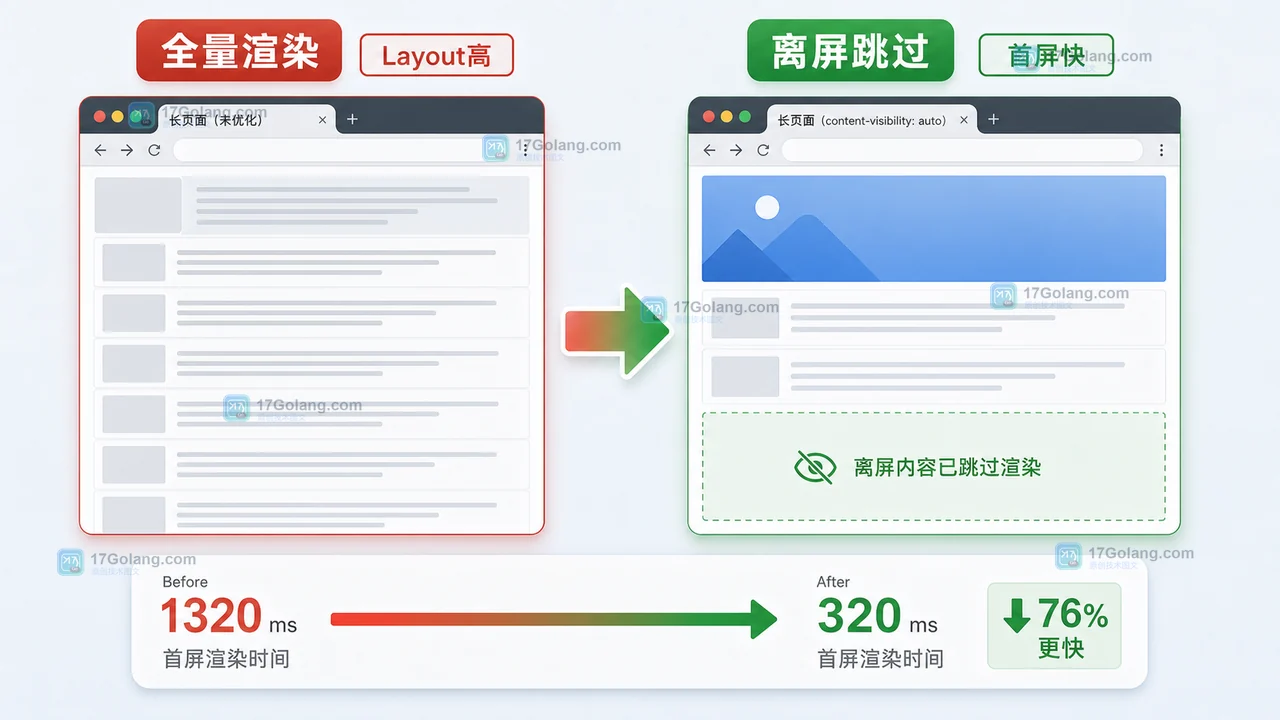
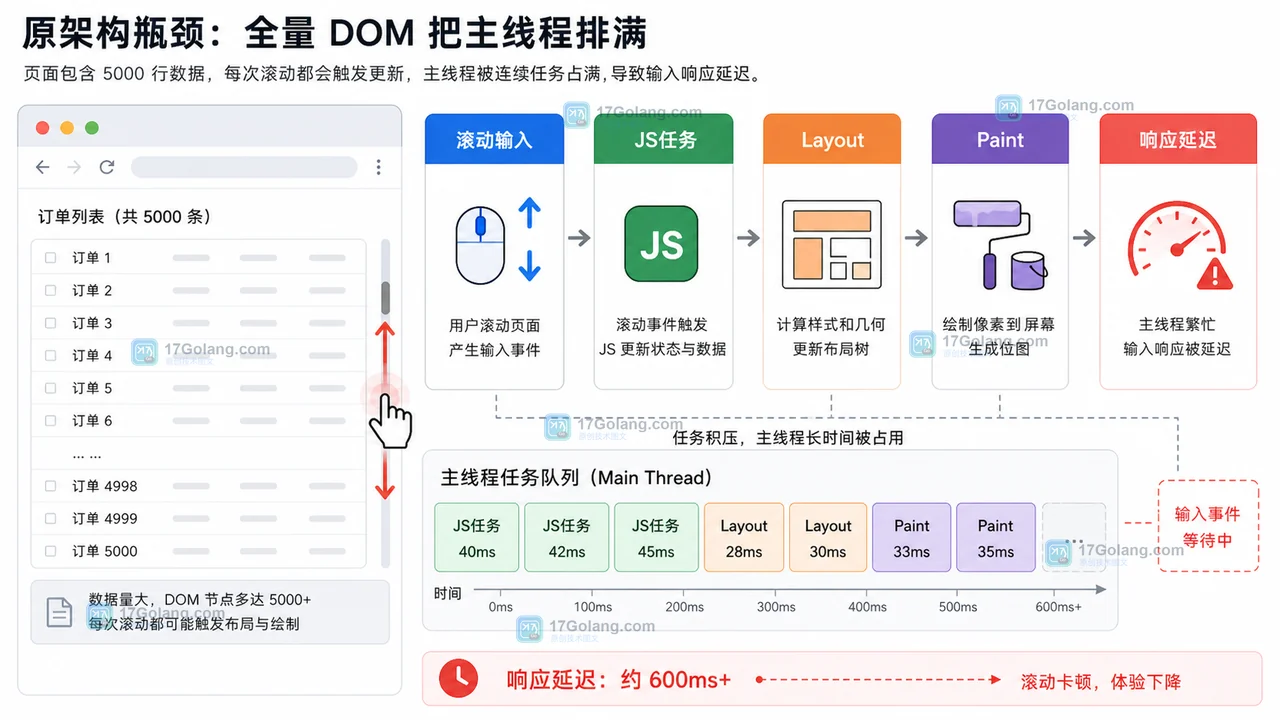
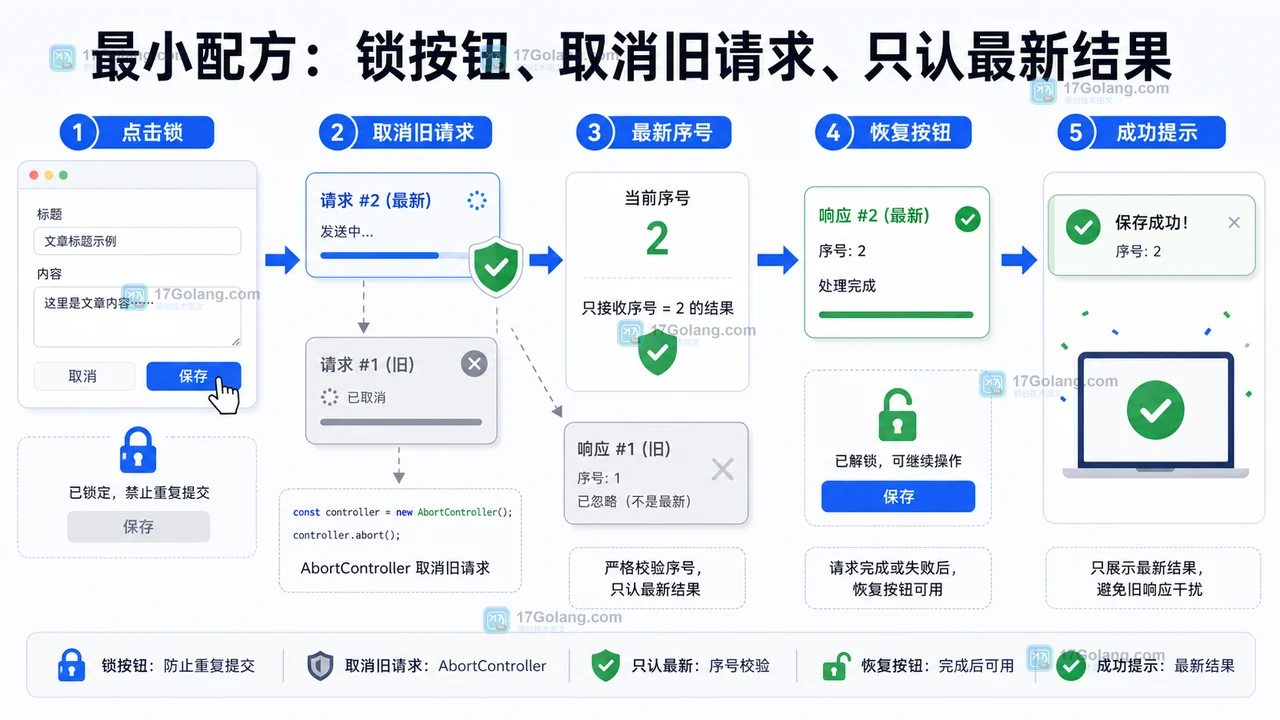
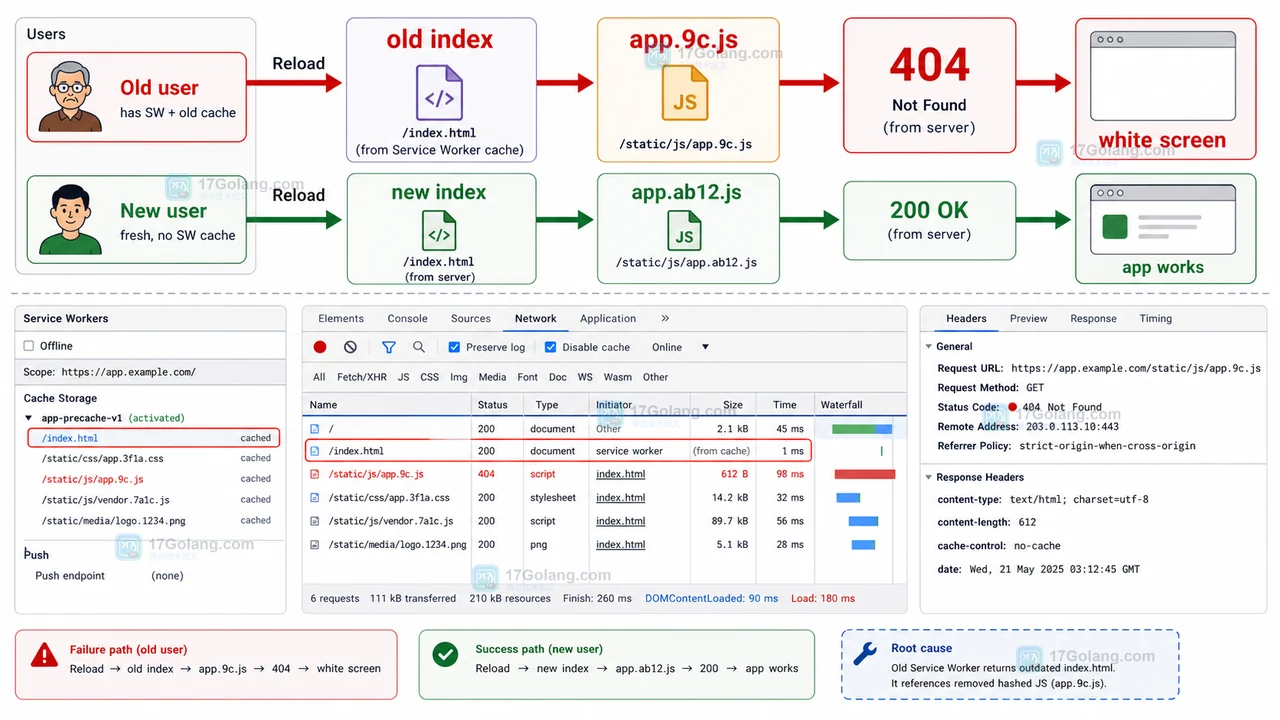
Rvest爬虫实战:NPB数据抓取技巧分享
各位小伙伴们,大家好呀!看看今天我又给各位带来了什么文章?本文标题是《Rvest爬虫实战:抓取NPB官网数据技巧》,很明显是关于文章的文章哈哈哈,其中内容主要会涉及到等等,如果能帮到你,觉得很不错的话,欢迎各位多多点评和分享!

本文详解如何使用 R 语言的 rvest 包稳定抓取 npb.jp 网站上的棒球统计表格,重点解决 SSL 证书错误、动态结构识别与 CSS 选择器失效等常见问题,并提供可复用的健壮代码方案。
