当前位置:首页 > 文章列表
>
文章 >
前端 >
提取HTML中img标签的图片链接,尤其是兼容src和data-src属性,可以通过解析HTML文档并遍历所有标签来实现。以下是一个使用Python的示例,展示了如何从HTML字符串中提取这些图片链接:✅ 示例代码(Python)from bs4 import BeautifulSoup
html = '''
提取HTML中img标签的图片链接,尤其是兼容src和data-src属性,可以通过解析HTML文档并遍历所有![]() 标签来实现。以下是一个使用Python的示例,展示了如何从HTML字符串中提取这些图片链接:✅ 示例代码(Python)from bs4 import BeautifulSoup
html = '''
标签来实现。以下是一个使用Python的示例,展示了如何从HTML字符串中提取这些图片链接:✅ 示例代码(Python)from bs4 import BeautifulSoup
html = '''
 2026-01-28 12:36:48
0浏览
收藏
2026-01-28 12:36:48
0浏览
收藏
今天golang学习网给大家带来了《提取HTML中img标签的图片链接,尤其是兼容src和data-src属性,可以通过解析HTML文档并遍历所有标签来实现。以下是一个使用Python的示例,展示了如何从HTML字符串中提取这些图片链接:✅ 示例代码(Python)from bs4 import BeautifulSoup
html = '''


 '''
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html, 'html.parser')
# 提取所有img标签
images = soup.find_all('img')
# 遍历每个img标签,提取src或data-src
for img in images:
src = img.get('src')
data_src = img.get('data-src')
if src:
print("src:", src)
if data_src:
print("data-src:", data_src)🔍 输出结果
src: https://example.com/image1.jpg
data-src: https://example.com/image2.jpg
src: https://example.com/image3.jpg
