Java/Kotlin忽略变音符号排序方法
本文深入解析了在Java/Kotlin中实现真正跨语言、语义准确的变音符号(如法语重音、希伯来尼库德、阿拉伯音标等)忽略式排序与搜索的关键技术,直击标准API因依赖Unicode码点而导致的排序错乱和搜索失位痛点;通过NFD规范化结合\p{Mn}精准剥离非间距标记,以及ICU4J的Collator和StringSearch提供的语言敏感排序与原始位置映射搜索,为国际化应用提供了从轻量级到生产级的完整解决方案——让“café”和“cafe”自然归为一类,“בְּרֵאשִׁית”中的“ברא”能被准确定位,彻底告别变音符号带来的用户体验割裂。

本文详解如何在多语言环境下(含法语、希伯来语等)实现真正忽略各类变音符号(diacritics)的字符串排序与精准位置感知搜索,涵盖标准 API 局限性分析、Unicode 规范化策略、ICU4J 高级解决方案及完整可运行示例。
本文详解如何在多语言环境下(含法语、希伯来语等)实现真正忽略各类变音符号(diacritics)的字符串排序与精准位置感知搜索,涵盖标准 API 局限性分析、Unicode 规范化策略、ICU4J 高级解决方案及完整可运行示例。
在国际化应用中,仅依赖 String.compareTo() 或 Arrays.sort() 进行排序、用 String.indexOf() 进行搜索,会导致法语(如 "Le Garçon")、越南语、阿拉伯语甚至希伯来语(含尼库德 Niqqud)等文本行为异常——因为这些操作直接基于 Unicode 码点,而变音符号(如 ç, é, ְ, ִ)在 Unicode 中常以组合字符(Combining Characters) 形式独立存在,破坏了视觉上的“字母连续性”。
✅ 核心挑战:不只是“去重音”,而是“语义对齐”
