字节团队提出猞猁Lynx模型:多模态LLMs理解认知生成类榜单SoTA
你在学习科技周边相关的知识吗?本文《字节团队提出猞猁Lynx模型:多模态LLMs理解认知生成类榜单SoTA》,主要介绍的内容就涉及到,如果你想提升自己的开发能力,就不要错过这篇文章,大家要知道编程理论基础和实战操作都是不可或缺的哦!
当前大语言模型 (Large Language Models, LLMs) 如 GPT4 在遵循给定图像的开放式指令方面表现出了出色的多模态能力。然而,这些模型的性能严重依赖于对网络结构、训练数据和训练策略等方案的选择,但这些选择并没有在先前的文献中被广泛讨论。此外,目前也缺乏合适的基准 (benchmarks) 来评估和比较这些模型,限制了多模态 LLMs 的 发展。
 图片
图片
- 论文:https://arxiv.org/abs/2307.02469
- 网站:https://lynx-llm.github.io/
- 代码:https://github.com/bytedance/lynx-llm
在这篇文章中,作者从定量和定性两个方面对此类模型的训练进行了系统和全面的研究。设置了 20 多种变体,对于网络结构,比较了不同的 LLMs 主干和模型设计;对于训练数据,研究了数据和采样策略的影响;在指令方面,探讨了多样化提示对模型指令跟随能力的影响。对于 benchmarks ,文章首次提出包括图像和视频任务的开放式视觉问答评估集 Open-VQA。
基于实验结论,作者提出了 Lynx,与现有的开源 GPT4-style 模型相比,它在表现出最准确的多模态理解能力的同时,保持了最佳的多模态生成能力。
评估方案
不同于典型的视觉语言任务,评估 GPT4-style 模型的主要挑战在于平衡文本生成能力和多模态理解准确性两个方面的性能。为了解决这个问题,作者提出了一种包含视频和图像数据的新 benchmark Open-VQA,并对当前的开源模型进行了全面的评价。
具体来说,采用了两种量化评价方案:
- 收集开放式视觉问答 (Open-VQA) 测试集,其包含关于物体、OCR、计数、推理、动作识别、时间顺序等不同类别的问题。不同于有标准答案的 VQA 数据集,Open-VQA 的答案是开放式的。为了评估 Open-VQA 上的性能,使用 GPT4 作为判别器,其结果与人类评估有 95% 的一致性。