data-src:》,其中涉及到的知识点包括等等,无论你是小白还是老手,都适合看一看哦~有好的建议也欢迎大家在评论留言,若是看完有所收获,也希望大家能多多点赞支持呀!一起加油学习~
'''
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html, 'html.parser')
# 提取所有img标签
images = soup.find_all('img')
# 遍历每个img标签,提取src或data-src
for img in images:
src = img.get('src')
data_src = img.get('data-src')
if src:
print("src:", src)
if data_src:
print("data-src:", data_src)🔍 输出结果
src: https://example.com/image1.jpg
data-src: https://example.com/image2.jpg
src: https://example.com/image3.jpg
data-src:》,其中涉及到的知识点包括等等,无论你是小白还是老手,都适合看一看哦~有好的建议也欢迎大家在评论留言,若是看完有所收获,也希望大家能多多点赞支持呀!一起加油学习~

本文介绍在Python网络爬虫中,如何使用BeautifulSoup灵活提取img标签的图片URL,无论其使用src还是data-src属性,确保所有图片链接被一致、准确地获取为纯文本。
在网页开发中,为优化加载性能,许多网站采用“懒加载”(lazy loading)技术:首屏图片直接通过 src 属性加载,而后续图片则使用 data-src 属性暂存URL,待滚动至可视区域时再由JavaScript动态赋值给 src。这导致在Web Scraping过程中,同一页面的 标签可能混用 src 和 data-src,无法用单一属性名统一提取。
直接硬编码 tag.get('src') 或 tag.get('data-src') 都会遗漏部分链接。正确做法是对每个匹配的 元素进行属性存在性判断,优先取 src(因其代表当前有效链接),若不存在则回退至 data-src(通常为备用真实URL)。
以下为完整、可运行的解决方案:
from bs4 import BeautifulSoup html = '''
![]()