- 排序问题:"cafe" 和 "café" 在字典序中被视作完全不同字符串,导致 "cafe" 排在 "café" 之前,违背用户直觉;
- 搜索问题:搜索 "rc" 在 "Le Garçon" 中应匹配 r + ç,且需返回原始字符串中 r 的索引(2)和 ç 的结束位置(4);更复杂的是希伯来语 "בְּרֵאשִׁית"(创世记)——其 6 个辅音字母后附着 5 个尼库德符号,length() 返回 11,但语义单元仅 6 个。简单正则 \\p{InCombiningDiacriticalMarks}+ 无法清除尼库德,因其 Unicode 类别为 Mn(Mark, Nonspacing),而非 InCombiningDiacriticalMarks 所覆盖的有限区块。
✅ 标准 Java/Kotlin 方案:NFD + 组合字符剥离(适用于多数拉丁/西里尔语)
Java 内置 Normalizer 是基础解法,但需正确使用 NFD(Normalization Form D) 拆分预组合字符,并配合精准 Unicode 属性匹配:
import java.text.Normalizer
import java.text.Normalizer.Form
fun stripDiacritics(input: String): String {
return Normalizer.normalize(input, Form.NFD)
.replace(Regex("\\p{Mn}+"), "") // \p{Mn} = Mark, Nonspacing — 覆盖所有非间距标记(含尼库德、重音、变音等)
}
// 示例
val french = "Le Garçon"
val stripped = stripDiacritics(french) // "Le Garcon"
println(stripped.indexOf("rc")) // 7 → 正确匹配 'r'+'c'
