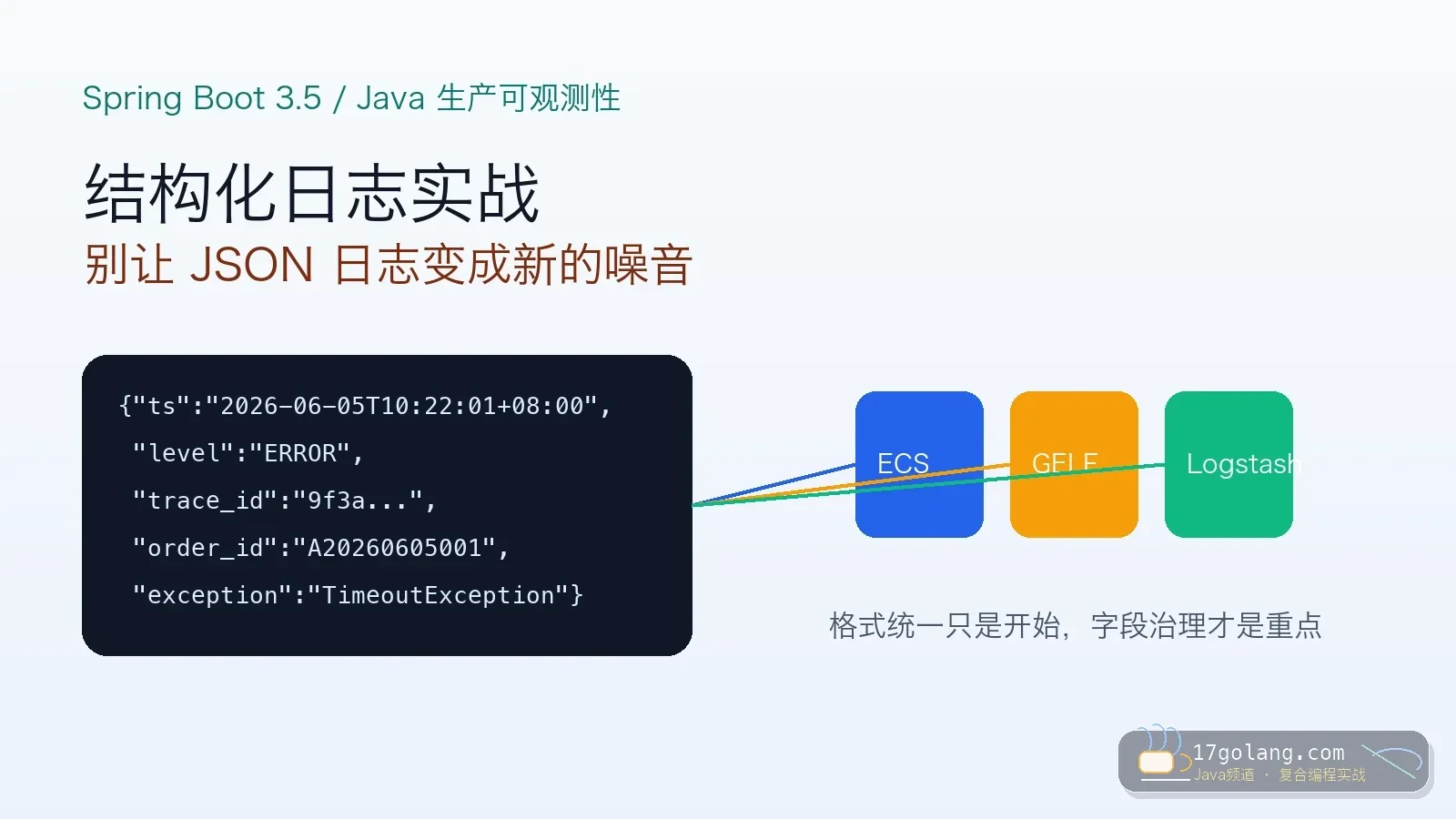
- 文章 · java教程 | 1星期前 | 日志 · Spring Boot · 生产实践 · 可观测性 · Java教程 · java 可观测性 MDC 结构化日志 Spring Boot 3.5
- Spring Boot 3.5 结构化日志实战:别让 JSON 日志变成新的噪音
- 332浏览 收藏
-
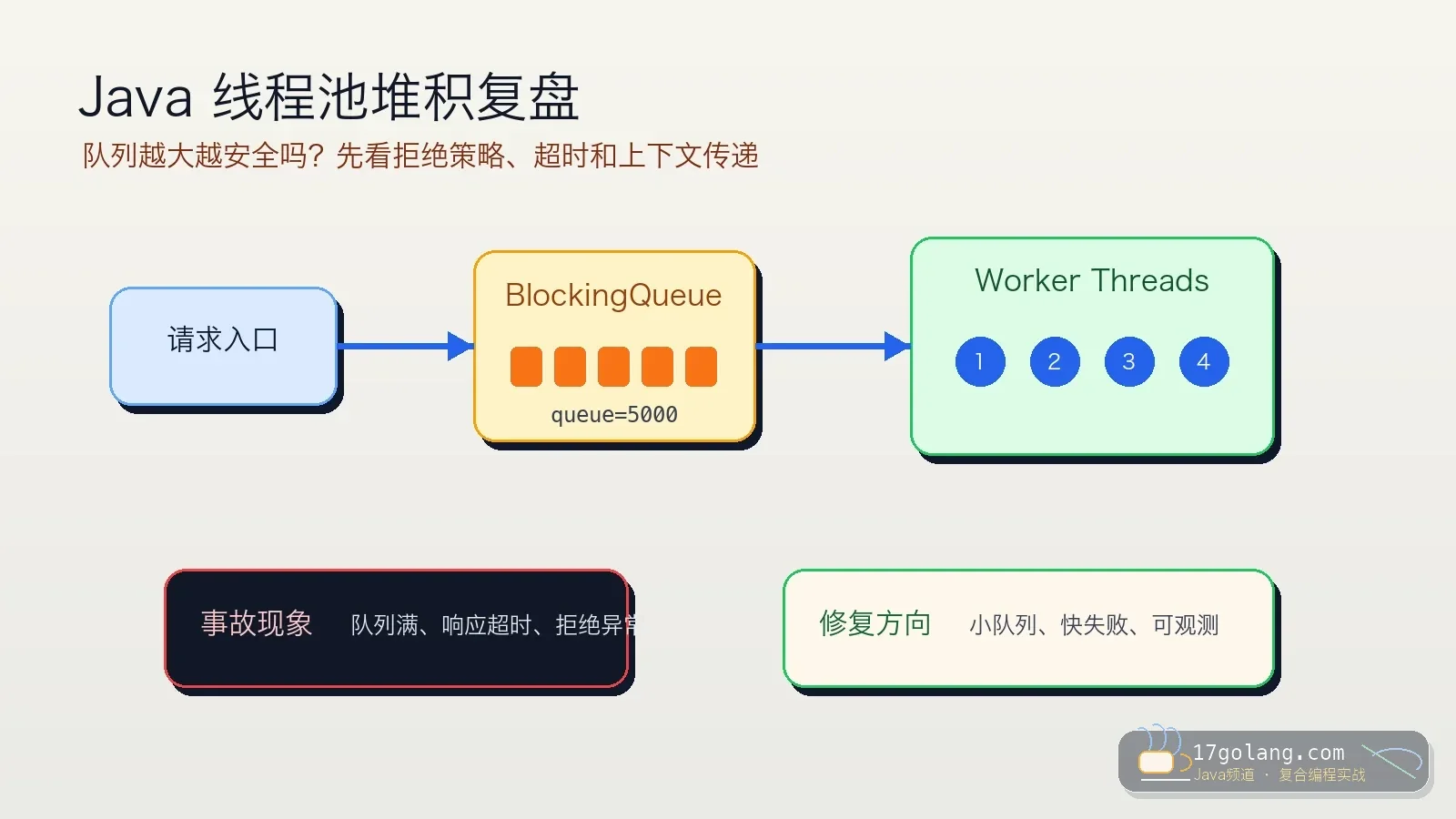
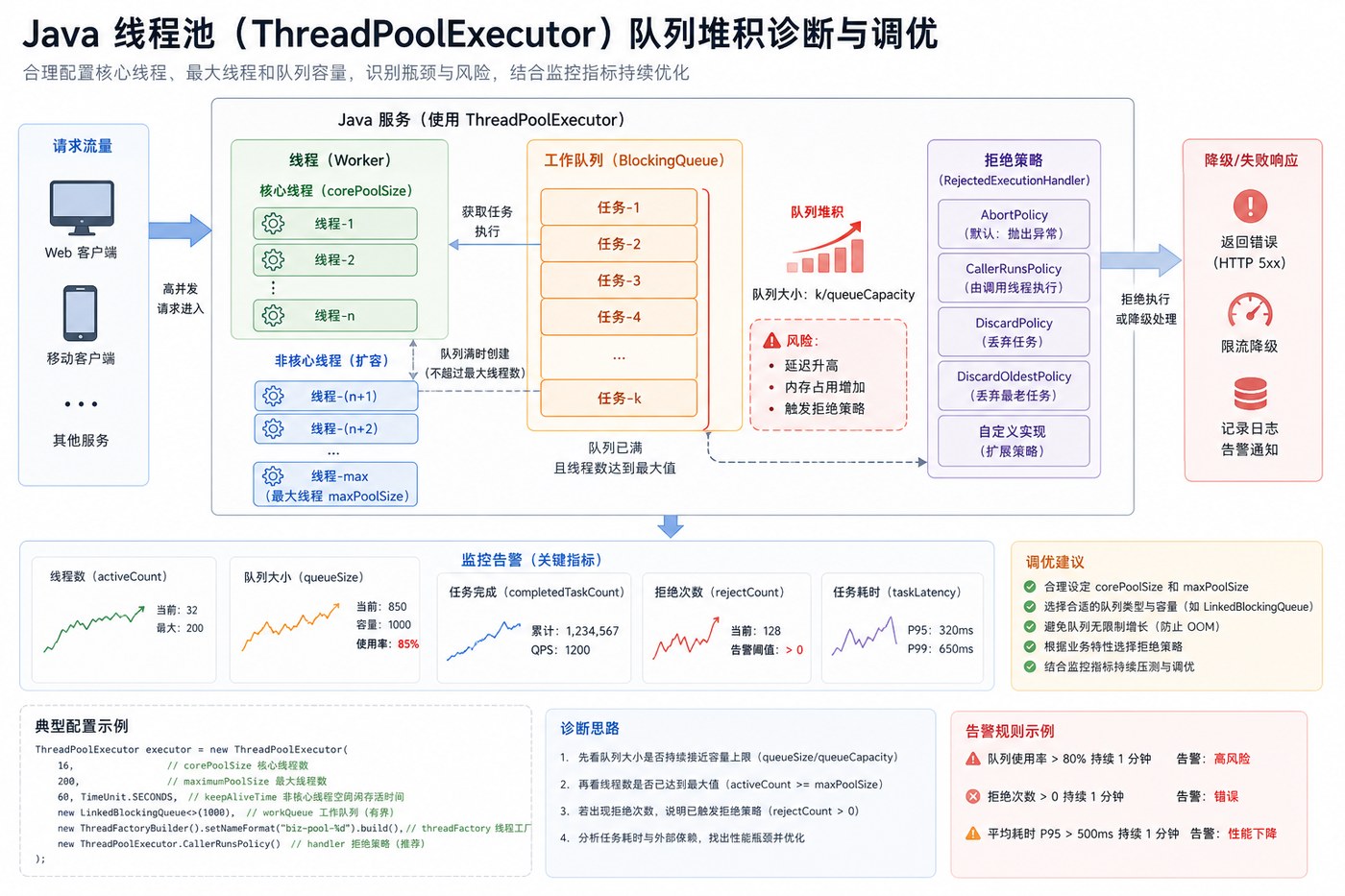
- 文章 · java教程 | 1星期前 | 线程池 · Spring Boot · 生产实践 · Java教程 · ThreadPoolExecutor · java 性能优化 线程池 spring boot threadpoolexecutor
- Java 线程池队列堆积复盘:别让无界队列把慢故障藏起来
- 326浏览 收藏

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 8636次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 9050次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 8877次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 10784次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 9721次使用
-
- 提升Java功能开发效率的有力工具:微服务架构
- 2023-10-06 501浏览
-
- 掌握Java海康SDK二次开发的必备技巧
- 2023-10-01 501浏览
-
- 如何使用java实现桶排序算法
- 2023-10-03 501浏览
-
- Java开发实战经验:如何优化开发逻辑
- 2023-10-31 501浏览
-
- 如何使用Java中的Math.max()方法比较两个数的大小?
- 2023-11-18 501浏览