''' soup = BeautifulSoup(html, 'html.parser') image_urls = [] for img in soup.select('img.class_name'): # 使用CSS选择器精准定位目标img url = img.get('src') or img.get('data-src') # 短路逻辑:有src则用src,否则用data-src if url: # 过滤空值,避免None或空字符串 image_urls.append(url) # 输出结果 for url in image_urls: print(url)

 '''
soup = BeautifulSoup(html, 'html.parser')
image_urls = []
for img in soup.select('img.class_name'): # 使用CSS选择器精准定位目标img
url = img.get('src') or img.get('data-src') # 短路逻辑:有src则用src,否则用data-src
if url: # 过滤空值,避免None或空字符串
image_urls.append(url)
# 输出结果
for url in image_urls:
print(url)
'''
soup = BeautifulSoup(html, 'html.parser')
image_urls = []
for img in soup.select('img.class_name'): # 使用CSS选择器精准定位目标img
url = img.get('src') or img.get('data-src') # 短路逻辑:有src则用src,否则用data-src
if url: # 过滤空值,避免None或空字符串
image_urls.append(url)
# 输出结果
for url in image_urls:
print(url)✅ 输出:
https://website1.png https://website2.png https://website3.png
? 关键技巧说明:
- 使用 soup.select('img.class_name') 比 find_all('img', class_='class_name') 更简洁且支持复合类名(如 class_name late);
- img.get('src') or img.get('data-src') 利用Python的短路求值,语义清晰、代码精简;
- 建议始终检查 url 是否为真值(if url:),因某些
可能既无 src 也无 data-src(如占位符或JS生成元素);