val hebrew = "בְּרֵאשִׁית"
val strippedHeb = stripDiacritics(hebrew) // "בראשית"
println(strippedHeb.length) // 6 → 语义长度恢复⚠️ 注意:\\p{Mn} 是关键!它比 \\p{InCombiningDiacriticalMarks} 更全面,覆盖 Unicode 标准中所有“非间距标记”(包括希伯来尼库德、泰文元音、阿拉伯音标等)。Normalizer.Form.NFD 将 ç → c + ̧,再由 \\p{Mn} 清除 ̧,从而实现跨语言标准化。
✅ ICU4J 方案:面向生产环境的鲁棒性增强(推荐)
当需支持土耳其语大小写规则、德语 ß→ss 映射、或希伯来语/阿拉伯语复杂排序权重时,ICU4J 是业界标准:
1. 添加依赖(Maven)
com.ibm.icu icu4j 74.1
2. 排序:使用 Collator(支持语言敏感规则)
import com.ibm.icu.text.Collator
import com.ibm.icu.text.RuleBasedCollator
val collator = Collator.getInstance(Locale.FRANCE).apply {
strength = Collator.PRIMARY // 忽略大小写、重音、变音,只比对基字
}
val list = listOf("cafe", "café", "Café", "Ça va")
list.sortedWith(collator).forEach(::println)
// 输出:cafe, Café, café, Ça va (按法语 PRIMARY 权重统一排序)3. 搜索:StringSearch 实现带位置的模糊匹配