- 此外,作者采用了由 mPLUG-owl [1] 提供的 OwlEval 数据集来评估模型的文本生成能力,虽然只包含 50 张图片 82 个问题,但涵盖故事生成、广告生成、代码生成等多样问题,并招募人工标注员对不同模型的表现进行打分。
结论
为了深入研究多模态 LLMs 的训练策略,作者主要从网络结构(前缀微调 / 交叉注意力)、训练数据(数据选择及组合比例)、指示(单一指示 / 多样化指示)、LLMs 模型(LLaMA [5]/Vicuna [6])、图像像素(420/224)等多个方面设置了二十多种变体,通过实验得出了以下主要结论:
- 多模态 LLMs 的指示遵循能力不如 LLMs。例如,InstructBLIP [2] 倾向于不管输入指令如何都生成简短的回复,而其他模型倾向于生成长句子而不考虑指令,作者认为这是由于缺乏高质量和多样化的多模态指令数据所导致的。
- 训练数据的质量对模型的性能至关重要。基于在不同的数据上进行实验的结果,发现使用少量的高质量数据比使用大规模的噪声数据表现得更好。作者认为这是生成式训练和对比式训练的区别,因为生成式训练是直接学习词的条件分布而不是文本和图像的相似度。因此,为了更好的模型性能,在数据方面需要满足两点:1)包含高质量的流畅文本;2)文本和图像内容对齐得较好。
- 任务和提示对零样本 (zero-shot) 能力至关重要。使用多样化任务和指令可以提升模型在未知任务上的零样本生成能力,这与纯文本模型中的观察结果一致。
- 平衡正确性和语言生成能力是很重要的。如果模型在下游任务 (如 VQA) 上训练不足,更可能生成与视觉输入不符的编造的内容;而如果模型在下游任务中训练过多,它则倾向于生成短答案,将无法按照用户的指示生成较长的答案。
- 前缀微调 (prefix-finetuning, PT) 是目前对 LLMs 进行多模态适配的最佳方案。在实验中,prefix-finetuning 结构的模型能更快地提升对多样化指示的遵循能力,比交叉注意力 (cross-attention, CA) 的模型结构更易训练。(prefix-tuning 和 cross-attention 为两种模型结构,具体见 Lynx 模型介绍部分)
Lynx 模型
作者提出了 Lynx(猞猁)—— 进行了两阶段训练的 prefix-finetuning 的 GPT4-style 模型。在第一阶段,使用大约 120M 图像 - 文本对来对齐视觉和语言嵌入 (embeddings) ;在第二阶段,使用 20 个图像或视频的多模态任务以及自然语言处理 (NLP) 数据来调整模型的指令遵循能力。