在使用 rvest 抓取日本职业棒球联盟(NPB)官网(如 https://npb.jp/bis/eng/2022/stats/std_c.html)时,初学者常遇到“无法定位表格”的问题——这并非因为网页结构复杂,而多源于三个关键因素:HTTPS 证书验证失败、HTML 实际结构与开发者工具显示不一致、以及过度嵌套的 CSS 选择器导致节点匹配失败。
原始代码中使用的 CSS 选择器 #stdivmaintbl > table > tbody > tr > td > div:nth-child(1) 过于具体且依赖 DOM 渲染路径,而 NPB 官网实际采用的是语义化类名(如 .stdtblmain)包裹表格,且页面中存在多个同类型表格(例如投手/打者统计),直接硬编码层级极易断裂。
✅ 推荐做法是:优先使用语义清晰的 class 名称定位,避免深度层级依赖。实测表明,.stdtblmain 是该页面所有主统计表的统一容器类,配合 html_table() 可自动解析其内部
占位,html_table(fill = TRUE) 可自动填充缺失值,但需后续清洗(如删除重复标题行、清理 "***" 占位符)。df_pitchers <- tables[[2]] # 第二个主表常为投手数据 ? 总结:成功抓取的核心在于「简化选择器 + 善用容错参数 + 本地化调试先行」。不要迷信浏览器开发者工具中看到的完整路径,而应观察 |
 清除浮动技巧:让背景完整覆盖内容
清除浮动技巧:让背景完整覆盖内容