import com.ibm.icu.text.StringSearch fun findIgnoringDiacritics(text: String, pattern: String): List{ val search = StringSearch(pattern, text).apply { // 启用重音/变音忽略 setAttribute(StringSearch.ACCENTED, StringSearch.ON, null) // 可选:启用大小写忽略 setAttribute(StringSearch.CASE, StringSearch.ON, null) } val results = mutableListOf () var pos = search.first() while (pos != StringSearch.DONE) { results += pos..(pos + pattern.length - 1) pos = search.next() } return results } // 测试希伯来语 val hebText = "בְּרֵאשִׁית בָּרָא אֱלֹהִים" val matches = findIgnoringDiacritics(hebText, "ברא") // 匹配无尼库德的"bara" println(matches) // [0..2, 8..10] — 返回原始字符串中的精确位置
✅ 最佳实践总结
| 场景 | 推荐方案 | 说明 |
|---|---|---|
| 轻量级、拉丁/西里尔语为主 | Normalizer.NFD + \\p{Mn} | 零依赖,性能高,覆盖 95% 常见语言 |
| 多语言混合、需精准排序权重 | ICU4J Collator | 支持 locale-specific 规则(如德语、土耳其语特殊处理) |
| 搜索需返回原始位置、支持尼库德/音标 | ICU4J StringSearch | 唯一能保证 find() 结果映射回原始字符串坐标的成熟方案 |
| 避免陷阱 | ❌ 不要用 NFC;❌ 不要用 \\p{InCombiningDiacriticalMarks};✅ 始终用 NFD + \\p{Mn} | NFC 会重新组合字符,InCombining... 类别过窄 |
? 提示:对于 Kotlin Multiplatform 或 Android,可封装为 expect/actual 函数;服务端高并发场景建议缓存 Collator 实例(线程安全)和 StringSearch 对象(避免重复初始化)。
通过组合 Unicode 规范化与 ICU4J 的深度本地化能力,你将获得真正符合全球用户直觉的文本处理体验——不再让 ç 和 c 成为两个世界。
理论要掌握,实操不能落!以上关于《Java/Kotlin忽略变音符号排序方法》的详细介绍,大家都掌握了吧!如果想要继续提升自己的能力,那么就来关注golang学习网公众号吧!
 Linux内核调试方法:kgdb与kdb配置详解
Linux内核调试方法:kgdb与kdb配置详解
- 上一篇
- Linux内核调试方法:kgdb与kdb配置详解

- 下一篇
- 企业微信关联小程序方法详解
-

- 文章 · java教程 | 3天前 | 并发编程 · 生产实践 · Java教程 · JDK25 · 虚拟线程 · 虚拟线程 Java 25 JEP 505 Structured Concurrency StructuredTaskScope
- Java 25 Structured Concurrency 实战:别让 CompletableFuture 把超时拖散
- 443浏览 收藏
-