- 若需去重,可将 image_urls 改为 set(),最后转为列表排序或保持插入顺序(Python 3.7+ dict/set 有序)。
该方法健壮、通用,适用于绝大多数懒加载场景,是生产级爬虫中处理混合属性图片链接的标准实践。
本篇关于《提取HTML中img标签的图片链接,尤其是兼容src和data-src属性,可以通过解析HTML文档并遍历所有标签来实现。以下是一个使用Python的示例,展示了如何从HTML字符串中提取这些图片链接:✅ 示例代码(Python)from bs4 import BeautifulSoup
html = '''
'''
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html, 'html.parser')
# 提取所有img标签
images = soup.find_all('img')
# 遍历每个img标签,提取src或data-src
for img in images:
src = img.get('src')
data_src = img.get('data-src')
if src:
print("src:", src)
if data_src:
print("data-src:", data_src)🔍 输出结果
src: https://example.com/image1.jpg
data-src: https://example.com/image2.jpg
src: https://example.com/image3.jpg
data-src:》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于文章的相关知识,请关注golang学习网公众号!  中学生综评系统入口及登录方法
中学生综评系统入口及登录方法
- 上一篇
- 中学生综评系统入口及登录方法
- 下一篇
- App下载量下滑,支出激增1560亿
-
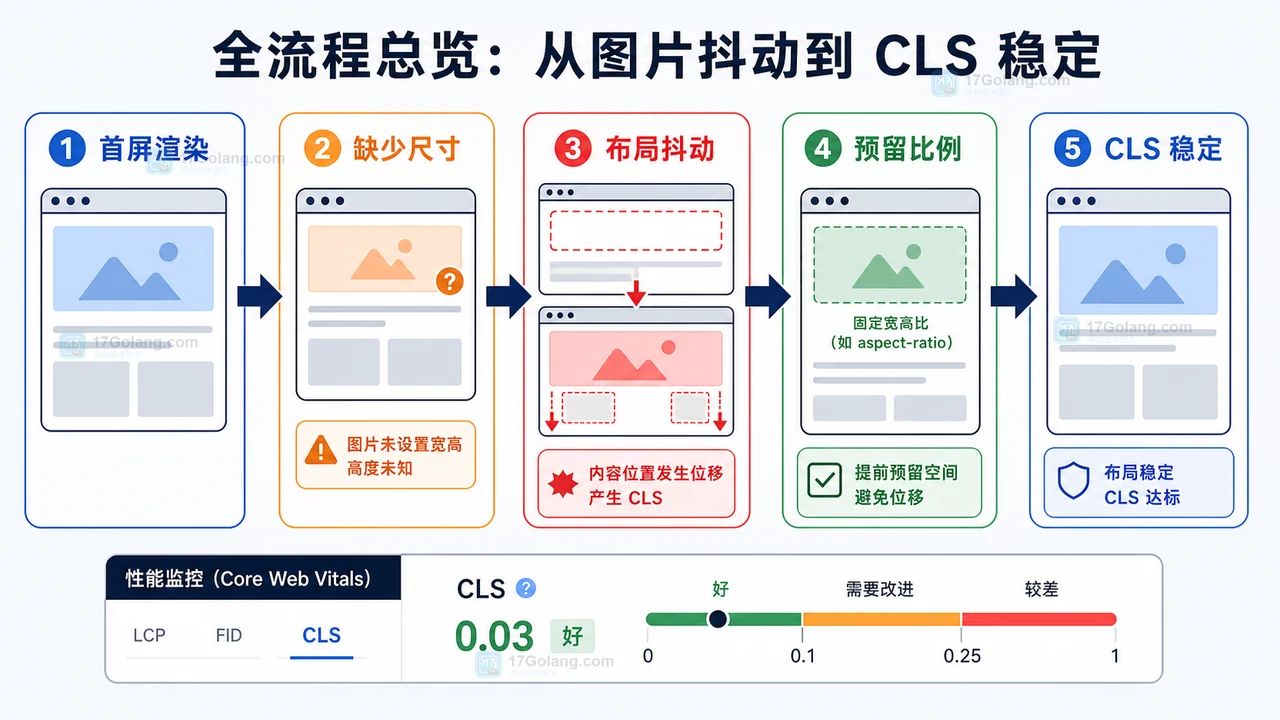
- 文章 · 前端 | 52分钟前 | 前端 · 性能优化 · cls · 懒加载 · Core Web Vitals · 前端 图片懒加载 IntersectionObserver CLS 布局稳定
- 前端图片懒加载布局抖动治理完整流程:占位比例、按需加载和 CLS 复查
- 128浏览 收藏
-

- 文章 · 前端 | 20小时前 | 工程化 · 前端 · javascript · css · 弹窗 · 前端 z-index 遮罩层 stacking context Portal 弹窗层级