 图片
图片
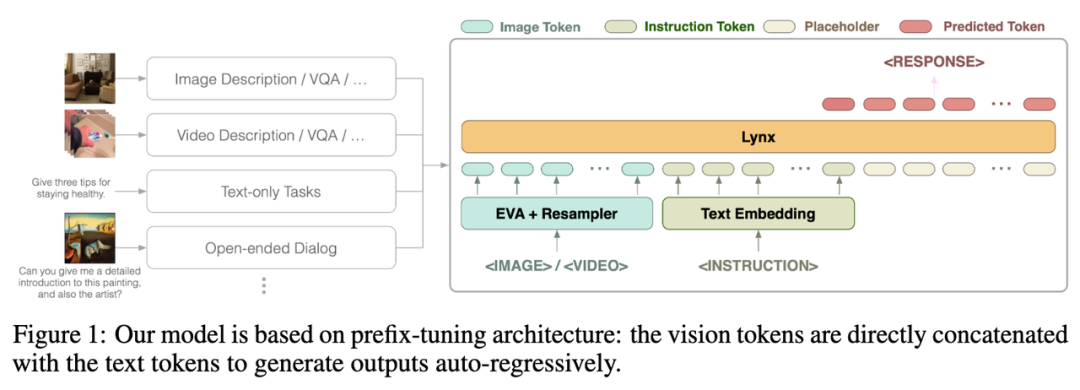
Lynx 模型的整体结构如上图 Figure 1 所示。
视觉输入经过视觉编码器处理后得到视觉令牌 (tokens) $$W_v$$,经过映射后与指令 tokens $$W_l$$ 拼接作为 LLMs 的输入,在本文中将这种结构称为「prefix-finetuning」以区别于如 Flamingo [3] 所使用的 cross-attention 结构。
此外,作者发现,通过在冻结 (frozen) 的 LLMs 某些层后添加适配器 (Adapter) 可以进一步降低训练成本。
模型效果
作者测评了现有的开源多模态 LLMs 模型在 Open-VQA、Mme [4] 及 OwlEval 人工测评上的表现(结果见后文图表,评估细节见论文)。可以看到 Lynx 模型在 Open-VQA 图像和视频理解任务、OwlEval 人工测评及 Mme Perception 类任务中都取得了最好的表现。其中,InstructBLIP 在多数任务中也实现了高性能,但其回复过于简短,相较而言,在大多数情况下 Lynx 模型在给出正确的答案的基础上提供了简明的理由来支撑回复,这使得它对用户更友好(部分 cases 见后文 Cases 展示部分)。
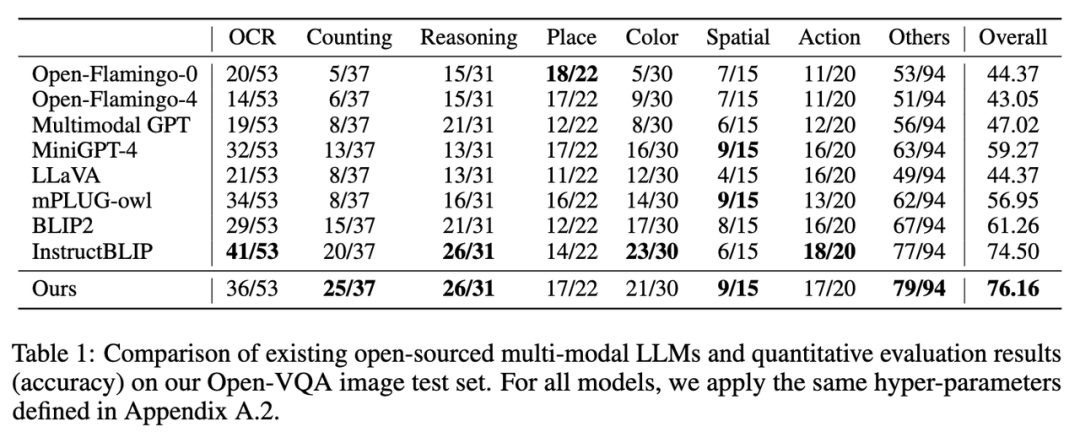
1. 在 Open-VQA 图像测试集上的指标结果如下图 Table 1 所示:
 图片
图片
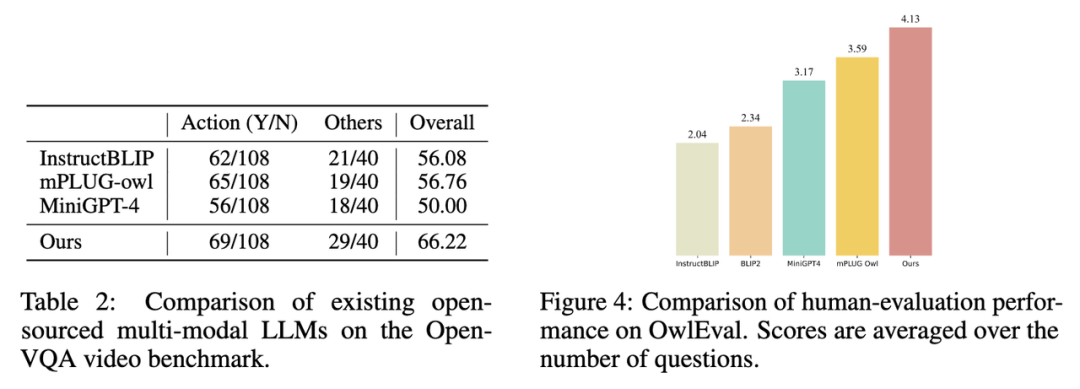
2. 在 Open-VQA 视频测试集上的指标结果如下图 Table 2 所示。
 图片
图片
3. 选取 Open-VQA 中得分排名靠前的模型进行 OwlEval 测评集上的人工效果评估,其结果如上图 Figure 4 所示。从人工评价结果可以看出 Lynx 模型具有最佳的语言生成性能。
 图片
图片
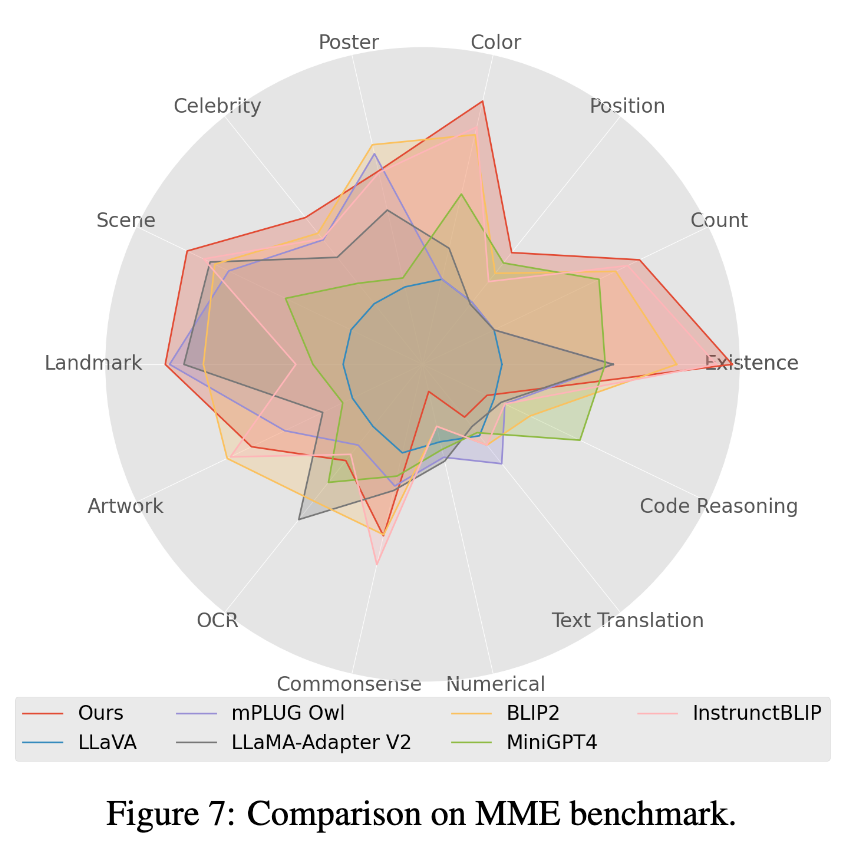
4. 在 Mme benchmark 测试中,Perception 类任务获得最好的表现,其中 14 类子任务中有 7 个表现最优。(详细结果见论文附录)
Cases 展示
Open-VQA 图片 cases