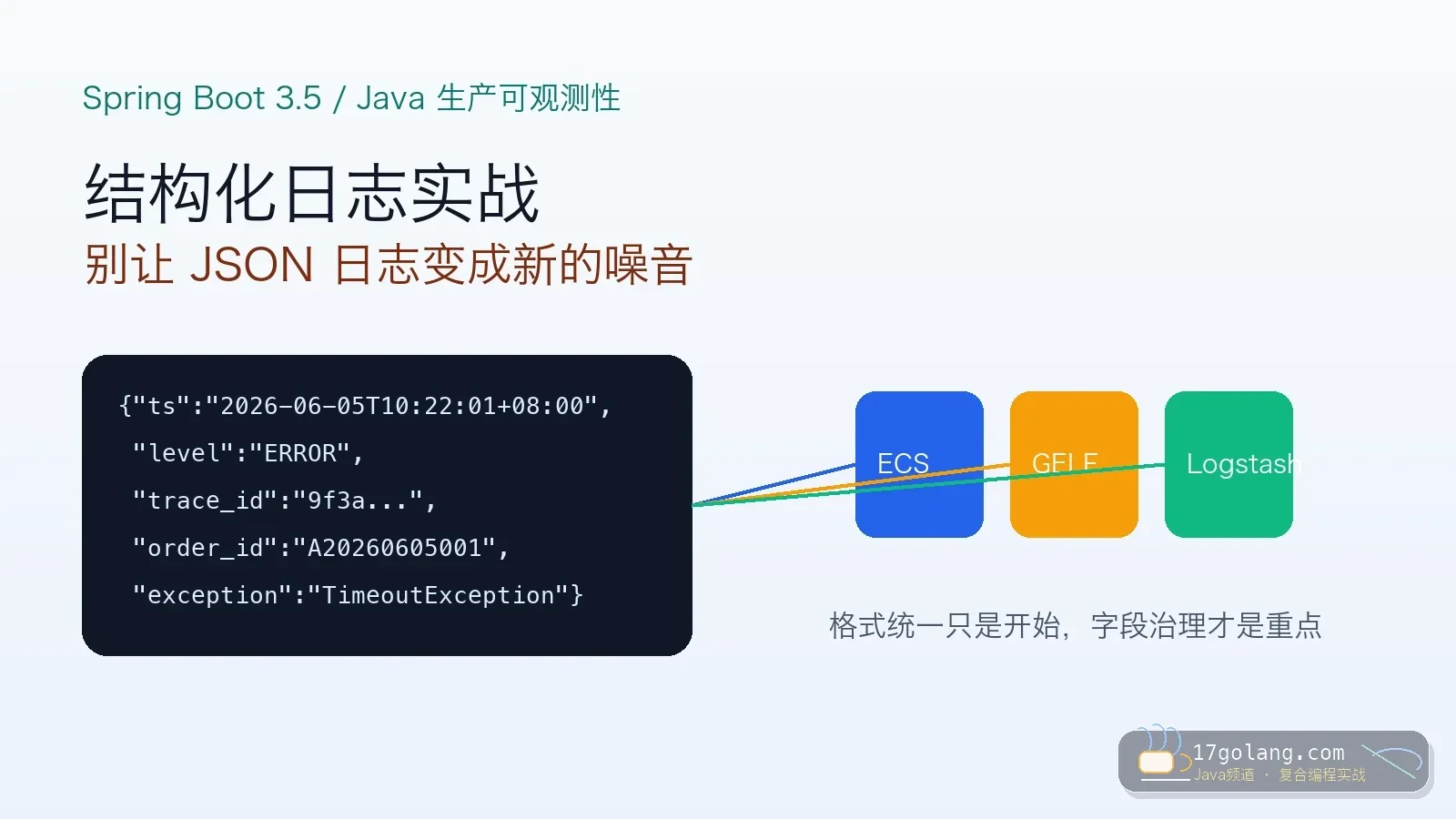
- 文章 · java教程 | 1星期前 | 日志 · Spring Boot · 生产实践 · 可观测性 · Java教程 · java 可观测性 MDC 结构化日志 Spring Boot 3.5
- Spring Boot 3.5 结构化日志实战:别让 JSON 日志变成新的噪音
- 332浏览 收藏
-
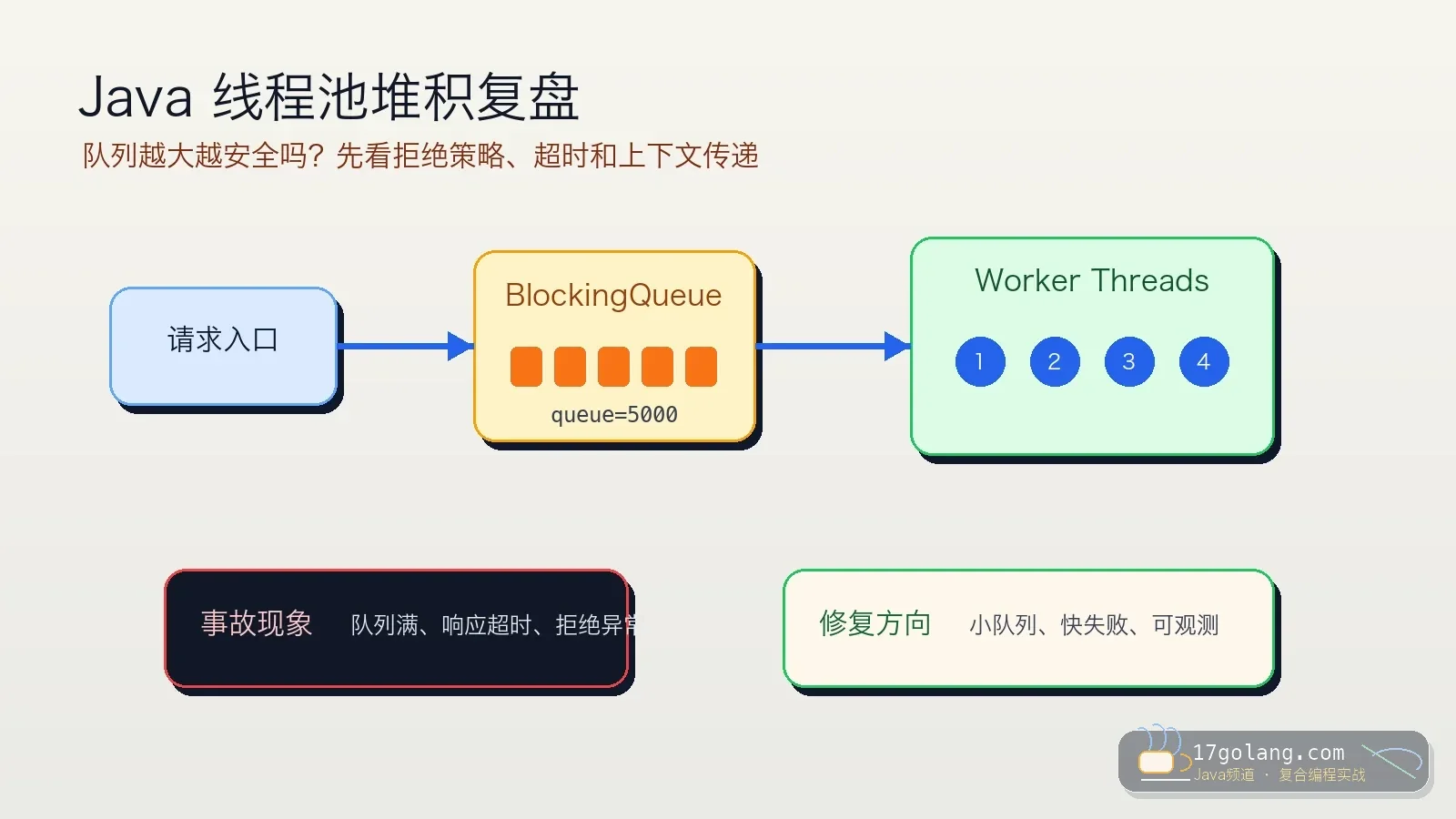
- 文章 · java教程 | 1星期前 | 线程池 · Spring Boot · 生产实践 · Java教程 · ThreadPoolExecutor · java 性能优化 线程池 spring boot threadpoolexecutor
- Java 线程池队列堆积复盘:别让无界队列把慢故障藏起来
- 326浏览 收藏
-
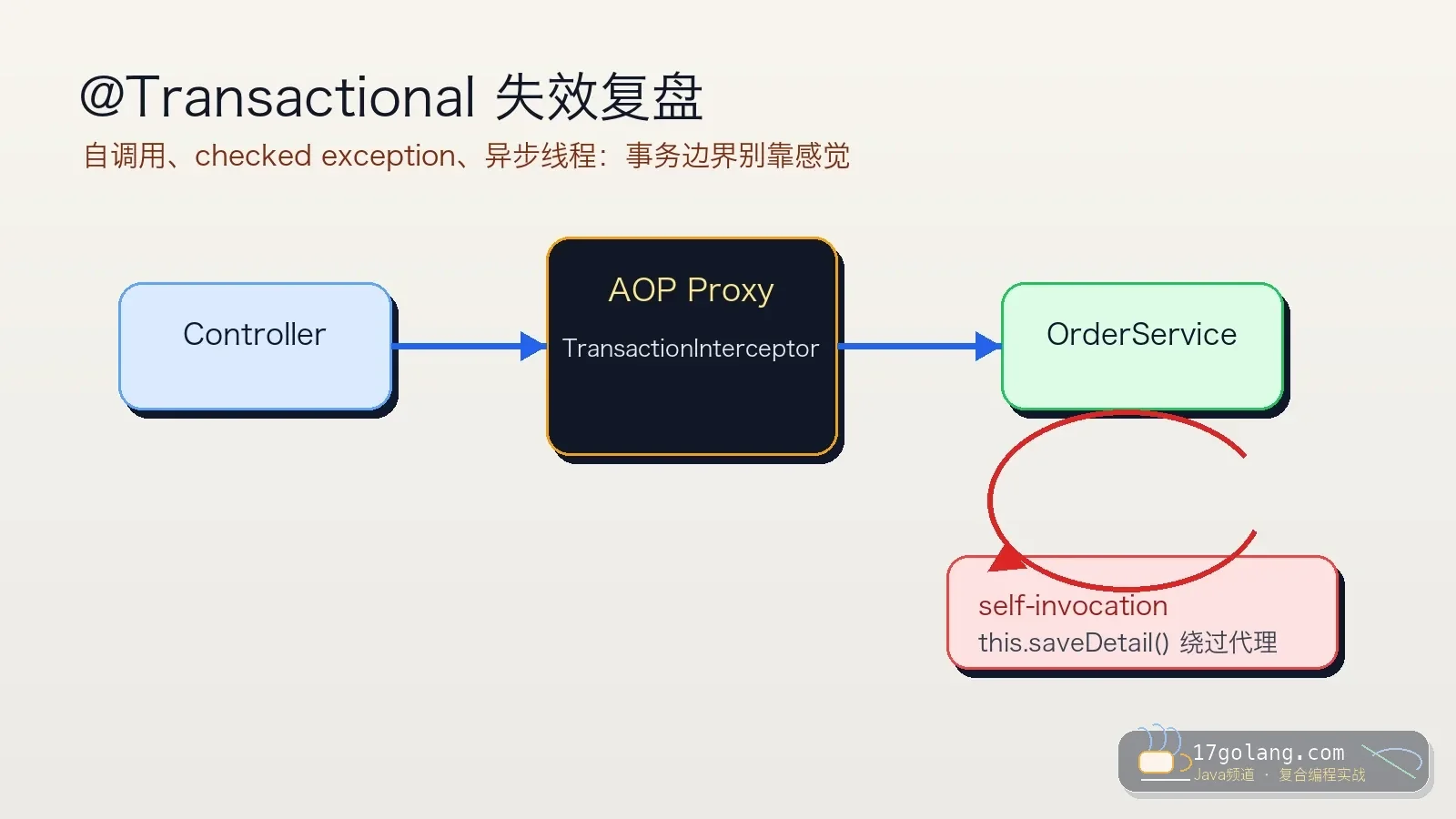
- 文章 · java教程 | 1星期前 | Spring Boot · 事务管理 · 生产实践 · Java教程 · Transactional · java 事务管理 spring boot 生产实践 Transactional
- @Transactional 失效复盘:自调用、异常回滚和异步线程别再踩坑
- 259浏览 收藏
-
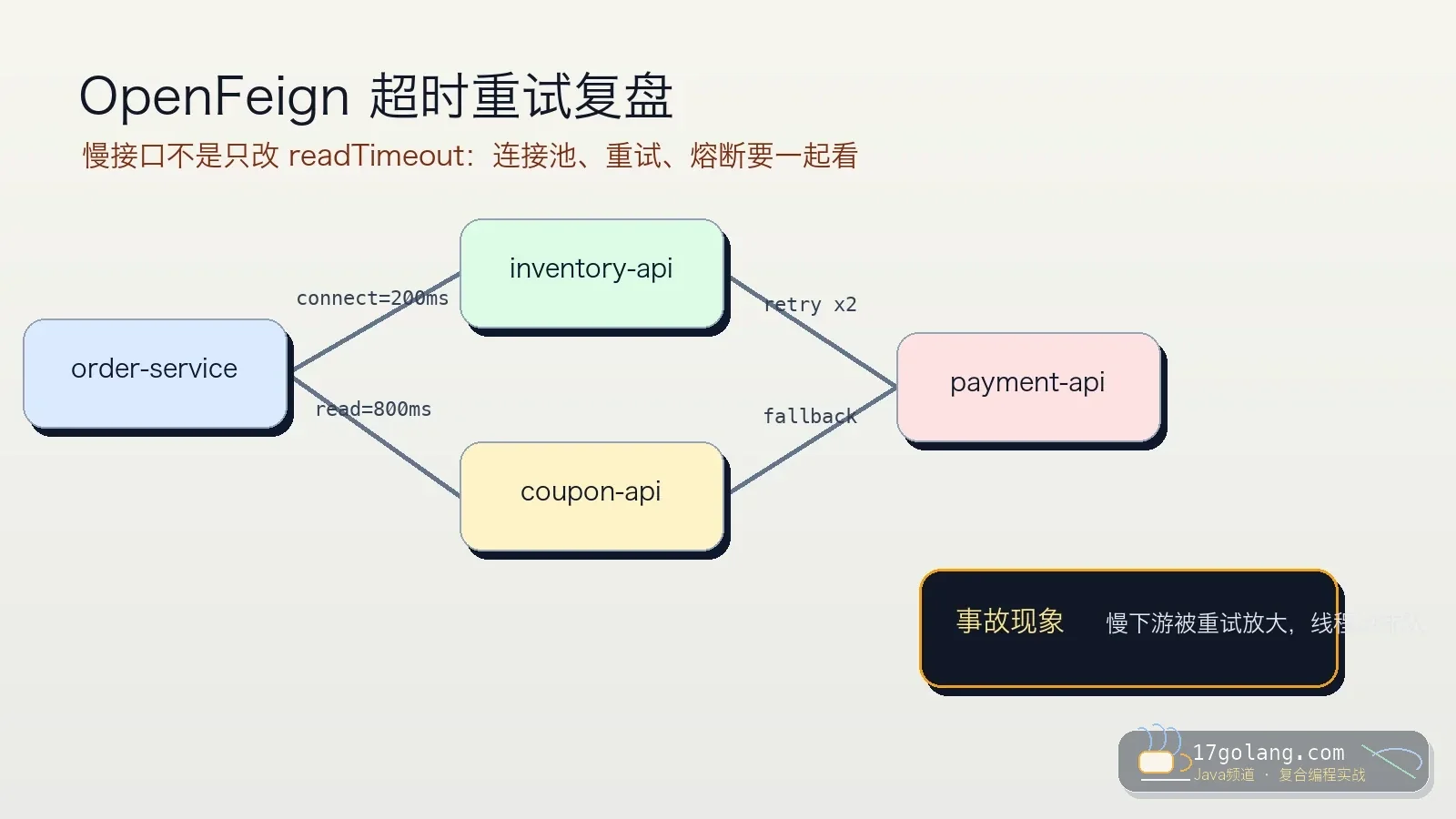
- 文章 · java教程 | 1星期前 | 微服务 · 生产实践 · Java教程 · Spring Cloud · OpenFeign · java 微服务 Spring Cloud 超时重试 OpenFeign
- OpenFeign 超时重试踩坑:别把慢下游重试成全链路雪崩
- 363浏览 收藏
-