- 前端弹窗层级治理工作流:从 z-index 混乱到 Portal 容器规范
- 350浏览 收藏
-
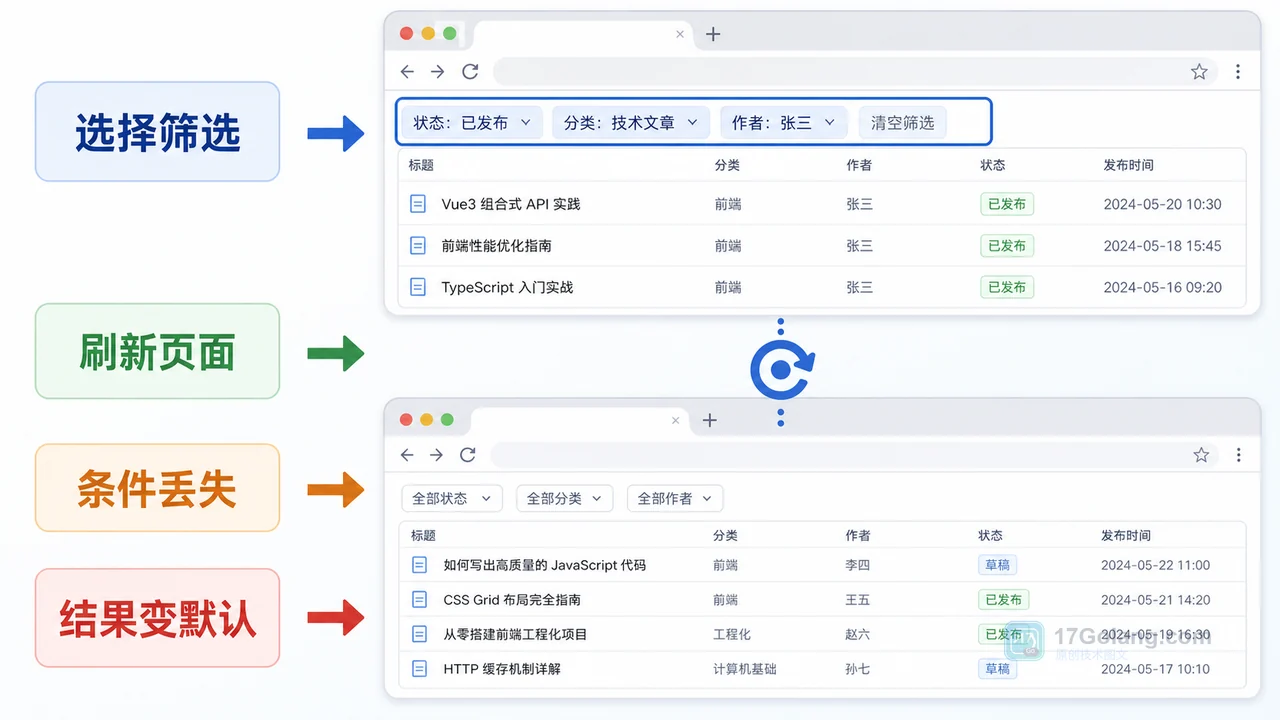
- 文章 · 前端 | 21小时前 | 前端 · javascript · URL参数 · 列表筛选 · 页面状态 · 前端 筛选条件 列表页 history.replaceState URLSearchParams 刷新还原
- 前端筛选条件刷新后丢失怎么办:从内存状态到 URL 参数一步步排查
- 348浏览 收藏
-
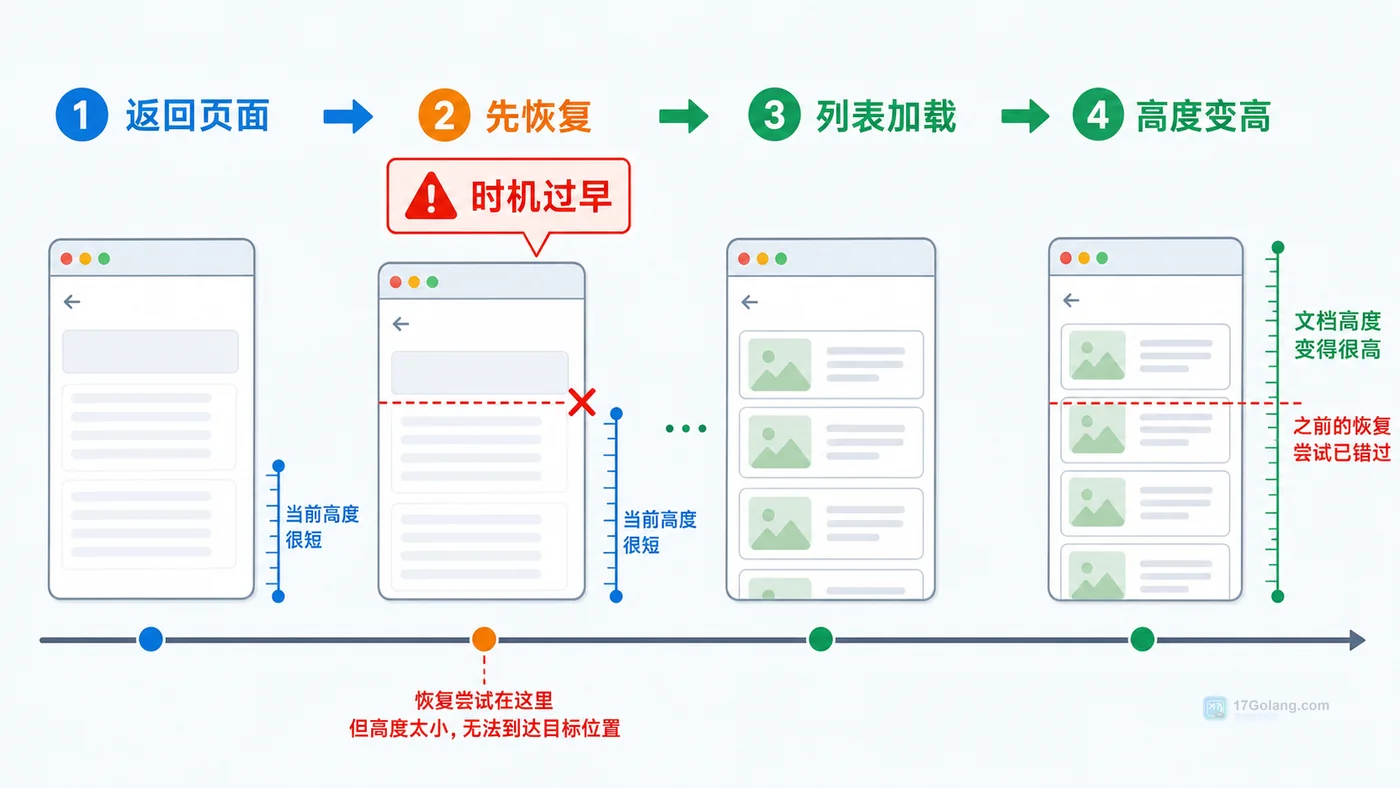
- 文章 · 前端 | 23小时前 | 前端 · 性能优化 · 路由 · javascript · 前端 用户体验 滚动位置 路由缓存 scrollRestoration
- 前端详情页返回列表丢失滚动位置怎么办:从复现到恢复一步步排查
- 458浏览 收藏
-
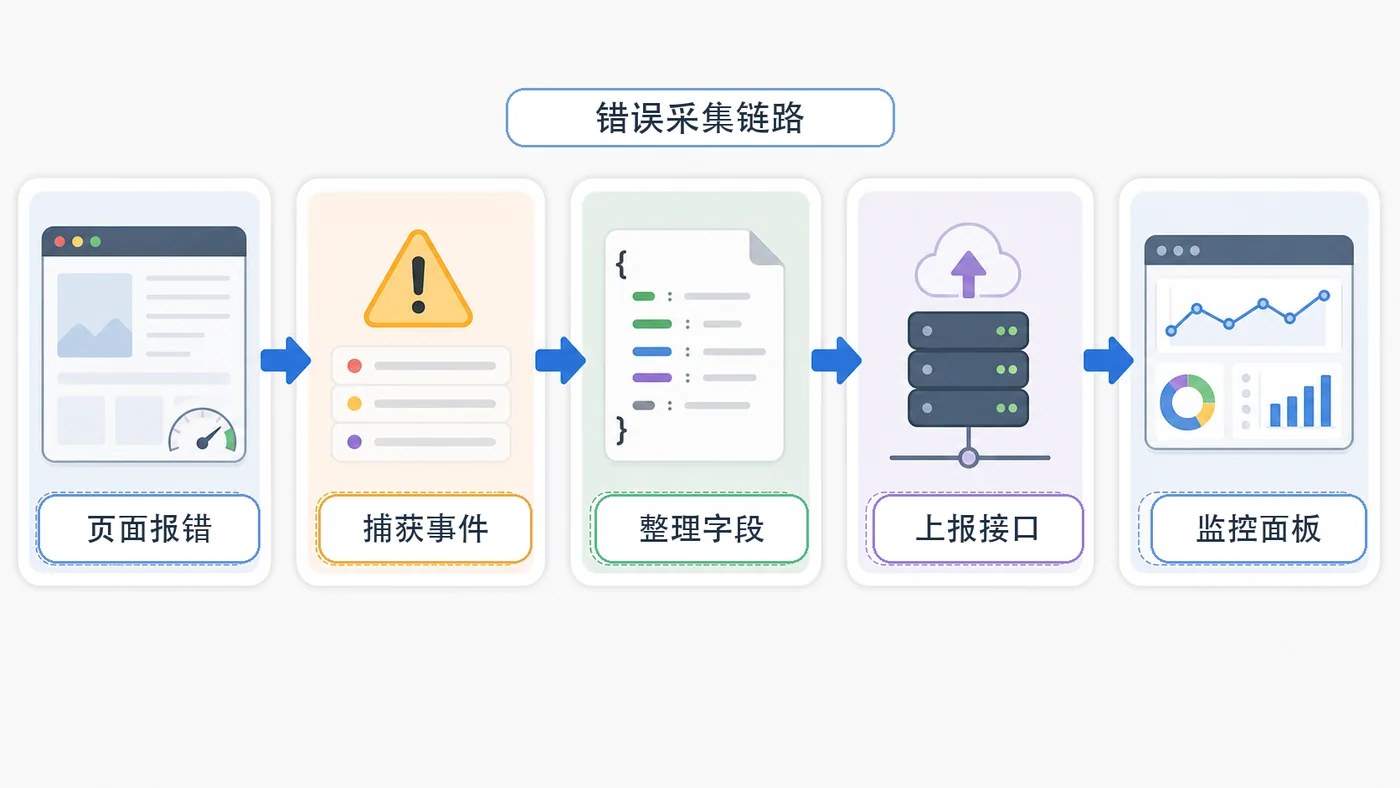
- 文章 · 前端 | 3天前 | 前端 · javascript · sourcemap · 错误监控 · 线上排查 · 前端 错误监控 告警 onerror sourcemap unhandledrejection
- 前端错误监控实战:onerror、unhandledrejection 和 sourcemap 定位问题
- 331浏览 收藏
-
- 文章 · 前端 | 3天前 | 前端 · javascript · 缓存治理 · localStorage · Web性能 · 前端 本地缓存 localStorage 过期时间 版本迁移 异常兜底
- 前端 localStorage 缓存治理实战:过期时间、版本号和异常兜底
- 480浏览 收藏
-
- 文章 · 前端 | 3天前 | 前端 · 性能优化 · javascript · 图片优化 · IntersectionObserver · 前端 性能优化 图片懒加载 IntersectionObserver Web性能 首屏优化
- 前端图片懒加载实战:用 IntersectionObserver 降低首屏压力
- 184浏览 收藏
-
- 文章 · 前端 | 3天前 | 前端 · 性能优化 · javascript · fetch · 前端 搜索优化 Fetch AbortController 请求竞态
- 前端搜索竞态治理实战:用 AbortController 取消过期请求
- 178浏览 收藏