OwlEval cases

Open-VQA 视频 case

总结
在本文中,作者通过对二十多种多模态 LLMs 变种的实验,确定了以 prefix-finetuning 为主要结构的 Lynx 模型并给出开放式答案的 Open-VQA 测评方案。实验结果显示 Lynx 模型表现最准确的多模态理解准确度的同时,保持了最佳的多模态生成能力。
理论要掌握,实操不能落!以上关于《字节团队提出猞猁Lynx模型:多模态LLMs理解认知生成类榜单SoTA》的详细介绍,大家都掌握了吧!如果想要继续提升自己的能力,那么就来关注golang学习网公众号吧!
 美团无人机的启示:互联网告别互联网
美团无人机的启示:互联网告别互联网
- 上一篇
- 美团无人机的启示:互联网告别互联网
- 下一篇
- Win10任务管理器的快捷键有哪些

-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 485次学习
-

- ljg-skills
- ljg-skills 是李继刚开源的 AI 技能与提示词集合,面向大模型使用者整理了一批可复用的 prompt、角色设定和任务技能模板,适合用于学习提示词设计、搭建个人 AI 工作流和沉淀团队常用智能体能力。
- 2457次使用
-

- MELO音乐
- MELO音乐是一站式AI视频与音乐制作助手,对标suno, udio的高品质体验。提供伴奏生成、原创写词、无损导出、哼唱识曲、混音变声等全套音频与短视频编辑工具。无论是流行Kpop、电音说唱、民谣古风、摇滚儿歌还是商用轻音乐,MELO为你免费谱曲,轻松做同款!
- 2262次使用
-

- UniScribe
- UniScribe 是一款 AI 音视频转文字与内容整理工具,支持上传音频、视频文件或粘贴 YouTube 链接,自动生成转写文本、摘要、思维导图和关键问题,并支持多格式导出,适合会议记录、课程学习、访谈整理和内容创作复盘。
- 2212次使用
-

- 剧云
- 剧云是专业中文剧本创作平台,安全稳定运行十余年,集成AI编剧、剧本医生审核、人物小传、剧情关系图、大纲编写、多人协作、Word导入导出、版权管控功能,数据安全防护,轻松高效创作剧本。
- 2419次使用
-

- 万象有声
- 万象有声,一个专为有声创作者打造的新一代智能有声内容创作平台。平台提供专业的智能拆章、智能画本编辑、AI配音、AI生成音效、后期制作、智能对轨、智能审听等有声创作全流程工具,可以帮助创作者高效、低成本创作出引人入胜的有声作品。立即体验,让有声书制作更简单!
- 2387次使用
-
- AI写作工具免费版安装教程(含豆包Clawdbot)
- 2026-05-30 501浏览
-
- WPS AI能自动生成PPT吗?输入主题一键制作演示文稿
- 2026-05-27 501浏览
-
- Canva手机闪退解决方法及适配指南
- 2026-05-25 501浏览
-
- Hermes Agent依赖的工具链有哪些 必备工具链介绍
- 2026-05-05 501浏览
-
- 千问AI官网地址链接入口_千问AI官方网站登陆入口
- 2026-05-05 501浏览