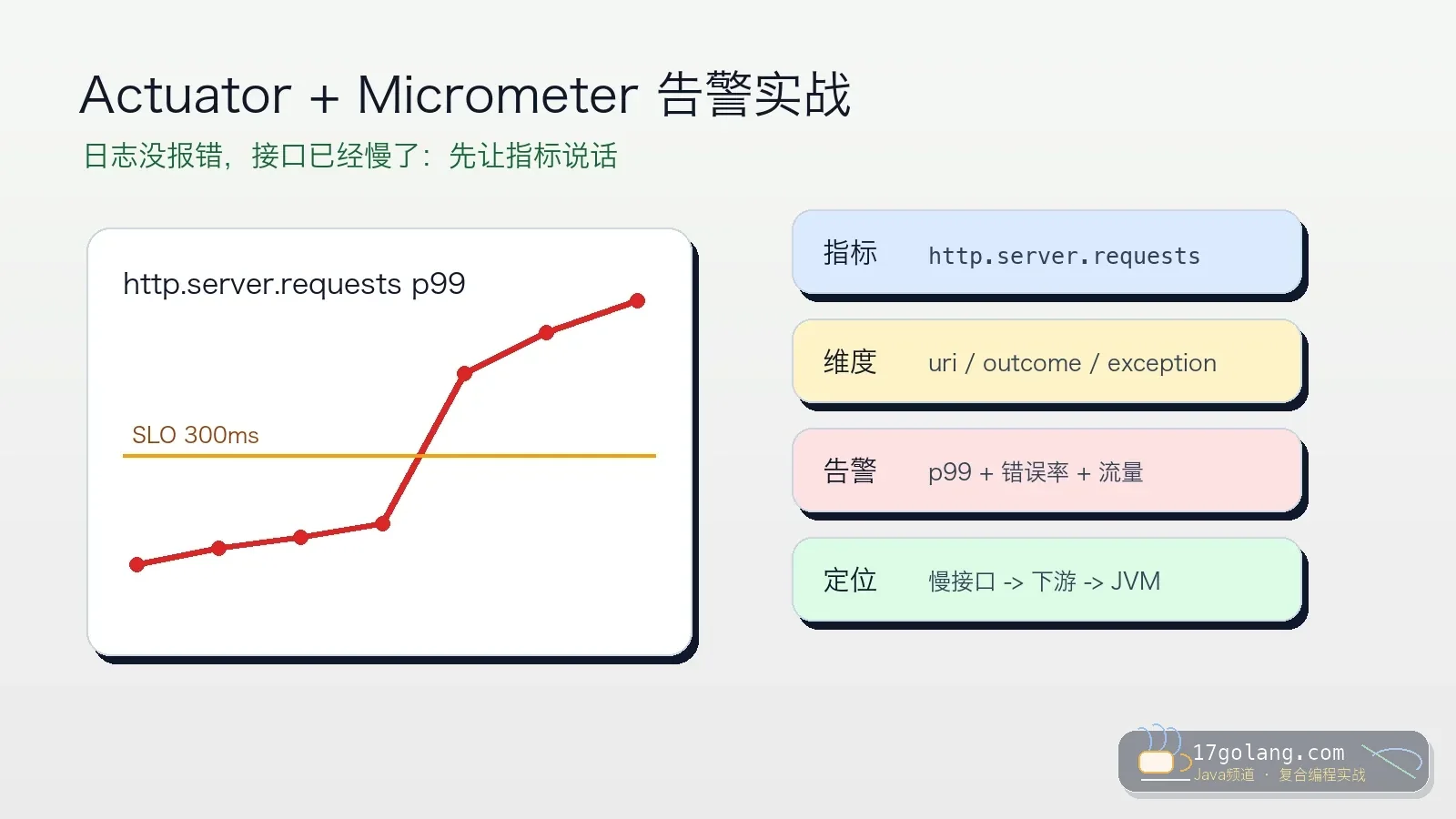
- 文章 · java教程 | 1星期前 | Spring Boot · 生产实践 · Java教程 · Micrometer · Actuator · java spring boot Micrometer 可观测性 actuator
- Spring Boot 指标告警实战:Actuator + Micrometer 让慢接口先暴露
- 240浏览 收藏
-
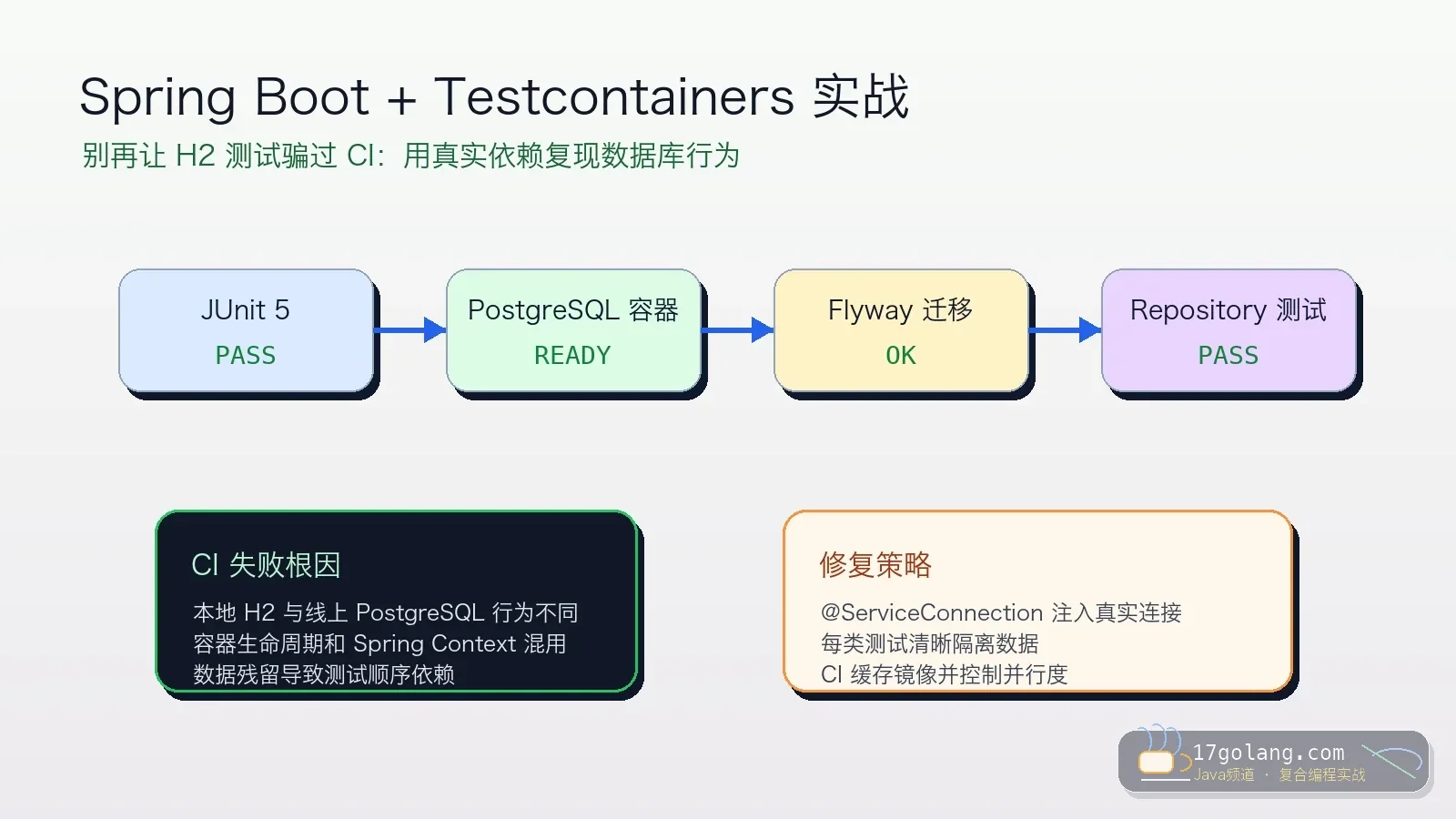
- 文章 · java教程 | 1星期前 | 工程化 · Spring Boot · junit · Java教程 · Testcontainers · java 集成测试 spring boot JUnit 5 Testcontainers
- Spring Boot 集成测试别再只靠 H2:Testcontainers 落地踩坑复盘
- 154浏览 收藏
-
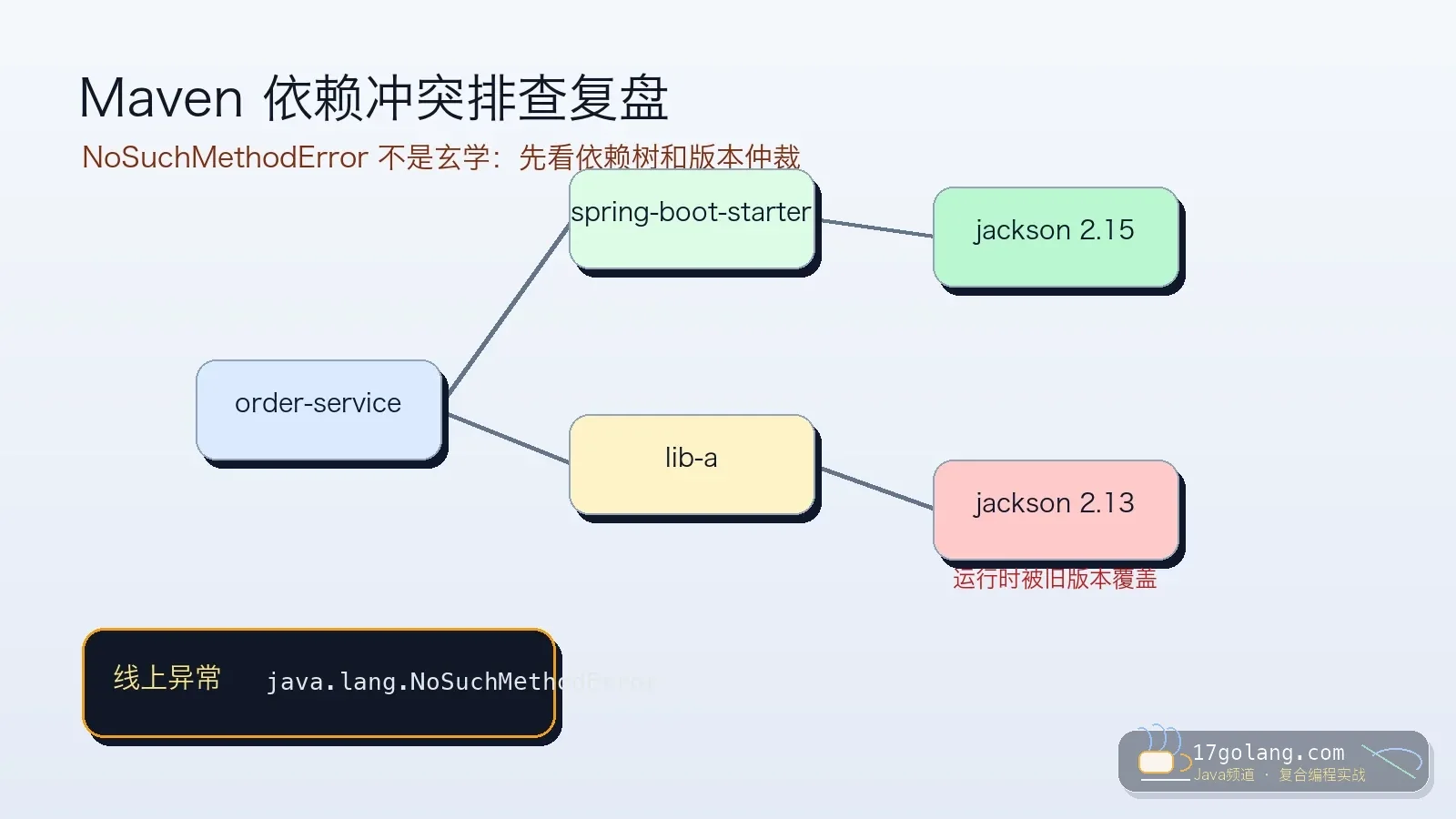
- 文章 · java教程 | 1星期前 | 依赖管理 · Spring Boot · maven · 生产实践 · Java教程 · java maven spring boot 依赖冲突 工程化
- Maven 依赖冲突排查:NoSuchMethodError 不是玄学,先看依赖树
- 135浏览 收藏



-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ChatExcel酷表
- ChatExcel酷表是由北京大学团队打造的Excel聊天机器人,用自然语言操控表格,简化数据处理,告别繁琐操作,提升工作效率!适用于学生、上班族及政府人员。
- 7811次使用
-

- Any绘本
- 探索Any绘本(anypicturebook.com/zh),一款开源免费的AI绘本创作工具,基于Google Gemini与Flux AI模型,让您轻松创作个性化绘本。适用于家庭、教育、创作等多种场景,零门槛,高自由度,技术透明,本地可控。
- 8239次使用
-

- 可赞AI
- 可赞AI,AI驱动的办公可视化智能工具,助您轻松实现文本与可视化元素高效转化。无论是智能文档生成、多格式文本解析,还是一键生成专业图表、脑图、知识卡片,可赞AI都能让信息处理更清晰高效。覆盖数据汇报、会议纪要、内容营销等全场景,大幅提升办公效率,降低专业门槛,是您提升工作效率的得力助手。
- 8049次使用
-

- 星月写作
- 星月写作是国内首款聚焦中文网络小说创作的AI辅助工具,解决网文作者从构思到变现的全流程痛点。AI扫榜、专属模板、全链路适配,助力新人快速上手,资深作者效率倍增。
- 9975次使用
-

- MagicLight
- MagicLight.ai是全球首款叙事驱动型AI动画视频创作平台,专注于解决从故事想法到完整动画的全流程痛点。它通过自研AI模型,保障角色、风格、场景高度一致性,让零动画经验者也能高效产出专业级叙事内容。广泛适用于独立创作者、动画工作室、教育机构及企业营销,助您轻松实现创意落地与商业化。
- 8816次使用
-
- 提升Java功能开发效率的有力工具:微服务架构
- 2023-10-06 501浏览
-
- 掌握Java海康SDK二次开发的必备技巧
- 2023-10-01 501浏览
-
- 如何使用java实现桶排序算法
- 2023-10-03 501浏览
-
- Java开发实战经验:如何优化开发逻辑
- 2023-10-31 501浏览
-
- 如何使用Java中的Math.max()方法比较两个数的大小?
- 2023-11-18 501浏览


